创建进程的多种方式、多进程实现TCP并发等知识点
创建进程的多种方式、多进程实现TCP并发等知识点
一、同步与异步
1.提交完成任务之后原地等待任务的返回结果,期间不做任何事
2.提交完任务之后不愿原地等待任务的返回结果,直接去做其他事情,有结果自动通知

二、阻塞与非阻塞
阻塞:
阻塞态:指结果返回之前,当前线程会被挂起,调用线程只有得到结果之后才会返回
非阻塞:
指在不能立刻得到结果之前,该调用不会阻塞当前线程。即就是就绪态,运行态
同步异步:用来描述任务的提交方式
阻塞和非阻塞:用来描述任务执行的状态
1. 同步阻塞:效率最低
在银行排队,并且在队伍中什么事情都不做。
2. 同步非阻塞:实际上是效率低下的,这个程序需要在这几种不同的行为之间来回的切换。
在银行排队,并且在队伍中做点其他事。
3. 异步阻塞:采用的是异步的方式去等待消息被触发(通知),异步操作是可以被阻塞住的,只不过它不是在处理消息时阻塞,而是在等待消息通知时被阻塞。
取号,在座位上等着叫号,期间不做事。
4.异步非阻塞:效率更高,程序不用在不同的操作中来回切换。
取号,在旁边座位上等着叫号,期间做任何自己想要做的事。
三、创建进程的多种方式
1.鼠标双击软件图标
2.Python代码创建进程
from multiprocessing import Process
import time
def task(name):
print('running',name)
time.sleep(3)
print('over',name)
if __name__ == '__main__':
p1 = Process(target=task,args=('jia',))
p1.start()
# task()
from multiprocessing import Process
import time
# def task(name):
# print('running',name)
# time.sleep(3)
# print('over',name)
class MyProcess(Process):
def __init__(self,name,age):
super().__init__()
self.name = name
self.age = age
def run(self):
print('running', self.name, self.age)
time.sleep(3)
print('over', self.name, self.age)
if __name__ == '__main__':
obj = MyProcess('jia',12)
obj.start()
print('main')
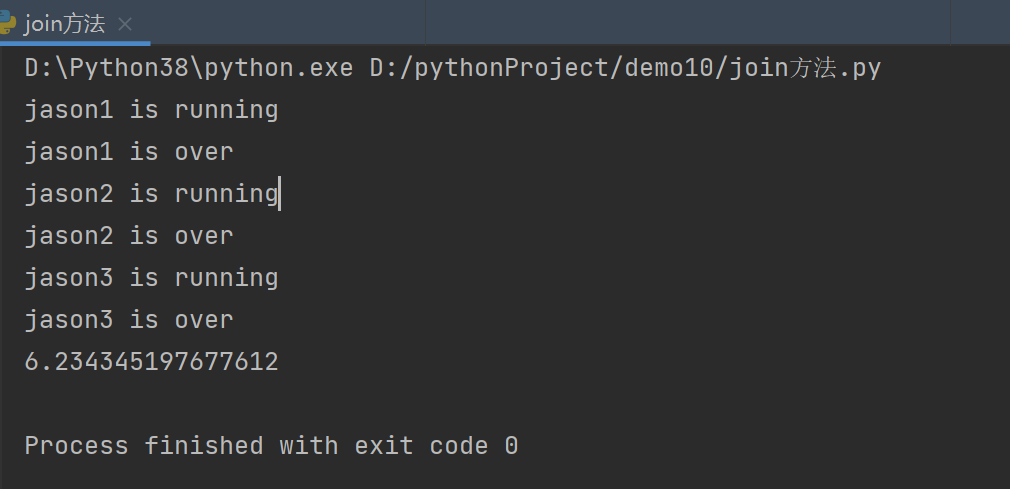
四、进程join方法
from multiprocessing import Process
import time
def task(name,n):
print('%s is running' % name)
time.sleep(n)
print('%s is over' % name)
if __name__ == '__main__':
p1 = Process(target=task,args=('jason1',1))
p2 = Process(target=task,args=('jason2',2))
p3 = Process(target=task,args=('jason3',3))
start_time = time.time()
p1.start()
p1.join()
# 注进程代码等待子进程代码运行结束后再执行
p2.start()
p2.join()
p3.start()
p3.join()
print(time.time() - start_time)
五、进程间数据隔离
# 同一台计算机上的多个进程数据是严格意义上的物理隔离
from multiprocessing import Process
import time
money = 1000
def task():
global money
money = 99
print('子进程的task函数查看money',money)
if __name__ == '__main__':
p1 = Process(target=task)
p1.start() # 创建子进程
time.sleep(2)
print(money)
六、进程间通信IPC机制
IPC:进程间的通信
消息队列:存储数据的地方,所有人都可以存,也可以取
from multiprocessing import Queue
q= Queue(4) # 括号内可以指定存储数的个数
q.put(111) # 往消息队列中存放数据
q.put(777) # 往消息队列中存放数据
q.put(999) # 往消息队列中存放数据
print(q.get()) # 取出数据
print(q.get()) # 取出数据
# print(q.get()) # 取出数据
print(q.get_nowait())
from multiprocessing import Process, Queue
def product(q):
q.put('子进程p添加的数据')
def consumer(q):
print('子进程获取队列中的数据', q.get())
if __name__ == '__main__':
q = Queue()
