论文泛读 A Novel Ensemble Learning-based Approach for Click Fraud Detection in Mobile Advertising [1/10]
title:新的基于集成学习的移动广告作弊检测
导语:基于buzzcity数据集,我们提出了对点击欺诈检测是基于一组来自现有属性的新功能的一种新方法。根据所得到的精度、召回率和AUC对所提出的模型进行评估。最后的模型基于6种不同的学习算法。我们用刚才说的三种指标,来证明模型是稳定的。我们的最终模型在训练、验证和测试数据集上显示了改进的结果,从而证明了它对不同数据集的普遍性。
1.Introduction 导入
大部分都是废话
1.1 Problem Formulation 问题构建
数据是用的buzzcity的数据,数据格式:http://www.dnagroup.org/PDF/FDMADataDescription.pdf
一个二分类问题,检测流量方publisher是是否在作弊。(实际上训练集里面有三种label,作弊,未作弊,和不确定)
衡量标准:resulting precision, recall and the area under the ROC curve,准确率,召回率,和AUC
2 Data Preprocessing and Feature Creation 数据预处理和特征工程
2.1 数据预处理:
先找出有用的特征,所有的数据为iplong, agent, partner id, campaign ID, country, time-at, category, referrer in the clicktable and partner id, address, bank account and label in the partner table,去掉无用的,比如partner address, bank account。
合并两个表(publisher database and click database)
2.2 特征提取:
借鉴了google反作弊的特征选择,以及其他的传统方向。
对于时间而言:作弊的方法一般有,第一种通常会使用各种技巧伪装自己的活动,例如生成非常稀疏的点击序列、IP地址的更改、从不同国家的计算机发出点击等等。另一些坚持只在给定时间间隔内产生最大点击次数的传统方法。针对这些,我们会选择1 min, 5 min, 1 hours, 3hours and 6 hours.的时间间隔,来统计他们的总点击次数,最大点击数、平均点击数、偏度和方差。
实际上我们就只会对于每一个时间间隔,统计平均值,最大值,方差,偏度

对于IP而言:构造五种特征:
1.最大同IP点击:一个IP地址最多的点击数量
2.IP数量:就对于每一个流量方,点击它广告的IP数量
3.每个IP的平均点击数量
4.熵的计算:IP点击的熵
5.方差:IP点击数量的方差
有些作弊是采用在一些ip上进行大量的点击,所以导致方差变高。
剩下的特征都差不多处理方式,类似于IP,一共创造了41种特征,链接在下面:http://www.dnagroup.org/PDF/FDMAFeatures.pdf
2.3 特征选择
特征选择用了三种方法:主成分分析(PCA)、公共空间模式(CSP)和wrapper subset evaluation
https://en.wikipedia.org/wiki/Principal_component_analysis
https://en.wikipedia.org/wiki/Common_spatial_pattern
wrapper subset evaluation是贪心的选择出一些特征集合来进行训练,用10-fold来进行衡量
3.Experimental Configuration 实验配置
3.1 Datasets
三个集合,训练集,从训练集拆出来的验证集,测试集。
训练集中,click database有3173834个实例,每个实例表示一个点击。publisher database有3081个,并且有标签标识是否在作弊。
验证集:2689005个点击,3064个publisher
测试集:2598815点击, 2112 publisher.
