python调用mediainfo工具批量提取视频信息
写了2个脚本,分别是v1版本和v2版本
都是python调用mediainfo工具提取视频元数据信息
v1版本是使用pycharm中测试运行的,指定了视频路径
v2版本是最终交付给运营运行的,会把v2版本打成exe运行
先看v1版本
import os,subprocess,json,re,locale,sys
import xlwt,time,shutil
#获取当前文件所在绝对目录路径
# this_path=os.path.abspath('.')
# print('当前路径为----',this_path)
# dir_path=this_path
#视频文件所在目录
dir_path='I:\\3分钟便当'
# print(os.listdir(this_path))
print('---------------------------------')
print('--------------程序马上开始----------------')
# dir_path=this_path
#定义个列表存放每个文件绝对路径,便于后期操作
init_list=[] # dir_path='F:\\玩具屋总视频'
#创建个方法,统计每个文件路径,并追加列表中。这里注释掉了递归,不获取子目录了,只获取dir_path下面的视频
def get_all_file(dir_path,init_list):
for file in os.listdir(dir_path):
# print(file)
filepath=os.path.join(dir_path,file)
# print(filepath)
if os.path.isdir(filepath):
print('遇到子目录---%s---此版本暂不提取子目录视频信息--'%(filepath))
time.sleep(2)
# get_all_file(filepath)
else:
if not file.endswith('exe'):
init_list.append(filepath)
return init_list
#执行上面方法,把每个文件绝对路径追加到列表中
file_list=get_all_file(dir_path,init_list)
print("文件读取完毕-----3秒后开始获取视频详细信息------------")
time.sleep(3) #定义个方法,获取单个media文件的元数据,返回为字典数据
#此程序核心是调用了mediainfo工具来提取视频信息的
def get_media_info(file):
pname='D:\mediainfo_i386\MediaInfo.exe "%s" --Output=JSON'%(file)
result=subprocess.Popen(pname,shell=False,stdout=subprocess.PIPE).stdout
list_std=result.readlines()
str_tmp=''
for item in list_std:
str_tmp+=bytes.decode(item.strip())
json_data=json.loads(str_tmp)
return json_data #定义个方法传递字典数据,返回自己想要的字段数据,返回值列表
def get_dict_data(json_data):
#获取文件大小
filesize=json_data['media']['track'][0]['FileSize']
#获取码率
malv=json_data['media']['track'][0]['OverallBitRate'][0:4]
#获取播放时长
duration=json_data['media']['track'][0]['Duration'].split('.')[0]
#获取文件类型
file_format=json_data['media']['track'][0]['Format']
#获取帧宽
samp_width=json_data['media']['track'][1]['Sampled_Width']
#获取帧高
samp_height=json_data['media']['track'][1]['Sampled_Height']
return [filesize,malv,duration,file_format,samp_width,samp_height] #定义个方法,获取文件名,它是key,它的value就是目标列表,返回值是个字典,参数是文件列表
dict_all={}
#定义个日志存提取失败视频文件名
f_fail=open('提取失败日志.log','a',encoding='utf-8') # 追加模式
def get_all_dict(file_list,f_fail):
for file in file_list:
filename=os.path.split(file)[1]
print(filename)
time.sleep(0.1)
try:
info_list=get_dict_data(get_media_info(file))
dict_all[filename]=info_list
except Exception as e:
print(filename,'------提取此文件信息失败---------')
f_fail.write(filename+'\r\n')
f_fail.close() get_all_dict(file_list,f_fail)
# for item in dict_all:
# print(item,dict_all[item]) #创建一个excel表存放文件路径信息,第一列是目录,第二列是文件名
wb = xlwt.Workbook()
sh = wb.add_sheet('元数据')
#写第一行
row_count=0
sh.write(row_count,0,"文件名")
sh.write(row_count,1,"文件大小")
sh.write(row_count,2,"码率")
sh.write(row_count,3,"总时长")
sh.write(row_count,4,"视频格式")
sh.write(row_count,5,"帧宽")
sh.write(row_count,6,"帧高") #批量写入视频信息
row_count=1
for item in dict_all:
sh.write(row_count,0,item)
sh.write(row_count,1,dict_all[item][0])
sh.write(row_count,2,dict_all[item][1])
sh.write(row_count,3,dict_all[item][2])
sh.write(row_count,4,dict_all[item][3])
sh.write(row_count,5,dict_all[item][4])
sh.write(row_count,6,dict_all[item][5])
row_count+=1
#
wb.save("元数据统计.xls")
#
在看v2版本
v2版本是对当前目录下的视频进行提取
import os,subprocess,json,re,locale,sys
import xlwt,time,shutil
#获取当前文件所在绝对目录路径
this_path=os.path.abspath('.')
