2020/4/26 大数据的zookeeper分布式安装
大数据的zookeeper分布式安装
**** 前面的文章已经提到Hadoop的伪分布式安装。现在就在原有的基础上安装zookeeper。
首先启动Hadoop平台
[root@master ~]# start-all.sh
Starting namenodes on [master]
Last login: Thu Mar 19 10:06:13 EDT 2020 from 192.168.200.1 on pts/2
Starting datanodes
Last login: Thu Mar 19 10:13:28 EDT 2020 on pts/2
Starting secondary namenodes [node1]
Last login: Thu Mar 19 10:13:31 EDT 2020 on pts/2
Starting resourcemanager
Last login: Thu Mar 19 10:13:46 EDT 2020 on pts/2
Starting nodemanagers
Last login: Thu Mar 19 10:13:56 EDT 2020 on pts/2
将下载好的zookeeper安装包上传到master节点
[root@master ~]# ls
anaconda-ks.cfg zookeeper-3.4.14.tar.gz
将安装包解压在当前的文件夹
[root@master ~]# tar -zxvf zookeeper-3.4.14.tar.gz
进入zookeeper-3.4.14/目录下,查看zookeeper的文件部署
[root@master ~]# cd zookeeper-3.4.14
[root@master zookeeper-3.4.14]# ll
total 1716
drwxr-xr-x 2 2002 2002 4096 Mar 6 2019 bin
-rw-rw-r-- 1 2002 2002 97426 Mar 6 2019 build.xml
drwxr-xr-x 2 2002 2002 88 Apr 25 08:41 conf
drwxr-xr-x 3 root root 60 Apr 25 08:46 datadir
drwxr-xr-x 2 2002 2002 4096 Mar 6 2019 dist-maven
-rw-rw-r-- 1 2002 2002 1709 Mar 6 2019 ivysettings.xml
-rw-rw-r-- 1 2002 2002 10742 Mar 6 2019 ivy.xml
drwxr-xr-x 4 2002 2002 4096 Mar 6 2019 lib
-rw-rw-r-- 1 2002 2002 11970 Mar 6 2019 LICENSE.txt
-rw-rw-r-- 1 2002 2002 3132 Mar 6 2019 NOTICE.txt
-rw-rw-r-- 1 2002 2002 31622 Mar 6 2019 pom.xml
-rw-rw-r-- 1 2002 2002 1765 Mar 6 2019 README.md
-rw-rw-r-- 1 2002 2002 1770 Mar 6 2019 README_packaging.txt
drwxr-xr-x 3 2002 2002 21 Mar 6 2019 src
-rw-rw-r-- 1 2002 2002 1515359 Mar 6 2019 zookeeper-3.4.14.jar
