聊一聊 HBase 是如何写入数据的?
hi,大家好,我是大D。今天继续了解下 HBase 是如何写入数据的,然后再讲解一下一个比较经典的面试题。
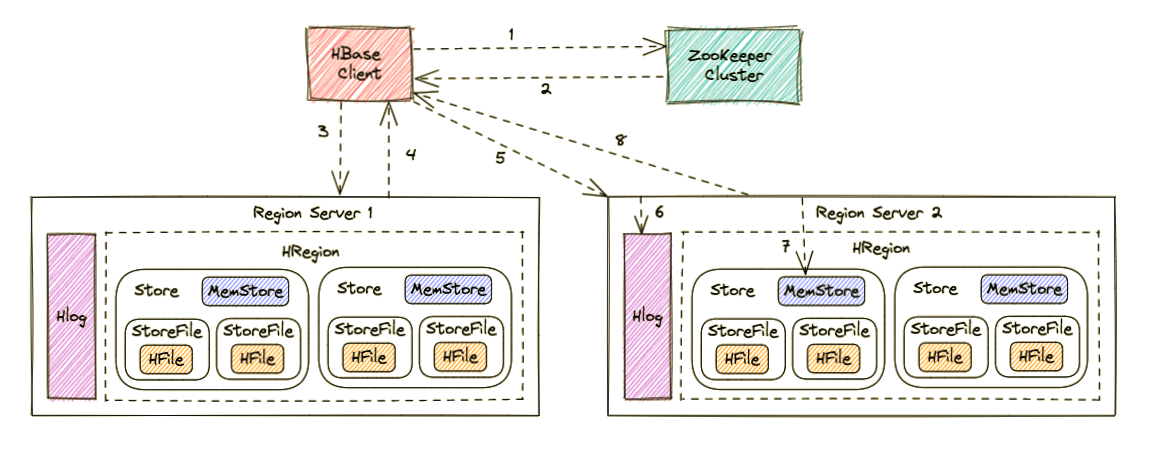
Region Server 寻址
- HBase Client 访问 ZooKeeper;
- 获取写入 Region 所在的位置,即获取 hbase:meta 表位于哪个 Region Server;
- 访问对应的 Region Server;
- 获取 hbase:meta 表,并查询出目标数据位于哪个 Region Server 中的哪个 Region 中。并将该 table 的 Region 信息以及 meta 表的位置信息缓存在客户端的 meta cache,方便下次访问;
写 Hlog
- HBase Client 向 Region Server 发送写 Hlog 请求;
- Region Server 会通过顺序写入磁盘的方式,将 Hlog 存储在 HDFS 上;
写 MemStore 并返回结果
- HBase Client 向 Region Server 发送写 MemStore 请求;
- 只有当写 Hlog 和写 MemStore 的请求都成功完成之后,并将反馈给 HBase Client,这时对于整个 HBase Client 写入流程已经完成。
MemStore 刷盘
HBase 会根据 MemStore 配置的刷盘策略定时将数据刷新到 StoreFile 中,完成数据持久化存储。
为什么要把 WAL 加载到 MemStore中,再刷写成 HFile 呢?
WAL (Write-Ahead-Log) 预写日志是 HBase 的 RegionServer 在处理数据插入和删除过程中用来记录操作内容的一种日志。每次Put、Delete等一条记录时,首先将其数据写入到 RegionServer 对应的 HLog 文件中去。
而WAL是保存在HDFS上的持久化文件,数据到达 Region 时先写入 WAL,然后被加载到 MemStore 中。这样就算Region宕机了,操作没来得及执行持久化,也可以再重启的时候从 WAL 加载操作并执行。
那么,我们从写入流程中可以看出,数据进入 HFile 之前就已经被持久化到 WAL了,而 WAL 就是在 HDFS 上的,MemStore 是在内存中的,增加 MemStore 并不能提高写入性能,为什么还要从 WAL 加载到 MemStore中,再刷写成 HFile 呢?
- 数据需要顺序写入,但 HDFS 是不支持对数据进行修改的;
- WAL 的持久化为了保证数据的安全性,是无序的;
- Memstore在内存中维持数据按照row key顺序排列,从而顺序写入磁盘;
所以 MemStore 的意义在于维持数据按照RowKey的字典序排列,而不是做一个缓存提高写入效率。
另外,非常欢迎大家加我VX: Abox_0226 ,备注「进群」,有关大数据技术的问题在群里一起探讨。
聊一聊 HBase 是如何写入数据的?的更多相关文章
- HBase BulkLoad批量写入数据实战
1.概述 在进行数据传输中,批量加载数据到HBase集群有多种方式,比如通过HBase API进行批量写入数据.使用Sqoop工具批量导数到HBase集群.使用MapReduce批量导入等.这些方式, ...
