python——5行代码采集3000+上市公司信息
毕业季也到了找工作的季节了,很多小伙伴都会一家一家的公司去看,这得多浪费时间啊。今天用Python教大家怎么采集公司的信息,相信大家会很喜欢这个教程的,nice!
基本环境配置
版本:Python3
系统:Windows
相关模块:pandas、csv
爬取目标网站
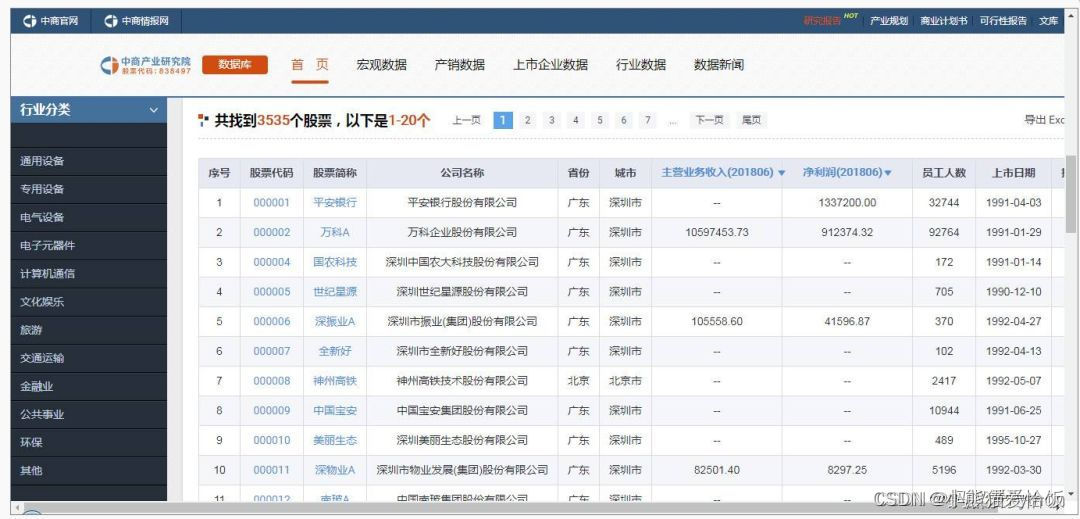
实现代码
###想要学习Python?Python学习交流群:660193417 满足你的需求,资料都已经上传群文件,可以自行下载!###
import pandas as pd
import csv
for i in range(1,178): # 爬取全部页
tb = pd.read_html('http://s.askci.com/stock/a/?reportTime=2017-12-31&pageNum=%s' % (str(i)))[3]
tb.to_csv(r'1.csv', mode='a', encoding='utf_8_sig', header=1, index=0)
3000+ 上市公司的信息,安安静静地躺在 Excel 中: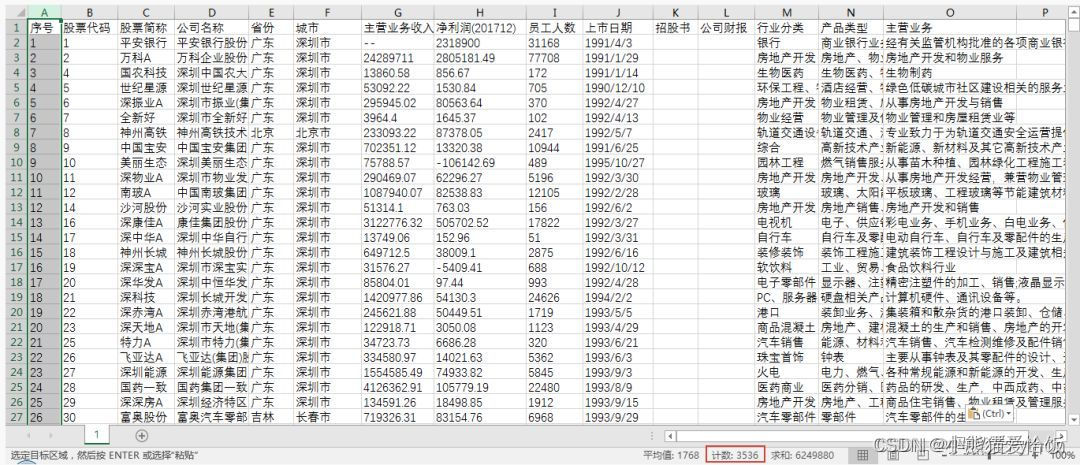
有了上面的信心后,我开始继续完善代码,因为 5 行代码太单薄,功能也太简单,大致从以下几个方面进行了完善:
- •增加异常处理
由于爬取上百页的网页,中途很可能由于各种问题导致爬取失败,所以增加了 try except 、if 等语句,来处理可能出现的异常,让代码更健壮。
- •增加代码灵活性
初版代码由于固定了 URL 参数,所以只能爬取固定的内容,但是人的想法是多变的,一会儿想爬这个一会儿可能又需要那个,所以可以通过修改 URL 请求参数,来增加代码灵活性,从而爬取更灵活的数据。
- •修改存储方式
初版代码我选择了存储到 Excel 这种最为熟悉简单的方式,人是一种惰性动物,很难离开自己的舒适区。但是为了学习新知识,所以我选择将数据存储到 MySQL 中,以便练习 MySQL 的使用。
- •加快爬取速度
初版代码使用了最简单的单进程爬取方式,爬取速度比较慢,考虑到网页数量比较大,所以修改为了多进程的爬取方式。
经过以上这几点的完善,代码量从原先的 5 行增加到了下面的几十行:
###想要学习Python?Python学习交流群:660193417 满足你的需求,资料都已经上传群文件,可以自行下载!###
import requests
import pandas as pd
from bs4 import BeautifulSoup
from lxml import etree
import time
import pymysql
from sqlalchemy import create_engine
from urllib.parse import urlencode # 编码 URL 字符串
start_time = time.time() #计算程序运行时间
def get_one_page(i):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
paras = {
'reportTime': '2017-12-31',
#可以改报告日期,比如2018-6-30获得的就是该季度的信息
'pageNum': i #页码
}
url = 'http://s.askci.com/stock/a/?' + urlencode(paras)
response = requests.get(url,headers = headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('爬取失败')
def parse_one_page(html):
soup = BeautifulSoup(html,'lxml')
content = soup.select('#myTable04')[0] #[0]将返回的list改为bs4类型
tbl = pd.read_html(content.prettify(),header = 0)[0]
