【机器学习】利用 Python 进行数据分析的环境配置 Windows(Jupyter,Matplotlib,Pandas)
环境配置
安装 python
博主使用的版本是 3.10.6
在 Windows 系统上使用 Virtualenv 搭建虚拟环境
- 安装 Virtualenv
打开 cmd 输入并执行
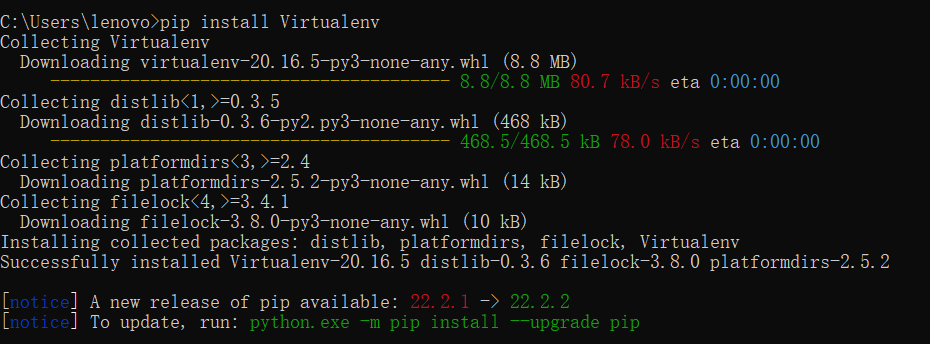
pip install Virtualenv
等待安装完成即可,如下图。
- 创建虚拟环境
进入自定义文件夹(Virtualenv),打开 cmd ,输入并执行
py -3 -m venv 虚拟环境名称

可以看到,自定义文件(Virtualenv)中创建了文件夹(virtualenvironment),即自定义的虚拟环境名称。
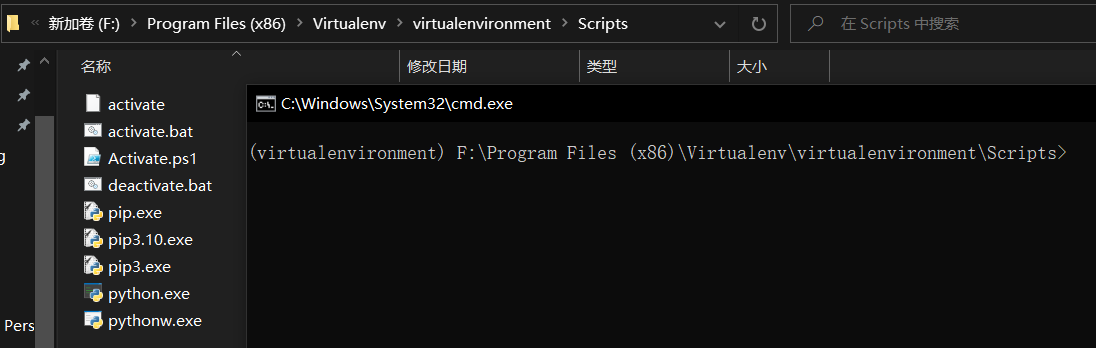
- 进入虚拟环境
进入该文件夹,再进入 Scripts,打开 cmd ,输入并执行
activate
- 退出虚拟环境
deactivate

- 将Scripts位置加入环境变量(可忽略)
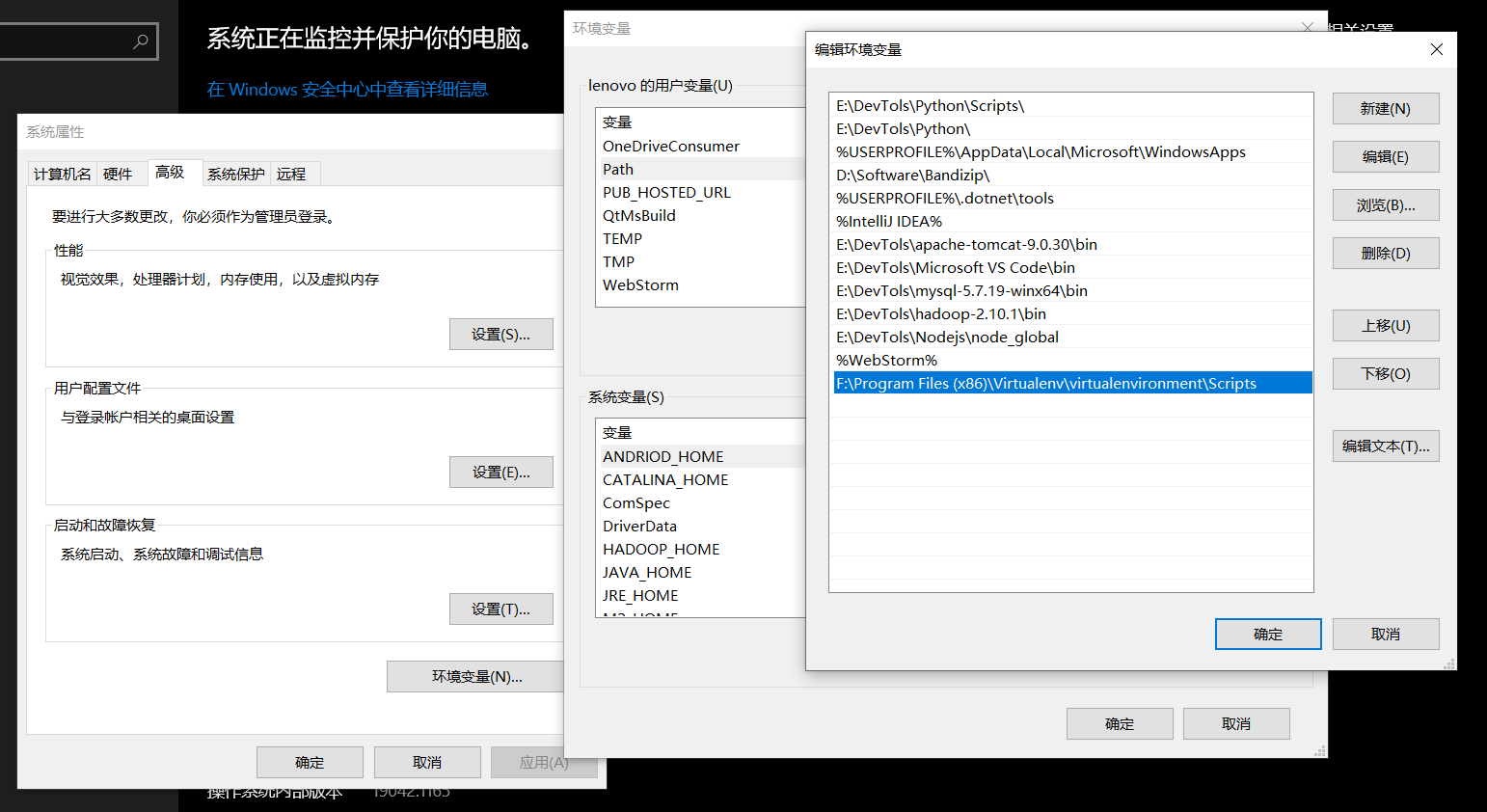
安装环境变量之后,可以在任意位置打开 cmd 进入虚拟环境,而不用先进入 Scripts 文件夹
软件安装(Windows 版)
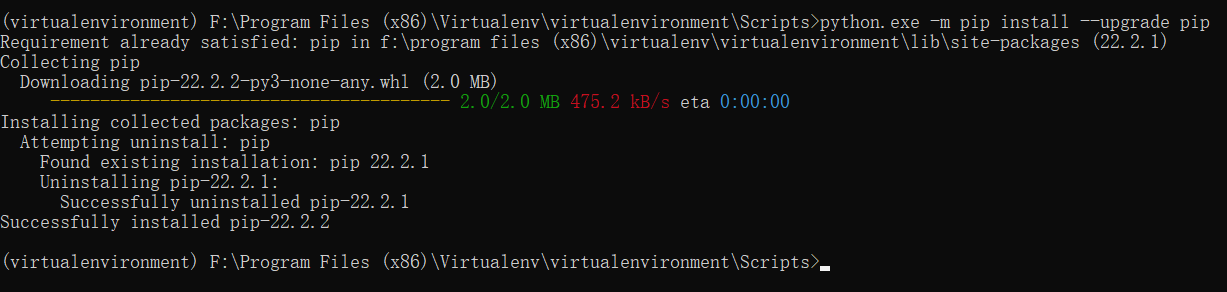
更新 pip
- 进入虚拟环境
- 更新
pip命令
输入并执行
