Improved GAN
https://www.bilibili.com/video/av9770302/?p=16
从之前讲的basic gan延伸到unified framework,到WGAN
再到通过WGAN进行Generation和Transformation

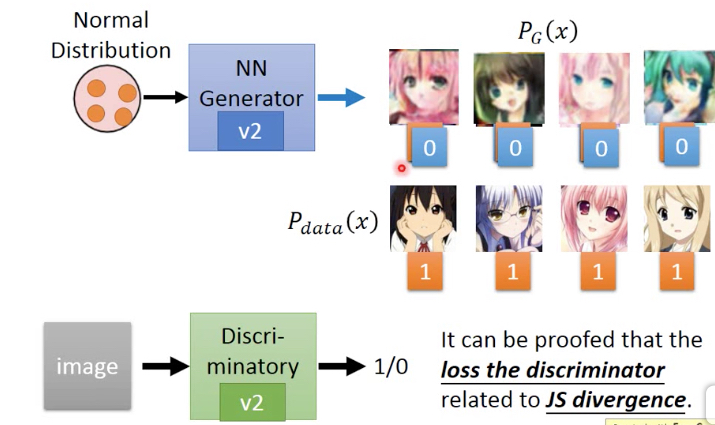
复习一下GAN,
首先我们有一个目标,target分布,Pdata,
蓝色部分表示Pdata高,即从这部分取出的x都是符合预期的,比如这里的头像图片
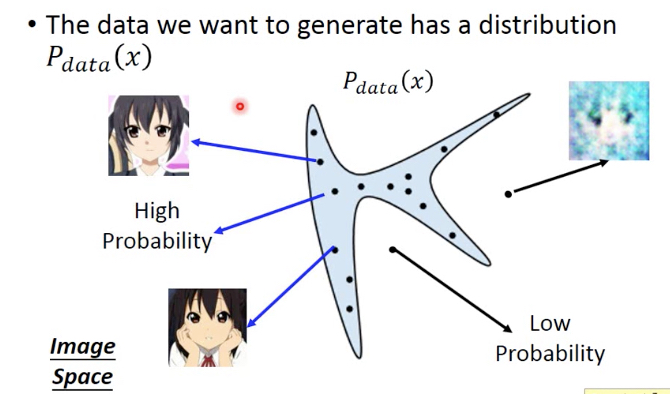
GAN的目的就是训练一个generator nn,让它的输出尽量接近Pdata分布
generator的输入一般都是normal distribution,输出接近Pdata,那么就意味着generator输出的x,高概率会落在蓝色区域,即我们想看到的图片
但这里的问题是,PG是算不出来的,其实这里Pdata我们也是不知道的,我们只有一些训练集,比如一批头像的图片
所以只有用sample的方式来训练
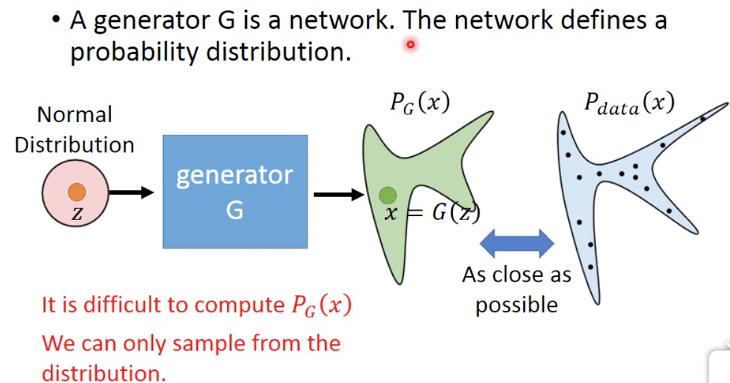
下面给出如何通过sample来训练,
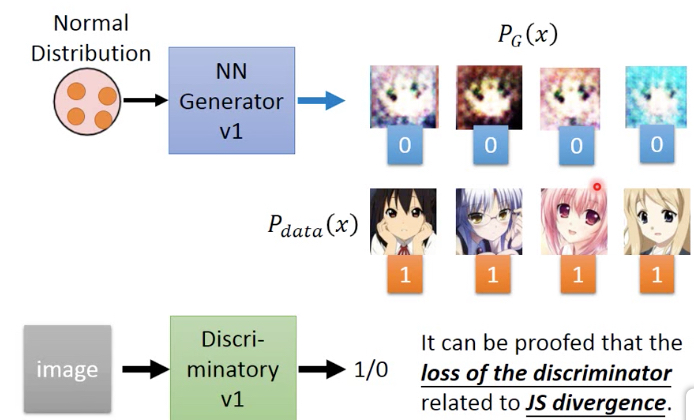
先随机从v1 generator中sample 4张图片作为false,从训练集中取4个作为true,来训练v1 discriminator
然后固定V1 discriminator,来训练出V2 generator
然后固定V1 discriminator,来训练出V2 generator,它产生的x,v1 discriminator都会判true
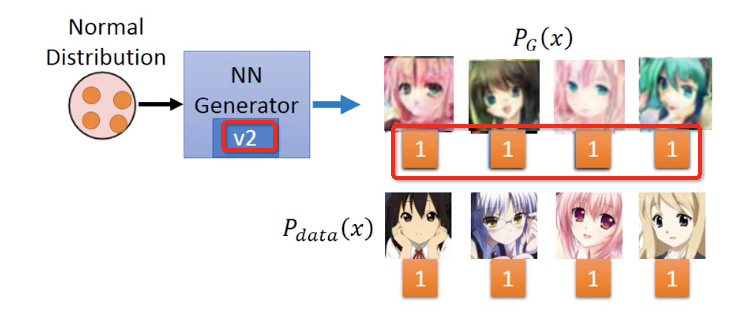
再训练产生V2 discriminator,让V2 generator生成的x,都被判false
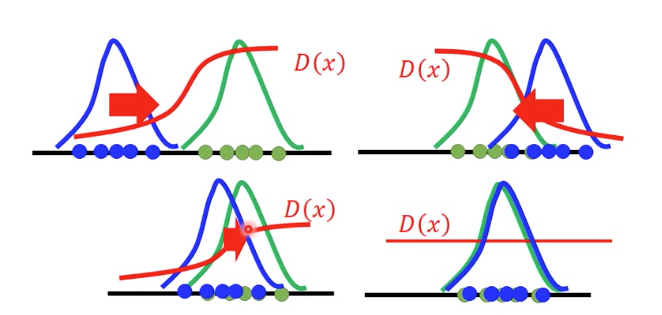
下面的图更形象的表示这一过程,
需要注意的是PG为蓝色曲线,调整generator nn的参数让它close Pdata,这个过程不是渐进的过程,而是一个反复的过程
nn的参数很难调的刚合适,往往或调过了,所以真实的过程是一个反复震荡close的过程
直到两者重合,discriminator就完全无法区分
简单的列出算法,
discriminator训练多次来max V,intuitive的理解V,让D(x)尽量大,即让训练集数据被判true,让D(x~)尽量小,即让generator生成的数据被判false
generator仅仅训练一次来min V,前面一项和generator无关所以不用考虑,min V,就要max D(G(z)),即让generator生成的数据尽量被判true