-rw-rw-r-- 1 2002 2002 836 Mar 6 2019 zookeeper-3.4.14.jar.asc
-rw-rw-r-- 1 2002 2002 33 Mar 6 2019 zookeeper-3.4.14.jar.md5
-rw-rw-r-- 1 2002 2002 41 Mar 6 2019 zookeeper-3.4.14.jar.sha1
drwxr-xr-x 3 2002 2002 45 Mar 6 2019 zookeeper-client
drwxr-xr-x 12 2002 2002 4096 Mar 6 2019 zookeeper-contrib
drwxr-xr-x 7 2002 2002 4096 Mar 6 2019 zookeeper-docs
drwxr-xr-x 3 2002 2002 33 Mar 6 2019 zookeeper-it
drwxr-xr-x 4 2002 2002 43 Mar 6 2019 zookeeper-jute
-rw-r–r-- 1 root root 32612 Apr 25 08:57 zookeeper.out
drwxr-xr-x 5 2002 2002 4096 Mar 6 2019 zookeeper-recipes
drwxr-xr-x 3 2002 2002 30 Mar 6 2019 zookeeper-server
使用复制命令生成配置文件zoo.cfg,代码如下:
[root@master zookeeper-3.4.14]# cd conf/
[root@master conf]$ ls
configuration.xsl log4j.properties zoo_sample.cfg
[root@master conf]$ cp zoo_sample.cfg zoo.cfg
[root@master conf]$ ls
configuration.xsl log4j.properties zoo.cfg zoo_sample.cfg
配置zoo.cfg文件
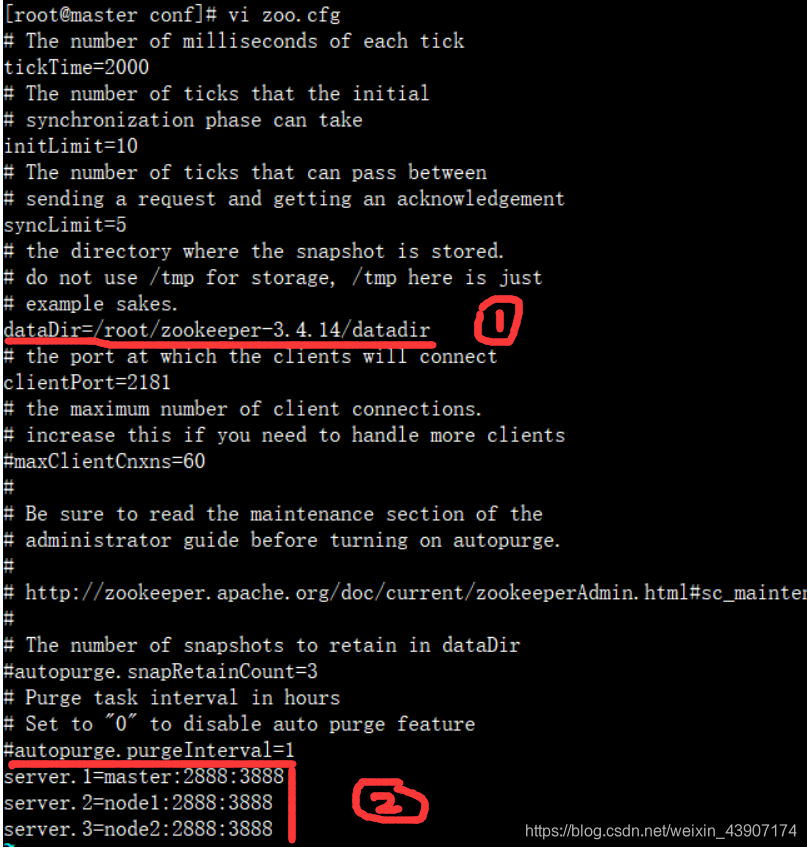
如上图第一处修改的是 dataDir的属性,就是存储数据的位置,后面我们会根据这个来创建相关的目录文件。
在文档结尾添加第二处的代码,然后保存退出;其中:server.1 中的“1”可以是其他的数字, 用来标识服务器,这个标识后面会写到下文中的myid文件里; 2888为Leader服务端口,3888为选举时所用的端口
创建datadir
[root@master ~]# mkdir /root/zookeeper-3.4.14/datadir
编辑myid内容,在里面添加1.
[root@master ~]# vi /root/zookeeper-3.4.14/datadir/myid
然后将zookeeper文件夹远程复制到其他两个节点。
[root@master ~]# scp -r zookeeper-3.4.10 node1:~/
[root@master ~]# scp -r zookeeper-3.4.10 node2:~/
分别在node1和node2上配置myid
[root@node1 ~]# vi /root/zookeeper-3.4.14/datadir/myid
[root@node2 ~]# vi /root/zookeeper-3.4.14/datadir/myid
在node1上将myid中的1改成2,在node2上将1该成3.
