使用 awk 命令统计文本
2022-04-19 11:25:15.008,b4d13bfca8fe4b93a85e65a88520d945,LogScheduler#printLog,10ms,Y,xxxxxxxx
2022-04-19 12:01:15.002,4d10d093dce8491c8ae3c1bff6dbd7c5,LogScheduler#printLog,999ms,N,xxxxxxxx
2022-04-19 12:12:16.003,d9d1f4b121764edb8cb260417cd75229,LogScheduler#printLog,5ms,Y,xxxxxxxx
2022-04-19 12:15:22.004,e3e10340e51c49ce9d688541ba799283,LogScheduler#printLog,1001ms,N,xxxxxxxx
2022-04-19 12:55:59.005,209d2f1407894da5aa0f44de621515c7,LogScheduler#printLog,1020ms,Y,xxxxxxxx
2022-04-19 13:25:15.006,e09f75c6d0d849068ae713820c94f3f9,LogScheduler#printLog,15ms,Y,xxxxxxxx
2022-04-19 13:25:15.008,b4d13bfca8fe4b93a85e65a885231231,LogScheduler#printLog,99ms,Y,xxxxxxxx
有那么一段日志,需要统计出来以下信息:
- 输出耗时超过 1000ms 并且结果是 Y 的整行
- 12:00 ~ 13:00 之间成功的行数,成功率