Unified Framework
下面来学习unifed framework,分成3部分
f-divergence
这篇论文称为f-Gan,Gan中Discriminator和JS-Divergence相关,其实可以任何f-divergence相关

f-divergence就可以用来衡量两个分布的相似度
这个定义对于函数f有两个约束,
其中f(1)=0,当p和q分布相同时,divergence就会取到0
f是convex,可以证明D的最小值就是0,下面通过jensen不等式,很容易证明

举几个f-divergence的例子,

Fenchel Conjugate(共轭)
对于每个convex函数,都存在一个对应的conjugate函数f*
定义是给定一个t,需要调整x,使得后面的式子最大,其中x需要在f的定义域中
这里假设先固定x,这样蓝框中的部分就变成线性函数,对不同的x就是不同的直线,现在对于某个给定t,只是找出最大的那个交点
从图上可以看出,f*也是convex的
右边举个例子,对于xlogx,他的f*就是exponential,从图上也能intuitive的看出


计算过程如下,maximizing就是求微分=0
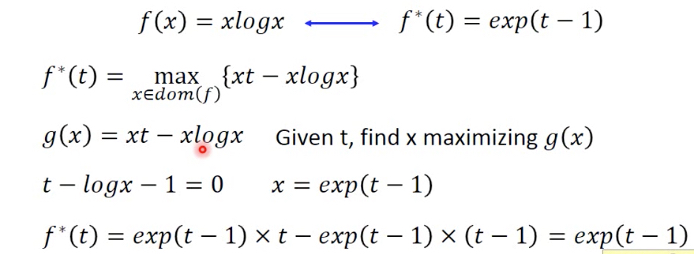
这里有个重要的特性,就是f** = f,即

