python妹子图爬虫5千张高清大图突破防盗链福利5千张福利高清大图
meizitu-spider
python通用爬虫-绕过防盗链爬取妹子图
这是一只小巧方便,强大的爬虫,由python编写
所需的库有
- requests
- BeautifulSoup
- os
- lxml
伪装成chrome浏览器,并加上referer请求头访问服务器不会被拒绝。
完整项目放在GitHub:https://github.com/Ymy214/meizitu-spider
具体实现思路:
- 分析网页源代码结构
- 找到合适的入口
- 循环爬取并去重加到循环队列
- 基本上实现了爬取所有图片
代码思路/程序流程:
我通过观察发现meizitu网站的分布结构虽然找不到切入口但是其结构每一个页面都会展示一个main-image主图,并且页面下面都会有推荐这个板块,所以就i昂到了利用从一个页面当作入口,利用beautifulsoup或者pyquery分析HTML页面提取出推荐的其他页面,添加到循环访问队列,整体程序最外蹭利用while循环控制结构,循环不重复地遍历队列里面的url页面,每个页面都只保存一个作为展示的主图这样就循环下去程序不停歇地运行也可以放到服务器上面爬取,顺便上传到网盘分享给广大--你懂的
下面是功能以及效果展示
整体展示
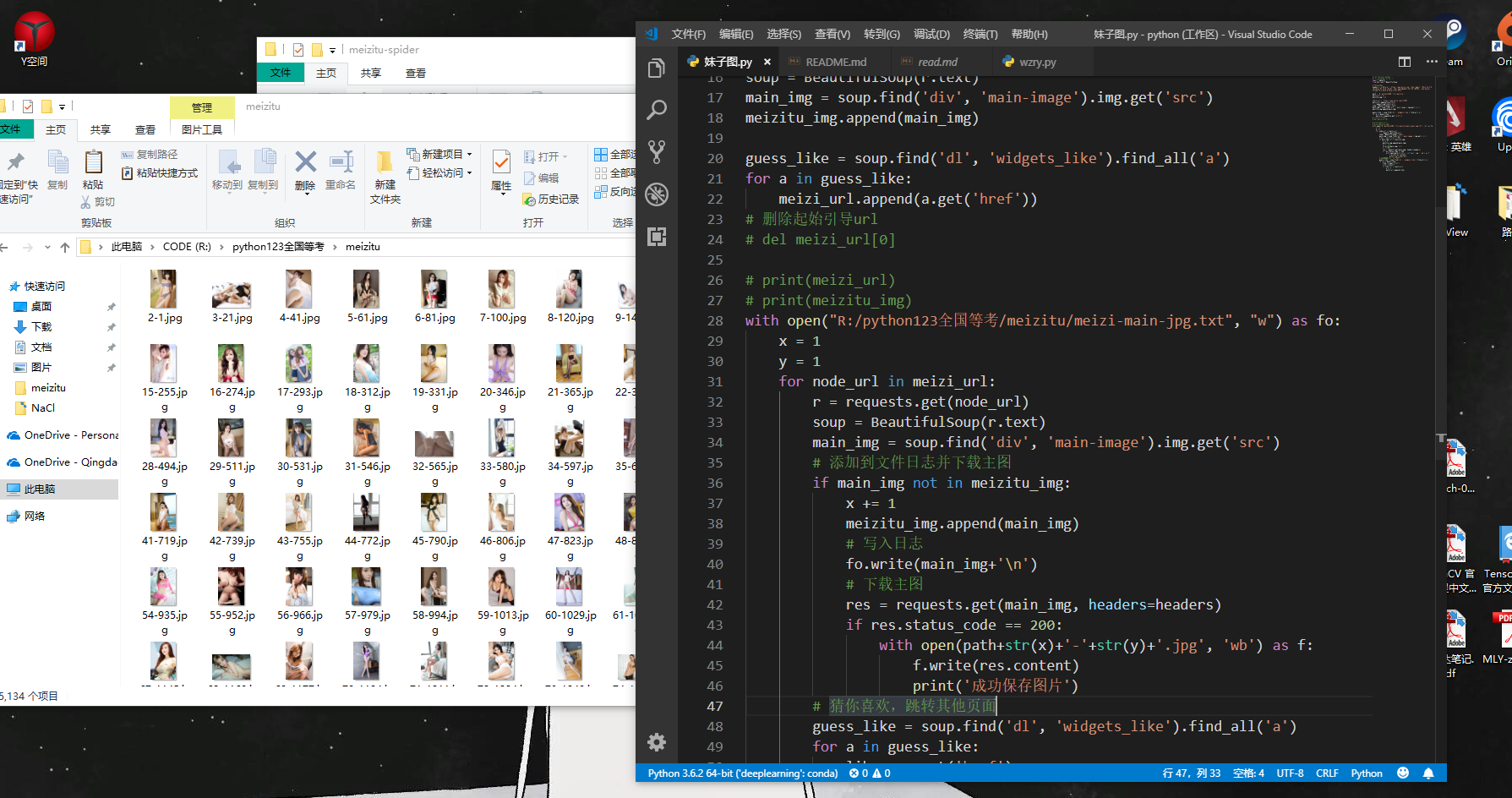
爬取效果展示-丰功伟绩
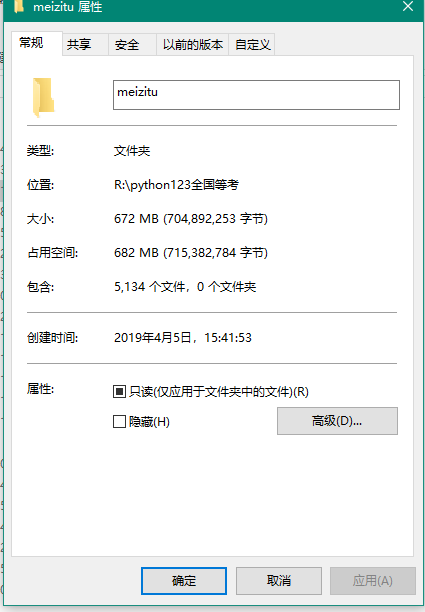
爬取效果展示-硕果累累
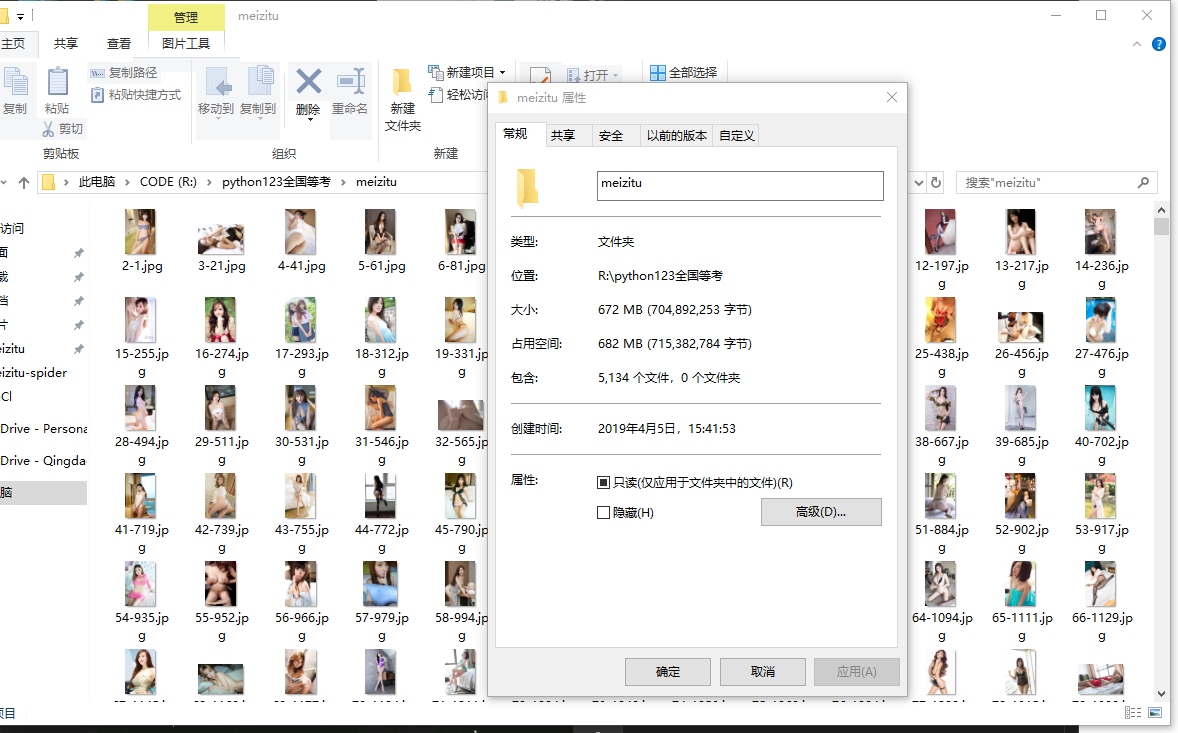
定制请求头
代码展示
python源代码如下
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
# 定制请求头
headers = {'Referer':'https://www.mzitu.com','User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3679.0 Safari/537.36'}
