如何使用 Yolov4 训练人脸口罩检测模型
前言
疫情当下,出入医院等公共场所都被要求佩戴口罩。这篇博客将会介绍如何使用 Yolov4,训练一个人脸口罩检测模型(使用 Yolov4 的原因是目前只复现到了 v4 ),代码地址为 https://github.com/zhiyiYo/yolov4。
Yolov4
Yolov4 的神经网络结构相比 Yolov3 变化不是很大,主要更换了激活函数为 Mish,增加了 SPP 块和 PAN 结构(图源 《yolo系列学习笔记----yolov4(SPP原理)》)。
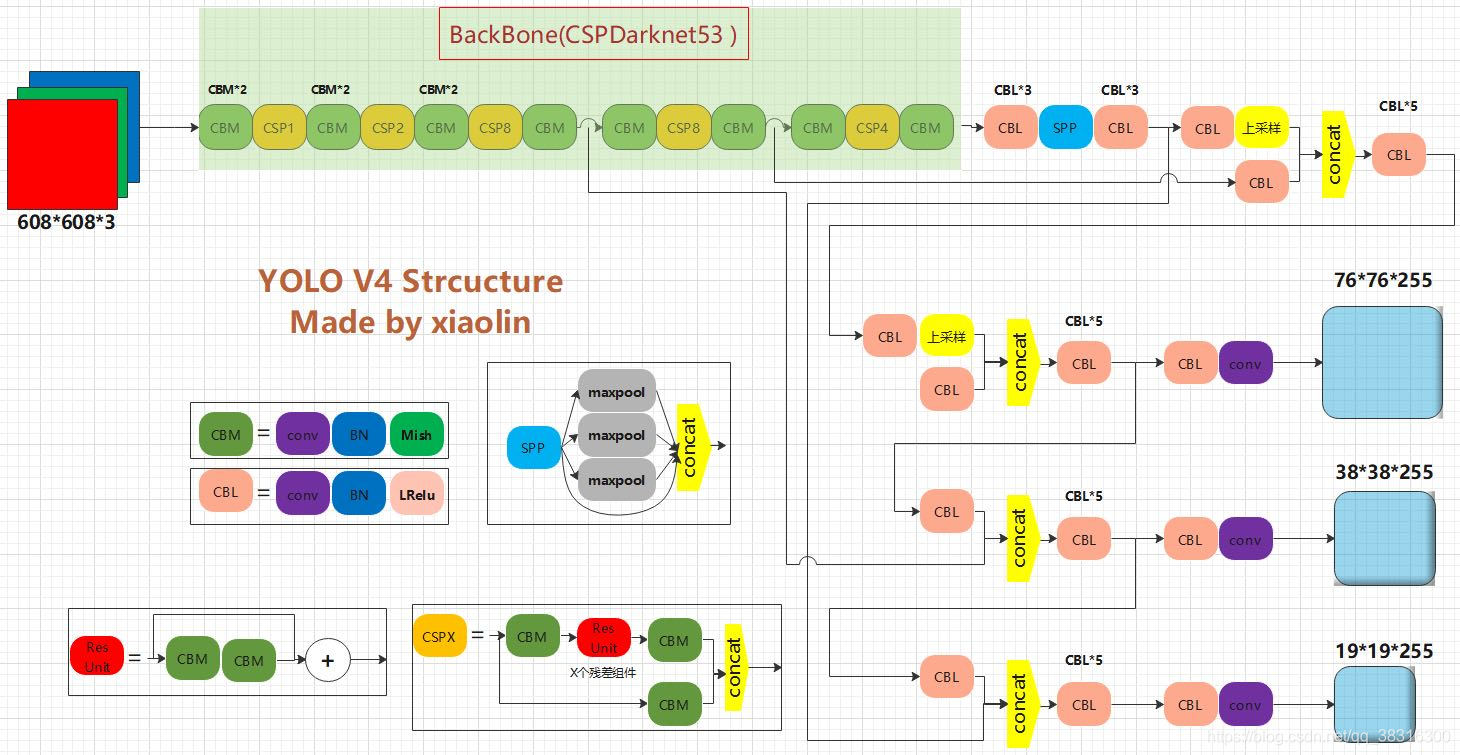
感觉 Yolov4 最大的特点就是使用了一大堆的 Trick,比如数据增强方面使用了马赛克数据增强、Mixup 数据增强,将定位损失函数更换为 CIOU 损失。论文中提到了很多的 Trick,我的代码中没有全部复现,不过在 VOC2012 数据集训练了 160 个 epoch 之后 mAP 也能达到 83%,效果还是不错的。
可以在终端使用下述指令下载 Yolov4 的代码:
git clone https://github.com/zhiyiYo/yolov4.git
人脸口罩数据集
网上可以找到很多人脸口罩数据集,这里使用的是 AIZOOTech 提供的数据集。由于这个数据集的结构和 Pascal VOC 数据集不一样,所以重新组织一下数据集,并且修复和移除了数据集中的非法标签,可以在 Kaggle 上下载此数据集。目前这个数据集包含 6130 张训练图像,1839 张测试图像,对于 Yolov4 的训练来说应该是绰绰有余的。下载完数据集将其解压到 data 文件夹下。
在训练之前,我们需要使用 K-means 聚类算法对训练集中的边界框进行聚类,对于 416×416 的输入图像,聚类结果如下:
anchors = [
[[100, 146], [147, 203], [208, 260]],
[[26, 43], [44, 65], [65, 105]],
[[4, 8], [8, 15], [15, 27]]
]
训练神经网络
训练目标检测模型一般都需要加载预训练的主干网络的权重,可以从谷歌云盘下载预训练好的权重 CSPDarknet53.pth 并将其放在 model 文件夹下。这里给出训练所用的代码 train.py,使用 python train.py 就能开始训练。模型会先冻结训练上 50 个 epoch,接着解冻训练 110 个 epoch:
# coding:utf-8
from net import TrainPipeline, VOCDataset
from utils.augmentation_utils import YoloAugmentation, ColorAugmentation
# 训练配置
config = {
"n_classes": len(VOCDataset.classes),
"image_size": 416,
"anchors": [
[[100, 146], [147, 203], [208, 260]],