python.exe -m pip install --upgrade pip
安装 matplotlib
输入并执行
pip install matplotlib
安装 pandas
输入并执行
pip install pandas
安装 TA-Lib
进入官网下载相关文件
https://www.lfd.uci.edu/~gohlke/pythonlibs/
注意只能下载指定版本,与本机 Python 版本一致
比如:TA_Lib-0.4.24-cp38-cp38-win_amd64.whl(前面是库版本 0.4.24,后面是对应的python版本 3.8。最后的数字代表 windows系统。32 位或者 64 位。电脑属性查看或者 cmd 里 python 查看)
一定要一一对应。否则会报 ERROR: TA_Lib-0.4.24-cp38-cp38-win32.whl is not a supported wheel on this platform.平台不符合的错误。
下载出来的文件不能改名。否则会报ERROR: TA_Lib64.whl(你更改后的文件名) is not a valid wheel filename.文件名无效错误。
将该文件放到虚拟环境的 Scripts 文件夹中,该步骤主要为了方便,如果没有配置环境变量
输入并执行(如果该文件在其他文件夹,请输入文件绝对地址)
pip install TA_Lib-0.4.24-cp310-cp310-win_amd64.whl
安装 tables
进入官网下载相关文件
https://www.lfd.uci.edu/~gohlke/pythonlibs/
