Pandas简易入门(一)
目录:
读取数据
索引
选择数据
简单运算
声明,本文引用于:https://www.dataquest.io/mission/8/introduction-to-pandas (建议阅读原文)
Pandas使用一个二维的数据结构DataFrame来表示表格式的数据,相比较于Numpy,Pandas可以存储混合的数据结构,同时使用NaN来表示缺失的数据,而不用像Numpy一样要手工处理缺失的数据,并且Pandas使用轴标签来表示行和列
读取数据
Pandas使用函数read_csv()来读取csv文件
import pandas
food_info = pandas.read_csv('food_info.csv')
print(type(food_info))
# 输出:<class 'pandas.core.frame.DataFrame'> 可见读取后变成一个DataFrame变量
该文件的内容如下:
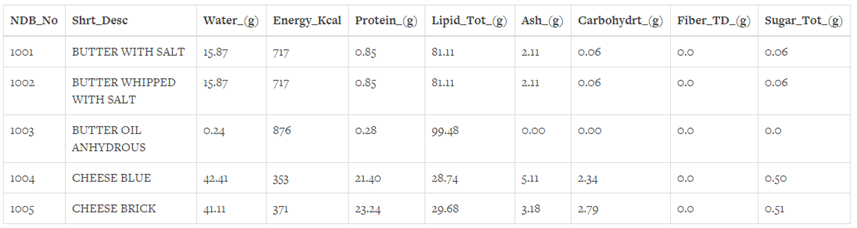
使用函数head( m )来读取前m条数据,如果没有参数m,默认读取前五条数据
first_rows = food_info.head() first_rows = food_info.head(3)
由于DataFrame包含了很多的行和列,Pandas使用省略号(...)来代替显示全部的行和列,可以使用colums属性来显示全部的列名
print(food_info.columns)
# 输出:输出全部的列名,而不是用省略号代替
Index(['NDB_No', 'Shrt_Desc', 'Water_(g)', 'Energ_Kcal', 'Protein_(g)', 'Lipid_Tot_(g)', 'Ash_(g)', 'Carbohydrt_(g)', 'Fiber_TD_(g)', 'Sugar_Tot_(g)', 'Calcium_(mg)', 'Iron_(mg)', 'Magnesium_(mg)', 'Phosphorus_(mg)', 'Potassium_(mg)', 'Sodium_(mg)', 'Zinc_(mg)', 'Copper_(mg)', 'Manganese_(mg)', 'Selenium_(mcg)', 'Vit_C_(mg)', 'Thiamin_(mg)', 'Riboflavin_(mg)', 'Niacin_(mg)', 'Vit_B6_(mg)', 'Vit_B12_(mcg)', 'Vit_A_IU', 'Vit_A_RAE', 'Vit_E_(mg)', 'Vit_D_mcg', 'Vit_D_IU', 'Vit_K_(mcg)', 'FA_Sat_(g)', 'FA_Mono_(g)', 'FA_Poly_(g)', 'Cholestrl_(mg)'], dtype='object')
可以使用tolist()函数转化为list
food_info.columns.tolist()
与Numpy一样,用shape属性来显示数据的格式
dimensions = food_info.shape print(dimensions)
输出:(8618,36) 表示这个表格有8618行和36列的数据,其中dimensions[0]为8618,dimensions[1]为36
与Numpy一样,用dtype属性来显示数据类型,Pandas主要有以下几种dtype:
- object -- 代表了字符串类型
- int -- 代表了整型
- float -- 代表了浮点数类型
- datetime -- 代表了时间类型
- bool -- 代表了布尔类型
当读取了一个文件之后,Pandas会通过分析值来推测每一列的数据类型
print(food_info.dtypes)
输出:每一列对应的数据类型
NDB_No int64
Shrt_Desc object
Water_(g) float64
Energ_Kcal int64
Protein_(g) float64
...
