hashMap探析
本篇文章包括:
- 数据结构
- 各个参数
- 为什么数组的长度是2的整数次方
- 为什么要将装载因子定义为0.75
- 为什么链表转红黑树的阈值为8
- hash碰撞
- put方法
- resize方法
- jdk7中数组扩容产生环的问题。
1.底层数据结构?
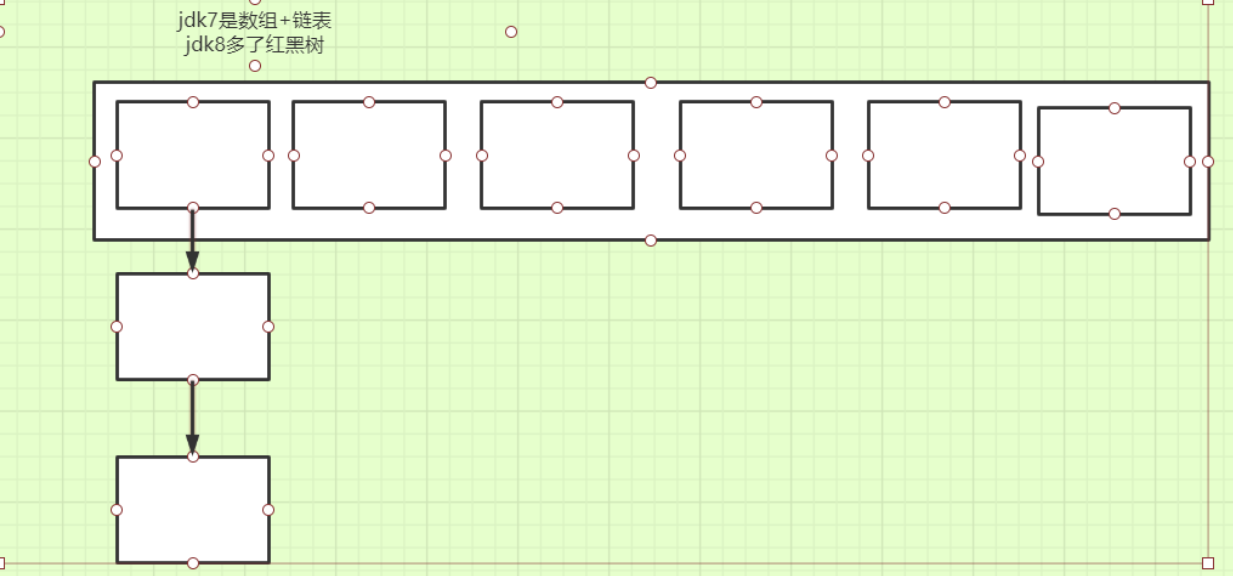
- 红黑树
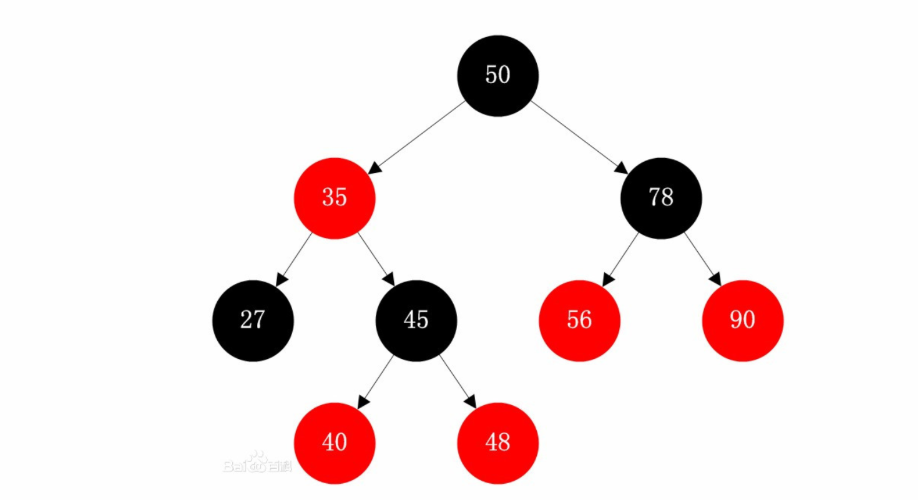
是一种接近二叉平衡树的数据结构,有5个性质:
性质1:每个节点要么是黑色,要么是红色。
性质2:根节点是黑色。
性质3:每个叶子节点(NIL||null)是黑色(为空的叶子结点)。
性质4:每个红色结点的两个子结点一定都是黑色。
性质5:任意一结点到每个叶子结点的路径都包含数量相同的黑结点。(保证了红黑树的平衡性)
红黑树的查询效率高,时间复杂度为O(logn),但是添加节点的代价高,因为本身需要保证平衡,方法包括左旋、右旋以及变色。
- 各个参数
/**
默认的初始容量
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**.