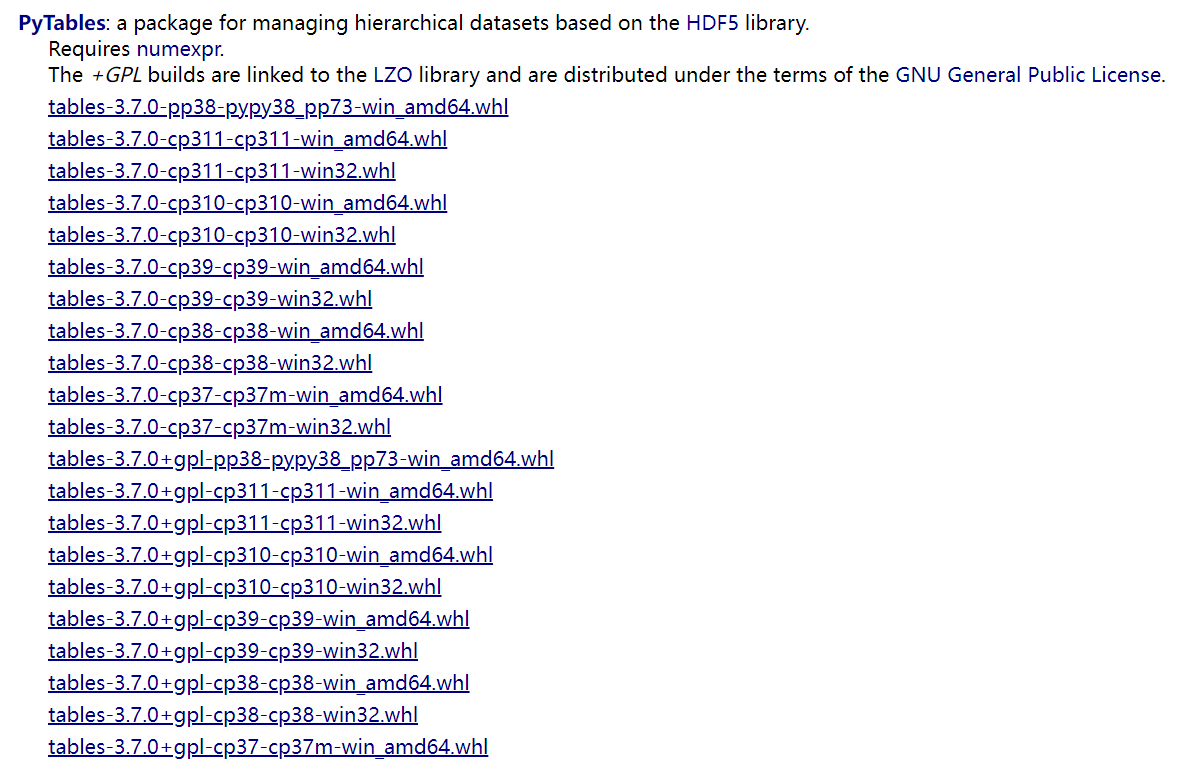
注意只能下载指定版本,与本机 Python 版本一致
输入并执行
pip install tables-3.7.0-cp310-cp310-win_amd64.whl
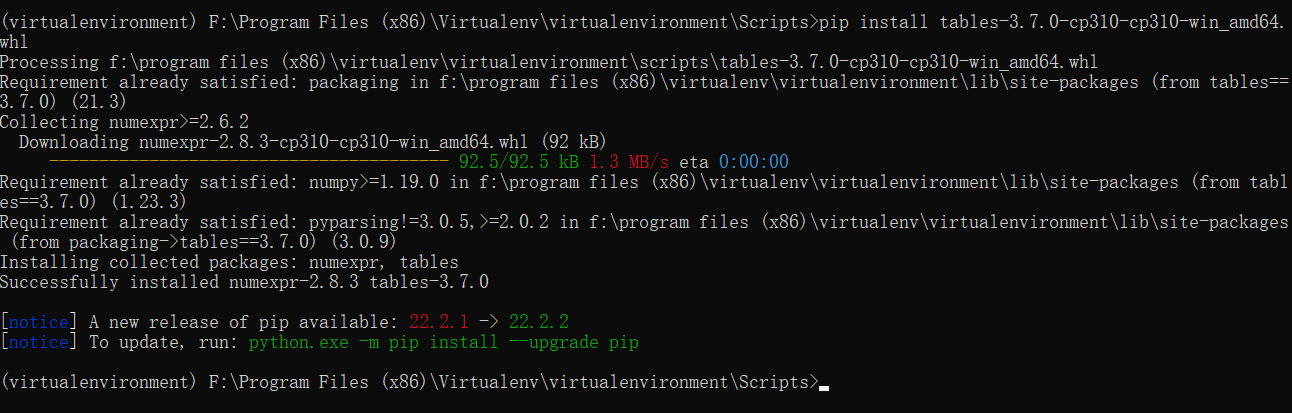
安装 jupytyer
输入并执行
pip install jupyter
Jupyter Notebook 使用
- 进入虚拟环境
- 输入并执行,即可进入网页端
jupyter notebook
# 或者
ipython notebook
可创建 python 文件,进行如下操作

每一行是一个 cell
快捷键:
ctrl enter:运行当前cell,留在当前cellshift enter:运行当前cell,创建并进入下一个cell
命令模式:
Y:cell 切换到 code 模式
M:cell 切换到 markdown 模式
A:在当前 cell 的上面添加 cell
B:在当前 cell 的下面添加 cell
双击D:删除当前 cell
编辑模式:
多光标操作:Ctrl 键点击鼠标
回退:Ctrl+Z
补全代码:变量、方法后跟 Tab 键
为一行或多行代码添加/取消注释:Ctrl+/
Matplotlib 使用
基本概念
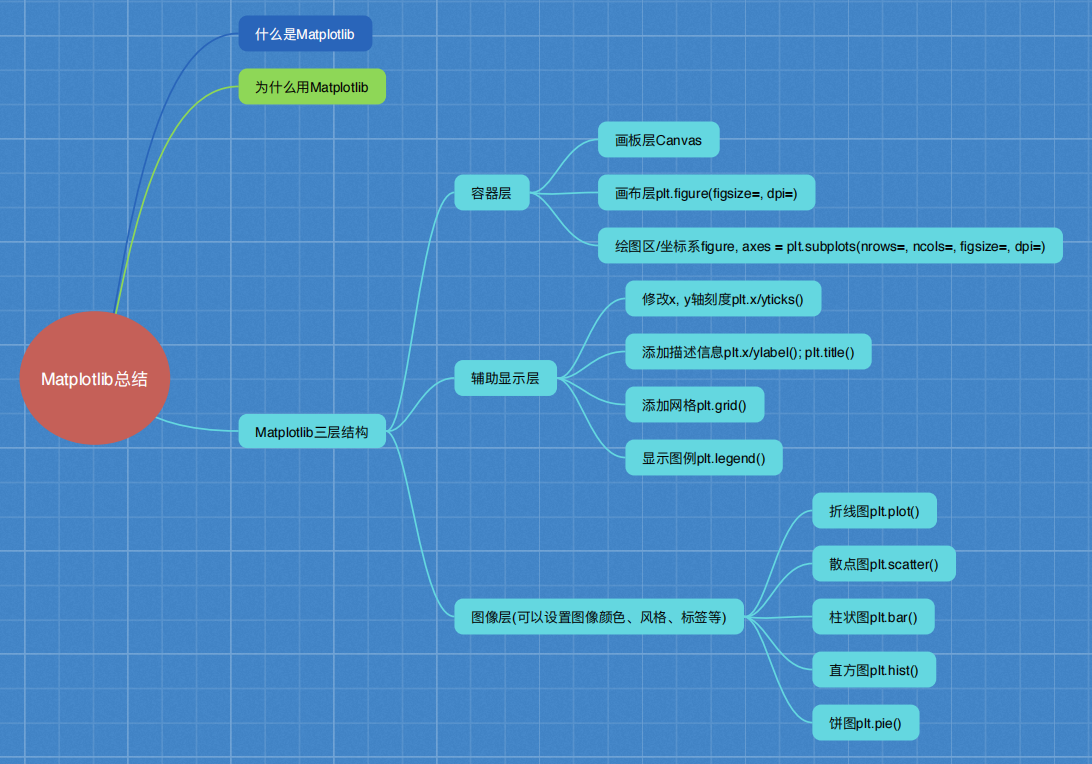
什么是Matplotlib : 画二维图表的python库
