聊一聊 HBase 是如何写入数据的?
hi,大家好,我是大D。今天继续了解下 HBase 是如何写入数据的,然后再讲解一下一个比较经典的面试题。
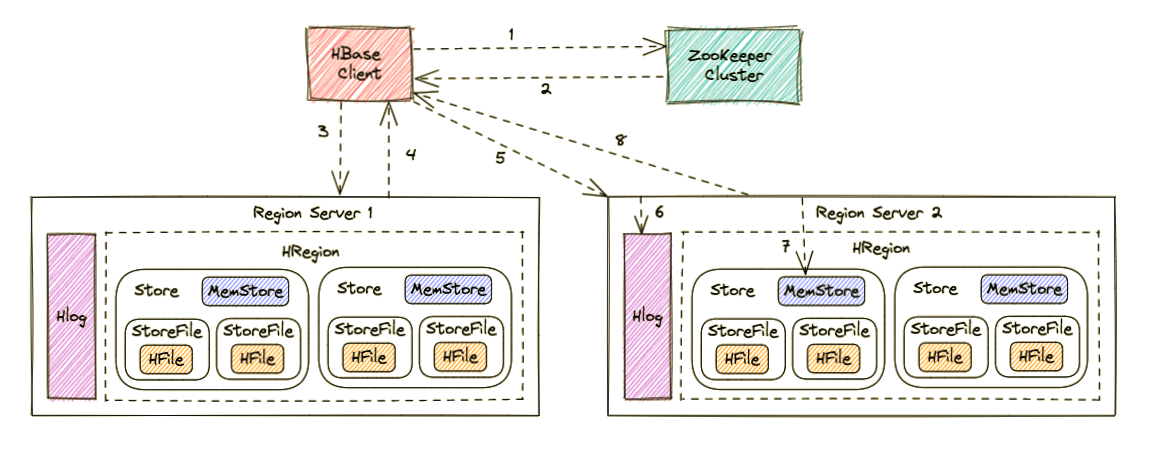
Region Server 寻址
- HBase Client 访问 ZooKeeper;
- 获取写入 Region 所在的位置,即获取 hbase:meta 表位于哪个 Region Server;
- 访问对应的 Region Server;
- 获取 hbase:meta 表,并查询出目标数据位于哪个 Region Server 中的哪个 Region 中。并将该 table 的 Region 信息以及 meta 表的位置信息缓存在客户端的 meta cache,方便下次访问;
写 Hlog
- HBase Client 向 Region Server 发送写 Hlog 请求;
- Region Server 会通过顺序写入磁盘的方式,将 Hlog 存储在 HDFS 上;
写 MemStore 并返回结果
- HBase Client 向 Region Server 发送写 MemStore 请求;
- 只有当写 Hlog 和写 MemStore 的请求都成功完成之后,并将反馈给 HBase Client,这时对于整个 HBase Client 写入流程已经完成。
MemStore 刷盘
HBase 会根据 MemStore 配置的刷盘策略定时将数据刷新到 StoreFile 中,完成数据持久化存储。
为什么要把 WAL 加载到 MemStore中,再刷写成 HFile 呢?
WAL (Write-Ahead-Log) 预写日志是 HBase 的 RegionServer 在处理数据插入和删除过程中用来记录操作内容的一种日志。每次Put、Delete等一条记录时,首先将其数据写入到 RegionServer 对应的 HLog 文件中去。
而WAL是保存在HDFS上的持久化文件,数据到达 Region 时先写入 WAL,然后被加载到 MemStore 中。这样就算Region宕机了,操作没来得及执行持久化,也可以再重启的时候从 WAL 加载操作并执行。
那么,我们从写入流程中可以看出,数据进入 HFile 之前就已经被持久化到 WAL了,而 WAL 就是在 HDFS 上的,MemStore 是在内存中的,增加 MemStore 并不能提高写入性能,为什么还要从 WAL 加载到 MemStore中,再刷写成 HFile 呢?
- 数据需要顺序写入,但 HDFS 是不支持对数据进行修改的;
- WAL 的持久化为了保证数据的安全性,是无序的;
- Memstore在内存中维持数据按照row key顺序排列,从而顺序写入磁盘;
所以 MemStore 的意义在于维持数据按照RowKey的字典序排列,而不是做一个缓存提高写入效率。
另外,非常欢迎大家加我VX: Abox_0226 ,备注「进群」,有关大数据技术的问题在群里一起探讨。
聊一聊 HBase 是如何写入数据的?的更多相关文章
- HBase BulkLoad批量写入数据实战
1.概述 在进行数据传输中,批量加载数据到HBase集群有多种方式,比如通过HBase API进行批量写入数据.使用Sqoop工具批量导数到HBase集群.使用MapReduce批量导入等.这些方式, ...
