爬虫&Selenium&ChromeDriver
一、Selenium
- selenium是什么
Selenium [1] 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。
在python爬虫可以简单的理解为:Selenium就是模仿人使用浏览器
如何下载或者是安装selenium
cmd进入win终端,输入命令
pip install selenium
二、ChromeDriver
ChromeDrive是什么
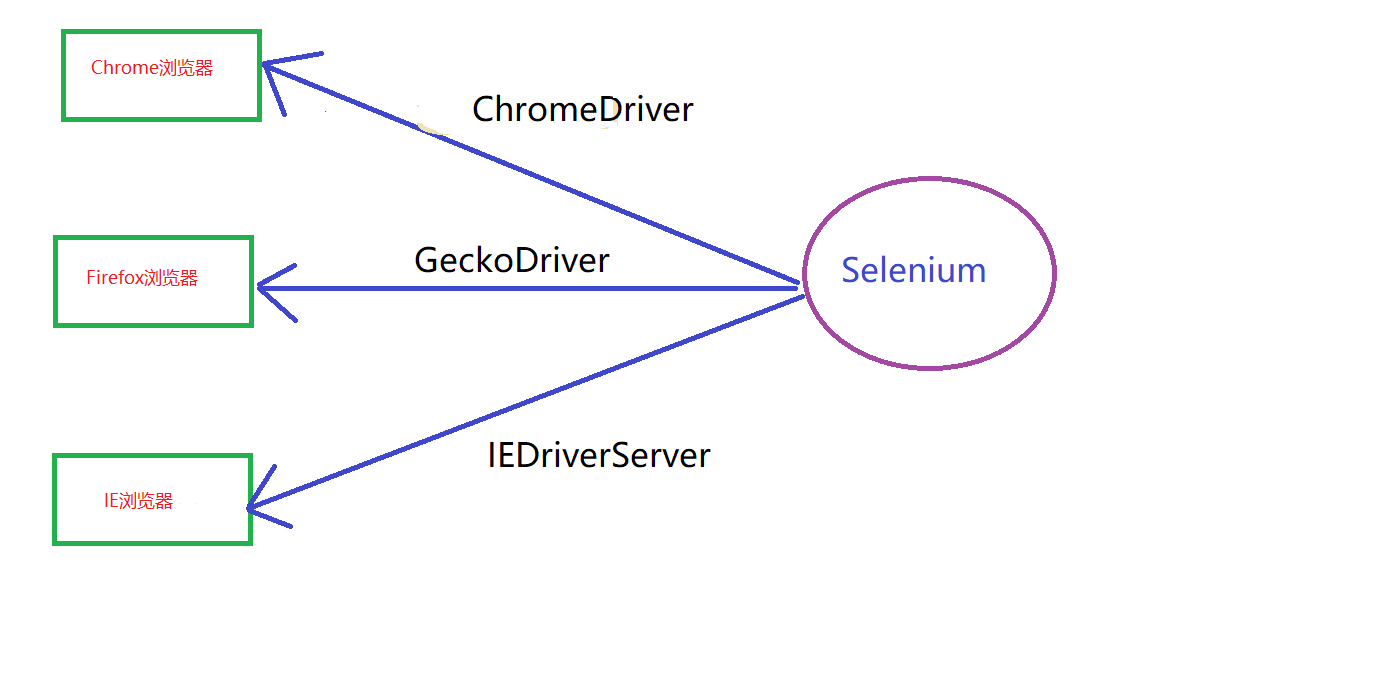
这个和JDBC类似,就是Selenium操作Chrome浏览器的驱动。同理Selenium操作Firefox浏览器就需要geckodriver,操作IE浏览器需要IEDriverServer驱动。