代入f-divergence的公式,得到
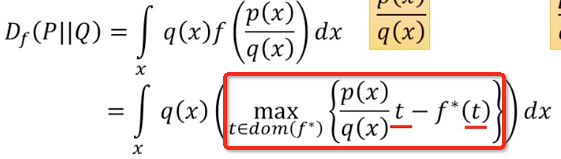
这个红框中的式子,给定x,找到一个t可以使得它取到最大值,那这个式子可以有个lowbound
如果随便给一个t,那么得到值一定是小于等于这个最大值
假设有个函数D,输入这个x,输出t,就有,因为对于任意一个D,从x算出的t,不一定是可以取到最大值的t
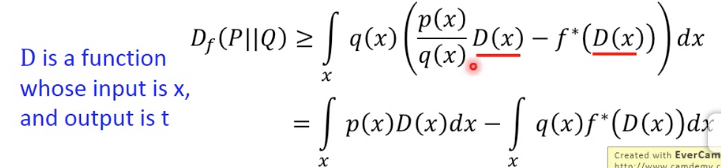
任意D代表下届,那么我们只要调整D,使得让其max,就可以逼近真实值
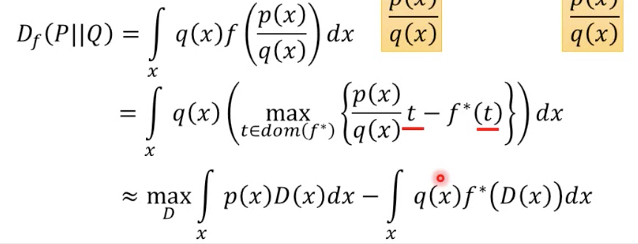
把上面的式子中,代入Pdata和PG,就得到Pdata和Pg的f-divergence的定义
如果我们要找一个PG,和Pdata尽量相似,也就是要找一个G,使得Df最小,于是得到G*
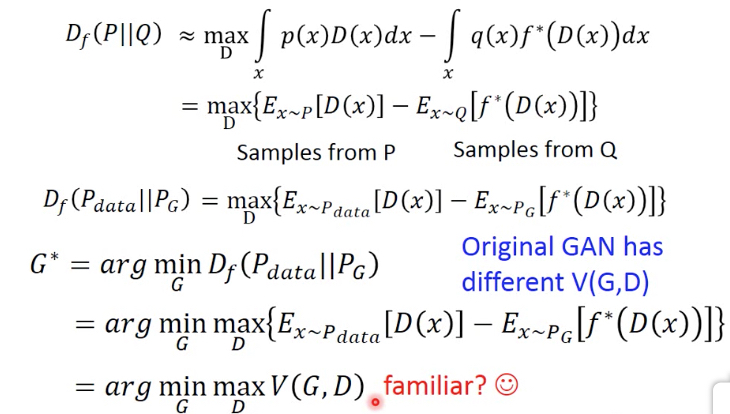
推导到这里就可以看出,之前GAN的V是怎么来的,这里用不同的f-divergence,即f不同,就可以得到不同的V
之前的GAN只是一种特殊形式罢了
所以这里就得到一种GAN的unified framework,这里列出各种不同的f-divergence

WGAN
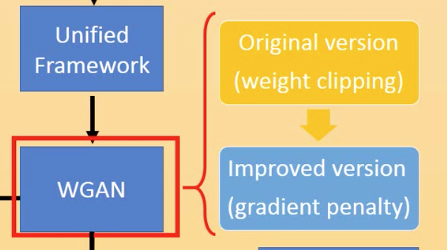
WGAN的论文,简单说,就是用earth mover's distance,或者wasserstein distance来衡量分布之间的差异

