Go第八篇之包的使用
Go 语言的源码复用建立在包(package)基础之上。Go 语言的入口 main() 函数所在的包(package)叫 main,main 包想要引用别的代码,必须同样以包的方式进行引用,本章内容将详细讲解如何导出包的内容及如何导入其他包。
Go 语言的包与文件夹一一对应,所有与包相关的操作,必须依赖于工作目录(GOPATH)。
Go语言GOPATH
GOPATH 是 Go 语言中使用的一个环境变量,它使用绝对路径提供项目的工作目录。
工作目录是一个工程开发的相对参考目录,好比当你要在公司编写一套服务器代码,你的工位所包含的桌面、计算机及椅子就是你的工作区。工作区的概念与工作目录的概念也是类似的。如果不使用工作目录的概念,在多人开发时,每个人有一套自己的目录结构,读取配置文件的位置不统一,输出的二进制运行文件也不统一,这样会导致开发的标准不统一,影响开发效率。
GOPATH 适合处理大量 Go 语言源码、多个包组合而成的复杂工程。
提示
C、C++、Java、C# 及其他语言发展到后期,都拥有自己的 IDE(集成开发环境),并且工程(Project)、解决方案(Solution)和工作区(Workspace)等概念将源码和资源组织了起来,方便编译和输出。
使用命令行查看GOPATH信息
在安装过 Go 开发包的操作系统中,可以使用命令行查看 Go 开发包的环境变量配置信息,这些配置信息里可以查看到当前的 GOPATH 路径设置情况。在命令行中运行go env后,命令行将提示以下信息:
$ go env
GOARCH="amd64"
GOBIN=""
GOEXE=""
GOHOSTARCH="amd64"
GOHOSTOS="linux"
GOOS="linux"
GOPATH="/home/davy/go"
GORACE=""
GOROOT="/usr/local/go"
GOTOOLDIR="/usr/local/go/pkg/tool/linux_amd64"
GCCGO="gccgo"
CC="gcc"
GOGCCFLAGS="-fPIC -m64 -pthread -fmessage-length=0"
CXX="g++"
CGO_ENABLED="1"
CGO_CFLAGS="-g -O2"
CGO_CPPFLAGS=""
CGO_CXXFLAGS="-g -O2"
CGO_FFLAGS="-g -O2"
CGO_LDFLAGS="-g -O2"
PKG_CONFIG="pkg-config"
命令行说明如下:
- 第 1 行,执行 go env 指令,将输出当前 Go 开发包的环境变量状态。
- 第 2 行,GOARCH 表示目标处理器架构。
- 第 3 行,GOBIN 表示编译器和链接器的安装位置。
- 第 7 行,GOOS 表示目标操作系统。
- 第 8 行,GOPATH 表示当前工作目录。
- 第 10 行,GOROOT 表示 Go 开发包的安装目录。
从命令行输出中,可以看到 GOPATH 设定的路径为:/home/davy/go(davy 为笔者的用户名)。
在 Go 1.8 版本之前,GOPATH 环境变量默认是空的。从 Go 1.8 版本开始,Go 开发包在安装完成后,将 GOPATH 赋予了一个默认的目录,参见下表。
| 平 台 | GOPATH 默认值 | 举 例 |
|---|---|---|
| Windows 平台 | %USERPROFILE%/go | C:\Users\用户名\go |
| Unix 平台 | $HOME/go | /home/用户名/go |
使用GOPATH的工程结构
在 GOPATH 指定的工作目录下,代码总是会保存在 $GOPATH/src 目录下。在工程经过 go build、go install 或 go get 等指令后,会将产生的二进制可执行文件放在 $GOPATH/bin 目录下,生成的中间缓存文件会被保存在 $GOPATH/pkg 下。