- 使用bulkload向hbase中批量写入数据
1.数据样式 写入之前,需要整理以下数据的格式,之后将数据保存到hdfs中,本例使用的样式如下(用tab分开): row1 N row2 M row3 B row4 V row5 N row6 M r ...
- Spark Streaming实时写入数据到HBase
一.概述 在实时应用之中,难免会遇到往NoSql数据如HBase中写入数据的情景.题主在工作中遇到如下情景,需要实时查询某个设备ID对应的账号ID数量.踩过的坑也挺多,举其中之一,如一开始选择使用NE ...
- spark 写入数据到Geomesa(Hbase)
package com.grady.geomesa import org.apache.spark.sql.jts.PointUDT import org.apache.spark.sql.types ...
- HBase存储剖析与数据迁移
1.概述 HBase的存储结构和关系型数据库不一样,HBase面向半结构化数据进行存储.所以,对于结构化的SQL语言查询,HBase自身并没有接口支持.在大数据应用中,虽然也有SQL查询引擎可以查询H ...
- ElasticSearch写入数据的工作原理是什么?
面试题 es 写入数据的工作原理是什么啊?es 查询数据的工作原理是什么啊?底层的 lucene 介绍一下呗?倒排索引了解吗? 面试官心理分析 问这个,其实面试官就是要看看你了解不了解 es 的一些基 ...
- HBase(六)HBase整合Hive,数据的备份与MR操作HBase
一.数据的备份与恢复 1. 备份 停止 HBase 服务后,使用 distcp 命令运行 MapReduce 任务进行备份,将数据备份到另一个地方,可以是同一个集群,也可以是专用的备份集群. 即,把数 ...
- hbase表的写入
hbase列式存储给我们画了一个很美好的大饼,好像有了它,很多问题都可以轻易解决.但在实际的使用过程当中,你会发现没有那么简单,至少一些通用的准则要遵守,还需要根据业务的实际特点进行集群的参数调整,不 ...
- 大数据学习笔记——HBase使用bulkload导入数据
HBase使用bulkload批量导入数据 HBase可使用put命令向一张已经建好了的表中插入数据,然而,当遇到数据量非常大的情况,一条一条的进行插入效率将会大大降低,因此本篇博客将会整理提高批量导 ...
随机推荐
- Markdown入门操作
Markdown基本操作 一. 字体 1. 标题 (1). 一级标题 "# + 标题名" (2). 其余类推 (最多支持6级标题) 加粗 " ** + 内容 + ** & ...
- java连接oracle数据库(转)
在做导游通项目所用到 package org.javawo.test; import java.sql.Connection; import java.sql.DriverManager; /** * ...
- 【uniapp 开发】工具类 -- MathUtil
获取随机数 /* ** randomWord 产生任意长度随机字母数字组合 ** randomFlag 是否任意长度 min 任意长度最小位[固定位数] max 任意长度最大位 ** ** 生成6-1 ...
- Java的虚拟线程(协程)特性开启预览阶段,多线程开发的难度将大大降低
高并发.多线程一直是Java编程中的难点,也是面试题中的要点.Java开发者也一直在尝试使用多线程来解决应用服务器的并发问题.但是多线程并不容易,为此一个新的技术出现了,这就是虚拟线程. 传统多线程的 ...
- Python 每日提醒写博客小程序,使用pywin32、bs4库
死循环延迟调用方法,使用bs4库检索博客首页文章的日期是否与今天日期匹配,不匹配则说明今天没写文章,调用pywin32库进行弹窗提醒我写博客.
- 另类终端「GitHub 热点速览 v.22.15」
作者:HelloGitHub-小鱼干 除了编译器之外,终端也是我们日常打交道的软件之一.但,你用它看过股票吗?OpenBBTerminal 不仅能让你看股票,还能让你用科学的方法进行股票投资.说到投资 ...
- NodeJS学习日报day4——模块化
// console.log(module); // 执行顺序不同,结果也不同 // module.exports = { // name : 'Cra2iTeT', // hi() { // con ...
- SpringCloud分布式尝试记录
服务提供端: 客户消费端:
- v-if 和 v-show 的区别
1.v-if && v-else && v-else-if <span v-if = "4 > 9">hello</span ...
- BurpSuite与Xray多级代理实现联动扫描
Xray是长亭科技推出的,最经典的莫过于代理模式下的被动扫描,它使得整个过程可控且更加精细化: 代理模式下的基本架构为,扫描器作为中间人,首先原样转发流量,并返回服务器响应给浏览器等客户端,通讯两端都 ...