print('当前路径为----',this_path)
dir_path=this_path
# print(os.listdir(this_path))
print('---------------------------------')
print('--------------程序马上开始----------------')
# dir_path=this_path
#定义个列表存放每个文件路径,便于后期操作
init_list=[]
# dir_path='I:\\3分钟便当'
# dir_path='F:\\玩具屋总视频'
#创建个方法,统计每个文件路径,并追加列表中。用到了递归,这里不获取子目录了
def get_all_file(dir_path,init_list):
for file in os.listdir(dir_path):
# print(file)
filepath=os.path.join(dir_path,file)
# print(filepath)
if os.path.isdir(filepath):
print('遇到子目录---%s---此版本暂不提取子目录视频信息--'%(filepath))
time.sleep(2)
# get_all_file(filepath)
else:
if not file.endswith('exe'):
init_list.append(filepath)
return init_list
#执行上面方法,把每个文件绝对路径追加到列表中
file_list=get_all_file(dir_path,init_list)
print("文件读取完毕-----3秒后开始获取视频详细信息------------")
time.sleep(3) #定义个方法,获取单个media文件的元数据,返回为字典数据
def get_media_info(file):
pname='D:\mediainfo_i386\MediaInfo.exe "%s" --Output=JSON'%(file)
result=subprocess.Popen(pname,shell=False,stdout=subprocess.PIPE).stdout
list_std=result.readlines()
str_tmp=''
for item in list_std:
str_tmp+=bytes.decode(item.strip())
json_data=json.loads(str_tmp)
return json_data #定义个方法传递字典数据,返回自己想要的字段数据,返回值列表
def get_dict_data(json_data):
#获取文件大小
filesize=json_data['media']['track'][0]['FileSize']
#获取码率