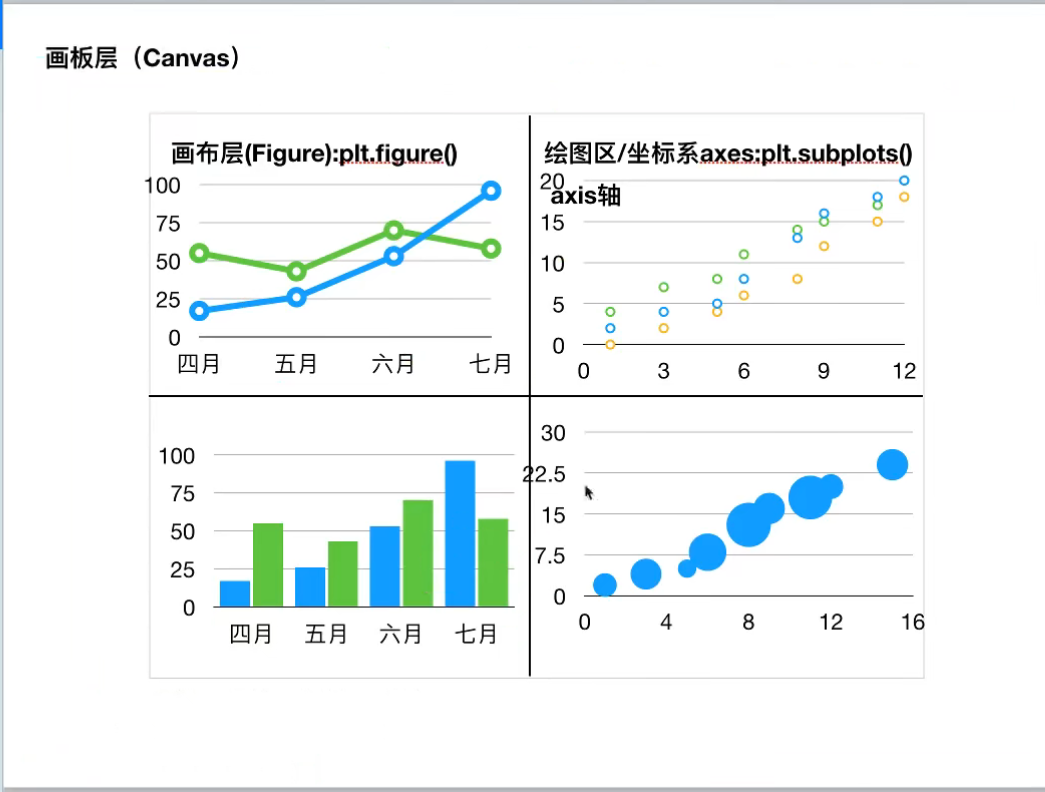
Matplotlib 三层结构:
- Canvas(画板)位于最底层,用户一般接触不到
- Figure(画布)建立在Canvas之上
- Axes(绘图区)建立在Figure之上
- 坐标轴(axis)、图例(legend)等辅助显示层以及图像层都是建立在Axes之上
快速入门
步骤
- 创建画布
- 绘制图像
- 显示图像
import matplotlib.pyplot as plt
import random
# 需求:再添加一个城市的温度变化
# 收集到北京当天温度变化情况,温度在1度到3度。
# 1、准备数据 x y
x = range(60)
y_shanghai = [random.uniform(15, 18) for i in x]
y_beijing = [random.uniform(1, 3) for i in x]
# 中文显示问题
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
# 2、创建画布
plt.figure(figsize=(20, 8), dpi=80)
# 3、绘制图像
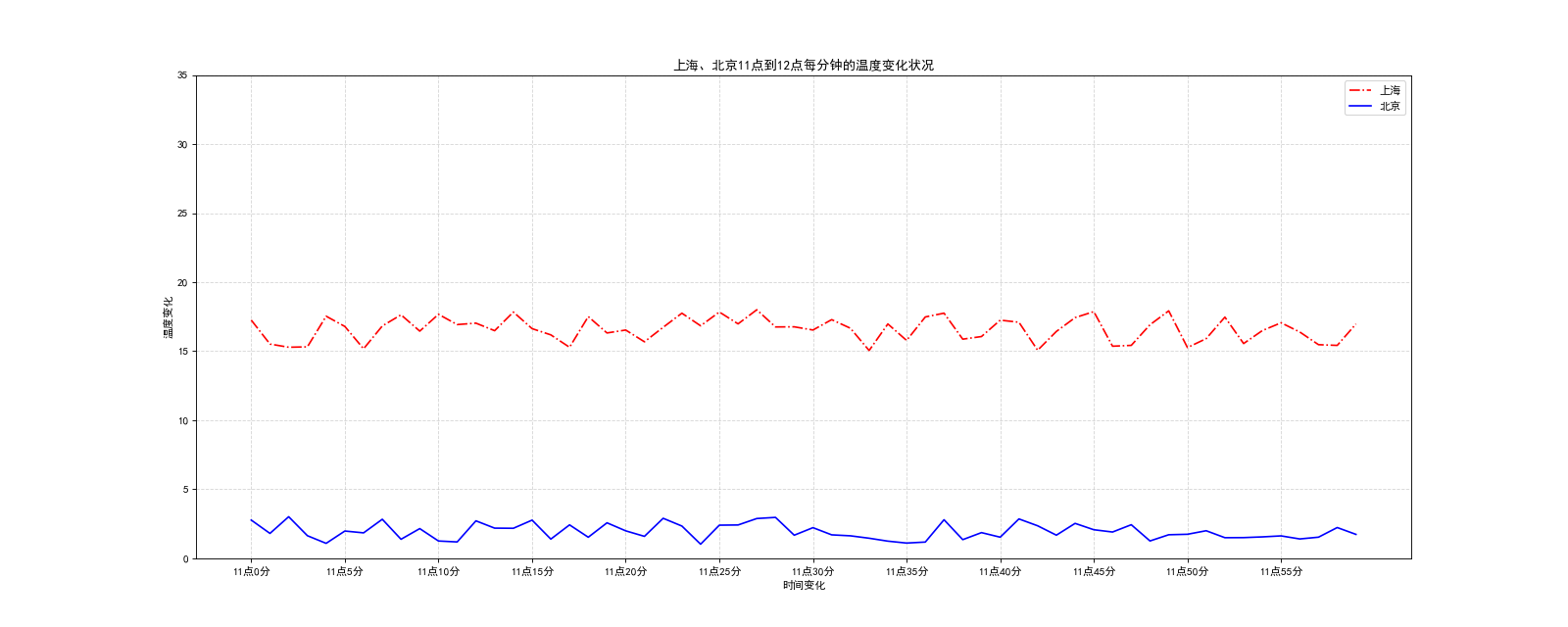
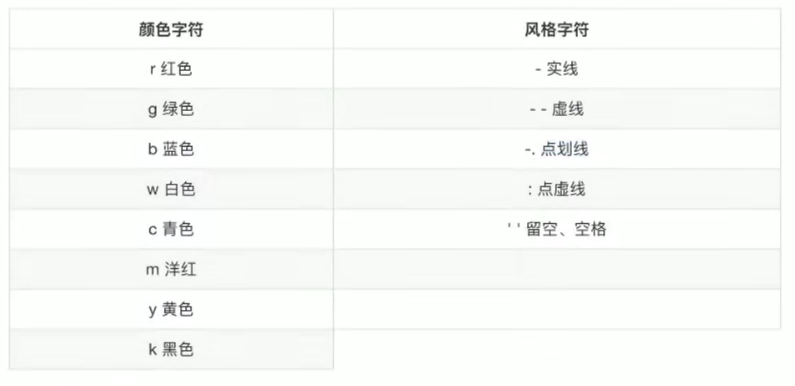
plt.plot(x, y_shanghai, color="r", linestyle="-.", label="上海")
plt.plot(x, y_beijing, color="b", label="北京")