在master节点配置zookeeper的环境变量
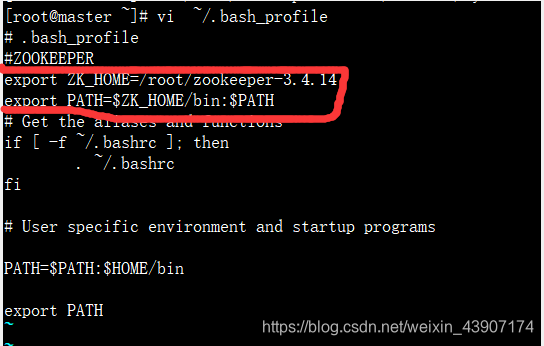
添加上图圈出的内容。
然后将配置好的内容发送到另外两台节点上。
[root@master ~]# scp ~/.bash_profile node1:~/
[root@master ~]# scp ~/.bash_profile node2:~/
在三台机子上分别使环境变量生效
source ~/.bash_profile
启动Zookeeper集群。分别登录master和node1、node2节点,进入zookeeper安装目录,启动服务
1.master节点
[root@master ~]# cd zookeeper-3.4.14
[root@master zookeeper-3.4.14]# bin/zkServer.sh start
2.node1节点
[root@node1 ~]# cd zookeeper-3.4.14/
[root@node1 zookeeper-3.4.14]# bin/zkServer.sh start
3.node2节点
[root@node2 ~]# cd zookeeper-3.4.14/
[root@node2 zookeeper-3.4.14]# bin/zkServer.sh start
在三个节点上分别运行bin/zkServer.sh status 命令查看状态,出现follower或leader表示ZK启动成功
bin/zkServer.sh status
[root@master ~]# cd zookeeper-3.4.14
[root@master zookeeper-3.4.14]# bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /root/zookeeper-3.4.14/bin/…/conf/zoo.cfg
Mode: follower[root@node1 ~]# cd zookeeper-3.4.14/
[root@node1 zookeeper-3.4.14]# bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /root/zookeeper-3.4.14/bin/…/conf/zoo.cfg
Mode: leader[root@node2 zookeeper-3.4.14]# bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /root/zookeeper-3.4.14/bin/…/conf/zoo.cfg
Mode: follower
测试ZooKeeper客户端命令是否可用
1.启动zookeeper客户端
[root@node2 ~]# cd zookeeper-3.4.14/
[root@node2 zookeeper-3.4.14]# bin/zkCli.sh -server master:2181[zk: master:2181(CONNECTED) 0] help
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BjIBI9E7-1587868990690)(C:\Users-_-\AppData\Roaming\Typora\typora-user-images\image-20200426103650659.png)]
per-3.4.14/
[root@node2 zookeeper-3.4.14]# bin/zkCli.sh -server master:2181
[zk: master:2181(CONNECTED) 0] help

至此zookeeper就搭建完毕了,不过要注意zookeeper的版本问题,欢迎大家留言讨论。
2020/4/26 大数据的zookeeper分布式安装的更多相关文章
- 大数据(7) - zookeeper的安装与使用
简介 ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件.它是一个为分布式应用提供一致性服务的软件,提 ...
- [大数据] hadoop全分布式安装
一.准备工作 在伪分布式的搭建基础上修改配置,搭建全分布式hadoop环境,伪分布式安装参照 hadoop伪分布式安装. 首先准备4台虚拟机,信息如下: 192.168.1.11 namenode1 ...
- [大数据] hadoop伪分布式安装
注意:节点主机的hostname不要带"_"等字符,否则会报错. 一.安装jdk rpm -i jdk-7u80-linux-x64.rpm 配置java环境变量: vi + /e ...
- 大数据系列之分布式数据库HBase-0.9.8安装及增删改查实践
若查看HBase-1.2.4版本内容及demo代码详见 大数据系列之分布式数据库HBase-1.2.4+Zookeeper 安装及增删改查实践 1. 环境准备: 1.需要在Hadoop启动正常情况下安 ...