如果需要将整个源码添加到版本管理工具(Version Control System,VCS)中时,只需要添加 $GOPATH/src 目录的源码即可。bin 和 pkg 目录的内容都可以由 src 目录生成。
设置和使用GOPATH
本节以 Linux 为演示平台,为大家演示使用 GOPATH 的方法。
1) 设置当前目录为GOPATH
选择一个目录,在目录中的命令行中执行下面的指令:
export GOPATH=`pwd`
该指令中的 pwd 将输出当前的目录,使用反引号`将 pwd 指令括起来表示命令行替换,也就是说,使用`pwd`将获得 pwd 返回的当前目录的值。例如,假设你的当前目录是“/home/davy/go”,那么使用`pwd`将获得返回值“/home/davy/go”。
使用 export 指令可以将当前目录的值设置到环境变量 GOPATH中。
2) 建立GOPATH中的源码目录
使用下面的指令创建 GOPATH 中的 src 目录,在 src 目录下还有一个 hello 目录,该目录用于保存源码。
mkdir -p src/hello
mkdir 指令的 -p 可以连续创建一个路径。
3) 添加main.go源码文件
使用 Linux 编辑器将下面的源码保存为 main.go 并保存到 $GOPATH/src/hello 目录下。
- package main
- import "fmt"
- func main(){
- fmt.Println("hello")
- }
4) 编译源码并运行
此时我们已经设定了 GOPATH,因此在 Go 语言中可以通过 GOPATH 找到工程的位置。
在命令行中执行如下指令编译源码:
go install hello
编译完成的可执行文件会保存在 $GOPATH/bin 目录下。
在 bin 目录中执行 ./hello,命令行输出如下:
hello world
在多项目工程中使用GOPATH
在很多与 Go 语言相关的书籍、文章中描述的 GOPATH 都是通过修改系统全局的环境变量来实现的。然而,根据笔者多年的 Go 语言使用和实践经验及周边朋友、同事的反馈,这种设置全局 GOPATH 的方法可能会导致当前项目错误引用了其他目录的 Go 源码文件从而造成编译输出错误的版本或编译报出一些无法理解的错误提示。
比如说,将某项目代码保存在 /home/davy/projectA 目录下,将该目录设置为 GOPATH。随着开发进行,需要再次获取一份工程项目的源码,此时源码保存在 /home/davy/projectB 目录下,如果此时需要编译 projectB 目录的项目,但开发者忘记设置 GOPATH 而直接使用命令行编译,则当前的 GOPATH 指向的是 /home/davy/projectA 目录,而不是开发者编译时期望的 projectB 目录。编译完成后,开发者就会将错误的工程版本发布到外网。
因此,建议大家无论是使用命令行或者使用集成开发环境编译 Go 源码时,GOPATH 跟随项目设定。在 Jetbrains 公司的 GoLand 集成开发环境(IDE)中的 GOPATH 设置分为全局 GOPATH 和项目 GOPATH,如下图所示。
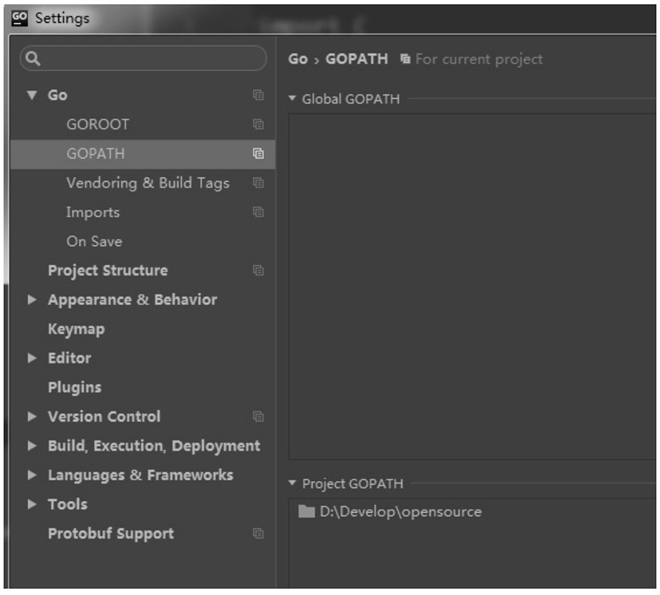
图:全局和项目GOPATH
图中的 Global GOPATH 代表全局 GOPATH,一般来源于系统环境变量中的 GOPATH;Project GOPATH 代表项目所使用的 GOPATH,该设置会被保存在工作目录的 .idea 目录下,不会被设置到环境变量的 GOPATH 中,但会在编译时使用到这个目录。建议在开发时只填写项目 GOPATH,每一个项目尽量只设置一个 GOPATH,不使用多个 GOPATH 和全局的 GOPATH。