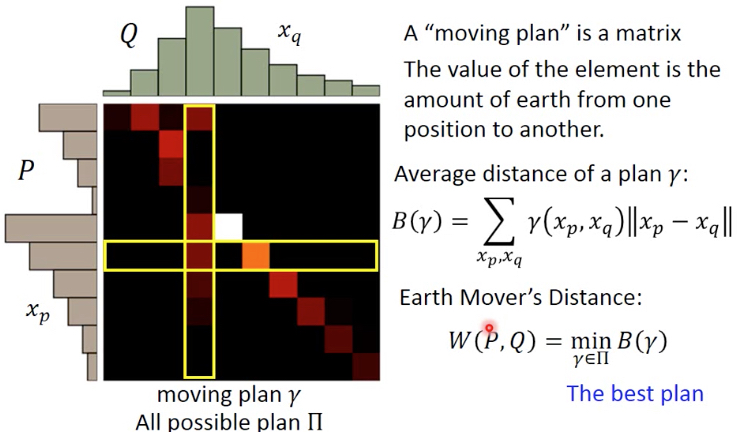
什么是earth mover's distance?
把P分布变成Q分布,有很多种moving plan,其中最小的称为earth mover's distance,如右图


形式化的表示,plan r可以表示成一个矩阵,每个value表示在这个位置上,需要从P移动多少到Q
这里定义出B(r),表示某个plan的平均距离
那么Earch Mover‘s Distance就是所有plan中最小的那个,可以看出算这个distance是很麻烦的,因为要先求一个最优化问题
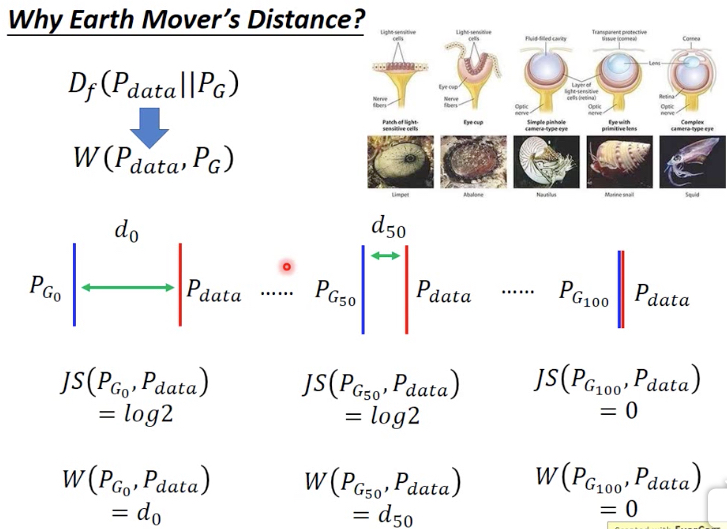
那Earch Mover‘s Distance有什么用,为什么要用它来替代f-divergence来衡量分布间的差异?
f-divergence计算差异的时候,是看两个分布是否有相同的部分,交集,这样的问题就是很难train,因为下面的例子,Pg0,Pg50的JS-divergence都是一样的,没有梯度
说明这样衡量两个分布的差异,不科学;所以用Earch Mover‘s Distance
虽然Pg0和Pg50都不相交,但是他们之间的距离是变小的,这样更容易训练
回到GAN Framework
之前说,从f-divergence是可以推导出GAN的公式的
那么现在从f-divergence换到Earch Mover‘s Distance,会是怎么样?
WGAN的论文说明,也可以从Earch Mover‘s Distance推导出下面的公式
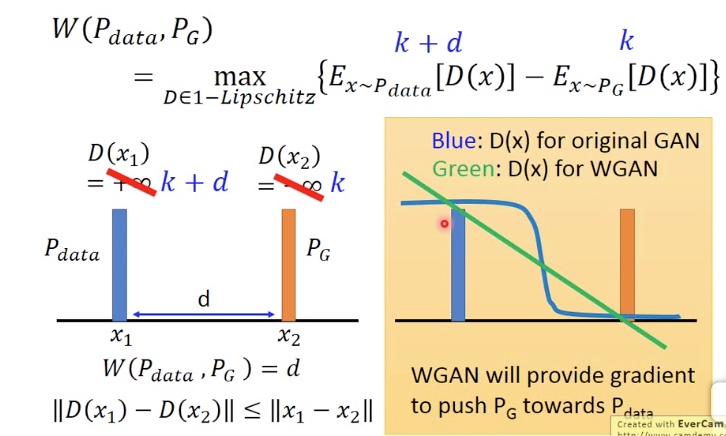
找出一个function D,让Pdata中抽样的x的D(x)尽量的大,而Pg中抽样的x的D(x)尽量的小
但这里D有个约束,必须是1-lipschitz
从lipschitz的定义可以看出,这样的函数,变化比较缓慢,即f(x)的变化要小于x的变化
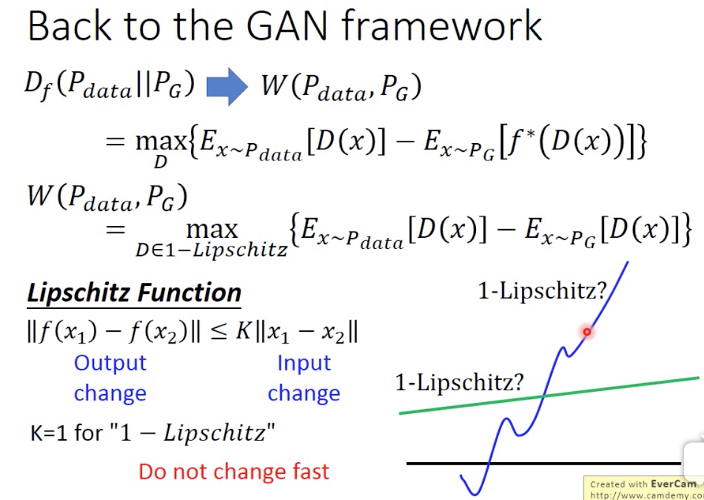
为何要加上1-lipschitz的约束?
因为如果不加,D会倾向于给D(x1) 正无穷,而D(x2)负无穷
而现在加了这个约束,x1和x2间的距离为d,那么D(x1)和D(x2)间的距离不能大于d
对于GAN,D(x)是一个二元分类器,输出是sigmod,在两端几乎没有梯度
而WGAN,D(x)是一个直线,训练起来更简单

