论文泛读 A Novel Ensemble Learning-based Approach for Click Fraud Detection in Mobile Advertising [1/10]
title:新的基于集成学习的移动广告作弊检测
导语:基于buzzcity数据集,我们提出了对点击欺诈检测是基于一组来自现有属性的新功能的一种新方法。根据所得到的精度、召回率和AUC对所提出的模型进行评估。最后的模型基于6种不同的学习算法。我们用刚才说的三种指标,来证明模型是稳定的。我们的最终模型在训练、验证和测试数据集上显示了改进的结果,从而证明了它对不同数据集的普遍性。
1.Introduction 导入
大部分都是废话
1.1 Problem Formulation 问题构建
数据是用的buzzcity的数据,数据格式:http://www.dnagroup.org/PDF/FDMADataDescription.pdf
一个二分类问题,检测流量方publisher是是否在作弊。(实际上训练集里面有三种label,作弊,未作弊,和不确定)
衡量标准:resulting precision, recall and the area under the ROC curve,准确率,召回率,和AUC
2 Data Preprocessing and Feature Creation 数据预处理和特征工程
2.1 数据预处理:
先找出有用的特征,所有的数据为iplong, agent, partner id, campaign ID, country, time-at, category, referrer in the clicktable and partner id, address, bank account and label in the partner table,去掉无用的,比如partner address, bank account。
合并两个表(publisher database and click database)
2.2 特征提取:
借鉴了google反作弊的特征选择,以及其他的传统方向。
对于时间而言:作弊的方法一般有,第一种通常会使用各种技巧伪装自己的活动,例如生成非常稀疏的点击序列、IP地址的更改、从不同国家的计算机发出点击等等。另一些坚持只在给定时间间隔内产生最大点击次数的传统方法。针对这些,我们会选择1 min, 5 min, 1 hours, 3hours and 6 hours.的时间间隔,来统计他们的总点击次数,最大点击数、平均点击数、偏度和方差。
实际上我们就只会对于每一个时间间隔,统计平均值,最大值,方差,偏度

对于IP而言:构造五种特征:
1.最大同IP点击:一个IP地址最多的点击数量
2.IP数量:就对于每一个流量方,点击它广告的IP数量
3.每个IP的平均点击数量
4.熵的计算:IP点击的熵
5.方差:IP点击数量的方差
有些作弊是采用在一些ip上进行大量的点击,所以导致方差变高。
剩下的特征都差不多处理方式,类似于IP,一共创造了41种特征,链接在下面:http://www.dnagroup.org/PDF/FDMAFeatures.pdf
2.3 特征选择
特征选择用了三种方法:主成分分析(PCA)、公共空间模式(CSP)和wrapper subset evaluation
https://en.wikipedia.org/wiki/Principal_component_analysis
https://en.wikipedia.org/wiki/Common_spatial_pattern
wrapper subset evaluation是贪心的选择出一些特征集合来进行训练,用10-fold来进行衡量
3.Experimental Configuration 实验配置
3.1 Datasets
三个集合,训练集,从训练集拆出来的验证集,测试集。
训练集中,click database有3173834个实例,每个实例表示一个点击。publisher database有3081个,并且有标签标识是否在作弊。
验证集:2689005个点击,3064个publisher
测试集:2598815点击, 2112 publisher.
