EM算法 大白话讲解
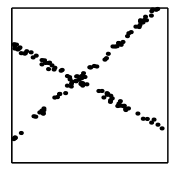
假设有一堆数据点 ,它是由两个线性模型产生的。公式如下:
,它是由两个线性模型产生的。公式如下:
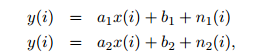
模型参数为a,b,n:a为线性权值或斜率,b为常数偏置量,n为误差或者噪声。
一方面,假如我们被告知这两个模型的参数,则我们可以计算出损失。
对于第i个数据点,第k个模型会预测它的结果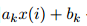
则,与真实结果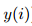 的差或者损失记为:
的差或者损失记为: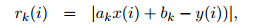
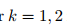
目标是最小化这个误差。
但是仍然不知道具体哪些数据由对应的哪个模型产生的。
另一方面,假设我们被告知这些数据对应具体哪个模型,则问题简化为求解约束条件下的线性方程解
(实际上可以计算出最小均分误差下的解,^-^)。
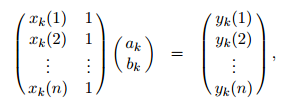
这两个假设,都只知道其中的一部分信息,所以求解困难。
EM算法就是重复迭代上述两步,固定因素A,放开因素B,然后固定因素B,再放开因素A,直到模型收敛,
如此迭代更新估计出模型的输出值以及参数值。
具体如下:
--------------------------------------------------------------------------------------------------------
在E步时,模型参数假定已知(随机初始化或者聚类初始化,后续不断迭代更新参数),
计算出每个点属于模型的似然度或者概率(软判决,更加合理,后续可以不断迭代优化,而硬判决不合理是因为之前的假定参数本身不可靠,判决准则也不可靠)。
根据模型参数,如何计算出似然度?
计算出模型输出值与真实值的残差:
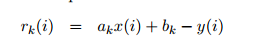
已知残差,计算出i点属于k模型的似然度(残差与似然度建立关系):
贝叶斯展开

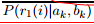 =
= 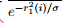 ,假设残差与概率分布为高斯分布,残差距离度量 转换成 概率度量。
,假设残差与概率分布为高斯分布,残差距离度量 转换成 概率度量。
残差越小,则发生概率越大。
根据产生的残差,判断i属于模型k的归属概率
则,

完成点分配到模型的目的
--------------------------------------------------------------------------------------------------------
--------------------------------------------------------------------------------------------------------
进入M步,知道各个点属于对应模型的概率,利用最小均分误差,估计出模型参数
绝对值差*概率,误差期望最小化
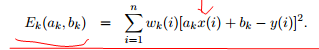 最小化
最小化
求偏导:
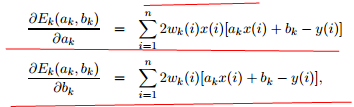
置0,则上述两公式展开为
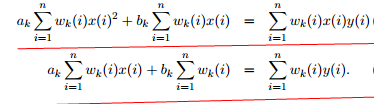
改写成 矩阵式:
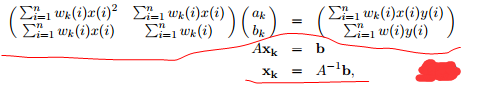
完成计算出ak和bk参数
如此,反复迭代,收敛
EM算法对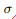 敏感,每轮迭代它的更新推荐公式:
敏感,每轮迭代它的更新推荐公式:
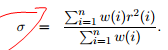
--------------------------------------------------------------------------------

同样地,在 GMM 中,我们就需要确定 影响因子pi(k)、各类均值pMiu(k) 和 各类协方差pSigma(k) 这些参数。 我们的想法是,找到这样一组参数,它所确定的概率分布生成这些给定的数据点的概率最大,而这个概率实际上就等于  ,我们把这个乘积称作似然函数 (Likelihood Function)
,我们把这个乘积称作似然函数 (Likelihood Function)
没法直接用求导解方程的办法直接求得最大值。
不清楚这类数据是具体哪个高斯生成的,或者说生成的概率。
E步中,确定出数据xi属于第i个高斯的概率:通过计算各个高斯分量的后验概率,占比求得。
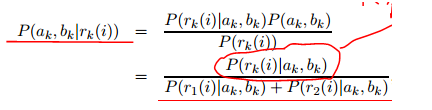
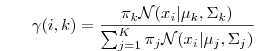
解决了点的归属。
M步中,重新计算出各个参数。
知道了各个点属于各个高斯的概率,可以重新计算求出 均值、方差、权重