提示
Visual Studio 早期在设计时,允许 C++ 语言在全局拥有一个包含路径。当一个工程多个版本的编译,或者两个项目混杂有不同的共享全局包含时,会发生难以察觉的错误。在新版本 Visual Studio 中已经废除了这种全局包含的路径设计,并建议开发者将包含目录与项目关联。
Go 语言中的 GOPATH 也是一种类似全局包含的设计,因此鉴于 Visual Studio 在设计上的失误,建议开发者不要设置全局的 GOPATH,而是随项目设置 GOPATH。
Go语言package
包(package)是多个 Go 源码的集合,是一种高级的代码复用方案,Go 语言默认为我们提供了很多包,如 fmt、os、io 包等,开发者可以根据自己的需要创建自己的包。
包要求在同一个目录下的所有文件的第一行添加如下代码,以标记该文件归属的包:
package 包名
包的特性如下:
- 一个目录下的同级文件归属一个包。
- 包名可以与其目录不同名。
- 包名为 main 的包为应用程序的入口包,编译源码没有 main 包时,将无法编译输出可执行的文件。
Go语言导出包中的标识符
在 Go 语言中,如果想在一个包里引用另外一个包里的标识符(如类型、变量、常量等)时,必须首先将被引用的标识符导出,将要导出的标识符的首字母大写就可以让引用者可以访问这些标识符了。
导出包内标识符
下面代码中包含一系列未导出标识符,它们的首字母都为小写,这些标识符可以在包内自由使用,但是包外无法访问它们,代码如下:
- package mypkg
- var myVar = 100
- const myConst = "hello"
- type myStruct struct {
- }
将 myStruct 和 myConst 首字母大写,导出这些标识符,修改后代码如下:
- package mypkg
- var myVar = 100
- const MyConst = "hello"
- type MyStruct struct {
- }
此时,MyConst 和 MyStruct 可以被外部访问,而 myVar 由于首字母是小写,因此只能在 mypkg 包内使用,不能被外部包引用。
导出结构体及接口成员
在被导出的结构体或接口中,如果它们的字段或方法首字母是大写,外部可以访问这些字段和方法,代码如下:
- type MyStruct struct {
- // 包外可以访问的字段
- ExportedField int
- // 仅限包内访问的字段
- privateField int
- }
- type MyInterface interface {
- // 包外可以访问的方法
- ExportedMethod()
- // 仅限包内访问的方法
- privateMethod()
- }
在代码中,MyStruct 的 ExportedField 和 MyInterface 的 ExportedMethod() 可以被包外访问。
Go语言import导入包
要引用其他包的标识符,可以使用 import 关键字,导入的包名使用双引号包围,包名是从 GOPATH 开始计算的路径,使用/进行路径分隔。
默认导入的写法
导入有两种基本格式,即单行导入和多行导入,两种导入方法的导入代码效果是一致的。
1) 单行导入
单行导入格式如下:
import "包1"
import "包2"
2) 多行导入
当多行导入时,包名在 import 中的顺序不影响导入效果,格式如下:
import(
"包1"
"包2"
…
)
参考代码 8-1 的例子来理解 import 的机制。
代码 8-1 的目录层次如下:
.