3.2 Platform and Tools Used
i7cpu,8G内存。特征的预处理用的matlab,数据存储用的mysql,模型训练用的WEKA。
3.3 Methods Used 方法使用
论文在这儿,说了一堆废话,他尝试了很多模型,发现决策树最厉害,所以我们就用决策树了。
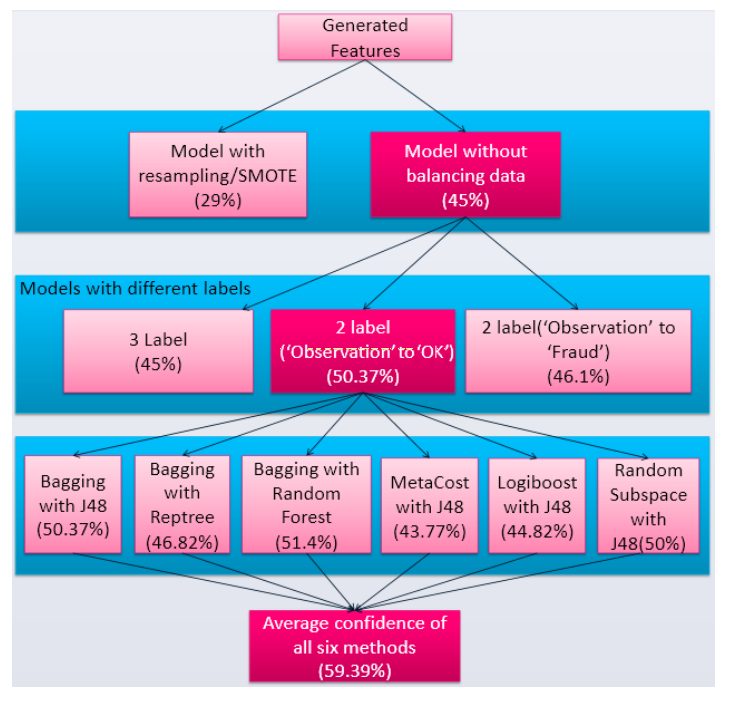
在我们的数据中数据有2.336的作弊者、2.596的不确定和95.068的未作弊,我们面临数据倾斜的问题。为了解决这个问题,我们用了smote算法来拟合出更多的反例。
用了Bagging Metacost还有 logiboost来进行集成学习。
4 Results
用acc作为衡量标准,模型为:
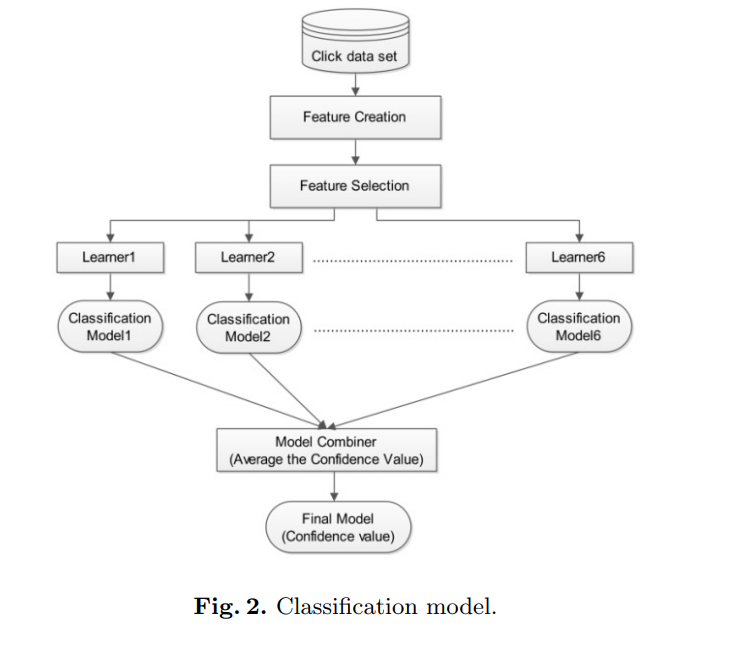
最后将6个模型取平均,就得到了最后的答案。

基础模型,总共就上面三种之一。
然后作者给我们展现了,如果你不做某个环节,你就亏了的故事。
5 Discussions and Conclusion
作者总结出,作弊者一般采用更换代理,点击间隔在1min~6hour之间的一些方法来作弊。
作者表示以后应该多用一些特征处理方法,比如做一些交叉特征来处理。
特征工程方面:
样本不均匀:过抽样和欠抽样,smote。或者构建小的数据集,类似随机森林。
在模型融合方面:作者太过于粗糙,实际上还有stacking,blending等方法https://mlwave.com/kaggle-ensembling-guide/
论文泛读 A Novel Ensemble Learning-based Approach for Click Fraud Detection in Mobile Advertising [1/10]的更多相关文章
- 论文泛读:Click Fraud Detection: Adversarial Pattern Recognition over 5 Years at Microsoft
这篇论文非常适合工业界的人(比如我)去读,有很多的借鉴意义. 强烈建议自己去读. title:五年微软经验的点击欺诈检测 摘要:1.微软很厉害.2.本文描述了大规模数据挖掘所面临的独特挑战.解决这一问 ...
