Numpy库基础___五
Numpy数据存取
•NumPy的随机数函数
 a = np.random.rand(1,2,3)
a = np.random.rand(1,2,3)
print(a)
#[[[0.03339719 0.72784732 0.47527802]
# [0.6456671 0.65639799 0.01300073]]] a = np.random.randn(1,2,3)
print(a)
#[[[ 0.59115211 -0.40289048 1.34532466]
# [-0.04616715 -0.64066822 -1.09722129]]] a = np.random.randint(100,200,(3,4))
print(a)
#[[161 131 187 134]
# [156 114 104 180]
# [182 163 158 121]] #随机数种子,10是给定的种子值
np.random.seed(10)
a = np.random.randint(100,200,(3,4))
print(a)
#[[109 115 164 128]
# [189 193 129 108]
# [173 100 140 136]]
a = np.random.randint(100,200,(3,4))
print(a)
#[[184 199 152 144]
# [173 171 179 144]
# [133 105 197 143]] np.random.shuffle(a)
print(a)
#[[173 171 179 144]
# [133 105 197 143]
# [184 199 152 144]] b = np.random.permutation(a)
#[[173 171 179 144]
# [133 105 197 143]
# [184 199 152 144]]
print(b)
#[[133 105 197 143]
# [173 171 179 144]
# [184 199 152 144]] a = np.random.randint(100,200,(8,))
print(a)
#[131 195 130 165 177 107 197 132] b = np.random.choice(a,(3,2))
print(b)
#[[195 107]
# [177 197]
# [130 107]] b = np.random.choice(a,(3,2),replace=False)
#[[107 130]
# [197 132]
# [195 131]] #加权,元素出现次数越多,被抽取的概率越高
b = np.random.choice(a,(3,2),p=a/np.sum(a))
print(b)
#[[197 130]
# [131 130]
# [131 130]]
u = np.random.uniform(0,10,(3,4))
print(u)
#[[7.49328353 4.35990777 8.19266316 5.02229727]
# [2.21122875 9.61785352 9.90294149 2.44401573]
# [3.88367203 9.22037768 7.87306998 2.00241521]] u = np.random.normal(10,5,(3,4))
print(u)
#[[13.44007699 10.5502136 14.79616224 -2.17381553]
# [10.42238979 10.12351539 2.8561042 16.78322252]
# [11.90679396 6.75343566 8.01259211 14.96874378]] u = np.random.poission(2,(3,4))
print(u)
#[[4 0 1 2]
# [2 2 3 2]
# [0 0 2 3]]
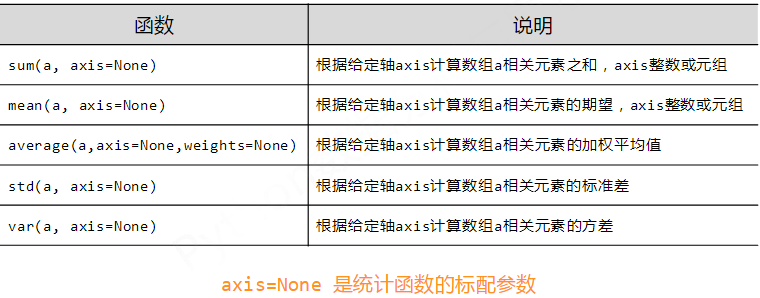
•NumPy的统计函数
a = np.arange(15).reshape(3,5)
print(a)
#[[ 0 1 2 3 4]
# [ 5 6 7 8 9]
# [10 11 12 13 14]]
print(np.sum(a))
#105
print(np.sum(a,axis=0))
#[15 18 21 24 27]
print(np.sum(a,axis=1))
#[10 35 60] print(np.mean(a))
#7.0
print(np.mean(a,axis=0))
#[5. 6. 7. 8. 9.]
print(np.mean(a,axis=1))
#[ 2. 7. 12.] print(np.average(a))
#7.0
print(np.average(a,axis=0,weights=[1,2,3]))
#[ 6.66666667 7.66666667 8.66666667 9.66666667 10.66666667]
a = np.arange(12).reshape(3,4)
print(a)
#[[ 0 1 2 3]
# [ 4 5 6 7]
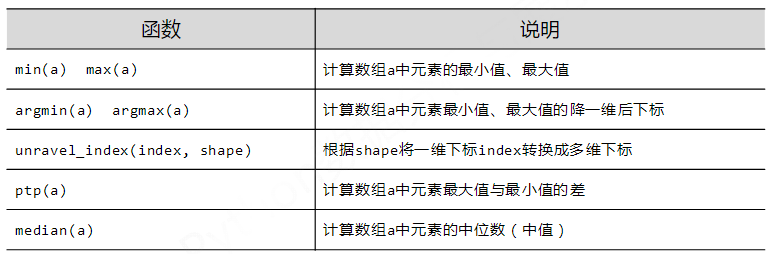
# [ 8 9 10 11]] print(np.min(a))
#0 print(np.max(a))
#11 print(np.argmin(a))
#0 print(np.argmax(a))
#11 print(np.unravel_index(10,(4,3)))
#(3,1) print(np.unravel_index(np.argmax(a),(4,3)))
#(3,2) print(np.ptp(a))
#11 print(np.median(a))
#5.5
•NumPy的梯度函数
- np.gradient(f):计算数组f中元素的梯度,当f为多维时,返回每个维度梯度
梯度:连续值之间的变化率,即斜率
X坐标轴连续三个x坐标对应的Y轴值:a,b,c其中b的梯度时(c-a)/2
a = np.random.randint(0,20,(5,))
print(a)
#[ 2 10 11 14 12] print(np.gradient(a))
#[ 8. 4.5 2. 0.5 -2. ]




Numpy库基础___五的更多相关文章
- Numpy库基础___四
Numpy数据存取 •数据的csv文件的存取 只能有效存取和读取一维和二维数据 a = np.arange(100).reshape(5,20) #用delimiter分割,默认为空格 np.save ...