malv=json_data['media']['track'][0]['OverallBitRate'][0:4]
#获取播放时长
duration=json_data['media']['track'][0]['Duration'].split('.')[0]
#获取文件类型
file_format=json_data['media']['track'][0]['Format']
#获取帧宽
samp_width=json_data['media']['track'][1]['Sampled_Width']
#获取帧高
samp_height=json_data['media']['track'][1]['Sampled_Height']
return [filesize,malv,duration,file_format,samp_width,samp_height] #定义个方法,获取文件名,它是key,它的value就是目标列表,返回值是个字典,参数是文件列表
dict_all={}
f_fail=open('提取失败日志.log','a',encoding='utf-8') # 追加模式
def get_all_dict(file_list,f_fail):
for file in file_list:
filename=os.path.split(file)[1]
print(filename)
time.sleep(0.1)
try:
info_list=get_dict_data(get_media_info(file))
dict_all[filename]=info_list
except Exception as e:
print(filename,'------提取此文件信息失败---------')
f_fail.write(filename+'\r\n')
f_fail.close() get_all_dict(file_list,f_fail)
# for item in dict_all:
# print(item,dict_all[item]) #创建一个excel表存放文件路径信息,第一列是目录,第二列是文件名
wb = xlwt.Workbook()
sh = wb.add_sheet('元数据')
#写第一行
row_count=0
sh.write(row_count,0,"文件名")
sh.write(row_count,1,"文件大小")
sh.write(row_count,2,"码率")
sh.write(row_count,3,"总时长")
sh.write(row_count,4,"视频格式")
sh.write(row_count,5,"帧宽")
sh.write(row_count,6,"帧高") row_count=1
for item in dict_all:
sh.write(row_count,0,item)