- 论文泛读·Adversarial Learning for Neural Dialogue Generation
原文翻译 导读 这篇文章的主要工作在于应用了对抗训练(adversarial training)的思路来解决开放式对话生成(open-domain dialogue generation)这样一个无监 ...
- NLP论文泛读之《教材在线评论的情感倾向性分析》
NLP论文泛读之<教材在线评论的情感倾向性分析> 本文借助细粒度情感分类技术, 对从网络上抓取大量计算机专业本科教材的评价文本进行情感极性 分析, 从而辅助商家和出版社改进教材的质量.制定 ...
- 【软件分析与挖掘】Multiple kernel ensemble learning for software defect prediction
摘要: 利用软件中的历史缺陷数据来建立分类器,进行软件缺陷的检测. 多核学习(Multiple kernel learning):把历史缺陷数据映射到高维特征空间,使得数据能够更好地表达: 集成学习( ...
- 论文笔记: Deep Learning based Recommender System: A Survey and New Perspectives
(聊两句,突然记起来以前一个学长说的看论文要能够把论文的亮点挖掘出来,合理的进行概括23333) 传统的推荐系统方法获取的user-item关系并不能获取其中非线性以及非平凡的信息,获取非线性以及非平 ...
- 论文翻译:2021_Towards model compression for deep learning based speech enhancement
论文地址:面向基于深度学习的语音增强模型压缩 论文代码:没开源,鼓励大家去向作者要呀,作者是中国人,在语音增强领域 深耕多年 引用格式:Tan K, Wang D L. Towards model c ...
- 论文笔记(2):A fast learning algorithm for deep belief nets.
论文笔记(2):A fast learning algorithm for deep belief nets. 这几天继续学习一篇论文,Hinton的A Fast Learning Algorithm ...
- 壁虎书7 Ensemble Learning and Random Forests
if you aggregate the predictions of a group of predictors,you will often get better predictions than ...
- Ensemble learning(集成学习)
定义 集成学习是一种机器学习范式,其中多个学习器被训练来解决相同的问题. 这与试图从训练数据中学习一个假设的普通机器学习方法相反,集成方法尝试构造一组假设并将它们结合使用. 一个集合包含一些通常被称为 ...
随机推荐
- CentOS 6.9 NFS安装和配置
1.安装依赖包 yum install nfs-utils rpcbind -y 2.开机启动 chkconfig rpcbind on chkconfig nfs on 3.创建一个共享目录和加权限 ...
- ASP.NET CORE Swagger
Package 添加并配置Swagger中间件 将Swagger生成器添加到方法中的服务集合中Startup.ConfigureServices: public void ConfigureServi ...
- css3三角形冒泡泡图形制作
图一: 图二: <!DOCTYPE html> <html> <head> <title>css 三角形</title> <style ...
- tmux 安装
安装libevent wget https://github.com/downloads/libevent/libevent/libevent-2.0.21-stable.tar.gz tar xzv ...
- python写csv文件
name=['lucy','jacky','eric','man','san'] place=['chongqing','guangzhou','beijing','shanghai','shenzh ...
- centos中less翻页查询的用法
用法实例: cat 21342.log | less
- JMeter3.0 post参数/BeanShell中文乱码问题
在用JMeter,在http请求的 Body Data或BeanShell中写的中文,为什么都是乱码—都是方框中间有个问号. 而且字体非常小,看着吃力,乱码现象如下图:
- tasksetCPU亲和力&docke容器资源限制
[taskset详解] taskset设置cpu亲和力,taskset能够将一个或者多个进程绑定到一个或者多个处理器上运行 参数: 选项: -a, --all-tasks 在给定 pid 的所有任务( ...
- Docker技术底层架构剖析
[Docker 底层技术] docker底层的 2 个核心技术分别是 Namespaces 和 Control groups 在操作系统中,网络配置,进程,用户,IPC(进程之间的调用)等信息之间的 ...
- Centos7X部署Zabbix监控
一:yum安装LAMP环境 zabbix-server端防火墙配置(可以选择iptables -F清空) iptables -A INPUT -m state --state NEW -m tcp - ...