└── src
└── chapter08
└── importadd
├── main.go
└── mylib
└── add.go
代码8-1 加函数(具体文件:…/chapter08/importadd/mylib/add.go)
- package mylib
- func Add(a, b int) int {
- return a + b
- }
第 3 行中的 Add() 函数以大写 A 开头,表示将 Add() 函数导出供包外使用。当首字母小写时,为包内使用,包外无法引用到。
add.go 在 mylib 文件夹下,习惯上将文件夹的命名与包名一致,命名为 mylib 包。
代码8-2 导入包(具体文件:…/chapter08/importadd/main.go)
- package main
- import (
- "chapter08/importadd/mylib"
- "fmt"
- )
- func main() {
- fmt.Println(mylib.Add(1, 2))
- }
代码说明如下:
- 第 4 行,导入 chapter08/importadd/mylib 包。
- 第 9 行,使用 mylib 作为包名,并引用 Add() 函数调用。
在命令行中运行下面代码:
export GOPATH=/home/davy/golangbook/code
go install chapter08/importadd
$GOPATH/bin/importadd
命令说明如下:
- 第 1 行,根据你的 GOPATH 不同,设置 GOPATH。
- 第 2 行,使用 go install 指令编译并安装 chapter08/code8-1 到 GOPATH 的 bin 目录下。
- 第 3 行,执行 GOPATH 的 bin 目录下的可执行文件 code8-1。
运行代码,输出结果如下:
3
导入包后自定义引用的包名
在默认导入包的基础上,在导入包路径前添加标识符即可形成自定义引用包,格式如下:
customName "path/to/package"
其中,path/to/package 为要导入的包路径,customName 为自定义的包名。
在 code8-1 的基础上,在 mylib 导入的包名前添加一个标识符,代码如下:
- package main
- import (
- renameLib "chapter08/importadd/mylib"
- "fmt"
- )
- func main() {
- fmt.Println(renameLib.Add(1, 2))
- }
代码说明如下:
- 第 4 行,将 chapter08/importadd/mylib 包导入,并且使用 renameLib 进行引用。
- 第 9 行,使用 renameLib 调用 chapter08/importadd/mylib 包中的 Add() 函数。
匿名导入包——只导入包但不使用包内类型和数值
如果只希望导入包,而不使用任何包内的结构和类型,也不调用包内的任何函数时,可以使用匿名导入包,格式如下:
- import (
- _ "path/to/package"
- )
其中,path/to/package 表示要导入的包名,下画线_表示匿名导入包。
匿名导入的包与其他方式导入包一样会让导入包编译到可执行文件中,同时,导入包也会触发 init() 函数调用。
包在程序启动前的初始化入口:init
在某些需求的设计上需要在程序启动时统一调用程序引用到的所有包的初始化函数,如果需要通过开发者手动调用这些初始化函数,那么这个过程可能会发生错误或者遗漏。我们希望在被引用的包内部,由包的编写者获得代码启动的通知,在程序启动时做一些自己包内代码的初始化工作。
例如,为了提高数学库计算三角函数的执行效率,可以在程序启动时,将三角函数的值提前在内存中建成索引表,外部程序通过查表的方式迅速获得三角函数的值。但是三角函数索引表的初始化函数的调用不希望由每一个外部使用三角函数的开发者调用,如果在三角函数的包内有一个机制可以告诉三角函数包程序何时启动,那么就可以解决初始化的问题。
Go 语言为以上问题提供了一个非常方便的特性:init() 函数。
init() 函数的特性如下:
- 每个源码可以使用 1 个 init() 函数。
- init() 函数会在程序执行前(main() 函数执行前)被自动调用。
- 调用顺序为 main() 中引用的包,以深度优先顺序初始化。
例如,假设有这样的包引用关系:main→A→B→C,那么这些包的 init() 函数调用顺序为:
C.init→B.init→A.init→main
说明:
- 同一个包中的多个 init() 函数的调用顺序不可预期。
- init() 函数不能被其他函数调用。
理解包导入后的init()函数初始化顺序