# prettify()优化代码,[0]从pd.read_html返回的list中提取出DataFrame
tbl.rename(columns = {'序号':'serial_number', '股票代码':'stock_code', '股票简称':'stock_abbre', '公司名称':'company_name', '省份':'province', '城市':'city', '主营业务收入(201712)':'main_bussiness_income', '净利润(201712)':'net_profit', '员工人数':'employees', '上市日期':'listing_date', '招股书':'zhaogushu', '公司财报':'financial_report', '行业分类':'industry_classification', '产品类型':'industry_type', '主营业务':'main_business'},inplace = True)
return tbl
def generate_mysql():
conn = pymysql.connect(
host='localhost',
user='root',
password='******',
port=3306,
charset = 'utf8',
db = 'wade')
cursor = conn.cursor()
sql = 'CREATE TABLE IF NOT EXISTS listed_company (serial_number INT(20) NOT NULL,stock_code INT(20) ,stock_abbre VARCHAR(20) ,company_name VARCHAR(20) ,province VARCHAR(20) ,city VARCHAR(20) ,main_bussiness_income VARCHAR(20) ,net_profit VARCHAR(20) ,employees INT(20) ,listing_date DATETIME(0) ,zhaogushu VARCHAR(20) ,financial_report VARCHAR(20) , industry_classification VARCHAR(20) ,industry_type VARCHAR(100) ,main_business VARCHAR(200) ,PRIMARY KEY (serial_number))'
cursor.execute(sql)
conn.close()
def write_to_sql(tbl, db = 'wade'):
engine = create_engine('mysql+pymysql://root:******@localhost:3306/{0}?charset=utf8'.format(db))
try:
tbl.to_sql('listed_company2',con = engine,if_exists='append',index=False)
# append表示在原有表基础上增加,但该表要有表头
except Exception as e:
print(e)
def main(page):
generate_mysql()
for i in range(1,page):
html = get_one_page(i)
tbl = parse_one_page(html)
write_to_sql(tbl)
# # 单进程
if __name__ == '__main__':
main(178)
endtime = time.time()-start_time
print('程序运行了%.2f秒' %endtime)
# 多进程
from multiprocessing import Pool
if __name__ == '__main__':
pool = Pool(4)
pool.map(main, [i for i in range(1,178)]) #共有178页
endtime = time.time()-start_time
print('程序运行了%.2f秒' %(time.time()-start_time))
最后
这个过程觉得很自然,
因为每次修改都是针对一个小点,
一点点去学,搞懂后添加进来,
而如果让你上来就直接写出这几十行的代码,
你很可能就放弃了。
所以,你可以看到,入门爬虫是有套路的,
最重要的是给自己信心。
以上就是这篇文章的全部内容了,
希望本文的内容对大家的学习或者工作具有一定的参考学习价值,不懂的记得留言鸭!!!
python——5行代码采集3000+上市公司信息的更多相关文章
- Python 1行代码实现文本分类(实战笔记),含代码详细说明及运行结果
Python 1行代码实现文本分类(实战笔记),含代码详细说明及运行结果 一.详细说明及代码 tc.py =============================================== ...
