python基础知识-day9(数据驱动)
1、数据驱动的概念
在自动化测试中,需要把测试的数据分离到JSON,YAML等文件中。
2、YAML 的相关知识
YAML 入门教程 分类 编程技术 YAML 是 "YAML Ain't a Markup Language"(YAML 不是一种标记语言)的递归缩写。在开发的这种语言时,YAML 的意思其实是:"Yet Another Markup Language"(仍是一种标记语言)。YAML 的语法和其他高级语言类似,并且可以简单表达清单、散列表,标量等数据形态。它使用空白符号缩进和大量依赖外观的特色,特别适合用来表达或编辑数据结构、各种配置文件、倾印调试内容、文件大纲(例如:许多电子邮件标题格式和YAML非常接近)。YAML 的配置文件后缀为 .yml,如:runoob.yml 。基本语法 大小写敏感 使用缩进表示层级关系 缩进不允许使用tab,只允许空格 缩进的空格数不重要,只要相同层级的元素左对齐即可 '#'表示注释
3、json数据驱动案例实战
1)在工程文件testDev下新建一个名为数据驱动的package;
2)在数据驱动包中新建login.json的文件;
3)在login.json文件在中编写如下代码:
1 {
2 "login":{"username": "cch","password":"admin"}
3 }
4)在数据驱动包中新建operationJson的python文件,并编写如下代码:
1 import json
2 def readJson():
3 return json.load(open("login.json")) #从login.json文件中读取数据
4 print(readJson())
5 print(type(readJson()))
6
7 print(readJson()["login"]["password"]) #从字典中获取登录的密码
5)运行operationJson文件中的代码后,得到如下结果:
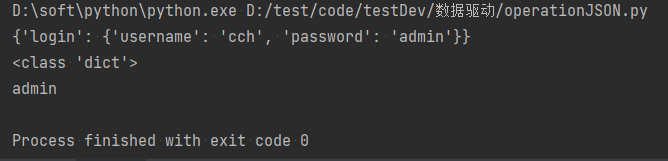
4、yaml数据驱动案例实战1
1)在工程文件testDev下新建一个名为数据驱动的package;
2)在数据驱动包中新建login.yaml的文件;
3)在login.yaml文件在中编写如下代码:
1 login:
2 username: 无涯 #注意冒号后边需空一格
3 password: admin
4
5 ali:
6 taobao:
7 shop:
8 name: 无涯课堂
4)在数据驱动包中新建operationYaml的python文件,并编写如下代码:
1 import yaml
2 def readYaml():
3 with open(file="login.yaml",mode="r",encoding="utf-8") as f:
4 return yaml.safe_load(f)
5 print(readYaml())
6 print(type(readYaml()))
7 print(readYaml()["login"]["password"])
8 print(readYaml()["ali"]["taobao"]["shop"]["name"])
5)运行operationYaml文件中的代码,得到如下结果:

4、yaml数据驱动案例实战2
1)在工程文件testDev下新建一个名为数据驱动的package;
2)在数据驱动包中新建data.yaml的文件;
3)在data.yaml文件在中编写如下代码:
1 --- #注意须添加“---”表示列表
2 login:
3 username: 无涯
4 ---
5 login:
6 username: wuya
4)在数据驱动包中新建operationYaml的python文件,并编写如下代码:
1 import yaml
2 def readYamlList():
3 with open(file="data.yaml",mode="r",encoding="utf-8") as f:
4 return list(yaml.safe_load_all(f))
5 print(readYamlList())
6 print(type(readYamlList()))
7 print(readYamlList()[0]["login"]["username"]) #获取“无涯”
8 print(readYamlList()[1]["login"]["username"]) #获取“wuya”
5)运行operationYaml文件中的代码,得到如下结果:

5、csv数据驱动案例实战1(列表形式)
1)在module包下面导入一个名为data.csv的文件,文件内容如下:
1 username,password,city 2 无涯,admin,中国西安 3 wuya,admin,西安
2)在module包下面新建一个名为csv学习的python文件,并编写以下代码:
1 import csv
2 def readCsvList():
3 lists=[]
4 with open(file='data.csv',mode="r",encoding="utf-8") as f:
5 reader=csv.reader(f) #调用reader形成列表形式
6 next(reader) #不读取第一行
7 for item in reader:
8 lists.append(item)
9 return lists
10 print(readCsvList())
以上代码运行的结果为:

6、csv数据驱动案例实战1(字典形式)
1)在module包下面导入一个名为data.csv的文件,文件内容如下:
1 username,password,city 2 无涯,admin,中国西安 3 wuya,admin,西安
2)在module包下面新建一个名为csv学习的python文件,并编写以下代码:
1 import csv
2 def readCsvDict():
3 lists=[]
4 with open(file="data.csv",mode="r",encoding="utf-8-sig") as f:#使用encoding="utf-8-sig",防止乱码
5 reader=csv.DictReader(f)
6 for item in reader:
7 lists.append(dict(item))
8 return lists
9 print(readCsvDict())
以上代码的运行结果为:

7.excel数据驱动案例实战
1)在module包下面导入一个名为data.xlsx的文件,文件内容如下:
| username | password | city |
| 无涯 | admin | 中国西安 |
2)在module包下面新建一个名为excel学习的python文件,并编写以下代码:
1 import xlrd
2 def readExcel():
3 lists=[]
4 book=xlrd.open_workbook("data.xlsx") #读取excel文件
5 sheet=book.sheet_by_index(0) #操作sheet
6 for item in range(1,sheet.nrows):
7 lists.append(sheet.row_values(item))
8 return lists
9 print(readExcel())
以上代码的运行结果为:

python基础知识-day9(数据驱动)的更多相关文章
- python基础知识-day9(库学习)
1.os学习 1 print(os.name) #获取操作系统 2 print(os.path.exists("D:\soft\python")) #判断路径是否存在 3 prin ...
- Python开发【第二篇】:Python基础知识
Python基础知识 一.初识基本数据类型 类型: int(整型) 在32位机器上,整数的位数为32位,取值范围为-2**31-2**31-1,即-2147483648-2147483647 在64位 ...
- python基础知识(二)
以下内容,作为python基础知识的补充,主要涉及基础数据类型的创建及特性,以及新数据类型Bytes类型的引入介绍
- python 基础知识(一)
python 基础知识(一) 一.python发展介绍 Python的创始人为Guido van Rossum.1989年圣诞节期间,在阿姆斯特丹,Guido为了打发圣诞节的无趣,决心开发一个新的脚本 ...
- python基础知识讲解——@classmethod和@staticmethod的作用
python基础知识讲解——@classmethod和@staticmethod的作用 在类的成员函数中,可以添加@classmethod和@staticmethod修饰符,这两者有一定的差异,简单来 ...
- python爬虫主要就是五个模块:爬虫启动入口模块,URL管理器存放已经爬虫的URL和待爬虫URL列表,html下载器,html解析器,html输出器 同时可以掌握到urllib2的使用、bs4(BeautifulSoup)页面解析器、re正则表达式、urlparse、python基础知识回顾(set集合操作)等相关内容。
本次python爬虫百步百科,里面详细分析了爬虫的步骤,对每一步代码都有详细的注释说明,可通过本案例掌握python爬虫的特点: 1.爬虫调度入口(crawler_main.py) # coding: ...
- python 爬虫与数据可视化--python基础知识
摘要:偶然机会接触到python语音,感觉语法简单.功能强大,刚好朋友分享了一个网课<python 爬虫与数据可视化>,于是在工作与闲暇时间学习起来,并做如下课程笔记整理,整体大概分为4个 ...
- python基础知识小结-运维笔记
接触python已有一段时间了,下面针对python基础知识的使用做一完整梳理:1)避免‘\n’等特殊字符的两种方式: a)利用转义字符‘\’ b)利用原始字符‘r’ print r'c:\now' ...
- Python基础知识(五)
# -*- coding: utf-8 -*-# @Time : 2018-12-25 19:31# @Author : 三斤春药# @Email : zhou_wanchun@qq.com# @Fi ...
随机推荐
- node.js - http、模块化、npm
今天是node学习的第二天,其实越往后面学越感觉有点熟悉的味道了,光针对于node来说哈,为什么呢,因为我之前学过一点云计算的东西,当时感觉没什么用搞了下服务器客户端这些,没想到这里还能用一用,至少看 ...
- Cf #709 Div. 2 B. Restore Modulo 一个只有三千多人过的b题, 妙啊!
传送门: https://codeforces.com/contest/1484/problem/B 原题 Example input 6 6 1 9 17 6 14 3 3 4 2 2 3 7 3 ...
- Codeforces Round #707 (Div. 2)A.英语漏洞 + C.Going Home C题收获不小
A题英语漏洞 A题传送门: https://codeforces.com/contest/1501/problem/A 其实题目说的很明白, 只是我傻傻的会错了意, 话不多说, 开整. 前两行是说, ...
- 分布式应用运行时 Dapr 1.7 发布
Dapr 是一个开源.可移植的.事件驱动的运行时,可以帮助开发人员构建在云和边缘上运行的弹性的.微服务的.无状态和有状态应用程序,并且关注于业务逻辑而不用考虑分布式相关的问题. 分布式相关的问题交给D ...
- CentOS 下 MySQL 服务搭建
1. 卸载旧 MySQL 查看 rpm 包 rpm-qa | grep mysql 如果存在,使用如下命令卸载 rpm -e 查找是否存在mysql 相关目录 find / -name mysql 卸 ...
- cookie和localstorge、sessionStorge的区别
一.背景由来 cookie原来是用来网络请求携带用户信息的,只不过在HTML5出现之前,前端没有本地存储的方法,只能使用cookie代替 localstorge.sessionStorge是html5 ...
- python基础练习题(题目 猴子吃桃问题:猴子第一天摘下若干个桃子,当即吃了一半,还不瘾,又多吃了一个第二天早上又将剩下的桃子吃掉一半,又多吃了一个。以后每天早上都吃了前一天剩下的一半零一个。到第10天早上想再吃时,见只剩下一个桃子了。求第一天共摘了多少)
day13 --------------------------------------------------------------- 实例021:猴子偷桃 题目 猴子吃桃问题:猴子第一天摘下若干 ...
- Linux中信号量的实现
如果一个任务获取信号量失败,该任务就必须等待,直到其他任务释放信号量.本文的重点是,在Linux中,当有任务释放信号量之后,如何唤醒正在等待该信号量的任务. 信号量定义如下: struct semap ...
- Vue Router的简单了解
Vue Router Vue Router官方文档 传统Web项目开发往往采用超链接实现页面之间的切换和跳转.Vue开发的是单页面应用(Single Page Application,SPA),不能使 ...
- 灵感乍现!造了个与众不同的Dubbo注册中心扩展轮子
hello大家好呀,我是小楼. 作为一名基础组件开发,服务好每一位业务开发同学是我们的义务(KPI). 客服群里经常有业务开发同学丢来一段代码.一个报错,而我们,当然要微笑服务,耐心解答. 有的问题, ...