日志格式:时间,traceId,类方法名,耗时,结果,内容
看到这里,如果小伙伴已经有思路了,那就没必要往下面看了,直接拉到最后,点赞、在看。
这里要使用的就是 awk 命令。
常用内置变量
awk 的主要功能就是对文本进行统计报告,具体介绍可以看菜鸟笔记,下面仅介绍几个常用的内置变量。
- FS:行字段分隔符,默认是空格,可以使用
-F指定分隔符 - $0、$1……:行字段分隔符分割后获取指定部分,$0 是获取整行记录
- NF:当前行的字段数量
- RS:行记录分隔符
- NR:行号
大概常用的就这几个,下面看一下实际使用效果
效果展示
notes % > awk '{print $0}' c.log
因为 $0 就代表整行记录,所以输出结果如下。
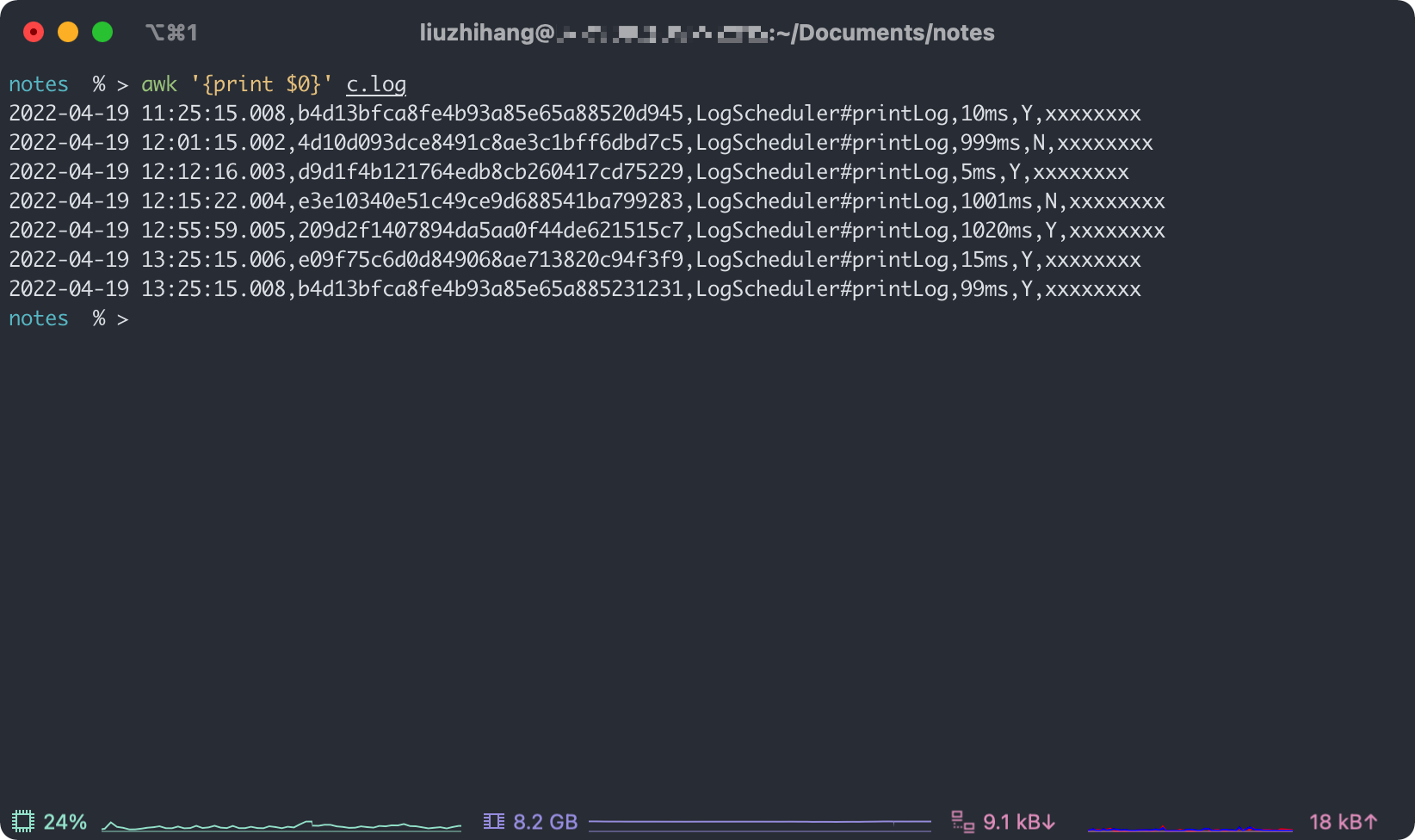
那 $1 的结果呢?
