给jdk写注释系列之jdk1.6容器(10)-Stack&Vector源码解析
public
class Stack<E> extends Vector<E> {
我们发现Stack继承了Vector,Vector又是什么东东呢,看一下。
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
发现没有,Vector是List的一个实现类,其实Vector也是一个基于数组实现的List容器,其功能及实现代码和ArrayList基本上是一样的。那么不一样的是什么地方的,一个是数组扩容的时候,Vector是*2,ArrayList是*1.5+1;另一个就是Vector是线程安全的,而ArrayList不是,而Vector线程安全的做法是在每个方法上面加了一个synchronized关键字来保证的。但是这里说一句,Vector已经不官方的(大家公认的)不被推荐使用了,正式因为其实现线程安全方式是锁定整个方法,导致的是效率不高,那么有没有更好的提到方案呢,其实也不能说有,但是还真就有那么一个,Collections.synchronizedList(),这不是我们今天的重点不做深入探讨,回到Stack的实现上。
// 底层使用数组存储数据
protected Object[] elementData;
// 元素个数
protected int elementCount ;
// 自定义容器扩容递增大小
protected int capacityIncrement ; public Vector( int initialCapacity, int capacityIncrement) {
super();
// 越界检查
if (initialCapacity < 0)
throw new IllegalArgumentException( "Illegal Capacity: " +
initialCapacity);
// 初始化数组
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
} // 使用synchronized关键字锁定方法,保证同一时间内只有一个线程可以操纵该方法
public synchronized boolean add(E e) {
modCount++;
// 扩容检查
ensureCapacityHelper( elementCount + 1);
elementData[elementCount ++] = e;
return true;
} private void ensureCapacityHelper(int minCapacity) {
// 当前元素数量
int oldCapacity = elementData .length;
// 是否需要扩容
if (minCapacity > oldCapacity) {
Object[] oldData = elementData;
// 如果自定义了容器扩容递增大小,则按照capacityIncrement进行扩容,否则按两倍进行扩容(*2)
int newCapacity = (capacityIncrement > 0) ?
(oldCapacity + capacityIncrement) : (oldCapacity * 2);
if (newCapacity < minCapacity) {
newCapacity = minCapacity;
}
// 数组copy
elementData = Arrays.copyOf( elementData, newCapacity);
}
}
/**
* 获取栈顶的对象,但是不删除
*/
public synchronized E peek() {
// 当前容器元素个数
int len = size(); // 如果没有元素,则直接抛出异常
if (len == 0)
throw new EmptyStackException();
// 调用elementAt方法取出数组最后一个元素(最后一个元素在栈顶)
return elementAt(len - 1);
} /**
* 根据index索引取出该位置的元素,这个方法在Vector中
*/
public synchronized E elementAt(int index) {
// 越界检查
if (index >= elementCount ) {
throw new ArrayIndexOutOfBoundsException(index + " >= " + elementCount);
} // 直接通过数组下标获取元素
return (E)elementData [index];
}
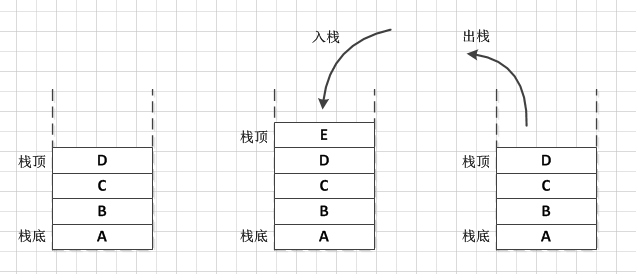
4.pop()——弹栈(出栈),获取栈顶的对象,并将该对象从容器中删除
/**
* 弹栈,获取并删除栈顶的对象
*/
public synchronized E pop() {
// 记录栈顶的对象
E obj;
// 当前容器元素个数
int len = size(); // 通过peek()方法获取栈顶对象
obj = peek();
// 调用removeElement方法删除栈顶对象
removeElementAt(len - 1); // 返回栈顶对象
return obj;
} /**
* 根据index索引删除元素
*/
public synchronized void removeElementAt(int index) {