# 主进程往队列中添加数据
p1 = Process(target=consumer, args=(q,))
p2 = Process(target=product, args=(q,))
p1.start()
p2.start()
print('main')
七、进程对象诸多方法
1.如何查看进程号
from multiprocessing import Process,current_process
current_process()
current_process().pid
import os
os.getpid()
os.getppid()
2.终止进程
p1.terminate()
ps:计算机操作系统都有对应的命令可以直接杀死进程
3.判断进程是否存活
p1.is_alive()
八、生产者消费者模型
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
简单的来说就是我们去买棒冰,生产者肯定先制作好棒冰(数据),我们去买的时候生产者会卖给我们,再次期间这些棒冰会存储在冰柜内(消息队列/数据库)。
'''
完整的生产者消费者模型至少有是三个部分:
生产者
消息队列/数据库
消费者
'''
九、守护进程
# 守护进程会随着守护的进程结束而立刻结束
from multiprocessing import Process
import time
def task(name):
print('仙女姐姐:%s' % name)
time.sleep(3)
print('仙女姐姐:%s' % name)
if __name__ == '__main__':
p1 = Process(target=task,args=('feifei',))
p1.daemon = True
p1.start()
time.sleep(1)
print('仙女姐姐走了')
十、僵尸进程与孤儿进程
僵死进程:子进程退出后,会将该进程的重型资源释放掉(cpu,内存,打开的文件),子进程的进程描述符仍然保存在系统中,比如pid。
所有的子进程在运行结束之后都会变成僵尸进程(死了没死透)
程序正常结束才会产生僵尸进程,如果强制关闭父进程,操作系统会把父进程已经运行结束的子进程全部删除,也就不会产生僵尸进程了。
僵尸进程的危害:
系统的pid号是有限的,僵尸进程保留的信息如果一直不被释放,一直累计会导致没有可用的pid号而导致系统不能产生新的进程。
'''进程已经运行结束,但是相关的资源并没有完全清空,需要父进程参与回收'''
孤儿进程(无害):一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。
'''父进程意外死亡,子进程正常运行,该子进程就称之为孤儿进程,孤儿进程也不是没有人管,操作系统会自动分配福利院接收'''
十一、多进程数据错乱问题
from multiprocessing import Process
import time
import json
import random
# 查票
def search(name):
with open(r'data.json', 'r', encoding='utf8') as f:
data = json.load(f)
print('%s在查票 当前余票为:%s' % (name, data.get('ticket_num')))
# 买票
def buy(name):
# 再次确认票
with open(r'data.json', 'r', encoding='utf8') as f:
data = json.load(f)
# 模拟网络延迟
time.sleep(random.randint(1, 3))
# 判断是否有票 有就买
if data.get('ticket_num') > 0:
data['ticket_num'] -= 1
with open(r'data.json', 'w', encoding='utf8') as f:
json.dump(data, f)
print('%s买票成功' % name)
else:
print('%s很倒霉 没有抢到票' % name)
def run(name):
search(name)
buy(name)
if __name__ == '__main__':
for i in range(10):
p = Process(target=run, args=('用户%s'%i, ))
p.start()
# 用户1在查票 当前余票为:1
# 用户0在查票 当前余票为:1
# 用户2在查票 当前余票为:1
# 用户3在查票 当前余票为:1
# 用户4在查票 当前余票为:1
# 用户5在查票 当前余票为:1
# 用户6在查票 当前余票为:1
# 用户7在查票 当前余票为:1
# 用户8在查票 当前余票为:1
# 用户9在查票 当前余票为:1
# 用户2买票成功
# 用户5买票成功
# 用户4买票成功
# 用户3买票成功
# 用户0买票成功
# 用户7买票成功
# 用户9买票成功
# 用户6买票成功
# 用户1买票成功
# 用户8买票成功
创建进程的多种方式、多进程实现TCP并发等知识点的更多相关文章
- Python—创建进程池的方式
创建进程池 from multiprocessing import Pool import time,os result = [] # 存放所有worker函数的返回值 def worker(msg) ...