- Numpy库基础___一
ndarray一个强大的N维数组对象Array •ndarray的建立(元素默认浮点数) 可以利用list列表建立ndarray import numpy as np list =[0,1,2,3] ...
- Numpy库基础___三
ndarray一个强大的N维数组对象Array •ndarray的操作 索引 a = np.arange(24).reshape((2,3,4)) print(a) #[[[ 0 1 2 3] # [ ...
- Numpy库基础___二
ndarray一个强大的N维数组对象Array •ndarray的变换 x.reshape(shape)重塑数组的shape,要求元素的个数一致,不改变原数组 x = np.ones((2,3,4), ...
- Numpy库的学习(五)
今天继续学习一下Numpy库,废话不多说,整起走 先说下Numpy中,经常会犯错的地方,就是数据的复制 这个问题不仅仅是在numpy中有,其他地方也同样会出现 import numpy as np a ...
- $python数据分析基础——初识numpy库
numpy库是python的一个著名的科学计算库,本文是一个quickstart. 引入:计算BMI BMI = 体重(kg)/身高(m)^2 假如有如下几组体重和身高数据,让求每组数据的BMI值: ...
- Python基础——numpy库的使用
1.numpy库简介: NumPy提供了许多高级的数值编程工具,如:矩阵数据类型.矢量处理,以及精密的运算库.专为进行严格的数字处理而产生. 2.numpy库使用: 注:由于深度学习中存在大量的 ...
- 数据分析与科学计算可视化-----用于科学计算的numpy库与可视化工具matplotlib
一.numpy库与matplotlib库的基本介绍 1.安装 (1)通过pip安装: >> pip install matplotlib 安装完成 安装matplotlib的方式和nump ...
- numpy库的学习笔记
一.ndarray 1.numpy 库处理的最基础数据类型是由同种元素构成的多维数组(ndarray),简称“数组”. 2.ndarray是一个多维数组的对象,ndarray数组一般要求所有元素类型相 ...
随机推荐
- Java执行cmd命令、bat脚本、linux命令,shell脚本等
1.Windows下执行cmd命令 如复制 D:\tmp\my.txt 到D:\tmp\my_by_only_cmd.txt 现文件如图示: 执行代码: private static void run ...
- Nacos中服务删除不了,怎么办?
前两天遇到了一个问题,Nacos 中的永久服务删除不了,折腾了一番,最后还是顺利解决了.以下是原因分析和解决方案,建议先收藏,以备不时之需. 临时实例和持久化实例是 Nacos 1.0.0 中新增了一 ...
- mysql data local的使用导入与导出数据到.txt
一.先创建表 CREATE TABLE stu(id INT UNSIGNED AUTO_INCREMENT,NAME VARCHAR(15) UNIQUE, /* 唯一约束 , 可以不填写,如果填写 ...
- MySQL架构原理之运行机制
所谓运行机制即MySQL内部就如生产车间如何进行生产的.如下图: 1.建立连接,通过客户端/服务器通信协议与MySQL建立连接.MySQL客户端与服务端的通信方式是"半双工".对于 ...
- VS2019如何设置程序以管理员权限启动
最重要的一点.本文解释的是C#项目如何以管理员权限启动. 一个很大的误导项 该图片是C++程序的项目配置属性.C#项目中并找不到.然而网上的很多教程没有说清楚.导致我找了这个菜单找了很久. C#项目的 ...
- IDEA自带Http Client替代Postman校验接口
对比Postman的优势 对于数据格式变动可以更为敏锐的观察到.生成的接口请求文件可以同步到代码库,支持多人使用. 使用说明 创建请求文件 使用IDEA,在项目的Scratches下创建Http Re ...
- python写的百度图片爬虫
学了一下python正则表达式,写一个百度图片爬虫玩玩. 当技术遇上心术不正的人,就成我这样的2B青年了. python3.6开发.程序已经打包好,下载地址: http://pan.baidu.com ...
- 『无为则无心』Python面向对象 — 57、类属性和实例属性
目录 1.类属性 (1)类属性的访问 (2)修改类属性 2.类属性和实例属性区别 1.类属性 (1)类属性的访问 类属性就是 类对象 所拥有的属性,它被 该类的所有实例对象 所共有. 类属性可以使用 ...
- CobaltStrike逆向学习系列(10):TeamServer 启动流程分析
这是[信安成长计划]的第 10 篇文章 关注微信公众号[信安成长计划] 0x00 目录 0x01 基本校验与解析 0x02 初始化 0x03 启动 Listeners 在之前的分析中,都是针对 Cob ...
- sql注入代码分析及预防
sql注入的原因,表面上说是因为 拼接字符串,构成sql语句,没有使用 sql语句预编译,绑定变量.但是更深层次的原因是,将用户输入的字符串,当成了 "sql语句" 来执行. 1. ...