Go 语言包会从 main 包开始检查其引用的所有包,每个包也可能包含其他的包。Go 编译器由此构建出一个树状的包引用关系,再根据引用顺序决定编译顺序,依次编译这些包的代码。
在运行时,被最后导入的包会最先初始化并调用 init() 函数。
通过下面的代码理解包的初始化顺序。
代码8-3 包导入初始化顺序入口(…/chapter08/pkginit/main.go)
- package main
- import "chapter08/code8-2/pkg1"
- func main() {
- pkg1.ExecPkg1()
- }
代码说明如下:
- 第 3 行,导入 pkg1 包。
- 第 7 行,调用 pkg1 包的 ExecPkg1() 函数。
代码8-4 包导入初始化顺序pkg1(…/chapter08/pkginit/pkg1/pkg1.go)
- package pkg1
- import (
- "chapter08/code8-2/pkg2"
- "fmt"
- )
- func ExecPkg1() {
- fmt.Println("ExecPkg1")
- pkg2.ExecPkg2()
- }
- func init() {
- fmt.Println("pkg1 init")
- }
代码说明如下:
- 第 4 行,导入 pkg2 包。
- 第 8 行,声明 ExecPkg1() 函数。
- 第 12 行,调用 pkg2 包的 ExecPkg2() 函数。
- 第 15 行,在 pkg1 包初始化时,打印 pkg1 init。
代码8-5 包导入初始化顺序pkg2(…/chapter08/pkginit/pkg2/pkg2.go)
- package pkg2
- import "fmt"
- func ExecPkg2() {
- fmt.Println("ExecPkg2")
- }
- func init() {
- fmt.Println("pkg2 init")
- }
代码说明如下:
- 第 5 行,声明 ExecPkg2() 函数。
- 第 10 行,在 pkg2 包初始化时,打印 pkg2 init。
执行代码,输出如下:
pkg2 init
pkg1 init
ExecPkg1
ExecPkg2
Go语言工厂模式自动注册
本例利用包的 init 特性,将 cls1 和 cls2 两个包注册到工厂,使用字符串创建这两个注册好的结构实例。
完整代码的结构如下:
.
└── src
└── chapter08
└── clsfactory
├── main.go
└── base
└── factory.go
└── cls1
└── reg.go
└── cls2
└── reg.go
类工厂(具体文件:…/chapter08/clsfactory/base/factory.go)
- package base
- // 类接口
- type Class interface {
- Do()
- }
- var (
- // 保存注册好的工厂信息
- factoryByName = make(map[string]func() Class)
- )
- // 注册一个类生成工厂
- func Register(name string, factory func() Class) {
- factoryByName[name] = factory
- }
- // 根据名称创建对应的类
- func Create(name string) Class {
- if f, ok := factoryByName[name]; ok {
- return f()
- } else {
- panic("name not found")
- }
- }
这个包叫base,负责处理注册和使用工厂的基础代码,该包不会引用任何外部的包。
以下是对代码的说明:
- 第 4 行定义了“产品”:类。
- 第 10 行使用了一个 map 保存注册的工厂信息。
- 第 14 行提供给工厂方注册使用,所谓的“工厂”,就是一个定义为
func() Class的普通函数,调用此函数,创建一个类实例,实现的工厂内部结构体会实现 Class 接口。 - 第 19 行定义通过名字创建类实例的函数,该函数会在注册好后调用。
- 第 20 行在已经注册的信息中查找名字对应的工厂函数,找到后,在第 21 行调用并返回接口。
- 第 23 行是如果创建的名字没有找到时,报错。
类1及注册代码(具体文件:…/chapter08/clsfactory/cls1/reg.go)
- package cls1
- import (
- "chapter08/clsfactory/base"
- "fmt"
- )
- // 定义类1
- type Class1 struct {
- }
- // 实现Class接口
- func (c *Class1) Do() {
