kNN处理iris数据集-使用交叉验证方法确定最优 k 值
基本流程:
1、计算测试实例到所有训练集实例的距离;
2、对所有的距离进行排序,找到k个最近的邻居;
3、对k个近邻对应的结果进行合并,再排序,返回出现次数最多的那个结果。
交叉验证:
对每一个k,使用验证集计算,记录k对应的错误次数,取错误数最小的k
# -*- coding: utf-8 -*-
import os
import pandas as pd
import matplotlib.pyplot as plt
import math
import operator
#按照8:2的比例分割数据
#testSetIndex : 第几组为测试样本,取值范围0 - 4
def splitData(trainSet, testSet, testSetIndex):
#data = pd.read_csv('iris.txt', skiprows=0, skipfooter=0, sep=r'\s+', encoding="utf-8", engine='python', header=None)
data = pd.read_csv('iris.txt', encoding="utf-8", engine='python', header=None)
for i in range(150):
if testSetIndex == (i % 50) / 10:
testSet.append(data.iloc[i])
else:
trainSet.append(data.iloc[i])
return
#计算欧氏距离
#instance1 : 实例1
#instance2 : 实例2
#dimension :维度
def computeDistance(instance1, instance2, dimension):
distance = 0
for i in xrange(dimension):
#print(instance1[i], instance2[i])
distance += pow((instance1[i] - instance2[i]), 2)
return math.sqrt(distance)
#trainSet : 训练样本集
#instance : 实例数据
#k : 1 - 120
def kNN(trainSet, instance, k):
distances = []
dimension = len(instance) - 1
#计算测试实例到训练集实例的距离
for i in xrange(len(trainSet)):
dist = computeDistance(instance, trainSet[i], dimension)
distances.append((trainSet[i], dist))
#对所有的距离进行排序
distances.sort(key=operator.itemgetter(1))
neighbors = []
#返回k个最近邻
for i in range(k):
neighbors.append(distances[i][0])
#对k个近邻进行合并,返回最多的那个
listClass = {}
for i in xrange(len(neighbors)):
response = neighbors[i][4]
if response in listClass:
listClass[response] += 1
else:
listClass[response] = 1
#排序
sortResult = sorted(listClass.iteritems(), key = operator.itemgetter(1), reverse=True)
return sortResult[0][0]
def main():
trainSet = [] #训练数据集