那么这个式子怎么求解?
关键是1-lipschitz的约束,怎么处理
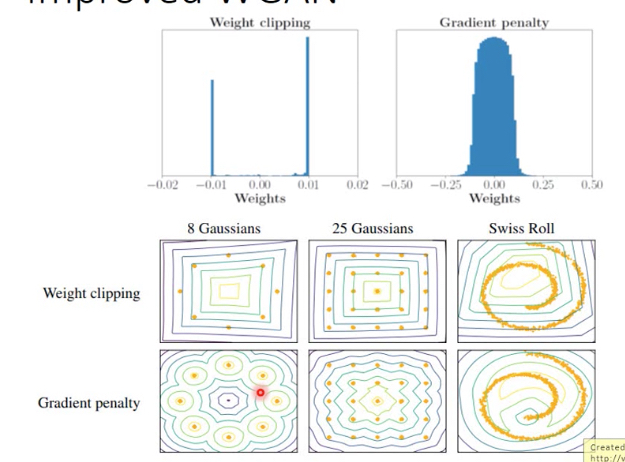
这里的方法是weight clipping,就是限制w的参数在[-c,c],这样也就限制函数输出的变化程度
有两个问题,
这里weight clipping,只能做到K-lipschitz,而不是1-lipschitz,论文里面说这里放宽到k-lipschitz也是没有问题的
这个条件是充分非必要条件,也就是说weigth clipping后,得到的D集合是真正D集合的子集,所以得到的D也许无法Max大括号中的式子

图中显示,weight clipping的作用,如果没有weight clipping,线会趋向垂直,因为要使得max
加上weight clipping,其实就是限制住斜率
对比之前的GAN的算法,W-GAN的算法会做如下改动,

用WGAN还有一个好处是,我们真的可以用W来衡量生成图片质量好坏
在GAN中,W是JS-divergence,衡量的是交集,只要不想交,JS-divergence都是一样的值,而WGAN衡量的确实是两个分布的距离,所以距离越近,生成的图片质量越好