3.2 Platform and Tools Used
i7cpu,8G内存。特征的预处理用的matlab,数据存储用的mysql,模型训练用的WEKA。
3.3 Methods Used 方法使用
论文在这儿,说了一堆废话,他尝试了很多模型,发现决策树最厉害,所以我们就用决策树了。
在我们的数据中数据有2.336的作弊者、2.596的不确定和95.068的未作弊,我们面临数据倾斜的问题。为了解决这个问题,我们用了smote算法来拟合出更多的反例。
用了Bagging Metacost还有 logiboost来进行集成学习。
4 Results
用acc作为衡量标准,模型为:
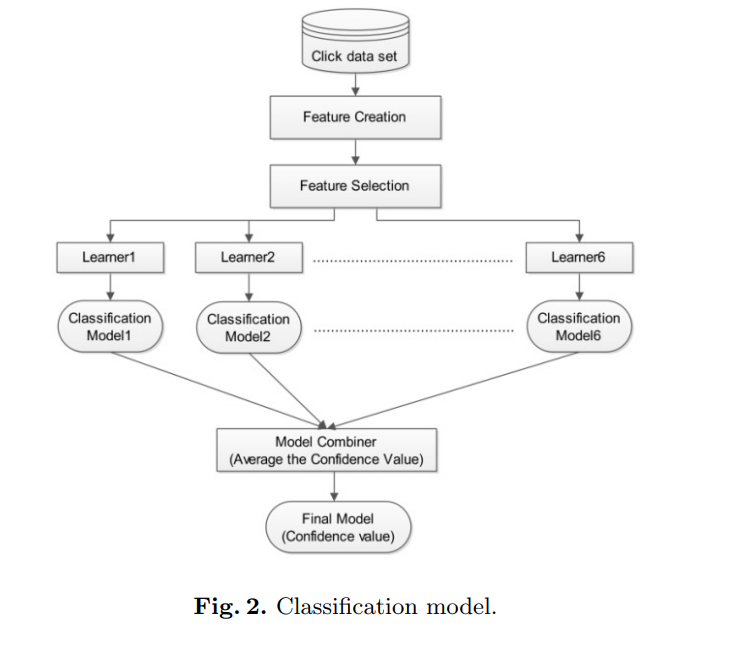
最后将6个模型取平均,就得到了最后的答案。

基础模型,总共就上面三种之一。
然后作者给我们展现了,如果你不做某个环节,你就亏了的故事。
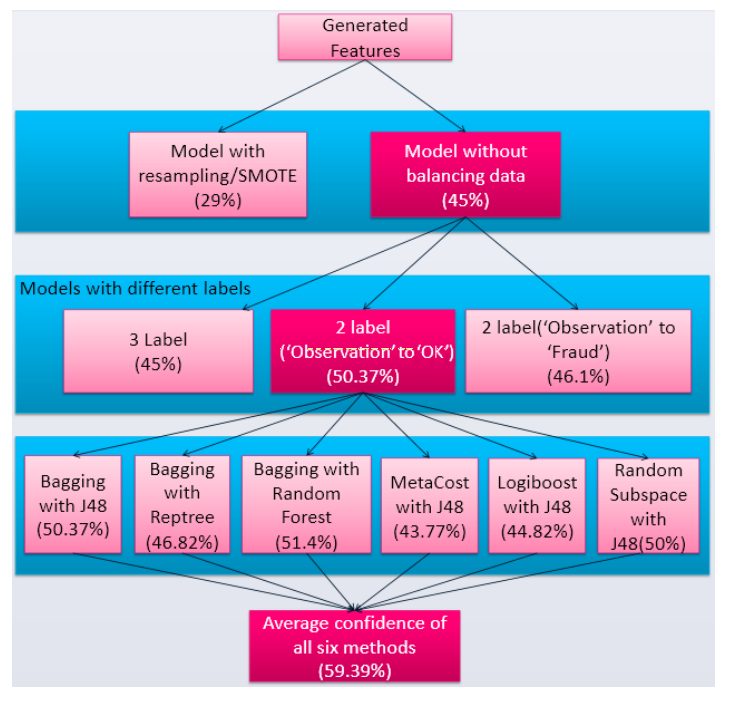
5 Discussions and Conclusion
作者总结出,作弊者一般采用更换代理,点击间隔在1min~6hour之间的一些方法来作弊。
作者表示以后应该多用一些特征处理方法,比如做一些交叉特征来处理。
特征工程方面:
样本不均匀:过抽样和欠抽样,smote。或者构建小的数据集,类似随机森林。
在模型融合方面:作者太过于粗糙,实际上还有stacking,blending等方法https://mlwave.com/kaggle-ensembling-guide/
论文泛读 A Novel Ensemble Learning-based Approach for Click Fraud Detection in Mobile Advertising [1/10]的更多相关文章
- 论文泛读:Click Fraud Detection: Adversarial Pattern Recognition over 5 Years at Microsoft
这篇论文非常适合工业界的人(比如我)去读,有很多的借鉴意义. 强烈建议自己去读. title:五年微软经验的点击欺诈检测 摘要:1.微软很厉害.2.本文描述了大规模数据挖掘所面临的独特挑战.解决这一问 ...
- 论文泛读·Adversarial Learning for Neural Dialogue Generation
原文翻译 导读 这篇文章的主要工作在于应用了对抗训练(adversarial training)的思路来解决开放式对话生成(open-domain dialogue generation)这样一个无监 ...