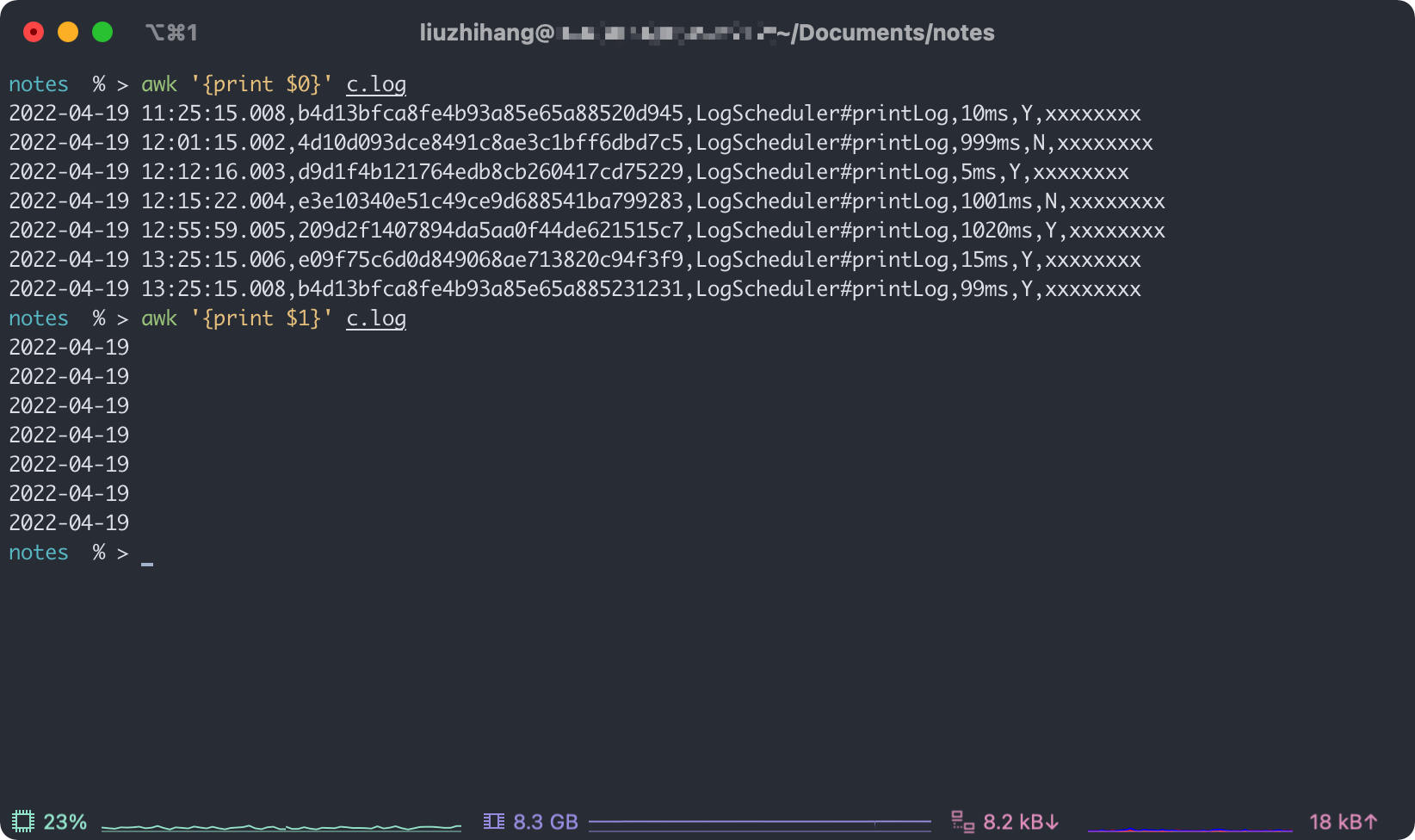
因为默认是空格作为分隔符,所以输出的结果就只有日期了。
指定分隔符为,之后,看一下输出结果:
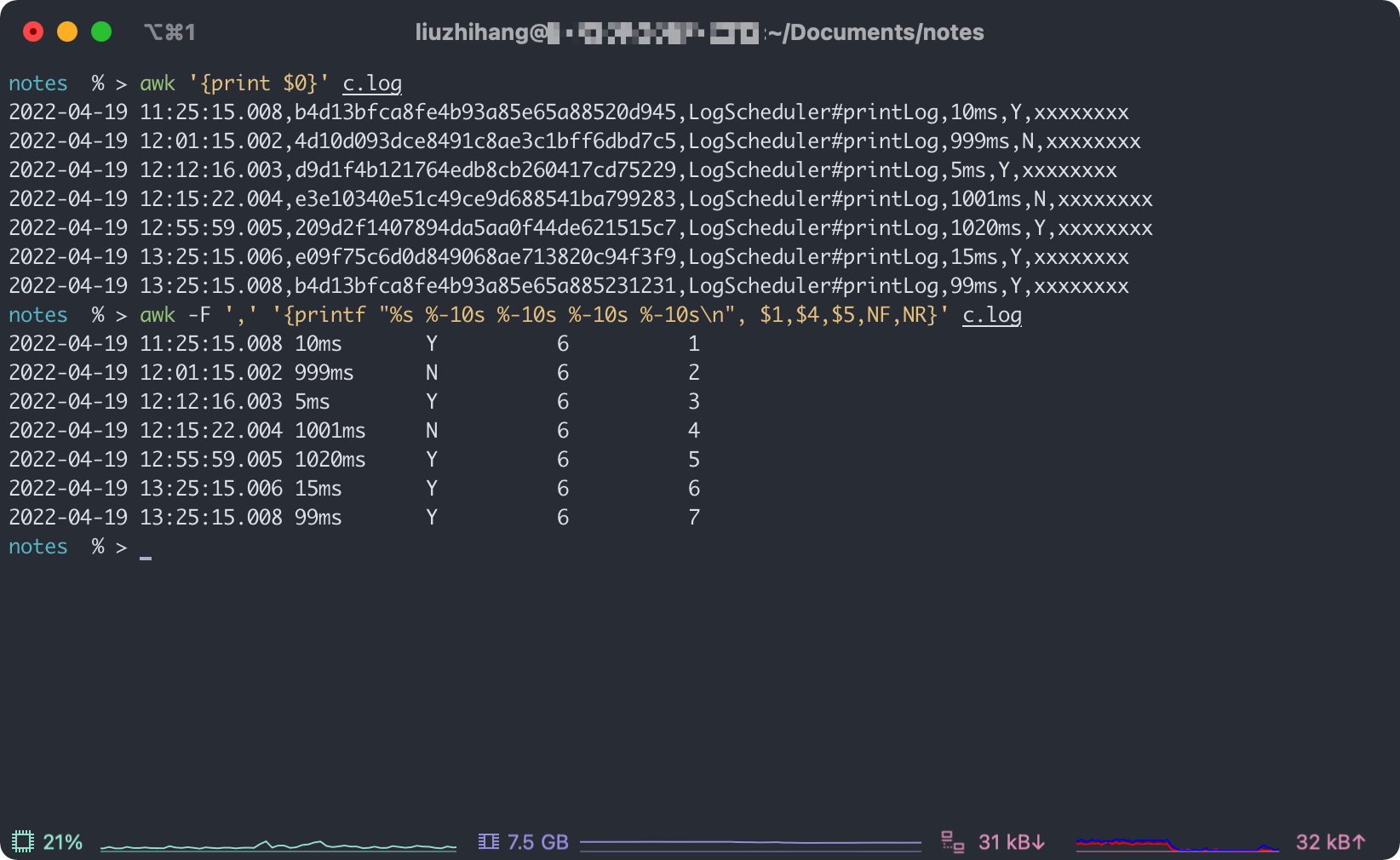
题目答案
基本上熟悉了怎么使用剩下的就比较好办了。
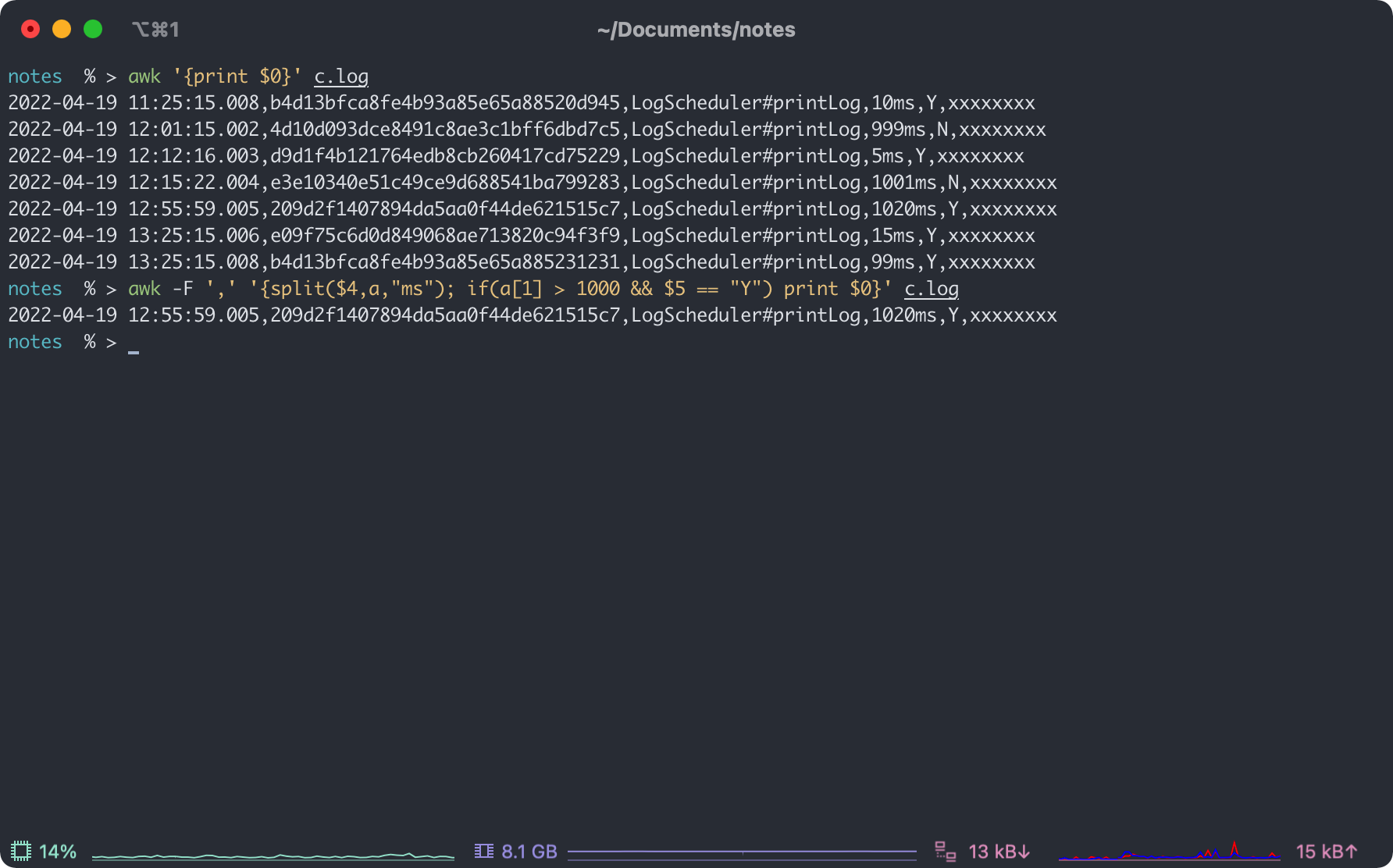
- 耗时超过 1000ms 且 Y 的行
notes % > awk -F ',' '{split($4,a,"ms"); if(a[1] > 1000 && $5 == "Y") print $0}' c.log
- 12:00 ~ 13:00 之间成功的行数,成功率