# 显示图例,这里显示图例的前提是plt.plot时要添加标签label=“”
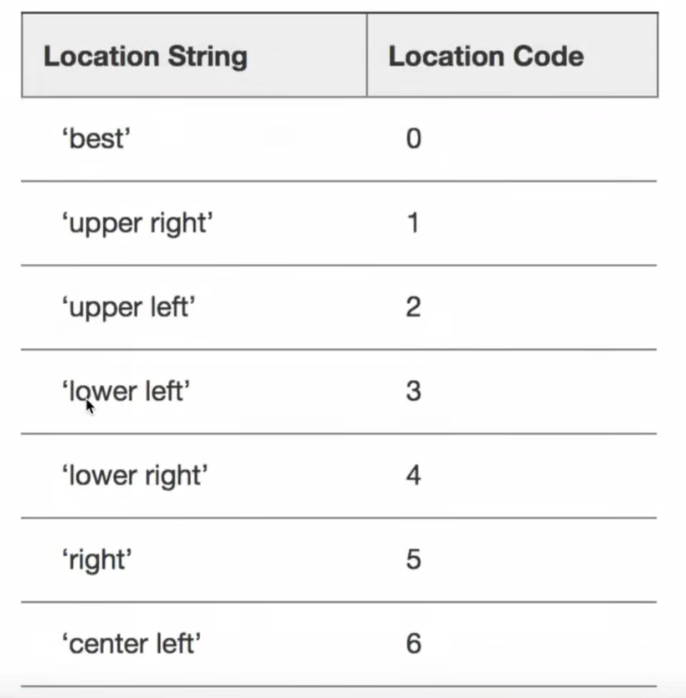
plt.legend(loc = "upper right")#legend有自己的参数可以控制图例位置
# 修改x、y刻度
# 准备x的刻度说明 ticks表示刻度
x_label = ["11点{}分".format(i) for i in x]
plt.xticks(x[::5], x_label[::5])
#步长为5,即不让刻度显示过于密集第一处的x[::5]也要写,应该是用来给x_label定位的
plt.yticks(range(0, 40, 5))
# 添加网格显示,其中的alpha是网格的透明程度
plt.grid(linestyle="--", alpha=0.5)
# 添加描述信息
plt.xlabel("时间变化")
plt.ylabel("温度变化")
plt.title("上海、北京11点到12点每分钟的温度变化状况")
# 保存图片,注意必须放在 show 之前, 因为 show 之后会释放缓存
plt.savefig("test.png")
# 4、显示图
plt.show()
- 图形风格
- 图例位置
- 创建多个绘图区
figure, axes = plt.subplots(nrows=1, ncols=2, figsize=(20, 8), dpi=80)
实例:
import matplotlib.pyplot as plt