sh.write(row_count,1,dict_all[item][0])
sh.write(row_count,2,dict_all[item][1])
sh.write(row_count,3,dict_all[item][2])
sh.write(row_count,4,dict_all[item][3])
sh.write(row_count,5,dict_all[item][4])
sh.write(row_count,6,dict_all[item][5])
row_count+=1
#
wb.save("元数据统计.xls")
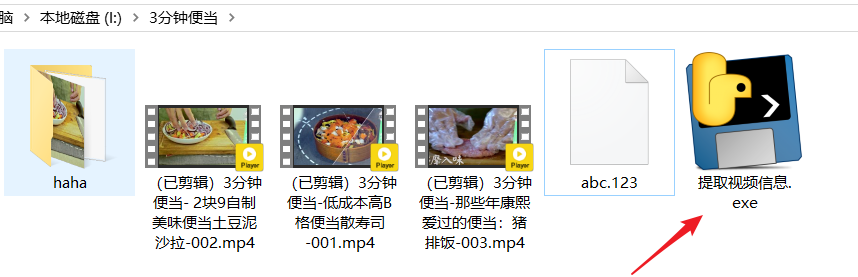
把v2版本打成exe文件
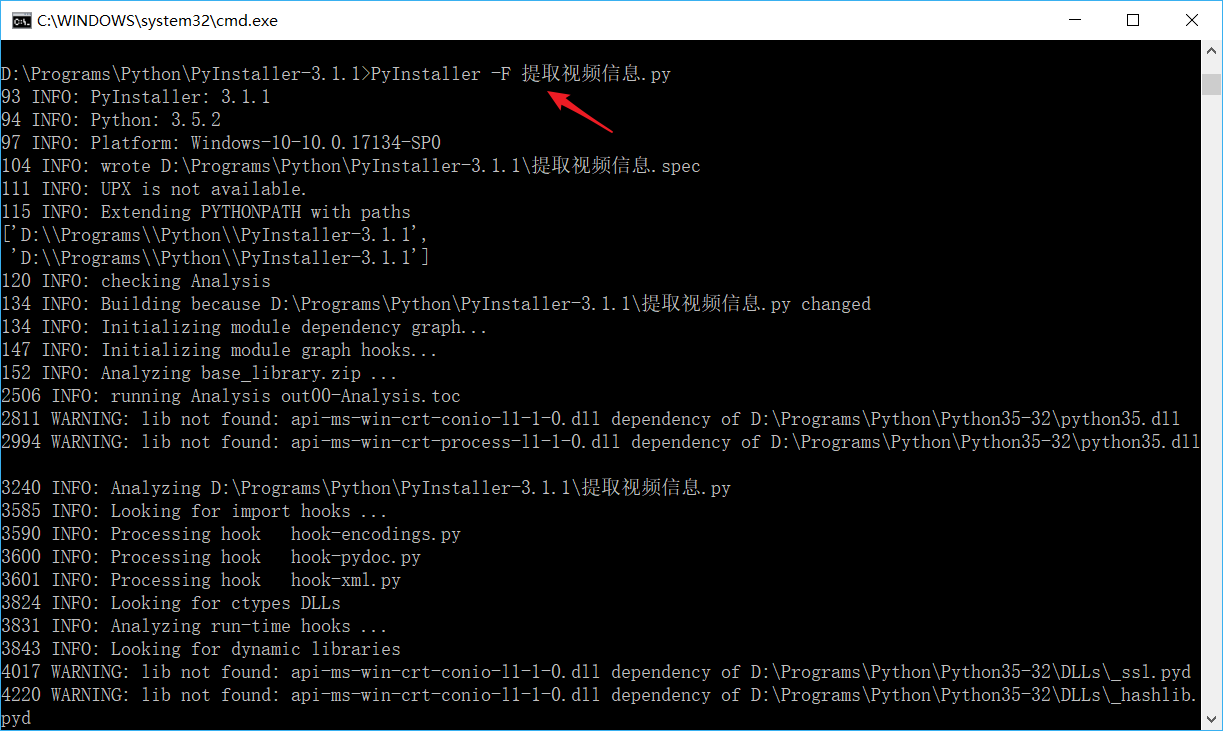
如下路径下拷贝此exe文件

这个程序交付给运营同事即可
测试和验证部分
使用方式,把程序放在视频同级目录下
按照代码缩写,如果视频运行成功:
1、此程序不会对haha目录进行处理
2、对于无法识别的文件比如abc.123(可能不是视频文件,或者已经损坏的视频文件),此程序会记录日志,同时程序正常运行不会中断
3、程序运行之后会有一个失败日志.log文件,记录了提取信息失败的视频名,同时把提取成功的视频文件放在“元数据统计.xls”中
测试验证下
双击运行
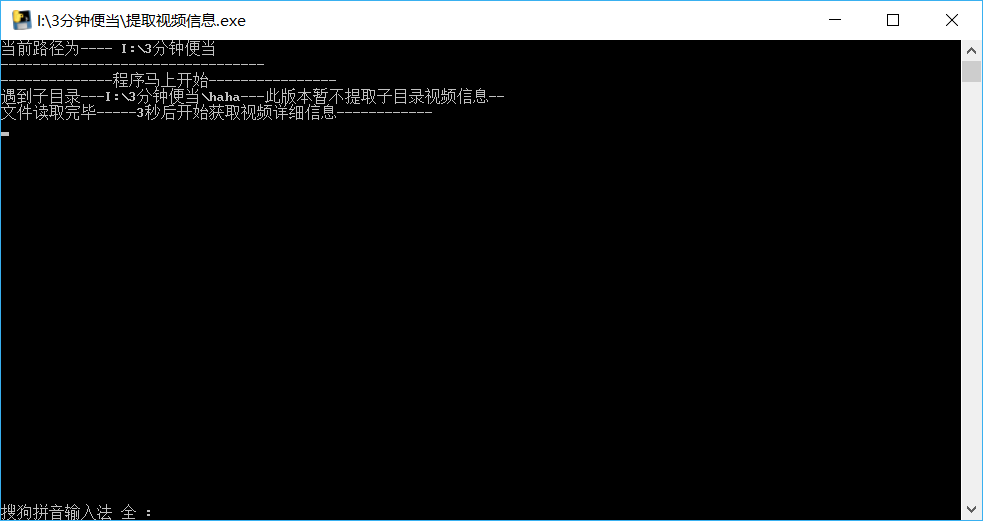
运行结束
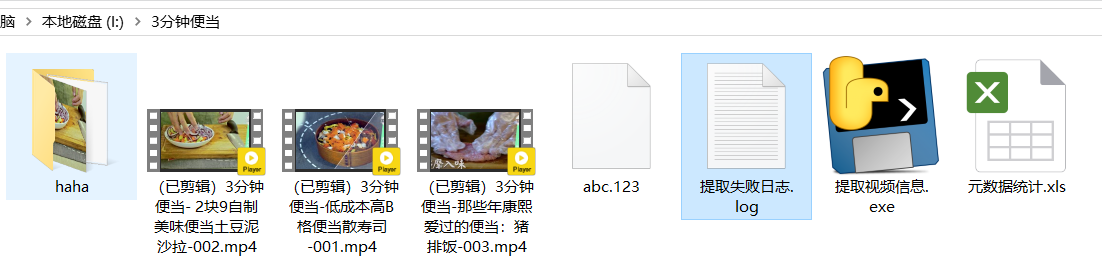

excel表信息
文件大小是字节,如果想显示为MB或者GB,使用excel表内置的公式即可处理
有很多字段,码率,时长等。这里因为运营只需要如下字段,就提取了这些

如果把此exe程序交付给运营同事使用,需要把D盘那个mediainfo_i386文件夹一起交给他们,此文件加必须放在D盘
python调用mediainfo工具批量提取视频信息的更多相关文章
- python调用HEG工具批量处理MODIS数据
下面的代码主要用于使用python语言调用NASA官方的MODIS处理工具HEG进行投影坐标转换与重采样批量处理 主要参考 HEG的用户手册:https://newsroom.gsfc.nasa.go ...
- Python调用ffpmeg和ffprobe处理视频文件
需求: 运营有若干批次的视频.有上千个,视频文件,有mp4格式的,有ts格式的 现在有需要去掉视频文件片头和片尾的批量操作需求. 比如 文件夹A下面的视频去掉片尾10秒 文件夹B下面的视频去掉片头6秒 ...
- 使用mediainfo工具统计每个视频文件(媒体文件)播放时长
需求 1.运营那边需要统计大量视频文件的播放时长,并汇总记录到excel表中,问我有什么方法搞定 这边搜索了很多统计媒体文件时长的,主要有以下几种 1.使用java获取 2.使用python获取 3. ...