testSet = [] #测试数据集
#1. 数据分割8:2
splitData(trainSet, testSet, 4)
#2. 使用交叉验证方法确定最优 k 值,并给出在该情形下分类器的错误分类率
errCountSet = [0] * 120
#9总数据切割方式,对每一个k,记录k对应的总错误次数
for j in xrange(0, 5):
trainSet = []
testSet = []
splitData(trainSet, testSet, j)
for k in xrange(0, 120):
#对每一个k,使用验证集计算,记录k对应的错误次数
for i in xrange(len(testSet)):
trainResult = kNN(trainSet, testSet[i], k + 1)
if trainResult != testSet[i][4]:
errCountSet[k] = errCountSet[k] + 1
#取错误数最小的k 有多个
min = 1
for i in xrange(0, 120):
errCountSet[i] = errCountSet[i] / (30 * 5.0)
if min > errCountSet[i]:
min = errCountSet[i]
#k = i + 1
#打印错误率最小的k值
for i in xrange(0, 120):
if min == errCountSet[i]:
print i + 1, min
fig = plt.figure(figsize=(20, 15))
ax1 = fig.add_subplot(111)
#ax2 = fig.add_subplot(122)
ax1.plot(range(1, 121), errCountSet)
ax1.set_xlabel('k')
ax1.set_ylabel('Error Rate')
plt.show()
return
if __name__ == "__main__":
main()
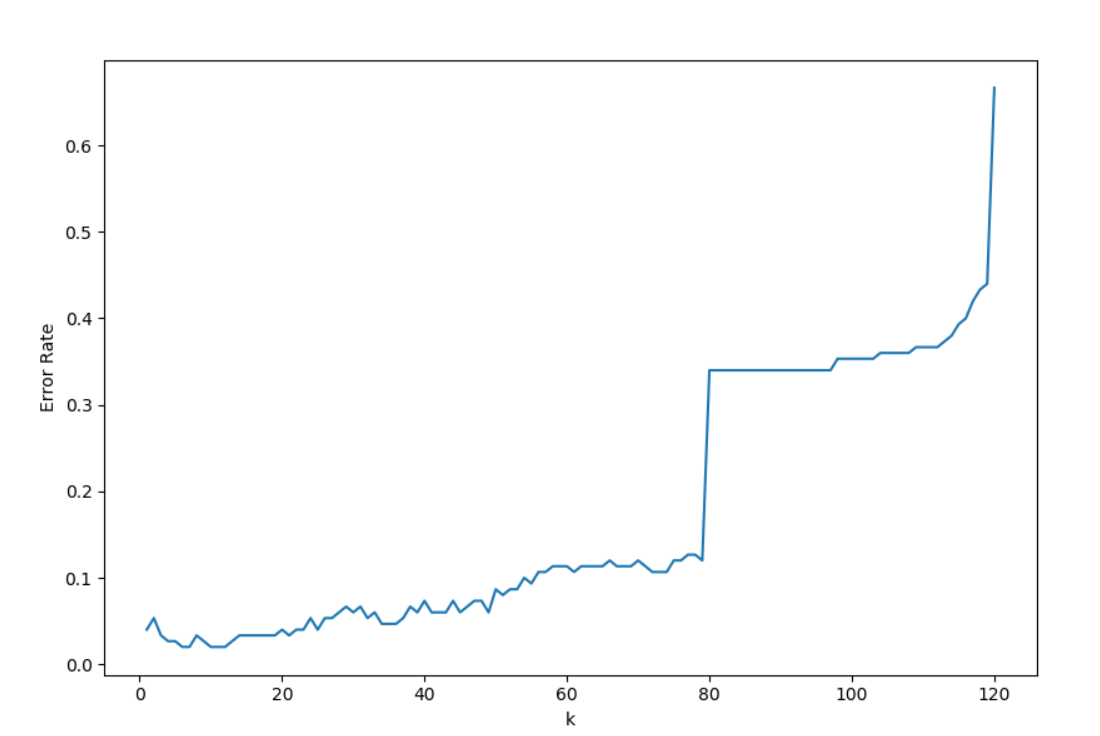
分别使用参数k=1~120进行实验,并进行交叉验证,错误分类率曲线如下:
kNN处理iris数据集-使用交叉验证方法确定最优 k 值的更多相关文章
- 使用KNN对iris数据集进行分类——python
filename='g:\data\iris.csv' lines=fr.readlines()Mat=zeros((len(lines),4))irisLabels=[]index=0for lin ...
- 十折交叉验证10-fold cross validation, 数据集划分 训练集 验证集 测试集
机器学习 数据挖掘 数据集划分 训练集 验证集 测试集 Q:如何将数据集划分为测试数据集和训练数据集? A:three ways: 1.像sklearn一样,提供一个将数据集切分成训练集和测试集的函数 ...
- 用交叉验证改善模型的预测表现-着重k重交叉验证
机器学习技术在应用之前使用“训练+检验”的模式(通常被称作”交叉验证“). 预测模型为何无法保持稳定? 让我们通过以下几幅图来理解这个问题: 此处我们试图找到尺寸(size)和价格(price)的关系 ...
- 机器学习——交叉验证,GridSearchCV,岭回归
0.交叉验证 交叉验证的基本思想是把在某种意义下将原始数据(dataset)进行分组,一部分做为训练集(train set),另一部分做为验证集(validation set or test set) ...
- 机器学习基础:(Python)训练集测试集分割与交叉验证
在上一篇关于Python中的线性回归的文章之后,我想再写一篇关于训练测试分割和交叉验证的文章.在数据科学和数据分析领域中,这两个概念经常被用作防止或最小化过度拟合的工具.我会解释当使用统计模型时,通常 ...