[[26, 43], [44, 65], [65, 105]],
[[4, 8], [8, 15], [15, 27]]
],
"darknet_path": "model/CSPdarknet53.pth",
"lr": 1e-2,
"batch_size": 8,
"freeze_batch_size": 16,
"freeze": True,
"freeze_epoch": 50,
"max_epoch": 160,
"start_epoch": 0,
"num_workers": 4,
"save_frequency": 10,
"no_aug_ratio": 0
}
# 加载数据集
root = 'data/FaceMaskDataset/train'
dataset = VOCDataset(
root,
'all',
transformer=YoloAugmentation(config['image_size']),
color_transformer=ColorAugmentation(config['image_size']),
use_mosaic=True,
use_mixup=True,
image_size=config["image_size"]
)
if __name__ == '__main__':
train_pipeline = TrainPipeline(dataset=dataset, **config)
train_pipeline.train()
测试神经网络
训练完使用 python evals.py 可以测试所有保存的模型,evals.py 代码如下:
# coding:utf-8
import json
from pathlib import Path
import matplotlib as mpl
import matplotlib.pyplot as plt
from net import EvalPipeline, VOCDataset
mpl.rc_file('resource/theme/matlab.mplstyle')
# 载入数据集
root = 'data/FaceMaskDataset/val'
dataset = VOCDataset(root, 'all')
anchors = [
[[100, 146], [147, 203], [208, 260]],
[[26, 43], [44, 65], [65, 105]],
[[4, 8], [8, 15], [15, 27]]
]
# 列出所有模型,记得修改 Yolo 模型文件夹的路径
model_dir = Path('model/2022-10-05_22-59-44')
model_paths = [i for i in model_dir.glob('Yolo_*')]
model_paths.sort(key=lambda i: int(i.stem.split("_")[1]))
# 测试所有模型
mAPs = []
iterations = []