- 搭建大数据hadoop完全分布式环境遇到的坑
搭建大数据hadoop完全分布式环境,遇到很多问题,这里记录一部分,以备以后查看. 1.在安装配置完hadoop以后,需要格式化namenode,输入指令:hadoop namenode -forma ...
- 【大数据之数据仓库】安装部署GreenPlum集群
本篇将向大家介绍如何快捷的安装部署GreenPlum测试集群,大家可以跟着我一块儿实践一把^_^ 1.主机资源 申请2台网易云主机,操作系统必须是RedHat或者CentOS,配置尽量高一点.如果是s ...
- 大数据系列之分布式数据库HBase-1.2.4+Zookeeper 安装及增删改查实践
之前介绍过关于HBase 0.9.8版本的部署及使用,本篇介绍下最新版本HBase1.2.4的部署及使用,有部分区别,详见如下: 1. 环境准备: 1.需要在Hadoop[hadoop-2.7.3] ...
- 【大数据】Zookeeper学习笔记
第1章 Zookeeper入门 1.1 概述 Zookeeper是一个开源的分布式的,为分布式应用提供协调服务的Apache项目. 1.2 特点 1.3 数据结构 1.4 应用场景 提供的服务包括:统 ...
- 大数据之 ZooKeeper原理及其在Hadoop和HBase中的应用
ZooKeeper是一个开源的分布式协调服务,由雅虎创建,是Google Chubby的开源实现.分布式应用程序可以基于ZooKeeper实现诸如数据发布/订阅.负载均衡.命名服务.分布式协调/通知. ...
随机推荐
- [codevs]1250斐波那契数列<矩阵乘法&快速幂>
题目描述 Description 定义:f0=f1=1, fn=fn-1+fn-2(n>=2).{fi}称为Fibonacci数列. 输入n,求fn mod q.其中1<=q<=30 ...
- springboot项目启动-自动创建数据表
很多时候,我们部署一个项目的时候,需要创建大量的数据表.例如mysql,一般的方法就是通过source命令完成数据表的移植,如:source /root/test.sql.如果我们需要一个项目启动后, ...
- JAVA实现图片验证
一.什么是图片验证码? 可以参考下面这张图: 我们在一些网站登陆的时候,经常需要填写以上图片的信息. 这种图片验证方式是我们最常见的形式,它可以有效的防范恶意攻击者采用恶意工具,来进行窃取用户的密码 ...
- I - 动物狂想曲 HDU - 6252(差分约束)
I - 动物狂想曲 HDU - 6252 雷格西桑和路易桑是好朋友,在同一家公司工作.他们总是一起乘地铁去上班.他们的路线上有N个地铁站,编号从1到N.1站是他们的家,N站是公司. 有一天,雷格西桑起 ...
- 浅谈Java接口(Interface)
浅谈Java接口 先不谈接口,不妨设想一个问题? 如果你写了个Animal类,有许多类继承了他,包括Hippo(河马), Dog, Wolf, Cat, Tiger这几个类.你把这几个类拿给别人用,但 ...
- Docket 容器引擎
Docker 是世界领先的软件容器平台.是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中, 然后发布到任何流行的Linux或Windows机器上,可以实现虚拟化(软件 ...
- python开发基于SMTP协议的邮件代发服务
写在这篇文章前照例给大家灌输点名词解释,理论知识,当然已经很熟悉的同学可以往下翻直接看干货 1. 什么是SMTP SMTP即简单传输协议(Simple Mail Transfer Protocol), ...
- Oracle 数据库创建导入
Oracle 数据库创建导入 由 Alma 创建, 最后一次修改 2018-06-04 14:37:50 在本章教程中,将教大家如何在Oracle 中创建导入数据库. 注意:本教程中的有些命令您可能并 ...
- Hadoop(学习·2)
Hadoop 操作步骤: 192.168.1.110-113 ...
- vim效率操作
vim效率操作 案例6:vim效率操作 6.1问题 本例要求掌握使用vim文本编辑器时能够提高操作效率的一些常用技巧和方法,完成 ...