import random
# 需求:再添加一个城市的温度变化
# 收集到北京当天温度变化情况,温度在1度到3度。
# 1、准备数据 x y
x = range(60)
y_shanghai = [random.uniform(15, 18) for i in x]
y_beijing = [random.uniform(1, 3) for i in x]
# 2、创建画布
# plt.figure(figsize=(20, 8), dpi=80)
figure, axes = plt.subplots(nrows=1, ncols=2, figsize=(20, 8), dpi=80)
# 3、绘制图像
axes[0].plot(x, y_shanghai, color="r", linestyle="-.", label="上海")
axes[1].plot(x, y_beijing, color="b", label="北京")
# 显示图例
axes[0].legend()
axes[1].legend()
# 修改x、y刻度
# 准备x的刻度说明
x_label = ["11点{}分".format(i) for i in x]
axes[0].set_xticks(x[::5])
axes[0].set_xticklabels(x_label)
axes[0].set_yticks(range(0, 40, 5))
axes[1].set_xticks(x[::5])
axes[1].set_xticklabels(x_label)
axes[1].set_yticks(range(0, 40, 5))
# 添加网格显示
axes[0].grid(linestyle="--", alpha=0.5)
axes[1].grid(linestyle="--", alpha=0.5)
# 添加描述信息
axes[0].set_xlabel("时间变化")
axes[0].set_ylabel("温度变化")
axes[0].set_title("上海11点到12点每分钟的温度变化状况")
axes[1].set_xlabel("时间变化")
axes[1].set_ylabel("温度变化")
axes[1].set_title("北京11点到12点每分钟的温度变化状况")
# 4、显示图
plt.show()
【机器学习】利用 Python 进行数据分析的环境配置 Windows(Jupyter,Matplotlib,Pandas)的更多相关文章
- < 利用Python进行数据分析 - 第2版 > 第五章 pandas入门 读书笔记
<利用Python进行数据分析·第2版>第五章 pandas入门--基础对象.操作.规则 python引用.浅拷贝.深拷贝 / 视图.副本 视图=引用 副本=浅拷贝/深拷贝 浅拷贝/深拷贝 ...
- 《利用python进行数据分析》读书笔记--第五章 pandas入门
http://www.cnblogs.com/batteryhp/p/5006274.html pandas是本书后续内容的首选库.pandas可以满足以下需求: 具备按轴自动或显式数据对齐功能的数据 ...