索引
读取了文件后,Pandas会把文件的一行作为列的索引标签,使用行数字作为行的索引标签
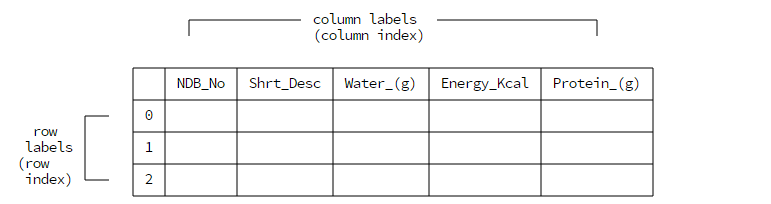
注意,行标签是从数字0开始的
Pandas使用Series数据结构来表示一行或一列的数据,类似于Numpy使用向量来表示数据。Numpy只能使用数字来索引,而Series可以使用非数字来索引数据,当你选择返回一行数据的时候,Series并不仅仅返回该行的数据,同时还有每一列的标签的名字。
譬如要返回文件的第一行数据,Numpy就会返回一个列表(但你可能不知道每一个数字究竟代表了什么)

而Pandas则会同时把每一列的标签名返回(此时就很清楚数据的意思了)

选择数据
Pandas使用loc[]方法来选择行的数据
# 选择单行数据: food_info.loc[0] # 选择行标号为0的数据,即第一行数据 food_info.loc[6] # 选择行标号为6的数据,即第七行数据 # 选择多行数据: food_info.loc[3:6] # 使用了切片,注意:由于这里使用loc[]函数,所以返回的是行标号为3,4,5,6的数据,与python的切片不同的是这里会返回最后的标号代表的数据,但也可以使用python的切片方法: food_info[3:7] food_info.loc[[2,5,10]] # 返回行标号为2,5,10三行数据 练习:返回文件的最后五行 方法一: length = food_info.shape[0] last_rows = food_info.loc[length-5:length-1] 方法二: num_rows = food_info.shape[0] last_rows = food_info[num_rows-5:num_rows] Pandas直接把列名称填充就能返回该列的数据 ndb_col = food_info["NDB_No"] # 返回列名称为NDB_No的那一列的数据 zinc_copper = food_info[["Zinc_(mg)", "Copper_(mg)"]] # 返回两列数据
简单运算
现在要按照如下公式计算所有食物的健康程度,并按照降序的方式排列结果:
Score=2×(Protein_(g))−0.75×(Lipid_Tot_(g))
对DataFrame中的某一列数据进行算术运算,其实是对该列中的所有元素进行逐一的运算,譬如:
water_energy = food_info["Water_(g)"] * food_info["Energ_Kcal"]
原理:
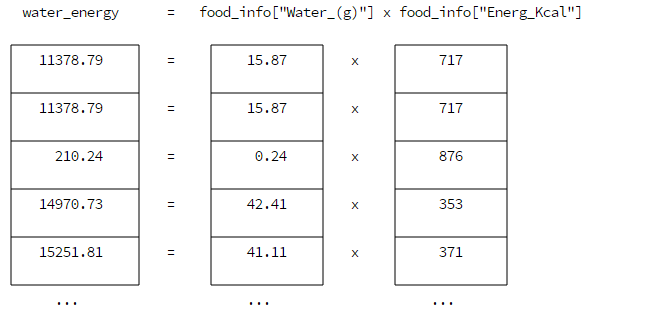
由于每一列的数据跨度太大,有的数据是从0到100000,而有的数据是从0到10,所以为了尽量减少数据尺度对运算结果的影响,采取最简单的方法来规范化数据,那就是将每个数值都除以该列的最大值,从而使所有数据都处于0和1之间。其中max()函数用来获取该列的最大值.
food_info['Normalized_Protein'] = food_info['Protein_(g)'] / food_info['Protein_(g)'].max()
food_info['Normalized_Fat'] = food_info['Lipid_Tot_(g)'] / food_info['Lipid_Tot_(g)'].max()
food_info['Norm_Nutr_Index'] = food_info["Normalized_Protein"] * 2 - food_info["Normalized_Fat"] * 0.75
注意:上面的两个语句已经在原来的DataFrame中添加了三列,列名分别为Normalized_Protein和Normalized_Fat,Norm_Nutr_Index。只需要使用中括号和赋值符就能添加新列,类似于字典
对DataFrame的某一列数据排序,只需要使用函数sort()即可
food_info.sort("Sodium_(mg)") # 函数参数为列名,默认是按照升序排序,同时返回一个新的DataFrame
food_info.sort("Norm_Nutr_Index", inplace=True, ascending=False ) # 通过inplace参数来控制在原表排序,而不是返回一个新的对象;ascending参数用来控制是否升序排序
Pandas简易入门(一)的更多相关文章
- Pandas简易入门(二)
目录: 处理缺失数据 制作透视图 删除含空数据的行和列 多行索引 使用apply函数 本节主要介绍如何处理缺失的数据,可以参考原文:https://www. ...