- 『Python』Python 调用 ZoomEye API 批量获取目标网站IP
#### 20160712 更新 原API的访问方式是以 HTTP 的方式访问的,根据官网最新文档,现在已经修改成 HTTPS 方式,测试可以正常使用API了. 0x 00 前言 ZoomEye 的 ...
- python调用aapt工具直接获取包名和tagertSdkversion
背景: 每次海外游戏上架都需要符合google的上架规则,其中适配方面tagetSdkversion有硬性要求,比如需要适配安卓q就需要tagetSdkversion达到28,水平太渣的我每次调用aa ...
- python 调用zabbix api实现查询主机信息,输出所有主机ip
之前发现搜索出来的主机调用zabbix api信息都不是那么明确,后来通过zabbix官方文档,查到想要的api信息,随后写一篇自己这次项目中用到的api. #!/usr/bin/env python ...
- 制作大漠字库并用python调用大漠工具方法来识别文字
1.制作字库 1.截取需要的图片 2.这里截取了"火狐主页"四个字,接下来抓取文字的颜色 3.颜色由是由三个部分组成,即R G B其中的R是由00-FF(16进制) 即0-255个 ...
- bat文件调用cmd命令批量提取文件夹中的文件名(批量修改文件扩展名)
前言: 在平时的工作中,经常需要批量统计文件和数据,如果逐个统计的话太耗时,而且容易出错那么有没有什么快速的方法呢,这里给大家介绍一种简单高效的方法. 方法: 1.打开CMD命令: 按下 Ctrl+R ...
- Python调用zabbix API批量添加主机 (读取Excel)
本文转载自:http://blog.mreald.com/178 Zabbix可以通过自发现添加主机,不过有时候不准确,通过API添加会更加准确! 脚本使用的跟zabbix相关的内容.参考的是zabb ...
随机推荐
- 线程(四)之Queue
SynchronousQueue SynchronousQueue是无界的,是一种无缓冲的等待队列,但是由于该Queue本身的特性,在某次添加元素后必须等待其他线程取走后才能继续添加:可以认为Sync ...
- MATLAB绘图功能(2) 二维底层绘图修饰
文末源代码 部分源代码 % x=0:0.1:2*pi; % y=sin(x); % plot(x,y); % line对象 % h = line([-pi:0.01:pi],sin([-pi:0. ...
- spring 配置Value常量(不支持到static上)
spring 配置Value常量(不支持到static上) 看代码吧,语言表达有问题. package com.variflight.xzair.rest.constant; import org.s ...
- Docker Image管理学习笔记,ZT
Docker Image管理学习笔记 http://blog.csdn.net/junjun16818/article/details/38423391
- CKEditor富文本编辑器
CKEditor 富文本即具备丰富样式格式的文本.在运营后台,运营人员需要录入课程的相关描述,可以是包含了HTML语法格式的字符串.为了快速简单的让用户能够在页面中编辑带格式的文本,我们引入富文本编辑 ...
- Luffy之注册认证(容联云通讯短信验证)
用户的注册认证 前端显示注册页面并调整首页头部和登陆页面的注册按钮的链接. 注册页面Register,主要是通过登录页面进行改成而成. 先构造前端页面 <template> <div ...
- Android:手把手教你 实现Activity 与 Fragment 相互通信,发送字符串信息(含Demo)
前言Activity 与 Fragment 的使用在Android开发中非常多今天,我将主要讲解 Activity 与 Fragment 如何进行通信,实际上是要解决两个问题: Activity 如何 ...
- [LeetCode]题1:two sum
Example: Given nums = [2, 7, 11, 15], target = 9, Because nums[0] + nums[1] = 2 + 7 = 9, return [0 ...
- centos7下stf安装介绍(一)----环境搭建
重要:node version需要8.x.x 介绍 stf 全称 Smartphone Test Farm ,一款WEB 端移动设备批量管理工具(Remote control all your Sma ...
- Hashmap的学习整理
这是我大致了解Hashmap的第一个博客:https://www.cnblogs.com/chengxiao/p/6059914.html 我将摘录里面的重点: 哈希表的主干就是数组 存储位置 = f ...