如此EM重复。
参考:http://blog.csdn.net/abcjennifer/article/details/8198352
--------------------------------------------------------------------------------------------------------
EM算法 大白话讲解的更多相关文章
- 【机器学习】EM算法详细推导和讲解
今天不太想学习,炒个冷饭,讲讲机器学习十大算法里有名的EM算法,文章里面有些个人理解,如有错漏,还请读者不吝赐教. 众所周知,极大似然估计是一种应用很广泛的参数估计方法.例如我手头有一些东北人的身高的 ...
- 转载:EM算法的最精辟讲解
机器学习十大算法之一:EM算法.能评得上十大之一,让人听起来觉得挺NB的.什么是NB啊,我们一般说某个人很NB,是因为他能解决一些别人解决不了的问题.神为什么是神,因为神能做很多人做不了的事.那么EM ...
- 从数学角度看最大期望(EM)算法 I
[转载请注明出处]http://www.cnblogs.com/mashiqi 2014/11/18 更新.发现以前的公式(2)里有错误,现已改过来.由于这几天和Can讨论了EM算法,回头看我以前写的 ...
- 机器学习第三课(EM算法和高斯混合模型)
极大似然估计,只是一种概率论在统计学的应用,它是参数估计的方法之一.说的是已知某个随机样本满足某种概率分布,但是其中具体的参数不清楚,参数估计就是通过若干次试验,观察其结果,利用结果推出参数的大概值. ...
- 猪猪的机器学习笔记(十四)EM算法
EM算法 作者:樱花猪 摘要: 本文为七月算法(julyedu.com)12月机器学习第十次次课在线笔记.EM算法全称为Expectation Maximization Algorithm,既最大 ...
- 机器学习——EM算法
1 数学基础 在实际中,最小化的函数有几个极值,所以最优化算法得出的极值不确实是否为全局的极值,对于一些特殊的函数,凸函数与凹函数,任何局部极值也是全局极致,因此如果目标函数是凸的或凹的,那么优化算法 ...
- 学习笔记——EM算法
EM算法是一种迭代算法,用于含有隐变量(hidden variable)的概率模型参数的极大似然估计,或极大后验概率估计.EM算法的每次迭代由两步组成:E步,求期望(expectation):M步,求 ...
- K-Means聚类和EM算法复习总结
摘要: 1.算法概述 2.算法推导 3.算法特性及优缺点 4.注意事项 5.实现和具体例子 6.适用场合 内容: 1.算法概述 k-means算法是一种得到最广泛使用的聚类算法. 它是将各个聚类子集内 ...
- EM算法总结
EM算法总结 - The EM Algorithm EM是我一直想深入学习的算法之一,第一次听说是在NLP课中的HMM那一节,为了解决HMM的参数估计问题,使用了EM算法.在之后的MT中的词对齐中也用 ...
随机推荐
- Init.rc分析(刘举奎)
http://www.360doc.com/content/14/0926/20/13253385_412582822.shtml
- 猜数游戏-flag的运用
package my;import java.util.Scanner;public class MyJava { public static void main(String[] ar ...
- nginx+fastcgi php 使用file_get_contents、curl、fopen读取localhost本站点.php异常的情况
原文:http://www.oicto.com/nginx_fastcgi_php_file_get_contents/ 参考:http://os.51cto.com/art/201408/44920 ...
- 利用 gperftools 对nginx mysql 内存管理 性能优化
利用 gperftools 对nginx 与 mysql 进行 内存管理 性能优化 降低负载. Gperftools 是由谷歌开发.官方对gperftools 的介绍为: These tools ...
- sencha touch视频教程
链接地址:http://v.youku.com/v_show/id_XOTI1MDg1ODQ4.html
- HDU 5650 so easy
n不为1的时候输出a[1],否则输出0 #include<cstdio> #include<cstring> #include<cmath> #include< ...
- KERMIT,XMODEM,YMODEM,ZMODEM传输协议小结(转)
源:KERMIT,XMODEM,YMODEM,ZMODEM传输协议小结 Kermit协议 报文格式: 1.MARK,起始标记START_CHAR,为 0x01(CTRIL-A): 2.LEN,报文剩余 ...
- stm32驱动DS1302芯片
天时可以自动调整,且具有闰年补偿功能.工作电压宽达2.5-5.5V.采用双电源供电(主电源和备用电源),可设置备用电源充电方式,提供了对后背电源进行涓细电流充电的能力.DS1302的外部引脚分配如下图 ...
- ireport 取消自动分页,detail不分页,当没有数据的时候显示title
报表文件属性页面 lgnore pagination 勾选上,就可以取消分页功能.
- ERROR 1044 (42000): Access denied for user ''@'localhost' to database 'mysql'
提示:ERROR 1044 (42000): Access denied for user ''@'localhost' to database 'mysql'.前两天也出现过这个问题,网上找了一个比 ...