modCount++;
// 越界检查
if (index >= elementCount ) {
throw new ArrayIndexOutOfBoundsException(index + " >= " +
elementCount);
}
else if (index < 0) {
throw new ArrayIndexOutOfBoundsException(index);
}
// 计算数组元素要移动的个数
int j = elementCount - index - 1;
if (j > 0) {
// 进行数组移动,中间删除了一个,所以将后面的元素往前移动(这里直接移动将index位置元素覆盖掉,就相当于删除了)
System. arraycopy(elementData, index + 1, elementData, index, j);
}
// 容器元素个数减1
elementCount--;
// 将容器最后一个元素置空(因为删除了一个元素,然后index后面的元素都向前移动了,所以最后一个就没用了 )
elementData[elementCount ] = null; /* to let gc do its work */
}
5.push(E item)——压栈(入栈),将对象添加进容器并返回
/**
* 将对象添加进容器并返回
*/
public E push(E item) {
// 调用addElement将元素添加进容器
addElement(item);
// 返回该元素
return item;
} /**
* 将元素添加进容器,这个方法在Vector中
*/
public synchronized void addElement(E obj) {
modCount++;
// 扩容检查
ensureCapacityHelper( elementCount + 1);
// 将对象放入到数组中,元素个数+1
elementData[elementCount ++] = obj;
}
6.search(Object o)——返回对象在容器中的位置,栈顶为1
/**
* 返回对象在容器中的位置,栈顶为1
*/
public synchronized int search(Object o) {
// 从数组中查找元素,从最后一次出现
int i = lastIndexOf(o); // 因为栈顶算1,所以要用size()-i计算
if (i >= 0) {
return size() - i;
}
return -1;
}
7.empty()——容器是否为空
/**
* 检查容器是否为空
*/
public boolean empty() {
return size() == 0;
}
import java.util.LinkedList;
public class LinkedStack<E> {
private LinkedList<E> linked ;
public LinkedStack() {
this.linked = new LinkedList<E>();
}
public E push(E item) {
this.linked .addFirst(item);
return item;
}
public E pop() {
if (this.linked.isEmpty()) {
return null;
}
return this.linked.removeFirst();
}
public E peek() {
if (this.linked.isEmpty()) {
return null;
}
return this.linked.getFirst();
}
public int search(E item) {
int i = this.linked.indexOf(item);
return i + 1;
}
public boolean empty() {
return this.linked.isEmpty();
}
}
给jdk写注释系列之jdk1.6容器(10)-Stack&Vector源码解析的更多相关文章
- 给jdk写注释系列之jdk1.6容器(13)-总结篇之Java集合与数据结构
是的,这篇blogs是一个总结篇,最开始的时候我提到过,对于java容器或集合的学习也可以看做是对数据结构的学习与应用.在前面我们分析了很多的java容器,也接触了好多种常用的数据结构,今天 ...
- 给jdk写注释系列之jdk1.6容器(12)-PriorityQueue源码解析
PriorityQueue是一种什么样的容器呢?看过前面的几个jdk容器分析的话,看到Queue这个单词你一定会,哦~这是一种队列.是的,PriorityQueue是一种队列,但是它又是一种什么样的队 ...
- 给jdk写注释系列之jdk1.6容器(11)-Queue之ArrayDeque源码解析
前面讲了Stack是一种先进后出的数据结构:栈,那么对应的Queue是一种先进先出(First In First Out)的数据结构:队列. 对比一下Stack,Queue是一种先进先出的容 ...
- 给jdk写注释系列之jdk1.6容器(9)-Strategy设计模式之Comparable&Comparator接口
前面我们说TreeMap和TreeSet都是有顺序的集合,而顺序的维持是要靠一个比较器Comparator或者map的key实现Comparable接口. 既然说到排序,首先我们不用去关心什 ...