如何下载或者安装ChromeDriver
注意:ChromeDriver要和自己使用的chrome版本一致
注意:ChromeDriver要和自己使用的chrome版本一致
注意:ChromeDriver要和自己使用的chrome版本一致2.1 查询自己chrome的版本
地址栏输入:
chrome://version/

比如我的是:80.0.3987.149
2.2 下载ChromeDriver
地址栏:
https://npm.taobao.org/mirrors/chromedriver/
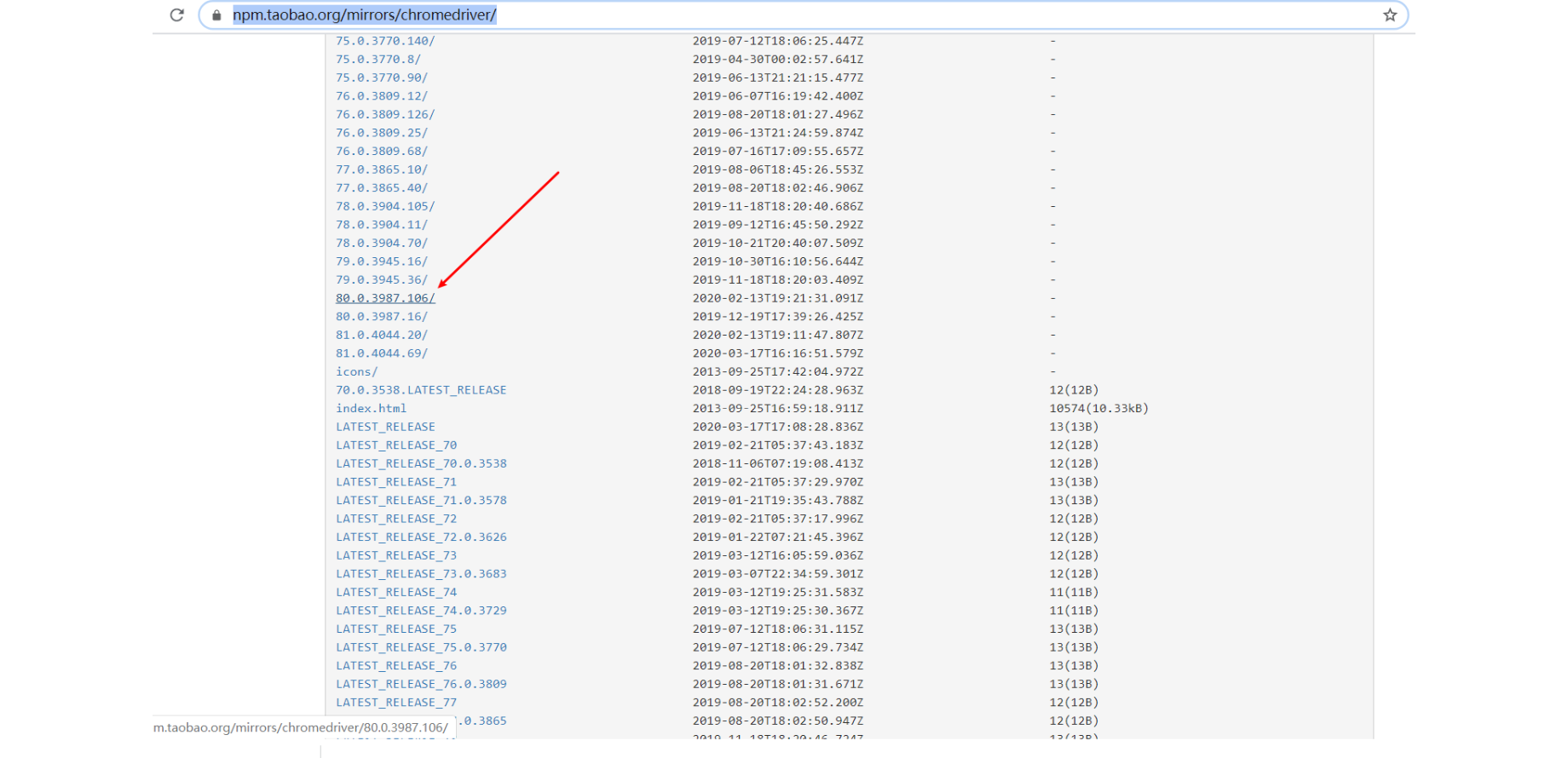
这里可能有人要问,不是最后一位不一样吗?