path = 'R:/python123全国等考/meizitu/'
meizi_url = []
meizitu_img = []
start_url = 'https://www.mzitu.com/177007'
meizi_url.append(start_url)
r = requests.get(start_url)
soup = BeautifulSoup(r.text)
main_img = soup.find('div', 'main-image').img.get('src')
meizitu_img.append(main_img)
guess_like = soup.find('dl', 'widgets_like').find_all('a')
for a in guess_like:
meizi_url.append(a.get('href'))
# 删除起始引导url
# del meizi_url[0]
# print(meizi_url)
# print(meizitu_img)
with open("R:/python123全国等考/meizitu/meizi-main-jpg.txt", "w") as fo:
x = 1
y = 1
for node_url in meizi_url:
r = requests.get(node_url)
soup = BeautifulSoup(r.text)
main_img = soup.find('div', 'main-image').img.get('src')
# 添加到文件日志并下载主图
if main_img not in meizitu_img:
x += 1
meizitu_img.append(main_img)
# 写入日志
fo.write(main_img+'\n')
# 下载主图
res = requests.get(main_img, headers=headers)
if res.status_code == 200:
with open(path+str(x)+'-'+str(y)+'.jpg', 'wb') as f:
f.write(res.content)
print('成功保存图片')
# 猜你喜欢,跳转其他页面
guess_like = soup.find('dl', 'widgets_like').find_all('a')
for a in guess_like:
like = a.get('href')
# 添加推荐页面
if like not in meizi_url:
y += 1
meizi_url.append(like)
另外本人还有面下给小白的
- 王者荣耀皮肤高清大图
- 背景故事爬虫
欢迎学习支持
有用或帮到你的话不妨点个star我将感激不尽
python妹子图爬虫5千张高清大图突破防盗链福利5千张福利高清大图的更多相关文章
- [Python爬虫]煎蛋网OOXX妹子图爬虫(1)——解密图片地址
之前在鱼C论坛的时候,看到很多人都在用Python写爬虫爬煎蛋网的妹子图,当时我也写过,爬了很多的妹子图片.后来煎蛋网把妹子图的网页改进了,对图片的地址进行了加密,所以论坛里面的人经常有人问怎么请求的 ...
- Scrapy框架实战-妹子图爬虫
Scrapy这个成熟的爬虫框架,用起来之后发现并没有想象中的那么难.即便是在一些小型的项目上,用scrapy甚至比用requests.urllib.urllib2更方便,简单,效率也更高.废话不多说, ...
- Python爬虫入门教程 2-100 妹子图网站爬取
妹子图网站爬取---前言 从今天开始就要撸起袖子,直接写Python爬虫了,学习语言最好的办法就是有目的的进行,所以,接下来我将用10+篇的博客,写爬图片这一件事情.希望可以做好. 为了写好爬虫,我们 ...
- 爬虫实战【5】送福利!Python获取妹子图上的内容
[插入图片,妹子图首页] 哈,只敢放到这个地步了. 今天给直男们送点福利,通过今天的代码,可以把你的硬盘装的满满的~ 下面就开始咯! 第一步:如何获取一张图片 假如我们知道某张图片的url,如何获取到 ...