- 给jdk写注释系列之jdk1.6容器(8)-TreeSet&NavigableMap&NavigableSet源码解析
TreeSet是一个有序的Set集合. 既然是有序,那么它是靠什么来维持顺序的呢,回忆一下TreeMap中是怎么比较两个key大小的,是通过一个比较器Comparator对不对,不过遗憾的是,今天仍然 ...
- 给jdk写注释系列之jdk1.6容器(7)-TreeMap源码解析
TreeMap是基于红黑树结构实现的一种Map,要分析TreeMap的实现首先就要对红黑树有所了解. 要了解什么是红黑树,就要了解它的存在主要是为了解决什么问题,对比其他数据结构比如数组,链 ...
- 给jdk写注释系列之jdk1.6容器(6)-HashSet源码解析&Map迭代器
今天的主角是HashSet,Set是什么东东,当然也是一种java容器了. 现在再看到Hash心底里有没有会心一笑呢,这里不再赘述hash的概念原理等一大堆东西了(不懂得需要先回去看下Has ...
- 给jdk写注释系列之jdk1.6容器(5)-LinkedHashMap源码解析
前面分析了HashMap的实现,我们知道其底层数据存储是一个hash表(数组+单向链表).接下来我们看一下另一个LinkedHashMap,它是HashMap的一个子类,他在HashMap的基础上维持 ...
- 给jdk写注释系列之jdk1.6容器(4)-HashMap源码解析
前面了解了jdk容器中的两种List,回忆一下怎么从list中取值(也就是做查询),是通过index索引位置对不对,由于存入list的元素时安装插入顺序存储的,所以index索引也就是插入的次序. M ...
随机推荐
- 为了以后愉快的玩耍,Virtualbox安装Ubuntu
为了以后愉快的玩耍,Virtualbox安装Ubuntu 每次安装虚拟机都是总要折腾一下,毕竟不是特别熟悉,几个小细节总要google半天,为了以后能愉快的玩耍.把这些问题都记录下来,免得再折腾. 此 ...
- cocos2d-x 纹理深入研究 第二部分
转自:http://blog.csdn.net/qq51931373/article/details/9152227 1.纹理控制. 看此代码: CCSprite *pSprite = CCSprit ...
- log4j2使用总结
一.Log4j有三个主要的组件:Loggers,Appenders和Layouts,这里可简单理解为日志级别,日志要输出的地方和日志格式 1. Logger Logger的日志级别有6级,分别是TRA ...
- HDU 1213 How Many Tables (并查集)
How Many Tables 题目链接: http://acm.hust.edu.cn/vjudge/contest/123393#problem/C Description Today is Ig ...
- C++中#include包含头文件带 .h 和不带 .h 的区别
C++中#include包含头文件带 .h 和不带 .h 的区别? 如 #include <iostream> 和 #include <iostream.h> 包含的东西有哪些 ...
- HDU 1255 覆盖的面积 (线段树+扫描线+离散化)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1255 题意很清楚,就是让你求矩阵之间叠加层数大于1的矩形块的面积和. 因为n只有1000,所以我离散化 ...
- CodeForces 705B Spider Man (水题)
题意:给定 n 个数,表示不同的环,然后把环拆成全是1,每次只能拆成两个,问你有多少次. 析:也不难,反正都要变成1,所以把所有的数都减1,再求和即可. 代码如下: #pragma comment(l ...
- 绑定线程到特定CPU处理器
参考这篇文章 http://blog.chinaunix.net/uid-27761170-id-5050258.html 代码如下: #define _GNU_SOURCE #include < ...
- HTTP Header 简介
HTTP Header 简介 HTTP(HyperTextTransferProtocol)即超文本传输协议,目前网页传输的的通用协议.HTTP协议采用了请求/响应模型,浏览器或其他客户端发出请求,服 ...
- Spring aop实现方式记录
原文地址:http://blog.csdn.net/moreevan/article/details/11977115 Spring提供了两种方式来生成代理对象: JDKProxy和Cglib,具体使 ...