答:的却,但是我估计只要前三位相同应该都可以的。有兴趣的同学可以试一下哈
点击进去,下载对应的OS版本,比如我的是win电脑,我就下载第三个。
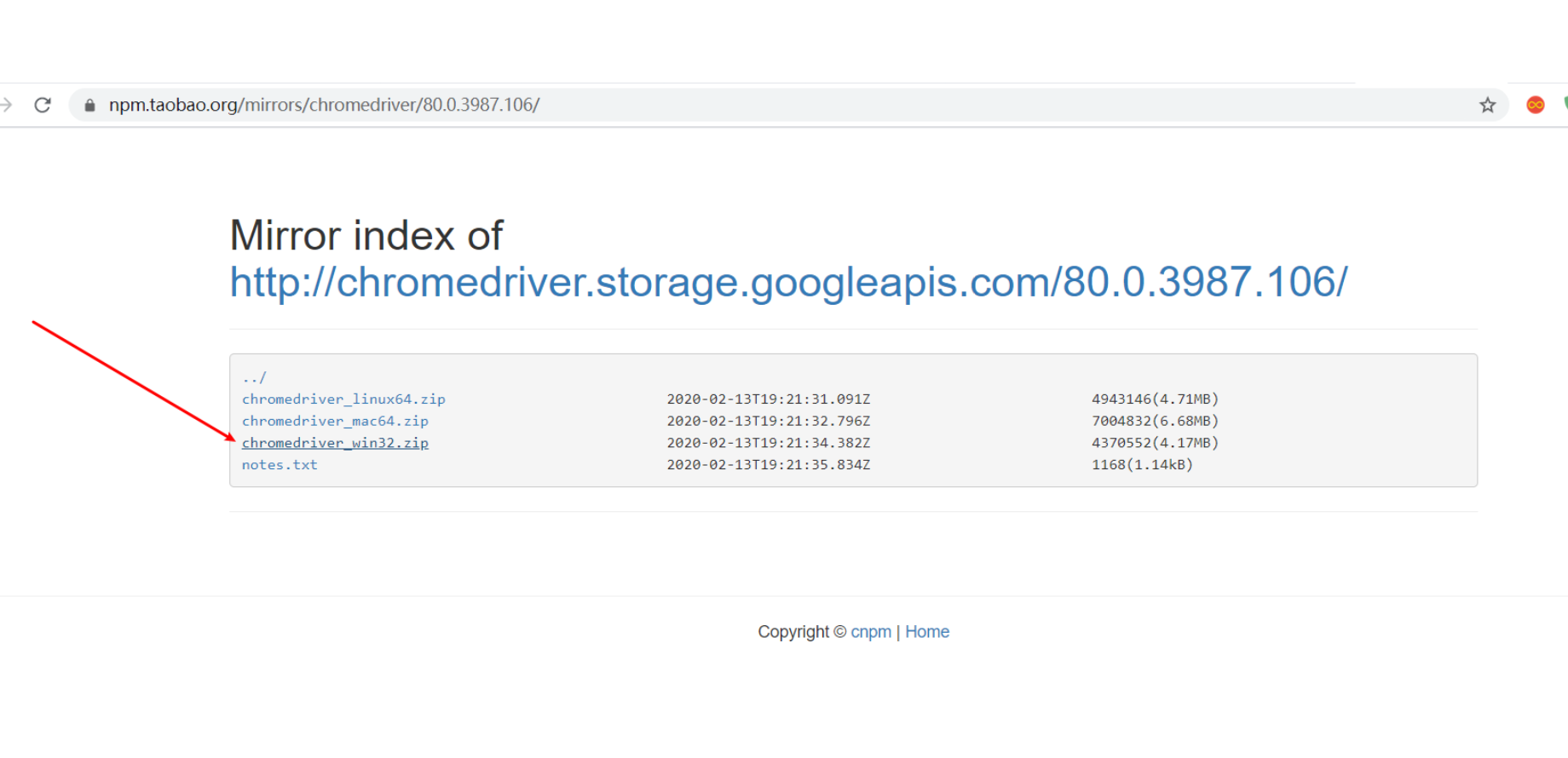
2.3 下载好之后,解压,把chromedriver.exe放到任意位置都可以。但是有要求:
- 路径上不能有中文
- 存放的路径不需要特殊权限
这样就可以了,接下来我们来测试一下。
三、测试
直接看代码
from selenium import webdriver #导入必要的库
#功能需求:模仿人类使用搜索框进行搜索
# 业务分析:在搜索框中输入“关键字”,点击“百度一下”或者是“回车” #chromedriver.exe的存放路径
driver_path=r"C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe" # 通过webdriver对象的Chrome方法【不同的浏览器对应不同的方法】,获取到chromedriver.exe
driver = webdriver.Chrome(executable_path=driver_path) # 访问百度
driver.get("http://www.baidu.com") # 根据页面的id值定位到搜索框的
input_tag = driver.find_element_by_id("kw") #假如我们搜索“java”
input_tag.send_keys("java") # 根据页面id获取到“百度一下”按钮