- S折交叉验证(S-fold cross validation)
S折交叉验证(S-fold cross validation) 觉得有用的话,欢迎一起讨论相互学习~Follow Me 仅为个人观点,欢迎讨论 参考文献 https://blog.csdn.net/a ...
- 总结:Bias(偏差),Error(误差),Variance(方差)及CV(交叉验证)
犀利的开头 在机器学习中,我们用训练数据集去训练(学习)一个model(模型),通常的做法是定义一个Loss function(误差函数),通过将这个Loss(或者叫error)的最小化过程,来提高模 ...
- 验证和交叉验证(Validation & Cross Validation)
之前在<训练集,验证集,测试集(以及为什么要使用验证集?)(Training Set, Validation Set, Test Set)>一文中已经提过对模型进行验证(评估)的几种方式. ...
- MATLAB曲面插值及交叉验证
在离散数据的基础上补插连续函数,使得这条连续曲线通过全部给定的离散数据点.插值是离散函数逼近的重要方法,利用它可通过函数在有限个点处的取值状况,估算出函数在其他点处的近似值.曲面插值是对三维数据进行离 ...
随机推荐
- appium安装完成后运行和执行python脚本的错误合集
1.第一个错误如下: main.js: error: argument "--app": Expected one argument. null 这个一般是appium服务端安装的 ...
- .net 连接kafka
新建两个控制台项目,一个生产者,一个消费者,使用Nuget安装Confluent.Kafka 生产者 static void Main(string[] args) { var config = ne ...
- Android开发之漫漫长途 XIX——HTTP
该文章是一个系列文章,是本人在Android开发的漫漫长途上的一点感想和记录,我会尽量按照先易后难的顺序进行编写该系列.该系列引用了<Android开发艺术探索>以及<深入理解And ...
- Shell脚本 | 截取包名
之前写 shell 脚本的几篇文章都是先大致介绍脚本的功能和写法,然后一股脑的给出完整的代码.并没有细致入微的解释脚本中的每一行是如何思考如何编写的. 今天反其道而行之,只介绍一行代码.争取能讲的清楚 ...
- 通过spring抽象路由数据源+MyBatis拦截器实现数据库自动读写分离
前言 之前使用的读写分离的方案是在mybatis中配置两个数据源,然后生成两个不同的SqlSessionTemplate然后手动去识别执行sql语句是操作主库还是从库.如下图所示: 好处是,你可以人为 ...
- SpringCloud Eureka服务注册及发现——服务端/客户端/消费者搭建
Eureka 是 Netflix 出品的用于实现服务注册和发现的工具. Spring Cloud 集成了 Eureka,并提供了开箱即用的支持.其中, Eureka 又可细分为 Eureka Serv ...
- java远程调试(idea)
遇见一个怪异问题,无奈线上数据库有限制,只能远程调试下代码.突然发现,远程调试代码真的好简单,简单记录下操作步骤. 1.在idea里创建一个Remote,远程连接的入口. 找到 Edit Config ...
- spring-boot-2.0.3之redis缓存实现,不是你想的那样哦!
前言 开心一刻 小白问小明:“你前面有一个5米深的坑,里面没有水,如果你跳进去后该怎样出来了?”小明:“躺着出来呗,还能怎么出来?”小白:“为什么躺着出来?”小明:“5米深的坑,还没有水,跳下去不死就 ...
- Java设计模式学习记录-桥接模式
前言 这次介绍结构型设计模式中的第二种模式,桥接模式. 使用桥接模式的目的就是为了解耦,松散的耦合更利于扩展,但是会增加相应的代码量和设计难度. 桥接模式 桥接模式是为了将抽象化与实现化解耦,让二者可 ...
- Scrapy-Splash的介绍、安装以及实例
scrapy-splash的介绍 在前面的博客中,我们已经见识到了Scrapy的强大之处.但是,Scrapy也有其不足之处,即Scrapy没有JS engine, 因此它无法爬取JavaScrip ...