- fmt.Println("Class1")
- }
- func init() {
- // 在启动时注册类1工厂
- base.Register("Class1", func() base.Class {
- return new(Class1)
- })
- }
上面的代码展示了Class1的工厂及产品定义过程。
- 第 9~15 行定义 Class1 结构,该结构实现了 base 中的 Class 接口。
- 第 20 行,Class1 结构的实例化过程叫 Class1 的工厂,使用 base.Register() 函数在 init() 函数被调用时与一个字符串关联,这样,方便以后通过名字重新调用该函数并创建实例。
类2及注册代码(具体文件:…/chapter08/clsfactory/cls2/reg.go)
- package cls2
- import (
- "chapter08/clsfactory/base"
- "fmt"
- )
- // 定义类2
- type Class2 struct {
- }
- // 实现Class接口
- func (c *Class2) Do() {
- fmt.Println("Class2")
- }
- func init() {
- // 在启动时注册类2工厂
- base.Register("Class2", func() base.Class {
- return new(Class2)
- })
- }
Class2 的注册与 Class1 的定义和注册过程类似。
类工程主流程(具体文件:…/chapter08/clsfactory/main.go)
- package main
- import (
- "chapter08/clsfactory/base"
- _ "chapter08/clsfactory/cls1" // 匿名引用cls1包, 自动注册
- _ "chapter08/clsfactory/cls2" // 匿名引用cls2包, 自动注册
- )
- func main() {
- // 根据字符串动态创建一个Class1实例
- c1 := base.Create("Class1")
- c1.Do()
- // 根据字符串动态创建一个Class2实例
- c2 := base.Create("Class2")
- c2.Do()
- }
下面是对代码的说明:
- 第 5 和第 6 行使用匿名引用方法导入了 cls1 和 cls2 两个包。在 main() 函数调用前,这两个包的 init() 函数会被自动调用,从而自动注册 Class1 和 Class2。
- 第 12 和第 16 行,通过 base.Create() 方法查找字符串对应的类注册信息,调用工厂方法进行实例创建。
- 第 13 和第 17 行,调用类的方法。
执行下面的指令进行编译:
export GOPATH=/home/davy/golangbook/code
go install chapter08/clsfactory
$GOPATH/bin/clsfactory
代码输出如下:
Class1
Class2
Go第八篇之包的使用的更多相关文章
- Python之路【第十八篇】:Web框架们
Python之路[第十八篇]:Web框架们 Python的WEB框架 Bottle Bottle是一个快速.简洁.轻量级的基于WSIG的微型Web框架,此框架只由一个 .py 文件,除了Pytho ...
- 第八篇 Integration Services:高级工作流管理
本篇文章是Integration Services系列的第八篇,详细内容请参考原文. 简介在前面两篇文章,我们创建了一个新的SSIS包,学习了SSIS中的脚本任务和优先约束,并检查包的MaxConcu ...
- 【强烈强烈推荐】《ORACLE PL/SQL编程详解》全原创(共八篇)--系列文章导航
原文:[强烈强烈推荐]<ORACLE PL/SQL编程详解>全原创(共八篇)--系列文章导航 <ORACLE PL/SQL编程详解> 系列文章目录导航 ——通过知识共享树立个人 ...
- 【译】第八篇 Integration Services:高级工作流管理
本篇文章是Integration Services系列的第八篇,详细内容请参考原文. 简介在前面两篇文章,我们创建了一个新的SSIS包,学习了SSIS中的脚本任务和优先约束,并检查包的MaxConcu ...
- 跟我学SpringCloud | 第八篇:Spring Cloud Bus 消息总线
SpringCloud系列教程 | 第八篇:Spring Cloud Bus 消息总线 Springboot: 2.1.6.RELEASE SpringCloud: Greenwich.SR1 如无特 ...