- Pandas简易入门(四)
本节主要介绍一下Pandas的另一个数据结构:DataFrame,本文的内容来源:https://www.dataquest.io/mission/147/pandas-internals-dataf ...
- Pandas简易入门(三)
本节主要介绍一下Pandas的数据结构,本文引用的网址:https://www.dataquest.io/mission/146/pandas-internals-series 本文所使用的数据来自于 ...
- 机器学习简易入门(四)- logistic回归
摘要:使用logistic回归来预测某个人的入学申请是否会被接受 声明:(本文的内容非原创,但经过本人翻译和总结而来,转载请注明出处) 本文内容来源:https://www.dataquest.io/ ...
- 不用搭环境的10分钟AngularJS指令简易入门01(含例子)
不用搭环境的10分钟AngularJS指令简易入门01(含例子) `#不用搭环境系列AngularJS教程01,前端新手也可以轻松入坑~阅读本文大概需要10分钟~` AngularJS的指令是一大特色 ...
- pandas教程1:pandas数据结构入门
pandas是一个用于进行python科学计算的常用库,包含高级的数据结构和精巧的工具,使得在Python中处理数据非常快速和简单.pandas建造在NumPy之上,它使得以NumPy为中心的应用很容 ...
- pandas快速入门
pandas快速入门 numpy之后让我们紧接着学习pandas.Pandas最初被作为金融数据分析工具而开发出来,后来因为其强大性以及友好性,在数据分析领域被广泛使用,下面让我们一窥究竟. 本文参考 ...
- Web压力测试工具 LoadRunner12.x简易入门教程--(一)回放与录制
LoadRunner12.x简易入门教程--(一)回放与录制 今天在这里分享一下LoadRunner12.x版本的入门使用方法,希望对刚接触LoadRunner的童鞋有所帮助. LoadRun ...
- Python pandas快速入门
Python pandas快速入门2017年03月14日 17:17:52 青盏 阅读数:14292 标签: python numpy 数据分析 更多 个人分类: machine learning 来 ...
随机推荐
- javascript模块化编程-详解立即执行函数表达式IIFE
一.IIFE解释 全拼Imdiately Invoked Function Expression,立即执行的函数表达式. 像如下的代码所示,就是一个匿名立即执行函数: (function(windo ...
- Spring Boot 静态页面
spring boot项目只有src目录,没有webapp目录,会将静态访问(html/图片等)映射到其自动配置的静态目录,如下 /static /public /resources /META-IN ...
- 高通移植mipi LCD的过程LK代码
lk部分:(实现LCD兼容) 1. 函数定位 aboot_init()来到target_display_init(): 这就是高通原生lk LCD 兼容的关键所在.至于你需要兼容多少LCD 就在whi ...
- 20个最常用的Windows命令行
1. 中断命令执行Ctrl + Z 2. 文件/目录cd 切换目录例:cd // 显示当前目录例:cd .. // 进入父目录 3.创建目录md d:\mp3 // 在C:\建立mp3文件夹md d: ...
- Alpha冲刺! Day11 - 砍柴
Alpha冲刺! Day11 - 砍柴 今日已完成 晨瑶: gitkraken团队协作流程教程基本完工. 昭锡:将主页包含UI界面.逻辑处理等与底部栏整合,学习Retrofit网络库. 永盛:更多 c ...
- postgresql中uuid的使用
本文总共介绍两种方法 : 1.使用create extension命令 create extension "uuid-ossp" 安装扩展成功以后,就可以通过uuid_genera ...
- PostgreSQL 空间处理函数
PostGIS中的常用函数 以下内容包括比较多的尖括号,发布到blogger的时候会显示不正常,内容太多我也无暇一个个手动改代码,因此如有问题就去参考PostGIS官方文档. 首先需要说明一下,这里许 ...
- span 文本内容超过宽度自动换行
span{word-break:normal; width:auto; display:block; white-space:pre-wrap;word-wrap : break-word ;over ...
- Django之ORM查询进阶
基于双下划线的双表查询 分组与聚合函数 基于双下划线的双表查询 Django 还提供了一种直观而高效的方式在查询(lookups)中表示关联关系,它能自动确认 SQL JOIN 联系.要做跨关系查询, ...
- Docker部署HDFS
docker部署hadoop只是实验目的,每个服务都是通过手动部署,比如namenode, datanode, journalnode等.如果为了灵活的管理集群,而不使用官方封装好的自动化部署脚本,本 ...