awk -F ',' 'BEGIN{count=0;sum=0}{if($1>="2022-04-19 12:00:00.000" && $1<"2022-04-19 13:00:00.000"){sum+=1;if($5 == "Y")count+=1}}END{print NR,count,sum,count/sum}' c.log
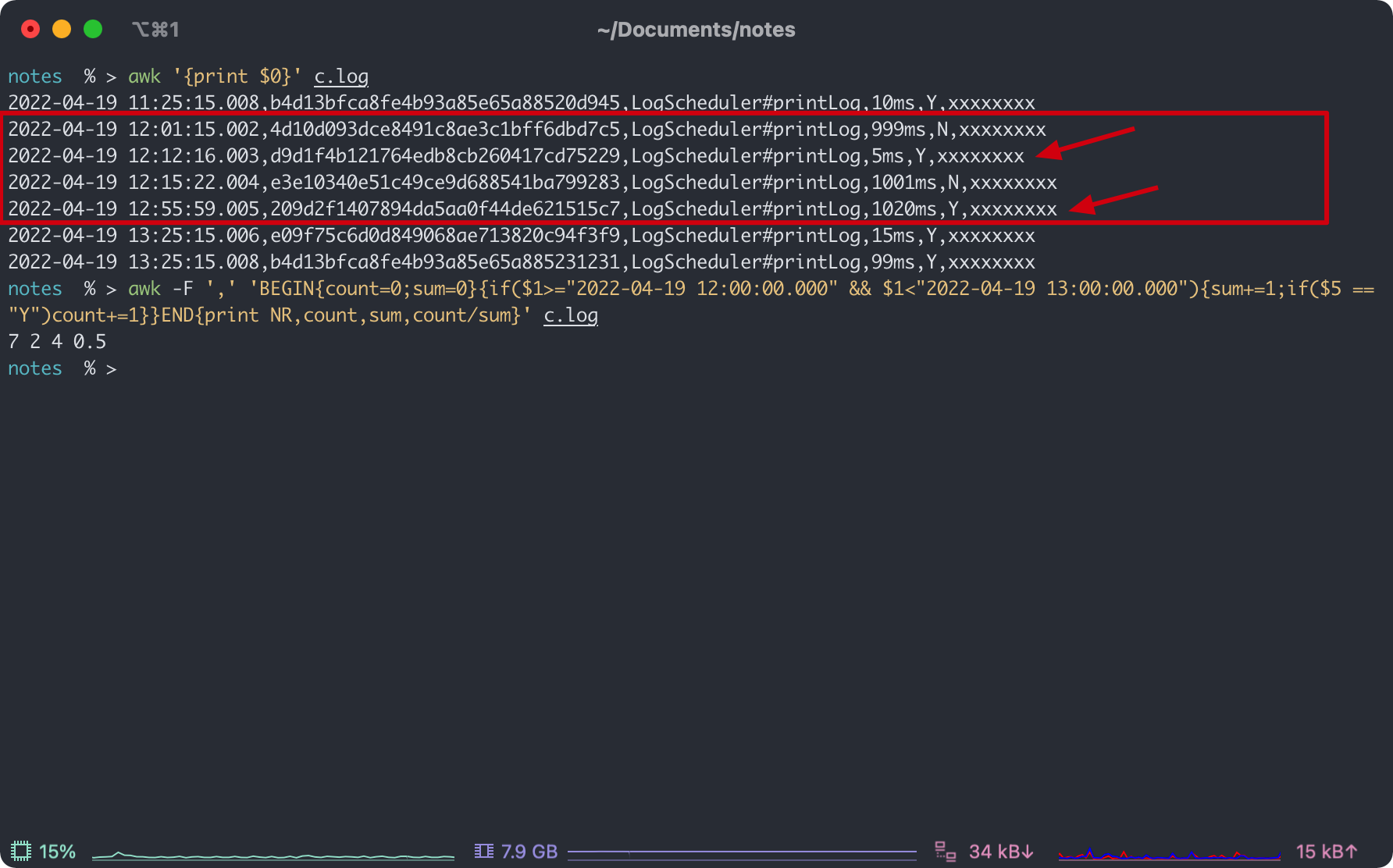
总记录 7 条, 12:00 ~ 13:00 之间成功的行数是 2,成功率 0.5。
总结
上面只是在工作中可能会遇到的一个场景,所以记录下来,如果小伙伴有更合适的方式来统计计算,欢迎留言。
使用 awk 命令统计文本的更多相关文章
- 转:使用awk命令获取文本的某一行,某一列
1.打印文件的第一列(域) : awk '{print $1}' filename2.打印文件的前两列(域) : awk '{print ...