Improved GAN,Gradient penalty
改进的点,主要是如果保证1-lipschitz,之前用的是weight clipping
现在换一种方式,
当D是1-lipschitz时,D对x的gradients的norm小于等于1,比较自觉的定义,因为1-lipschitz就是D的变化率要小于x的变化率
所以我们通过加一个罚项来近似这个约束,罚项的定义就是倾向于让gradients的norm小于等于1,这样罚项就会为0;这样虽然不能保证这个约束,但是当参数lambda足够大时,即罚项的权重足够大时,可以近似满足
这里的罚项是个积分,是对所有x的积分,实践中无法做到,所以改成抽样,x从Ppenalty中抽样
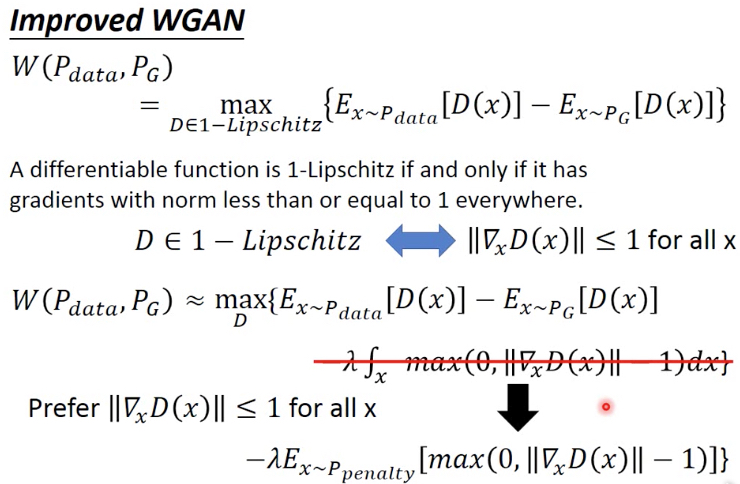
那这里的Ppenalty是怎么样的分布,这是有定义的,如下是Pdata和PG中间的区域
Pdata和PG各sample一个点,然后在连线,再在线上sample一个点作为Ppenalty

paper说这样做是因为实验效果比较好,给出的intuitive的解释是,generator是要将PG移向Pdata,所以他们之间的gradient是最有意义的
进一步优化罚项是,让gradient尽量接近于1,而非小于1
这样算法的收敛速度会更快,对于D而言肯定是gradient越大收敛的越快,而1-lipschitz约束gradient最大就是1

用gradient penalty的好处,
如果用weight clipping,显然很多weight都会被clip在边界上,很不自然,而gradient penalty的weight分布会更合理
同时生成的分布也更为合理
Transformation
Transformation,
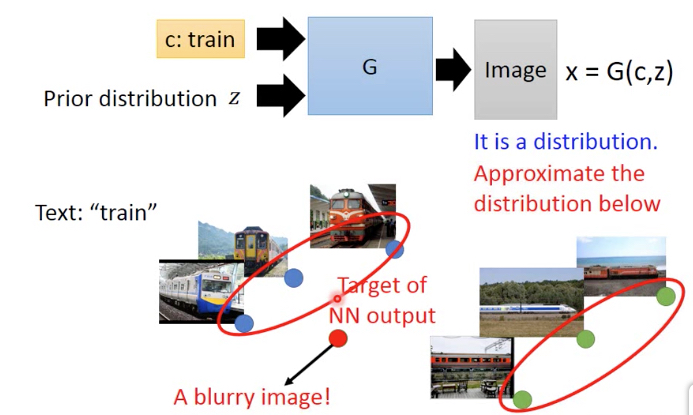
Paired data,比如Text to image,从一段话,生成一张图片
那么如果用传统的supervised learning的方法,会有下面的问题
比如train,所代表的火车有各种各样,所以生成的train会是所有火车的综合,变成一个很糊的输出图片