最大容量
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
装载因子
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
链表转红黑树阈值
*/
static final int TREEIFY_THRESHOLD = 8;
/**
红黑树转链表阈值
*/
static final int UNTREEIFY_THRESHOLD = 6;
/**
为避免调整大小和调整树型阈值之间的冲突,可以重新调整存储箱的最小表容量(如果存储箱中的节点太多,则重新调整表 的大小)应至少为4个树型阈值。
为了避免进行扩容、树形化选择的冲突,规定若桶内的节点的数量大于64则进行扩容,否则进行树形化
*/
static final int MIN_TREEIFY_CAPACITY = 64;
初始容量为什么是16或者说2的次方数
我们先看看2的次方数:
| 十进制数 | 二进制数 | |
|---|---|---|
| 2 | 0010 | |
| 4 | 0100 | |
| 8 | 1000 | |
| 16 | 0001 0000 |
发现2的整数次方的数的二进制刚好都是最高位为1,那又有什么用呢?这就要说说hashMap的put方法了额。
hashMap通过 (n - 1) & hash来计算键值对存放的数组下标,可以自己尝试计算一下发现如果n是2的整数次方数的话那么就和n%hash的值一样,也就是说是为了保证计算后的结果(作为下标)不超出数组长度减一,从而找到对应的存储位置。
public V put(K key, V value) {
//先计算key的hash值,然后调用putAal
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {
Node<K,V>[] tab;
Node<K,V> p;
int n, i;
//如果数组长度为0,就进行初始化容量默认为16
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//如果当前数组的这个位置没有元素就直接赋值
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
//否则有以下几种添加节点
Node<K,V> e; K k;
//当前的节点的hash值、key相等就进行覆盖
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//如果当前是为红黑树结构就加入到红黑树中
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//当前位置已经存在元素,并且是链表结构就加入节点
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//链表中有key相同的节点
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//将旧值替换为新值
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
//元素个数加一,并且判断是否需要扩容,若大于装载因子*数组长度就进行扩容
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
//hash值计算方法
static final int hash(Object key) {
int h;
//可以看出允许key为null,hashCode是一个本地方法
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
- hash碰撞:如果计算出来的最终的值(也就是要放到的那个数组下标的位置)对应的位置有元素就产生hash碰撞,解决办法有开放地址法,在哈希法,链地址(拉链)法以及通过建立公共的溢出区来解决。hashMap是使用的链地址法。通过尾插法插入到当前链表的尾部(jdk7采用的头插法会导致扩容的时候产生链表环的问题)。
装载因子
- 默认为0.75,为了在时间和空间上进行折中。如果小了就有可能造成空间的浪费,大了又会产生更多的hash碰撞,造成执行时间增加。
链表转红黑树,以及红黑树转链表
- 当链表的长度达到8的时候会转为红黑树结构,因为链表的查询效率低,如果链表过长就会造成查询时间过长,而红黑树结构的查询效率较高,但是进行增加元素的时候效率较低。当元素的个数为6的时候红黑树结构又会转为链表结构。
- 为什么会将阈值定为8?jdk官方解释:
Because TreeNodes are about twice the size of regular nodes, we
* use them only when bins contain enough nodes to warrant use
* (see TREEIFY_THRESHOLD). And when they become too small (due to
* removal or resizing) they are converted back to plain bins. In
* usages with well-distributed user hashCodes, tree bins are
* rarely used. Ideally, under random hashCodes, the frequency of
* nodes in bins follows a Poisson distribution
* (http://en.wikipedia.org/wiki/Poisson_distribution) with a
* parameter of about 0.5 on average for the default resizing
* threshold of 0.75, although with a large variance because of
* resizing granularity. Ignoring variance, the expected
* occurrences of list size k are (exp(-0.5) * pow(0.5, k) /
* factorial(k)). The first values are:
*
* 0: 0.60653066
* 1: 0.30326533
* 2: 0.07581633
* 3: 0.01263606
* 4: 0.00157952
* 5: 0.00015795
* 6: 0.00001316
* 7: 0.00000094
* 8: 0.00000006
* more: less than 1 in ten million
总之就是在8的时候再产生插入的操作的概率非常小,因为红黑树的增加节点的效率是很低的,不该有过多的增加节点的操作。
看看resize方法
final Node<K,V>[] resize() {
//旧数组
Node<K,V>[] oldTab = table;
//旧数组容量
int oldCap = (oldTab == null) ? 0 : oldTab.length;
//旧数组的扩容阈值
int oldThr = threshold;
//新数组的大小,扩容阈值
int newCap, newThr = 0;
//当旧数组长度不为0
if (oldCap > 0) {
//旧数组的长度已经为最大了就不进行扩容,直接将阈值赋值为最大
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
//对数组的容量和阈值扩大为原来的两倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
//当数组大小为0的时候对数组进行初始化,后面会对threshold进行处理,因为阈值是装载因子与数组的长度的乘积
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else {
// zero initial threshold signifies using defaults
//使用无参构造进行new数组,第一次put的时候会对数组进行默认的初始化
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
//对数组的阈值赋值
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
//以下是将旧数组的元素转移到新的数组中去
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
//如果当前下标有元素,有以下几种情况
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
///1.如果当前元素没有后继元素,则直接进行hash计算下标将节点放在新数组对应的下标处
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
//如果是红黑树结构,则拆分红黑树,并且有可能转为链表结构