- java创建线程的多种方式
java创建线程的四种方式 1.继承 Thread 类 通过继承 Thread 类,并重写它的 run 方法,我们就可以创建一个线程. 首先定义一个类来继承 Thread 类,重写 run 方法. 然 ...
- 使用docker创建静态网站应用-多种方式
能承载静态网站的服务器有很多,本文使用,nginx.apache.tomcat服务器演示docker静态网站应用设置 一,创建docker文件, 不同服务器的docker文件不一样,下面分别创建ngi ...
- Python 创建字典的多种方式
1.通过关键字dict和关键字参数创建 >>> dic = dict(spam = 1, egg = 2, bar =3) >>> dic {'bar': 3, ' ...
- Java并发编程原理与实战五:创建线程的多种方式
一.继承Thread类 public class Demo1 extends Thread { public Demo1(String name) { super(name); } @Override ...
- 并发编程 ~~~ 多进程~~~进程创建的两种方式, 进程pid, 验证进程之间的空间隔离, 进程对象join方法, 进程对象其他属性
一 进程创建的两种方式 from multiprocessing import Process import time def task(name): print(f'{name} is runnin ...
- Python之路(第三十七篇)并发编程:进程、multiprocess模块、创建进程方式、join()、守护进程
一.在python程序中的进程操作 之前已经了解了很多进程相关的理论知识,了解进程是什么应该不再困难了,运行中的程序就是一个进程.所有的进程都是通过它的父进程来创建的.因此,运行起来的python程序 ...
- python并发编程之多进程(一):进程开启方式&多进程
一,进程的开启方式 利用模块开启进程 from multiprocessing import Process import time,random import os def piao(name): ...
- python开发进程:进程开启方式&多进程
一,进程的开启方式 利用模块开启进程 from multiprocessing import Process import time,random import os def piao(name): ...
- 零基础逆向工程39_Win32_13_进程创建_句柄表_挂起方式创建进程
1 进程的创建过程 打开系统 --> 双击要运行的程序 --> EXE开始执行 步骤一: 当系统启动后,创建一个进程:Explorer.exe(也就是桌面进程) 步骤二: 当用户双击某一个 ...
随机推荐
- Sublime Text4(Build 4126) 安装备忘
Sublime Text4(Build 4126) 安装备忘 sublime text 4126 PJ已测可用 打开浏览器进入网站https://hexed.it 打开sublime text4安装目 ...
- SpringBoot 解决跨域问题代码
package com.example.demo.gs; import org.springframework.context.annotation.Configuration; import jav ...
- Educational Codeforces Round 130 (Rated for Div. 2) C. awoo's Favorite Problem
https://codeforc.es/contest/1697/problem/C 因为规则中,两种字符串变换都与'b'有关,所以我们根据b的位置来进行考虑: 先去掉所有的'b',如果两字符串不相等 ...
- xlwings 模块总结
基本使用 在子线程中使用时,有时需要在子线程函数中加入以下.有时不需要加入,目前还不明白具体的原因 import pythoncom # 导入的库 pythoncom.CoInitialize() # ...
- Java继承Frame画一个窗口显示图片
将图片显示到窗口上. 在工程目录下准备好图片5.png 运行代码: import javax.imageio.ImageIO; import java.awt.*; import java.awt.e ...
- 【题解】CF1714F Build a Tree and That Is It
题面传送门 解决思路 题目中虽然说是无根树,但我们可以钦定这棵树的根为节点 \(1\),方便构造,这是不 影响结果的. 以下记给定的三段长度为 \(a,b,c\). 先考虑无解的情况. 首先,给出的三 ...
- 01-Docker实战,搭建NodeJs环境
目的 实现简单的docker的nodejs容器,使用Dockerfile构建我们的使用nodejs开发的系统 技术栈 Docker Nodejs Express Linux step1 下拉nodej ...
- ifconfig命令的使用
ifconfig命令 用途:配置或显示TCP/IP网络的网络接口参数. *1.通过--help学习ifconfig的使用 点击查看代码 [root@rocky8 ~]# ifconfig --help ...
- C温故补缺(二):volatile
volatile 参考:CSDN volatile也是一个类型修饰符,被其修饰的变量意味着可以被某些编译器未知的因素修改,如操作系统,硬件,线程等. 当遇到volatile修饰的变量时,编译器对访问该 ...
- 运用领域模型——DDD
模型被用来描述人们所关注的现实或想法的某个方面.模型是一种简化.它是对现实的解释 -- 把与解决问题密切相关的方面抽象出来,而忽略无关的细节. 每个软件程序是为了执行用户的某项活动,或是满足客户的某种 ...