- 使用bulkload向hbase中批量写入数据
1.数据样式 写入之前,需要整理以下数据的格式,之后将数据保存到hdfs中,本例使用的样式如下(用tab分开): row1 N row2 M row3 B row4 V row5 N row6 M r ...
- Spark Streaming实时写入数据到HBase
一.概述 在实时应用之中,难免会遇到往NoSql数据如HBase中写入数据的情景.题主在工作中遇到如下情景,需要实时查询某个设备ID对应的账号ID数量.踩过的坑也挺多,举其中之一,如一开始选择使用NE ...
- spark 写入数据到Geomesa(Hbase)
package com.grady.geomesa import org.apache.spark.sql.jts.PointUDT import org.apache.spark.sql.types ...
- HBase存储剖析与数据迁移
1.概述 HBase的存储结构和关系型数据库不一样,HBase面向半结构化数据进行存储.所以,对于结构化的SQL语言查询,HBase自身并没有接口支持.在大数据应用中,虽然也有SQL查询引擎可以查询H ...
- ElasticSearch写入数据的工作原理是什么?
面试题 es 写入数据的工作原理是什么啊?es 查询数据的工作原理是什么啊?底层的 lucene 介绍一下呗?倒排索引了解吗? 面试官心理分析 问这个,其实面试官就是要看看你了解不了解 es 的一些基 ...
- HBase(六)HBase整合Hive,数据的备份与MR操作HBase
一.数据的备份与恢复 1. 备份 停止 HBase 服务后,使用 distcp 命令运行 MapReduce 任务进行备份,将数据备份到另一个地方,可以是同一个集群,也可以是专用的备份集群. 即,把数 ...
- hbase表的写入
hbase列式存储给我们画了一个很美好的大饼,好像有了它,很多问题都可以轻易解决.但在实际的使用过程当中,你会发现没有那么简单,至少一些通用的准则要遵守,还需要根据业务的实际特点进行集群的参数调整,不 ...
- 大数据学习笔记——HBase使用bulkload导入数据
HBase使用bulkload批量导入数据 HBase可使用put命令向一张已经建好了的表中插入数据,然而,当遇到数据量非常大的情况,一条一条的进行插入效率将会大大降低,因此本篇博客将会整理提高批量导 ...
随机推荐
- Java中final的使用
原文链接https://www.cnblogs.com/dolphin0520/p/10651845.html 作者Matrix海 子 本文为笔记 0. 概述 final和static一样都是修饰词, ...
- Docker镜像构建之docker commit
我们可以通过公共仓库拉取镜像使用,但是,有些时候公共仓库拉取的镜像并不符合我们的需求.尽管已经从繁琐的部署工作中解放出来了,但是在实际开发时,我们可能希望镜像包含整个项目的完整环境,在其他机器上拉取打 ...
- CPU架构:CPU架构详细介绍
1 概述 CPU架构是CPU商给CPU产品定的一个规范,主要目的是为了区分不同类型的CPU.目前市场上的CPU分类主要分有两大阵营,一个是intel.AMD为首的复杂指令集CPU,另一个是以IBM.A ...
- 7. Github Pages 搭建网站
7. Github Pages 搭建网站 个人站点 访问 https://用户名.github.io 搭建步骤 1) 创建个人站点 -> 新建仓库(注:仓库名必须是[用户名.github. ...
- formSelects
formSelects-v4.js 链接:https://pan.baidu.com/s/1Qp-ez7CuA1cVdWhP37EA7Q 提取码:17iq只需要下文中的css文件和js文件引入到页面 ...
- html5网页录音和语音识别
背景 在输入方式上,人们总是在追寻一种更高效,门槛更低的方式,来降低用户使用产品的学习成本.语音输入也是一种尝试较多的方式,有些直接使用语音(如微信语音聊天),有些需要将语音转化为文字(语音识别).接 ...
- java中hashCode和equals什么关系,hashCode到底怎么用的
Object类的hashCode的用法:(新手一定要忽略本节,否则会很惨) 马 克-to-win:hashCode方法主要是Sun编写的一些数据结构比如Hashtable的hash算法中用到.因为ha ...
- npx和npm的区别
npx 是 npm 的高级版本,npx 具有更强大的功能. 用途: 在项目中直接运行指令,直接运行node_modules中的某个指令,不需要输入文件路径 node-modules/.bin/babe ...
- 【Python打包成exe方法】——已解决导入第三方包无法打包的问题
前言 在我们写代码的过程中,我们开发的脚本一般都会用到一些第三方包,可能别人也需要用到我们的脚本,如果我们将我们的xx.py文件发给他,他是不能直接用的,他还需要安装python解释器,甚至还要安 ...
- 控制器全屏显示.不展示导航栏navigationbar
有些时候需要 让控制器全屏显示 ,不需要导航栏,或者说是在导航栏底部 基本情况: >控制器全屏 ``` if (@available(iOS 11.0, *)) { self.tableView ...