- $《利用Python进行数据分析》学习笔记系列——IPython
本文主要介绍IPython这样一个交互工具的基本用法. 1. 简介 IPython是<利用Python进行数据分析>一书中主要用到的Python开发环境,简单来说是对原生python交互环 ...
- 利用Python进行数据分析
最近在阅读<利用Python进行数据分析>,本篇博文作为读书笔记 ,记录一下阅读书签和实践心得. 准备工作 python环境配置好了,可以参见我之前的博文<基于Python的数据分析 ...
- PYTHON学习(三)之利用python进行数据分析(1)---准备工作
学习一门语言就是不断实践,python是目前用于数据分析最流行的语言,我最近买了本书<利用python进行数据分析>(Wes McKinney著),还去图书馆借了本<Python数据 ...
- 利用python进行数据分析——(一)库的学习
总结一下自己对python常用包:Numpy,Pandas,Matplotlib,Scipy,Scikit-learn 一. Numpy: 标准安装的Python中用列表(list)保存一组值,可以用 ...
- 利用python进行数据分析--(阅读笔记一)
以此记录阅读和学习<利用Python进行数据分析>这本书中的觉得重要的点! 第一章:准备工作 1.一组新闻文章可以被处理为一张词频表,这张词频表可以用于情感分析. 2.大多数软件是由两部分 ...
- 参考《利用Python进行数据分析(第二版)》高清中文PDF+高清英文PDF+源代码
第2版针对Python 3.6进行全面修订和更新,涵盖新版的pandas.NumPy.IPython和Jupyter,并增加大量实际案例,可以帮助高效解决一系列数据分析问题. 第2版中的主要更新了Py ...
- 利用Python进行数据分析-Pandas(第一部分)
利用Python进行数据分析-Pandas: 在Pandas库中最重要的两个数据类型,分别是Series和DataFrame.如下的内容主要围绕这两个方面展开叙述! 在进行数据分析时,我们知道有两个基 ...
随机推荐
- MySQL主从复制原理及搭建过程
GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源. 复制概述 复制即把一台服务器上的数据通过某种手段同步到另外一台或多台从服务器上,使得从服务器在数据上与主服务器保持一致. ...
- LINUX下基于NVIDIA HPC SDK 的 VASP6.3.x编译安装报错整理
关于gcc 用旧版本安装NVIDIA HPC SDK再编译会报错: "/opt/rh/devtoolset-8/root/usr/include/c++/8/bits/move.h" ...
- 神器 利器 Typora
用typora编辑真的实在太爽了! gooooooooooooooooooooooooooooooood! 支持html可以实现好看的排版! 支持latex实在是太棒了! 不过默认不支持,要去首选项里 ...
- java-servlet过滤器和监听
1 过滤器 过滤器是什么?servlet规范当中定义的一种特殊的组件,用于拦截容器的调用.注:容器收到请求之后,如果有过滤器,会先调用过滤器,然后在调用servlet. 如何写一个过滤器? 写一个ja ...
- jsp获取下拉框组件的值
jsp获取下拉框组件的值 1.首先,写一个带有下拉框的前台页 1 <%@ page language="java" contentType="text/html; ...
- SSM整合,快速新建javaWeb项目
整合前需要了解: spring和springmvc包扫描的注意事项 Spring applicationContext.xml (父容器),SpringMVC springmvc-servlet.xm ...
- package.json 与 package-lock.json 的关系
模块化开发在前端越来越流行,使用 node 和 npm 可以很方便的下载管理项目所需的依赖模块.package.json 用来描述项目及项目所依赖的模块信息. 那 package-lock.json ...
- Python小游戏——外星人入侵(保姆级教程)第一章 01创建Pygame窗口 02创建设置类Setting()
系列文章目录 第一章:武装飞船 01:创建Pygame窗口以及响应用户输入 02:创建设置类Setting() 一.前期准备 1.语言版本 Python3.9.0 2.编译器 Pycharm2022 ...
- [网鼎杯 2018]Comment-1|SQL注入|二次注入
1.打开之后只有一个留言页面,很自然的就想到了二次注入得问题,顺带查看了下源代码信息,并没有什么提示,显示界面如下: 2.那先扫描一下目录,同时随便留言一个测试以下,但是显示需要登录,账户.密码给出了 ...
- 简单html js css 轮播图片,不用jquery
这个是自己修改的轮播图片,在网上有的是flash 实现的轮播图片,对搜索引擎不友好, 比如:dedecms 的首页的轮播图是用flash实现滚动的. 所以这个自己修改了一下,实现html+js+css ...