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
//这里说明是链表结构,则采用尾插法进行元素的转移
Node<K,V> loHead = null, loTail = null;//低位
Node<K,V> hiHead = null, hiTail = null;//高位
Node<K,V> next;
do {
next = e.next;
//如果当前元素的hash值与旧数组进行与运算得到0则用低位记录
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
//否则用高位记录
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
//低位的保持不变
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
//高位的进行转移,转移到当前数组的下标加上旧数组长度的位置
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
- 为什么jdk7中扩容会产生环的问题
看resize方法:
//扩容
void resize(int newCapacity) {
Entry[] oldTable = table;//老的数据
int oldCapacity = oldTable.length;//获取老的容量值
if (oldCapacity == MAXIMUM_CAPACITY) {//老的容量值已经到了最大容量值
threshold = Integer.MAX_VALUE;//修改扩容阀值
return;
}
//新的结数组
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));//将老的表中的数据拷贝到新的结构中
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);//修改阀值
}
transfer方法:
//将老的表中的数据拷贝到新的数组中
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;//容量
for (Entry<K,V> e : table) { //遍历所有桶
while(null != e) { //遍历桶中所有元素(是一个链表)
Entry<K,V> next = e.next; //1
if (rehash) {//如果是重新Hash,则需要重新计算hash值
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);//定位Hash桶
e.next = newTable[i];//2
newTable[i] = e;//newTable[i]的值总是最新插入的值
e = next;//继续下一个元素
}
}
}
- 分析扩容的过程
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
//if (rehash) {
// e.hash = null == e.key ? 0 : hash(e.key);
// }
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
- 两个线程同时进行扩容(假设扩容后的元素在数组中的下标还是原来的下标),假设线程1先进行
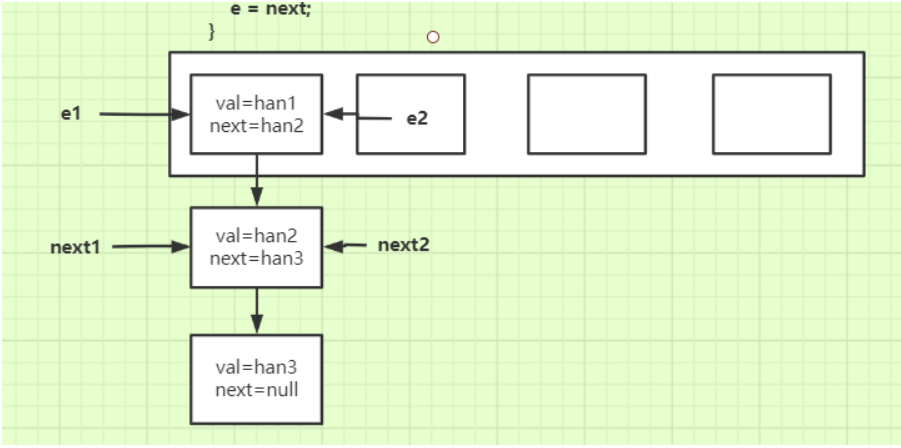
- 线程1扩容完毕后链表的顺序已经倒置:
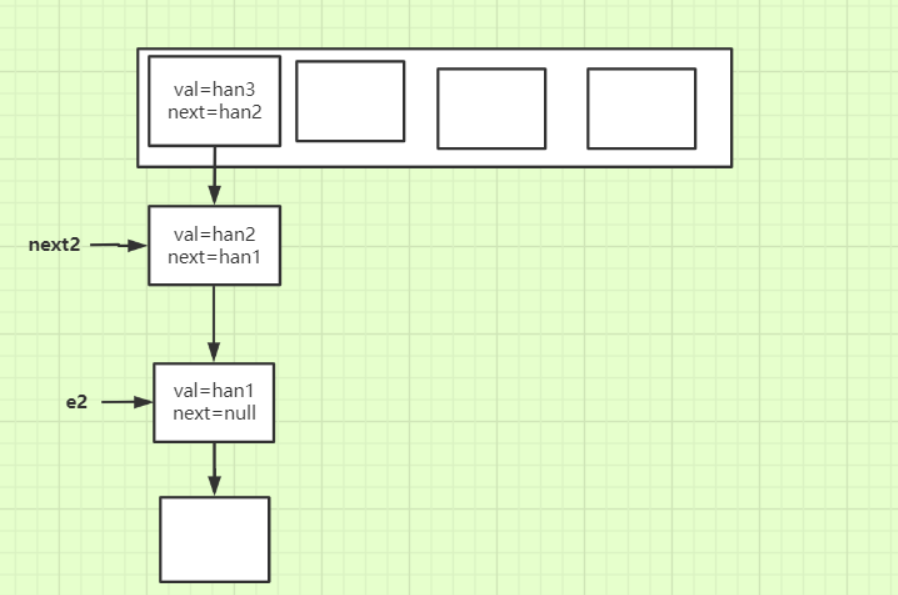
- 线程2进行扩容的时候就形成了环形链表:
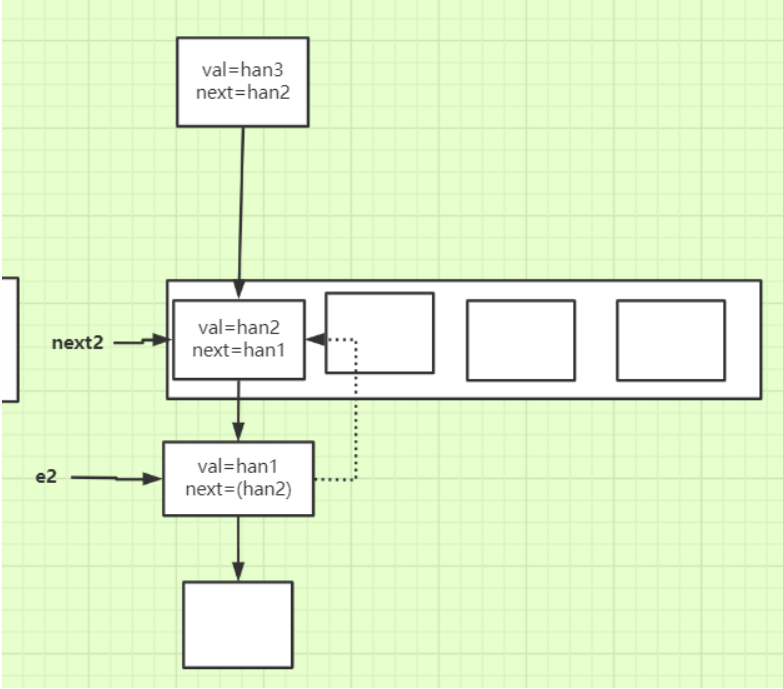
由于线程2中存放的han1的next还指向着han2,所以导致环形链表的产生。
jdk8中采用尾插法避免了这个问题,通过采用高位指针和低位指针来进行链表元素的转移,巧妙的避开了环形链表的问题。
hashMap探析的更多相关文章
- 开源中文分词工具探析(七):LTP
LTP是哈工大开源的一套中文语言处理系统,涵盖了基本功能:分词.词性标注.命名实体识别.依存句法分析.语义角色标注.语义依存分析等. [开源中文分词工具探析]系列: 开源中文分词工具探析(一):ICT ...
- 中文分词工具探析(二):Jieba
1. 前言 Jieba是由fxsjy大神开源的一款中文分词工具,一款属于工业界的分词工具--模型易用简单.代码清晰可读,推荐有志学习NLP或Python的读一下源码.与采用分词模型Bigram + H ...