- Linux:使用awk命令获取文本的某一行,某一列
无意中发现了一个巨牛的人工智能教程,忍不住分享一下给大家.教程不仅是零基础,通俗易懂,而且非常风趣幽默,像看小说一样!觉得太牛了,所以分享给大家.点 这里 可以跳转到教程.”. 1.打印文件的第一列( ...
- Linux:使用awk命令获取文本的某一行,某一列;sed插入指定的内容到指定文件中
awk相关用法: 1.打印文件的第一列(域) : awk '{print $1}' filename2.打印文件的前两列(域) : aw ...
- Linux中的高级文本处理命令,cut命令,sed命令,awk命令
1.2.1 cut命令 cut命令可以从一个文本文件或者文本流中提取文本列. cut语法 [root@www ~]# cut -d'分隔字符' -f fields ## 用于有特定分隔字符 [r ...
- awk统计文本里某一列重复出现的次数
比如这样的场景:现在有一个文本,里面是这样的内容: NOTICE: 12-14 15:11:13: parser. * 6685 url=[http://club.pchome.net/threa ...
- linux 文本分析工具---awk命令(7/1)
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大.简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各 ...
- 【文本处理命令】之awk命令详解
一.awk命令简介 awk 是一种很棒的语言,它适合文本处理和报表生成,其语法较为常见,借鉴了某些语言的一些精华,如 C 语言等.在 linux 系统日常处理工作中,发挥很重要的作用,掌握了 awk将 ...
- linux awk命令详解
linux awk命令详解 简介 awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大.简单来说awk就是把文件逐行的读入,以空格为默认分 ...
- awk命令详解
搜索 纠正错误 添加实例 awk 文本和数据进行处理的编程语言 补充说明 awk 是一种编程语言,用于在linux/unix下对文本和数据进行处理.数据可以来自标准输入(stdin).一个或多个文件 ...
随机推荐
- 原生js造轮子之模仿JQ的slideDown()与slideUp()
代码如下: const slider = (function() { var Slider = {}; // the constructed function,timeManager,as such ...
- 什么是jsp?jsp的内置对象有哪些?
这里是修真院前端小课堂,每篇分享文从 [背景介绍][知识剖析][常见问题][解决方案][编码实战][扩展思考][更多讨论][参考文献] 八个方面深度解析前端知识/技能,本篇分享的是: [什么是jsp? ...
- 【Android开发】【布局】各种TabLayout样式
Demo
- sql server学习总结一
一,数据库的三级模式结构 1. 模式 模式又称逻辑模式或者概念模式,是数据库中全体数据的逻辑结构和特征的描述,一个数据库只有一个模式,模式处于三级结构的中间层. 2. 外模式 外模式又称用 ...
- 如何在云服务器上安装vim(bash: vim :command not found)
1.apt-get update 2.apt-get install vim vim文件即可成功!
- python基本数据类型介绍
数据类型 首先知道什么是数据类型 针对不同的数据类型采用不同的处理方法 --目录-- 一.数据类型之整型 二.数据类型之浮点型 三.数据类型之字串符 四.数据之列表 一.数据类型之整型 1.其实呢就是 ...
- LevelDB 学习笔记1:布隆过滤器
LevelDB 学习笔记1:布隆过滤器 底层是位数组,初始都是 0 插入时,用 k 个哈希函数对插入的数字做哈希,并用位数组长度取余,将对应位置 1 查找时,做同样的哈希操作,查看这些位的值 如果所有 ...
- Blazor 生命周期
执行周期 1. SetParametersAsync 2. OnInitializedAsync(调用两次) 和 OnInitialized: 3. OnParametersSetAsync 或 On ...
- vue 组件复用 - component
vue 组件复用 - component vue 组件复用 就是对 component 标签的使用 先看图 下图看使用 结果: 可以看到 在箱包 这一项,我将banner 组件用了两次,我 每次 点击 ...
- Delphi 类库(DLL)动态调用与静态调用示例讲解
在Delphi或者其它程序中我们经常需要调用别人写好的DLL类库,下面直接上示例代码演示如何进行动态和静态的调用方法: { ************************************** ...