submit_btn = driver.find_element_by_id("su") #这个方法其实就是模仿人们点击“百度一下”按钮或者是“回车”
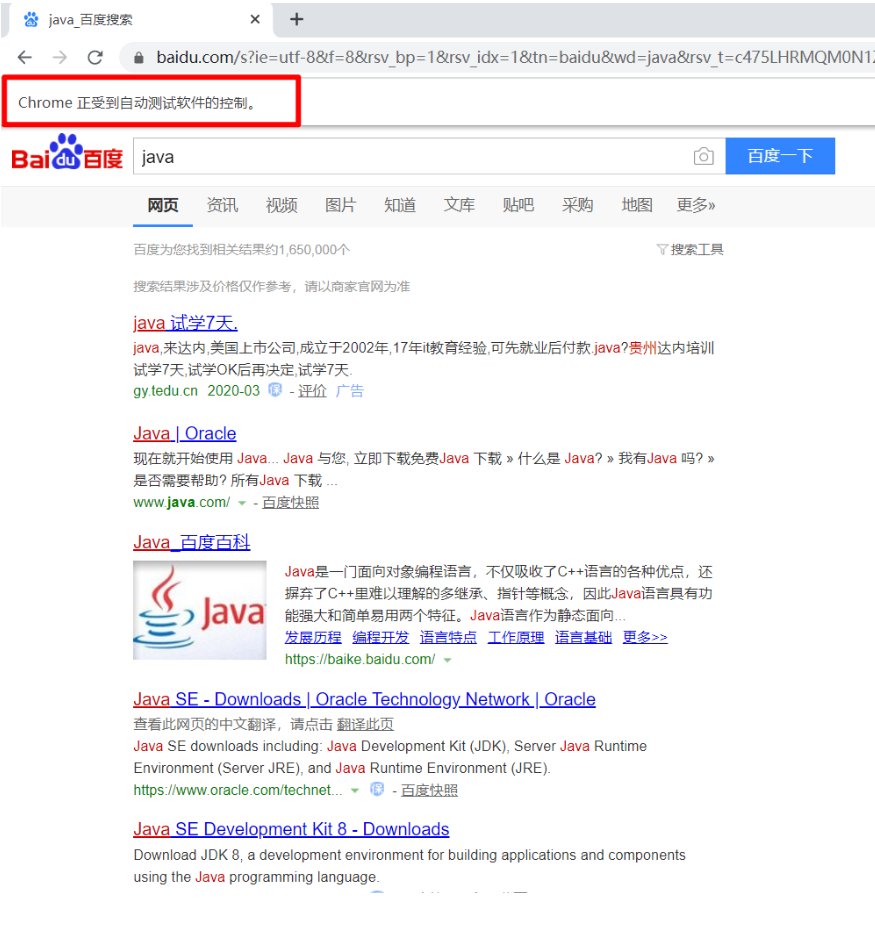
submit_btn.click()运行代码。它会自动打开浏览器并自动输入“java”,并回车。
看效果
四、为什么要用它——Selenium
答:因为有很多网站的数据都是异步请求(Ajax)加载数据的,我们直接爬取是获取不到数据的。因此我们使用selenium爬取返回来的页面是已经经过浏览器解析好的页面,我们再通过使用Xpath、bs4等,就可以爬取自己想要的数据了。
爬虫&Selenium&ChromeDriver的更多相关文章
- 爬虫 selenium+Xpath 爬取动态js页面元素内容
介绍 selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如 ...
- 爬虫----selenium模块
一.介绍 selenium最初是一个测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳 ...
- Python爬虫——selenium模块
selenium模块介绍 selenium最初是一个测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览 ...