- NLP论文泛读之《教材在线评论的情感倾向性分析》
NLP论文泛读之<教材在线评论的情感倾向性分析> 本文借助细粒度情感分类技术, 对从网络上抓取大量计算机专业本科教材的评价文本进行情感极性 分析, 从而辅助商家和出版社改进教材的质量.制定 ...
- 【软件分析与挖掘】Multiple kernel ensemble learning for software defect prediction
摘要: 利用软件中的历史缺陷数据来建立分类器,进行软件缺陷的检测. 多核学习(Multiple kernel learning):把历史缺陷数据映射到高维特征空间,使得数据能够更好地表达: 集成学习( ...
- 论文笔记: Deep Learning based Recommender System: A Survey and New Perspectives
(聊两句,突然记起来以前一个学长说的看论文要能够把论文的亮点挖掘出来,合理的进行概括23333) 传统的推荐系统方法获取的user-item关系并不能获取其中非线性以及非平凡的信息,获取非线性以及非平 ...
- 论文翻译:2021_Towards model compression for deep learning based speech enhancement
论文地址:面向基于深度学习的语音增强模型压缩 论文代码:没开源,鼓励大家去向作者要呀,作者是中国人,在语音增强领域 深耕多年 引用格式:Tan K, Wang D L. Towards model c ...
- 论文笔记(2):A fast learning algorithm for deep belief nets.
论文笔记(2):A fast learning algorithm for deep belief nets. 这几天继续学习一篇论文,Hinton的A Fast Learning Algorithm ...
- 壁虎书7 Ensemble Learning and Random Forests
if you aggregate the predictions of a group of predictors,you will often get better predictions than ...
- Ensemble learning(集成学习)
定义 集成学习是一种机器学习范式,其中多个学习器被训练来解决相同的问题. 这与试图从训练数据中学习一个假设的普通机器学习方法相反,集成方法尝试构造一组假设并将它们结合使用. 一个集合包含一些通常被称为 ...
随机推荐
- Oracle数据库表索引失效,解决办法:修改Oracle数据库优化器模式
ALTER SYSTEM SET OPTIMIZER_MODE=RULE scope=both; 其他可以选择的模式还有ALL_ROWS/CHOOSE/FIRST_ROWS/ALL_ROWS. 应用系 ...
- 标准C语言实现基于TCP/IP协议的文件传输
TCP/IP编程实现远程文件传输在LUNIX中一般都采用套接字(socket)系统调用. 采用客户/服务器模式,其程序编写步骤如下: 1.Socket系统调用 为了进行网络I/O,服务器和客户机两 ...
- Redis-Sentinel 哨兵
为什么需要哨兵? 一旦主节点宕机,那么需要人为修改所有应用方的主节点地址(改为新的master地址),还需要命令所有从节点复制新的主节点 那么这个问题,redis-sentinel就可以解决了 什么是 ...
- 用webstorm搭建vue项目
本文只针对新手. 首先要明白几个名词(概念). Node.js: Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境. Node.js 使用了一个事件驱动.非阻塞式 ...
- tomcat-会话绑定
会话保存 1) session sticky source_ip 原地址绑定 nginx: ip_hash haproxy: source lvs: ...
- window下用taskkill杀死进程
TASKKILL [/S system [/U username [/P [password]]]] { [/FI filter] [/PID processid | /IM imagename] } ...
- >maven-compiler-plugin的理解
在maven中项目中这个插件一直都会看见,但是一直没有认真学习一下为啥使用,现在有空就查询学习一下. 1.使用场景 下载了一些工程需要编译的时候. maven是个项目管理工具,如果我们不告诉它我们的代 ...
- vue回调函数无法更改model的值
data:{ isUpload:true, } 点击上传函数: getFile(event) { //选择图片 let eventId = event.target.id; let type= tes ...
- Idea问题:“marketplace plugins are not loaded”解决方案
博主本人遇见该问题时是想要通过Idea的plugins工具下载阿里巴巴的代码规约工具 但是在我点开settings,然后打开plugins工具时竟然给我提示“marketplace plugins a ...
- JavaEE-Servlet的部署和配置
1.:配置好相应环境和检查tomcat8.5能否运行,详见https://www.cnblogs.com/LJHAHA/p/10461697.html 2.将tomcat8.5下的webapps目录中 ...