for model_path in model_paths:
iterations.append(int(model_path.stem[5:]))
ep = EvalPipeline(model_path, dataset, anchors=anchors, conf_thresh=0.001)
mAPs.append(ep.eval()*100)
# 保存数据
with open('eval/mAPs.json', 'w', encoding='utf-8') as f:
json.dump(mAPs, f)
# 绘制 mAP 曲线
fig, ax = plt.subplots(1, 1, num='mAP 曲线')
ax.plot(iterations, mAPs)
ax.set(xlabel='iteration', ylabel='mAP', title='mAP curve')
plt.show()
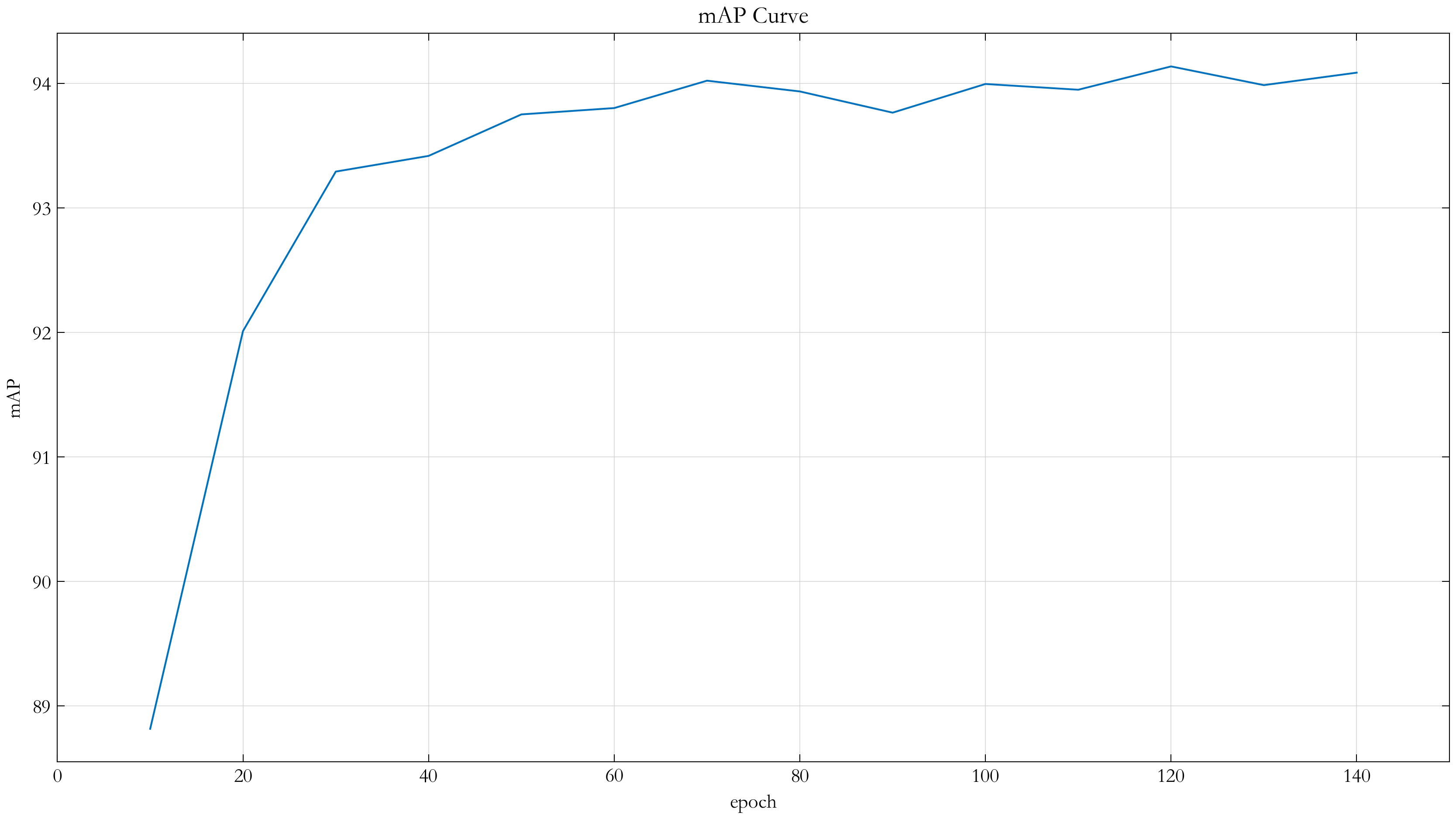
得到的 mAP 曲线如下图所示,在第 120 个 epoch 达到最大值 94.14%:
下面使用一张真实图像看看训练效果如何,运行 demo.py:
# coding:utf-8
from net import VOCDataset
from utils.detection_utils import image_detect
# 模型文件和图片路径
model_path = 'model/Yolo_120.pth'
image_path = 'resource/image/三上老师.jpg'
# 检测目标
anchors = [
[[100, 146], [147, 203], [208, 260]],
[[26, 43], [44, 65], [65, 105]],
[[4, 8], [8, 15], [15, 27]]
]
image = image_detect(model_path, image_path, VOCDataset.classes, anchors=anchors, conf_thresh=0.5)
image.show()
不错,效果非常好 :

后记
至此,介绍完了训练 Yolov4 人脸口罩检测模型的过程,代码放在了 https://github.com/zhiyiYo/yolov4,以上~~
如何使用 Yolov4 训练人脸口罩检测模型的更多相关文章
- K210,yolo,face_mask口罩检测模型训练及其在K210,kd233上部署
前段时间考研,再加上工作,时间很紧,一直没有更新博客,这几天在搞k210的目标检测模型,做个记录,遇到问题可以添加qq522414928或添加微信13473465975,共同学习 首先附上github ...
- PyTorch专栏(八):微调基于torchvision 0.3的目标检测模型
专栏目录: 第一章:PyTorch之简介与下载 PyTorch简介 PyTorch环境搭建 第二章:PyTorch之60分钟入门 PyTorch入门 PyTorch自动微分 PyTorch神经网络 P ...