- Python第一行代码
Python版本:Python 3.6.1 0x01 命令行交互 在交互式环境的提示符>>>下,直接输入代码,按回车,就可以立刻得到代码执行结果.现在,试试输入100+200,看看计 ...
- Python 5 行代码的神奇操作
Python 语言实现功能直接了当,简明扼要,今天咱们就来一起看看 Python 5 行代码的神奇操作! 1.古典兔子问题 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语 ...
- python多行代码简化
python中,可以把多行代码简化为一行,把for循环和if条件判断都集中到一行里来写,示例如下: >>> from nltk.corpus import stopwords > ...
- 利用Python几行代码批量生成验证码
几行代码批量生成authCode 整体步骤: 1.创建图片 2.创建画笔 3.在图片上生成点 4.在图片上画线 5.在图片在画圆 6.在图片在写文本 7.在图片在生成指定字体的文本 代码奉上 #!/u ...
- Python 3 行代码 5 秒抠图的 AI 神器,根本无需 PS
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 苏克1900 PS:如有需要Python学习资料的小伙伴可以加点击下 ...
- Python几行代码实现邮件发送
话不多说直接进入正题 首先我们需要安装一个名为'zmail'的包,终端执行'pip install zmail'即可实现安装. 直接上代码 import zmail mail = { 'subject ...
- 10分钟教你用python 30行代码搞定简单手写识别!
欲直接下载代码文件,关注我们的公众号哦!查看历史消息即可! 手写笔记还是电子笔记好呢? 毕业季刚结束,眼瞅着2018级小萌新马上就要来了,老腊肉小编为了咱学弟学妹们的学习,绞尽脑汁准备编一套大学秘籍, ...
- 比PS还好用!Python 20行代码批量抠图
你是否曾经想将某张照片中的人物抠出来,然后拼接到其他图片上去,从而可以即使你在天涯海角,我也可以到此一游? 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在 ...
随机推荐
- gin框架使用【5.路由分组】
package mainimport ( "github.com/gin-gonic/gin")func main() { router := gin.Default() v1Ro ...
- 手把手教会 VS2022 设计 Winform 高DPI兼容程序 (net461 net6.0 双出)
本文主要解决两个问题 C# Winform高DPI字体模糊. 高DPI下(缩放>100%), UI设计器一直提示缩放到100%, 如果不重启到100%,设计的控件会乱飞. 建立测试程序 新建.N ...
- 通知:PostgreSQL证书申报退税请抓紧!
2021年个税申报已于3月开始为了确保PostgreSQL证书能顺利退税中心特调研了学员中仅针对证书一项做退税申请没几天就得到结果2021年取得的PostgreSQL职业 技术证书确定可以退税! ...
- python学习-Day7
目录 作业讲解 数据类型内置方法2 字符串(str) 列表(list) 类型转换 内置方法 索引取值 切片操作 步长 统计列表中元素的个数 成员运算 (in和not in) 列表添加元素的方式* 删除 ...
- XCTF练习题---MISC---glance-50
XCTF练习题---MISC---glance-50 flag:TWCTF{Bliss by Charles O'Rear} 解题步骤: 1.观察题目,下载附件 2.下载完成以后,隐隐约约像是一张动图 ...
- [AcWing 68] 0到n-1中缺失的数字
点击查看代码 class Solution { public: int getMissingNumber(vector<int>& nums) { if (nums.empty() ...
- Markdown基础语法(上)
前言 按照官方文档,和根据自己所用和所理解所写 一.标题语法 一级标题最大,六级标题最小 # 一级标题 ## 二级标题 ### 三级标题 #### 四级标题 ##### 五级标题 ###### 六级标 ...
- 一文彻底搞懂JavaScript中的prototype
prototype初步认识 在学习JavaScript中,遇到了prototype,经过一番了解,知道它是可以进行动态扩展的 function Func(){}; var func1 = new Fu ...
- vue-router实现原理及简易demo
自定义路由demo,git地址: git@github.com:xsk-walter/Vue-router.git 一.router基本使用 ① 创建和路由相关的组件 ②Vue.use(vueRout ...
- Python数据分析--工具安装及Numpy介绍(1)
Anaconda 是一个跨平台的版本,通过命令行来管理安装包.进行大规模数据处理.预测分析和科学计算.它包括近 200 个工具包,大数据处理需要用到的常见包有 NumPy . SciPy . pand ...