所以这里用GAN来生成,GAN的输入有两个,除了train,还有一个分布z
所以得到的输出也不是一个值,而是一个分布,分布中的点就可以代表各种各样的case,所以每次sample都可能得到不一样值,蓝色或绿色点的任意一个,而不会是红点
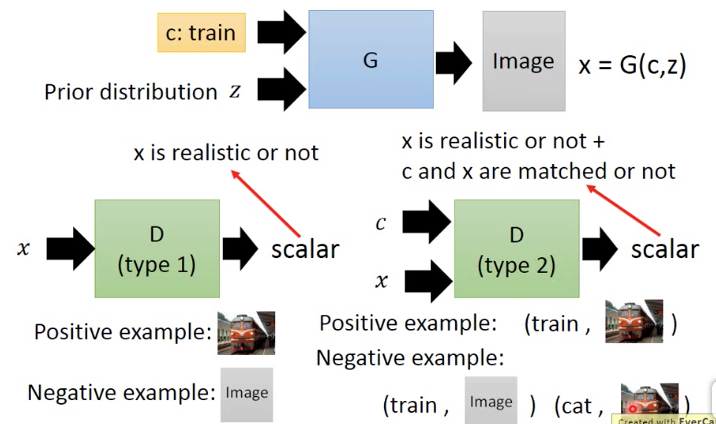
Conditional GAN的训练不同的地方,就是Discriminator的输入是两个,Negative example也要给出两种
如下图右,可以对比一下左边普通的discriminator
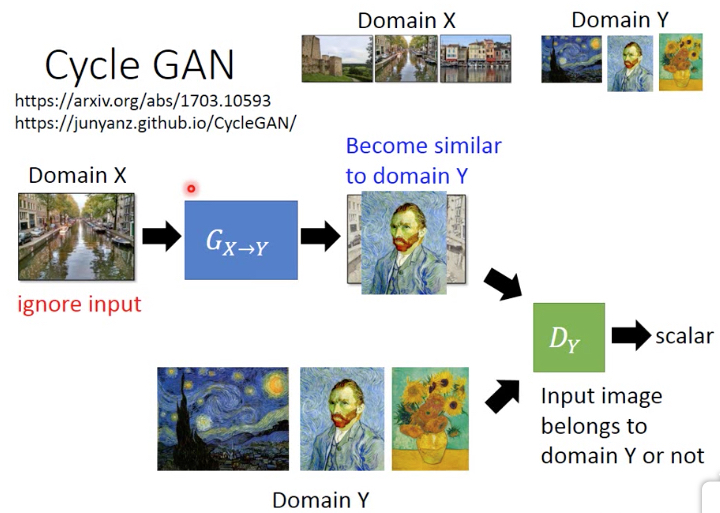
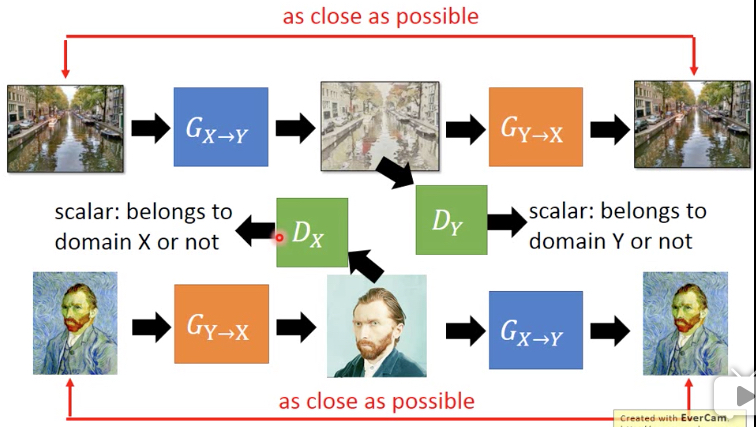
Unpaired Data,没有成对的训练集,比如有一堆普通图片,一堆梵高的图片
然后就想把普通图片转化成梵高风格