- 中文分词工具探析(一):ICTCLAS (NLPIR)
1. 前言 ICTCLAS是张华平在2000年推出的中文分词系统,于2009年更名为NLPIR.ICTCLAS是中文分词界元老级工具了,作者开放出了free版本的源代码(1.0整理版本在此). 作者在 ...
- 深入探析koa之中间件流程控制篇
koa被认为是第二代web后端开发框架,相比于前代express而言,其最大的特色无疑就是解决了回调金字塔的问题,让异步的写法更加的简洁.在使用koa的过程中,其实一直比较好奇koa内部的实现机理.最 ...
- Emmet 语法探析
Emmet 语法探析 Emmet(Zen Coding)是一个能大幅度提高前端开发效率的一个工具. 大多数编辑器都支持Snippet,即存储和重用一些代码块.但是前提是:你必须先定义 这些代码块. E ...
- 开源中文分词工具探析(三):Ansj
Ansj是由孙健(ansjsun)开源的一个中文分词器,为ICTLAS的Java版本,也采用了Bigram + HMM分词模型(可参考我之前写的文章):在Bigram分词的基础上,识别未登录词,以提高 ...
- 开源中文分词工具探析(四):THULAC
THULAC是一款相当不错的中文分词工具,准确率高.分词速度蛮快的:并且在工程上做了很多优化,比如:用DAT存储训练特征(压缩训练模型),加入了标点符号的特征(提高分词准确率)等. 1. 前言 THU ...
- 开源中文分词工具探析(五):FNLP
FNLP是由Fudan NLP实验室的邱锡鹏老师开源的一套Java写就的中文NLP工具包,提供诸如分词.词性标注.文本分类.依存句法分析等功能. [开源中文分词工具探析]系列: 中文分词工具探析(一) ...
- Erlang调度器细节探析
Erlang调度器细节探析 Erlang的很多基础特性使得它成为一个软实时的平台.其中包括垃圾回收机制,详细内容可以参见我的上一篇文章Erlang Garbage Collection Details ...
随机推荐
- Flutter 打包Android APK 笔记与事项
获取一个KEY 首先要获取 你的 打包应用的一个 key ,这一步其实和 在AndroidStudio 上打包 APK 一样,都是要注册一个本地的 key,key 其实也就是 jks文件啦. 如果已经 ...
- python post protobuf
本文主要讲述如何使用Python发送protobuf数据. 安装protobuf .tar.gz cd protobuf- ./configure make make install 安装成功. // ...
- Java——字节和字符的区别
字节 1.bit=1 二进制数据0或1 2.byte=8bit 1个字节等于8位 存储空间的基本计量单位 3.一个英文字母=1byte=8bit 1个英文字母是1个字节,也就是8位 4.一个汉字= ...
- Directory类和DirectoryInfo类
1.Directory类 Directory类公开了用于创建.移动.枚举.删除目录和子目录的静态方法 2.DirectoryInfo类 DirectoryInfo和Directory类的区别可以参看F ...
- Java网络小结
1,定位 IP对机器的定位 端口对软件的定位(65535) URL对软件上每一份资源的定位 2,TCP和UDP TCP 安全,性能低 ①ServerSocket②Socket UDP不安全,性能高 ① ...
- [uva_la7146 Defeat the Enemy(2014 shanghai onsite)]贪心
题意:我方n个军队和敌方m个军队进行一对一的对战,每个军队都有一个攻击力和防御力,只要攻击力不小于对方就可以将对方摧毁.问在能完全摧毁敌方的基础上最多能有多少军队不被摧毁. 思路:按防御力从大到小考虑 ...
- js代码中引入其他js文件
/***引入 js 文件 @example: import('js/aui.picker.js') @example: import(['js/aui.picker.js', 'css/aui.pic ...
- 1020 Tree Traversals (25分)思路分析 + 满分代码
题目 Suppose that all the keys in a binary tree are distinct positive integers. Given the postorder an ...
- Python内置函数列表
函数 用途 abs() 返回数字绝对值 all() 判断给定的可迭代参数 iterable 中的所有元素是否都为 TRUE,如果是返回 True,否则返回 False any() 判断给定的可迭代参数 ...
- 网站设计时应考虑哪些因素,以保证网站是对SEO友好
根据用户的搜索习惯做好栏目的设计 根据用户的习惯做好三大标签的设计 做好首页栏目的展现布局 对于用户来说的重点 展示栏目的合理化 多样化 细节化 代码的静态化 域名 服务器购买稳定 合格 网站内容的 ...