- 爬虫---selenium动态网页数据抓取
动态网页数据抓取 什么是AJAX: AJAX(Asynchronouse JavaScript And XML)异步JavaScript和XML.过在后台与服务器进行少量数据交换,Ajax 可以使网页 ...
- selenium + ChromeDriver 实战系列之启信宝(一)
之前写了一篇selenium + ChromeDriver的一些入门的知识,这篇博客里面找了启信宝这个网站,简单的进行了一个实战练习.本篇博客的结构如下: 首先会给出一些使用seleniu ...
- Python爬虫-selenium的使用(2)
使用selenium打开chrome浏览器百度进行搜索 12345678910111213141516171819202122232425 from selenium import webdriver ...
- [Python爬虫] Selenium实现自动登录163邮箱和Locating Elements介绍
前三篇文章介绍了安装过程和通过Selenium实现访问Firefox浏览器并自动搜索"Eastmount"关键字及截图的功能.而这篇文章主要简单介绍如何实现自动登录163邮箱,同时 ...
- [Python爬虫] Selenium+Phantomjs动态获取CSDN下载资源信息和评论
前面几篇文章介绍了Selenium.PhantomJS的基础知识及安装过程,这篇文章是一篇应用.通过Selenium调用Phantomjs获取CSDN下载资源的信息,最重要的是动态获取资源的评论,它是 ...
- [Python爬虫] Selenium获取百度百科旅游景点的InfoBox消息盒
前面我讲述过如何通过BeautifulSoup获取维基百科的消息盒,同样可以通过Spider获取网站内容,最近学习了Selenium+Phantomjs后,准备利用它们获取百度百科的旅游景点消息盒(I ...
随机推荐
- Welcome to Giyber Blog - LC的博客
"You can be the best! " 一切才刚开始 "不知道行不行,试试吧."抱着这样的理由,一个小白的成长记录,由此开始. 在 Mr.锤 的&quo ...
- 为什么 generator 忽略第一次 next 调用的参数值呢?
首先要理解几个基本概念. 执行生成器不会执行生成器函数体的代码,只是获得一个遍历器 一旦调用 next,函数体就开始执行,一旦遇到 yield 就返回执行结果,暂停执行 第二次 next 的参数会作为 ...
- resourcequota分析(一)-evaluator-v1.5.2
什么是evaluator 大家都知道,Kubernetes中使用resourcequota对配额进行管理.配额的管理涉及两个步骤:1.计算请求所需要的资源:2.比较并更新配额.所以解读resource ...
- Typora+PicGo+Gitee笔记方案
前言:需要学习的知识太多,从一开始就在寻找一款能让我完全满意的编辑器,然而一直都没有令我满意的.在前两天Typora新版本更新后,总算是拥有了一套我认为很完美的笔记方案:使用Typora编写markd ...
- jdbc里一个最靠谱的连接demo
最靠谱的jdbc连接例子 包括增删改,查一条数据,查所有数据. Bean.java public class Bean { private String id; private String numb ...
- Nginx之常用基本配置(三)
前面我们聊了下了Nginx作为WEB服务器对客户端请求相关配置,文件操作优化.Nginx访问控制.basic验证,.状态模块状态页.gzip压缩配置:回顾请参考https://www.cnblogs. ...
- 基于Noisy Channel Model和Viterbi算法的词性标注问题
给定一个英文语料库,里面有很多句子,已经做好了分词,/前面的是词,后面的表示该词的词性并且每句话由句号分隔,如下图所示 对于一个句子S,句子中每个词语\(w_i\)标注了对应的词性\(z_i\).现在 ...
- 微信小程序最新授权方法,getUserInfo
20180511微信小程序正式关闭原先getUserInfo的逻辑 不再允许自动弹出授权框. 方法一: index.wxml(准备一个用于给用户授权的页面,我这里直接用了一个全屏按钮) <vie ...
- 前端复习笔记--1.html标签复习速查
概览 文档章节 <body> <header> <nav> 导航 <aside> 表示和主要内容不相关的区域 <article> 表示一个独 ...
- 【Oracle】RAC的多实例数据迁移至单机的多实例。
思路:一般的思路可以通过RMAN进行数据的恢复.由于数据库可以停机,因此,这次试用数据泵(expdp,impdp)进行数据 的导入导出. 1.源数据库导出 通过编写导出shell脚本导出数据,如下: ...