可以通过,风格迁移,sytle transfer来做,也可以用Cycle GAN
如果用普通的GAN,用Discriminator来判断生成的图片和梵高的画比,是否是一副梵高的画
很容易会产生下面的效果,generator确实会生成梵高的画,但是和input无关
所以要加上约束,其实就是auto-encoding
但中间的编码要符合特定的分布,这里就是梵高画的分布
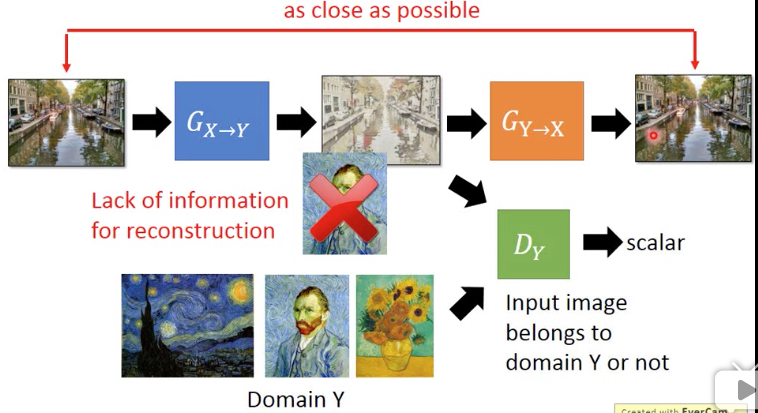
完整的版本就是这样的,
Improved GAN的更多相关文章
- Generative Adversarial Nets[Improved GAN]
0.背景 Tim Salimans等人认为之前的GANs虽然可以生成很好的样本,然而训练GAN本质是找到一个基于连续的,高维参数空间上的非凸游戏上的纳什平衡.然而不幸的是,寻找纳什平衡是一个十分困难的 ...
- [ZZ] Valse 2017 | 生成对抗网络(GAN)研究年度进展评述
Valse 2017 | 生成对抗网络(GAN)研究年度进展评述 https://www.leiphone.com/news/201704/fcG0rTSZWqgI31eY.html?viewType ...
- (转) GAN论文整理
本文转自:http://www.jianshu.com/p/2acb804dd811 GAN论文整理 作者 FinlayLiu 已关注 2016.11.09 13:21 字数 1551 阅读 1263 ...
- 常见GAN的应用
深入浅出 GAN·原理篇文字版(完整)|干货 from:http://baijiahao.baidu.com/s?id=1568663805038898&wfr=spider&for= ...
- Generative Adversarial Nets[content]
0. Introduction 基于纳什平衡,零和游戏,最大最小策略等角度来作为GAN的引言 1. GAN GAN开山之作 图1.1 GAN的判别器和生成器的结构图及loss 2. Condition ...
- Generative Adversarial Networks overview(1)
Libo1575899134@outlook.com Libo (原创文章,转发请注明作者) 本文章会先从Gan的简单应用示例讲起,从三个方面问题以及解决思路覆盖25篇GAN论文,第二个大部分会进一步 ...
- StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation - 1 - 多个域间的图像翻译论文学习
Abstract 最近在两个领域上的图像翻译研究取得了显著的成果.但是在处理多于两个领域的问题上,现存的方法在尺度和鲁棒性上还是有所欠缺,因为需要为每个图像域对单独训练不同的模型.为了解决该问题,我们 ...
- W-GAN系 (Wasserstein GAN、 Improved WGAN)
学习总结于国立台湾大学 :李宏毅老师 WGAN前作:Towards Principled Methods for Training Generative Adversarial Networks W ...
- (转) How to Train a GAN? Tips and tricks to make GANs work
How to Train a GAN? Tips and tricks to make GANs work 转自:https://github.com/soumith/ganhacks While r ...
随机推荐
- 删除 nuget 文件夹内容
vs2017 ->工具->选项->NuGet 包管理器->清除所有NuGet缓存
- 基于weixin-java-mp 做微信JS签名 invalid signature签名错误 官方说明
微信JS签名详情请见:http://mp.weixin.qq.com/wiki?t=resource/res_main&id=mp1421141115&token=&lang= ...
- nginx伪静态配置教程总结
在nginx中配置伪静态,也就是常说的url重写功能,只需在nginx.conf配置文件中写入重写规则即可. 当然,这个规则是需要熟悉正则表达式,只掌握nginx自身的正则匹配模式即可,对正则不了解的 ...
- 【Java】类加载过程
JVM把class文件加载到内存,并对数据进行校验.解析和初始化,最终形成JVM可以直接使用的Java类型的过程. 类加载的过程主要分为三个部分: 加载 链接 初始化 而链接又可以细分为三个小部分: ...
- AICODER全栈实习报名
三期班开始报名 三期班定于6月17日开班,实习费用如下: 三个月模式实习费为12000元. 一个月模式实习费为4500元. AICODER提供后付费模式,报名参加AICODER的线下实习3个月模式的朋 ...
- Windows 使用 Gogs 搭建 Git 服务器(转)
Windows 使用 Gogs 搭建 Git 服务器 随便说两句 之前有使用 Gitblit 在Windows搭建Git服务器,用的也挺好的,可能安装起来略麻烦一点.现在全用 Gogs 在wind ...
- CustomDrawableTextView
public class CustomDrawableTextView extends TextView{ //image width.height private int imageWidth; p ...
- 告别GOPATH,快速使用 go mod(Golang包管理工具)
https://studygolang.com/articles/17508?fr=sidebar 文中的wserver为module名,route为本地的包名,go.mod所在的目录名不一定非要和m ...
- Shell常见问题整理
1. 使用shell进行程序设计的原因是什么? 可以快速.简单的完成编程,非常适合于编写一些执行相对简单的任务的小工具.如果有一个简单的构想,可以通过它检查自己的想法是否可行.还可以使用shell对进 ...
- Spring 对事务管理的支持
1.Spring对事务管理的支持 Spring为事务管理提供了一致的编程模板,在高层次建立了统一的事务抽象.也就是说,不管选择Spring JDBC.Hibernate .JPA 还是iBatis,S ...