- Python协程爬取妹子图(内有福利,你懂得~)
项目说明: 1.项目介绍 本项目使用Python提供的协程+scrapy中的选择器的使用(相当好用)实现爬取妹子图的(福利图)图片,这个学会了,某榴什么的.pow(2, 10)是吧! 2.用到的知 ...
- Python3爬虫系列:理论+实验+爬取妹子图实战
Github: https://github.com/wangy8961/python3-concurrency-pics-02 ,欢迎star 爬虫系列: (1) 理论 Python3爬虫系列01 ...
- Python Scrapy 爬取煎蛋网妹子图实例(一)
前面介绍了爬虫框架的一个实例,那个比较简单,这里在介绍一个实例 爬取 煎蛋网 妹子图,遗憾的是 上周煎蛋网还有妹子图了,但是这周妹子图变成了 随手拍, 不过没关系,我们爬图的目的是为了加强实战应用,管 ...
- 《Python 3网络爬虫开发实战中文》超清PDF+源代码+书籍软件包
<Python 3网络爬虫开发实战中文>PDF+源代码+书籍软件包 下载: 链接:https://pan.baidu.com/s/18yqCr7i9x_vTazuMPzL23Q 提取码:i ...
- python爬取妹子图全站全部图片-可自行添加-线程-进程爬取,图片去重
from bs4 import BeautifulSoupimport sys,os,requests,pymongo,timefrom lxml import etreedef get_fenlei ...
随机推荐
- 【剑指Offer】面试题18. 删除链表的节点
题目 给定单向链表的头指针和一个要删除的节点的值,定义一个函数删除该节点. 返回删除后的链表的头节点. 注意:此题对比原题有改动 示例 1: 输入: head = [4,5,1,9], val = 5 ...
- PHP ~ 通过程序删除图片,同时删除数据库中的图片数据 和 图片文件
删除单张图片 <?php require_once '../../conn.php'; //连接数据库 $ID = $_GET['ID' ...
- 19 01 16 djano 视图以及url
视图 后台管理页面做好了,接下来就要做公共访问的页面了.当我们刚刚在浏览器中输入 http://127.0.0.1:8000/admin/ 之后,浏览器显示出了后台管理的登录页面,那有没有同学想过这个 ...
- VM15上安装macOS操作系统
(该篇博客已经成功安装上Xcode,放心下载) 因为要开学了,需要学习mac操作系统,自己没有苹果电脑只能虚拟机上下载喽 我在电脑上安装的VM15虚拟机,不会安装的可以来这里下载软件VM15虚拟机 ...
- 三十一、CI框架之使用验证码
一.CI的验证码功能用着很是舒服,需要在根目录下新建一个captcha的验证码文件夹用于存放生产的图片,代码如下: 二.浏览器效果如下: 总结:关于验证码生产函数,有很多参数可以设置,包括字体,验证码 ...
- javascript 连续赋值(连等运算)问题研究
前几天看到一个javascript 连续赋值的问题,运行了一下,结果出乎意料,发现这里的水真的有点深啊,连续赋值的底层机制,没有一本前端书籍有详细介绍的,自己做实验研究了一下,先来看结果: var a ...
- 利用京东云Serverless服务快速构建5G时代的IoT应用
10月31日,在2019年中国国际信息通信展览会上,工信部宣布:5G商用正式启动.5G商用时代来了! 5G的商用,使得数据传输速度.响应速度.连接数据.数据传输量.传输可靠性等方面都有了显著的提升,这 ...
- java伪代码 (第一章)
在<大道至简>第一章中,周爱民先生引用一则<愚公移山>的寓言,引出了编程的根本:顺序.选择.循环.汤问篇中所述的愚公移山这一事件,我们看到了原始需求的产生---“惩山北之塞,出 ...
- css 居中布局方案
position(transform css3 有些浏览器不兼容) <article id="one"> <section id="section&q ...
- ORACLE常见问题收集
1.Java代码执行oracle,update和insert语句卡住不动 解决方法:造成这样的情况原因在于你之前执行了update或insert操作但你并没有commit,导致你操作的这条记录被ora ...