- Spring Cloud实战 | 最八篇:Spring Cloud +Spring Security OAuth2+ Axios前后端分离模式下无感刷新实现JWT续期
一. 前言 记得上一篇Spring Cloud的文章关于如何使JWT失效进行了理论结合代码实践的说明,想当然的以为那篇会是基于Spring Cloud统一认证架构系列的最终篇.但关于JWT另外还有一个 ...
- 【译】SQL Server索引进阶第八篇:唯一索引
原文:[译]SQL Server索引进阶第八篇:唯一索引 索引设计是数据库设计中比较重要的一个环节,对数据库的性能其中至关重要的作用,但是索引的设计却又不是那么容易的事情,性能也不是那么轻易就 ...
- 解剖SQLSERVER 第八篇 OrcaMDF 现在支持多数据文件的数据库(译)
解剖SQLSERVER 第八篇 OrcaMDF 现在支持多数据文件的数据库(译) http://improve.dk/orcamdf-now-supports-databases-with-mult ...
- 第八篇 :微信公众平台开发实战Java版之如何网页授权获取用户基本信息
第一部分:微信授权获取基本信息的介绍 我们首先来看看官方的文档怎么说: 如果用户在微信客户端中访问第三方网页,公众号可以通过微信网页授权机制,来获取用户基本信息,进而实现业务逻辑. 关于网页授权回调域 ...
随机推荐
- idea导出war包并在tomcat上部署
生成war包 (一)进入项目配置页面 然后到达: (二)选择 设置好路径 然后apply (三)生成 然后再指定的目录就可以看见war包了. 部署到tomcat上 (一)将war包拷贝到tomcat的 ...
- 源代码下载 作者:王先荣(Xianrong Wang)
作者:王先荣(Xianrong Wang) 下面是我的一些源代码: 1. 图像处理学习系列源代码——包括该系列文章的几乎所有代码: 1.5. 图像处理学习系列中用到的dll文件包——将这个解压缩之后放 ...
- numpy中的广播(Broadcasting)
Numpy的Universal functions 中要求输入的数组shape是一致的,当数组的shape不相等的时候,则会使用广播机制,调整数组使得shape一样,满足规则,则可以运算,否则就出错 ...
- [lr & ps] 色彩空间管理
色彩空间 • 定义 色彩空间,Color Space,又称作色域.在色彩学中,人们建立了许多色彩模型,以一维.二维.三维甚至四维空间坐标来表示某一色彩,这种坐标系统所能定义的色彩范围即色彩空间.我们经 ...
- php发送 与接收流文件
PHP 发送与接收流文件 sendStreamFile.php 把文件以流的形式发送 receiveStreamFile.php 接收流文件并保存到本地 sendStreamFile.php < ...
- Linux系统——MySQL基础(三)
### MySQL主从复制实践#### 主从复制实践准备(1)主从复制数据库实战环境准备MySQL主从复制实践对环境的要求比较简单,可以是单机单数据库多实例的环境,也可以是两台服务器,每个机器一个独立 ...
- discuz formhash
class.core.php中 $this->var['formhash'] = formhash();define('FORMHASH', $this->var['formhash']) ...
- 学习Css补充知识点
1.text-transform: capitalize;UpperCase等 2.border-size:box,边框在定义的宽高范围内画, content默认,在宽高外画.元互的宽高只指内容 3 ...
- excel输入数字变成特殊符号问题
问题,在单元格里输入数字,结果变成文件夹类型的小图片或特殊符号了,原因是字体为Wingdings,将其设为Times New Roman即可
- hdu6000 Wash ccpc-20162017-finals B Wash
地址:http://acm.split.hdu.edu.cn/showproblem.php?pid=6000 题目: Wash Time Limit: 20000/10000 MS (Java/Ot ...