- 微调torchvision 0.3的目标检测模型
微调torchvision 0.3的目标检测模型 本文将微调在 Penn-Fudan 数据库中对行人检测和分割的已预先训练的 Mask R-CNN 模型.它包含170个图像和345个行人实例,说明如何 ...
- 人脸检测及识别python实现系列(5)——利用keras库训练人脸识别模型
人脸检测及识别python实现系列(5)——利用keras库训练人脸识别模型 经过前面稍显罗嗦的准备工作,现在,我们终于可以尝试训练我们自己的卷积神经网络模型了.CNN擅长图像处理,keras库的te ...
- 基于TensorFlow Object Detection API进行迁移学习训练自己的人脸检测模型(二)
前言 已完成数据预处理工作,具体参照: 基于TensorFlow Object Detection API进行迁移学习训练自己的人脸检测模型(一) 设置配置文件 新建目录face_faster_rcn ...
- dlib人脸关键点检测的模型分析与压缩
本文系原创,转载请注明出处~ 小喵的博客:https://www.miaoerduo.com 博客原文(排版更精美):https://www.miaoerduo.com/c/dlib人脸关键点检测的模 ...
- Python 3 利用 Dlib 19.7 和 sklearn机器学习模型 实现人脸微笑检测
0.引言 利用机器学习的方法训练微笑检测模型,给一张人脸照片,判断是否微笑: 使用的数据集中69张没笑脸,65张有笑脸,训练结果识别精度在95%附近: 效果: 图1 示例效果 工程利用pytho ...
- ssd物体检测模型训练和测试总结
参考网址:github:https://github.com/naisy/realtime_object_detection 2018.10.16ssd物体检测总结:切记粗略地看一遍备注就开始训练模型 ...
- 用keras实现人脸关键点检测(2)
上一个代码只能实现小数据的读取与训练,在大数据训练的情况下.会造内存紧张,于是我根据keras的官方文档,对上一个代码进行了改进. 用keras实现人脸关键点检测 数据集:https://pan.ba ...
随机推荐
- 简单使用 MySQL 索引
MySQL 索引 1 什么是索引 在数据库表中,对字段建立索引可以大大提高查询速度.通过善用这些索引,可以令 MySQL 的查询和 运行更加高效. 如果合理的设计且使用索引的 MySQL 是一辆兰博基 ...
- 破坏正方形UVA1603
题目大意 有一个由火柴棍组成的边长为n的正方形网格,每条边有n根火柴,共2n(n+1)根火柴.从上至下,从左到右给每个火柴编号,现在拿走一些火柴,问在剩下的后拆当中ongoing,至少还要拿走多少根火 ...
- 关于奇妙的 Fibonacci 的一些说明
奇妙的 Fibonacci,多次模拟赛中出现 同时也是 BZOJ 2813 一 Fibonacci 的 GCD 如果 \(F\) 是 Fibonacci 数列,那么众所周知的有 \(\gcd(F_i, ...
- Win10环境前后端分离项目基于Vue.js+Django+Python3实现微信(wechat)扫码支付流程(2021年最新攻略)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_182 之前的一篇文章:mpvue1.0+python3.7+Django2.0.4实现微信小程序的支付功能,主要介绍了微信小程序内 ...
- Vue3 computed && watch(watchEffect)
1 # Vue3 计算属性与监视 2 # 1.computed函数:与Vue2.x中的computed配置功能一致 3 inport {ref,computed,watch} from 'vue'; ...
- Odoo4 tree视图左上角新增Button
# 一.直接在tree根元素中新增.这种有个限制就是必须要勾选一或多条记录的时候按钮才会显示 <tree> <header> <button type="obj ...
- Redis 10 位图
参考源 https://www.bilibili.com/video/BV1S54y1R7SB?spm_id_from=333.999.0.0 版本 本文章基于 Redis 6.2.6 概述 Redi ...
- git使用的一些坑和新得(一)
这是一个坑 你要知道作为一个新手对git的使用还处于摸索状态 今天就将这样的坑分享给大家 昨天,接到任务将代码发到远程仓库里.于是,我就天真的按步骤提交了! 然后就: To https: ! [rej ...
- docker compose搭建redis7.0.4高可用一主二从三哨兵集群并整合SpringBoot【图文完整版】
一.前言 redis在我们企业级开发中是很常见的,但是单个redis不能保证我们的稳定使用,所以我们要建立一个集群. redis有两种高可用的方案: High availability with Re ...
- 【JDBC】学习路径1-JDBC背景知识
学习完本系列JDBC课程后,你就可以愉快使用Java操作我们的MySQL数据库了. 各种数据分析都不在话下了. 第一章:废话 JDBC编程,就是写Java的时候,调用了数据库. Java Databa ...