DataFrame 行列数据的筛选
一、对DataFrame的认知
DataFrame的本质是行(index)列(column)索引+多列数据。
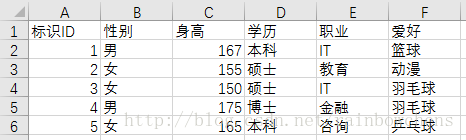
DataFrame默认索引是序号(0,1,2…),可以理解成位置索引。
一般我们用id标识不同记录,不会改变index。但为了理解不同特征(列)含义,我们往往会重新指定column。
二、对dataframe进行行列数据筛选
import pandas as pd
import numpy as np
from pandas import DataFrame
df = DataFrame(np.arange(20).reshape((4,5)),column = list('abcde')) #生成一个DataFrame

1.df[]&df. 选取列数据
df.a
df[[‘a’,’b’]]
2.df.loc[[index],[colunm]] 通过标签选择数据
不对行进行筛选时,[index]处填 : (不能为空),即df.loc[:,’a’]表示选取a列全部数据。
df.loc[0,’a’]
df.loc[0:1,[‘a’,’b’]]
df.loc[[0,2],[‘a’,’c’]]

3.df.iloc[[index],[colunm]] 通过位置选择数据
不对行进行筛选时,同df.loc[],即[index]处不能为空。
df.iloc[0,0]
df.iloc[0:1,1:3]
df.iloc[[0,2],[1,3]]

4.df.ix[[index],[column]] 通过标签or位置选择数据
df.ix[]混合了标签和位置选择。需要注意的是,[index]和[column]的框内需要指定同一类的选择。
df.ix[[0:1],[‘a’,3]]
报错
5.多条件筛选
原表数据:
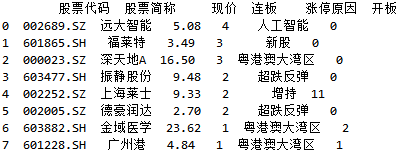
(1)使用“与”条件进行筛选
df1 = df.loc[(df['现价']>6)&(df['开板'] == 0)]
print(df1)
结果只有2条数据符合要求:

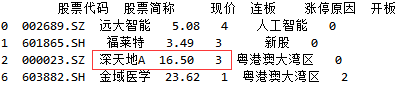
(2) 使用“或”条件进行筛选
df2 = df.loc[(df['现价']>10)|(df['连板'] >2)]
print(df2)
则有4条数据符合要求:(分别有2和6符合条件1,而0、1和2符合条件2)
DataFrame 行列数据的筛选的更多相关文章
- 【转载】使用Pandas对数据进行筛选和排序
使用Pandas对数据进行筛选和排序 本文转载自:蓝鲸的网站分析笔记 原文链接:使用Pandas对数据进行筛选和排序 目录: sort() 对单列数据进行排序 对多列数据进行排序 获取金额最小前10项 ...
- 从mysql8.0读取数据并形成pandas dataframe类型数据,精确定位行列式中的元素,并读取
from pandas import * import pandas as pd from sqlalchemy import create_engine engine = create_engine ...
- Slider 滚动条 Pagination分页插件 JS Ajax 数据范围筛选 加载 翻页 笔记
入职以后的第二个任务 根据用户所选的价格范围 筛选数据 修复BUG - 筛选数据后 总数没有更新.列表显示错误.翻页加载错误 用到的一些知识点 jquery插件系列之 - Slider滑块 max ...
- sql 游标例子 根据一表的数据去筛选另一表的数据
sql 游标例子 根据一表的数据去筛选另一表的数据 DECLARE @MID nvarchar(20)DECLARE @UTime datetime DECLARE @TBL_Temp table( ...
- vuejs实现本地数据的筛选分页
今天项目需要一份根据本地数据的筛选分页功能,好吧,本来以为很简单,网上搜了搜全是ajax获取的数据,这不符合要求啊,修改起来太费力气,还不如我自己去写,不多说直接上代码 效果图: 项目需要:点击左侧进 ...
- Python3 Pandas的DataFrame格式数据写入excle文件、json、html、剪贴板、数据库
Python3 Pandas的DataFrame格式数据写入excle文件.json.html.剪贴板.数据库 一.DataFrame格式数据 Pandas是Python下一个开源数据分析的库,它提供 ...
- sql 先查出已知的数据或者需要的数据再筛选
sql 先查出已知的数据或者需要的数据再筛选
- pandas.DataFrame——pd数据框的简单认识、存csv文件
接着前天的豆瓣书单信息爬取,这一篇文章看一下利用pandas完成对数据的存储. 回想一下我们当时在最后得到了六个列表:img_urls, titles, ratings, authors, detai ...
- pandas 学习 第5篇:DataFrame - 访问数据框
数据框是用于存储数据的二维结构,分为行和列,一行和一列的交叉位置是一个cell,该cell的位置是由行索引和列索引共同确定的.可以通过at/iat,或loc/iloc属性来访问数据框的元素,该属性后跟 ...
随机推荐
- [学习笔记]nodejs全局安装和本地安装的区别
参考来源于 nodejs全局安装和本地安装的区别 1.全局安装 $ npm install gulp --global 2.作为项目的开发一开(devDependencies)安装 $ npm ins ...
- 学习Vue 入门到实战——学习笔记
闲聊: 自从进了现在的公司,小颖就再没怎么接触vue了,最近不太忙,所以想再学习下vue,就看了看vue相关视频,顺便做个笔记嘻嘻. 视频地址:Vue 入门到实战1.Vue 入门到实战2 学习内容: ...
- ASP.NET Core MVC+EF Core从开发到部署
笔记本电脑装了双系统(Windows 10和Ubuntu16.04)快半年了,平时有时间就喜欢切换到Ubuntu系统下耍耍Linux,熟悉熟悉Linux命令.Shell脚本以及Linux下的各种应用的 ...
- PowerBI与Visio
前言 如何在Power BI中使用Visio, 刚好最近微软推出了适用于Power BI 的 Visio自定义可视化对象预览,分享给大家. 我们先看一下效果: 通过自定义可视化对象,将Visio ...
- TemplateBuilder Android Studio
TemplateBuilder:是Android Studio的一个开发模板,大大提高开发效率.
- bug制造者又上线了
上一家公司,领导经常这样表扬一位同事,“你写的bug远比你的功能值钱...” 今天特么的突然觉得我好像也有这样的功能,不知道是上次回家把脑子落家里了还是,前几天淋雨脑子进了水了. 呢么简单一个功能,愣 ...
- php(数组方法
什么是数组? 数组就是一组数据的集合 其表现形式就是内存中的一段连续的内存地址 数组名称其实就是连续内存地址的首地址 关于js中的数组特点 数组定义时无需指定数据类型 数组定义时可以无需指定数组长度 ...
- (function(){…})(); 与 (function(){…}());
从结果上来说,个人的意见是:他们是一样的.
- Source Insight中文注释乱码、字体大小、等宽解决方法
中文注释乱码解决方法: 用记事本打开源文件,然后,选择文件->另存为,编码选为”ANSI“ 字体的调整: Source Insight 菜单栏选择Options->Document O ...
- TZOJ:区间问题
描述 有n项工作,每项工作分别在 si时间开始,ti时间结束.对于每项工作你选择参与与否,如果选择 了参与,那么自始至终就必须全程参与.参与工作的时间段不可以重叠(即使是开始的瞬间和结束的瞬间重叠也是 ...