22-hadoop-hive搭建
1, hive简介
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。是为了非java人员对hdfs进行mapreduce操作的
数据仓库,英文名称为Data Warehouse,可简写为DW或DWH。数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它是单个数据存储,出于分析性报告和决策支持目的而创建。 为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制,简而言之,数据仓库是用来做查询分析的数据库,基本不用来做插入,修改,删除
hive的本质为: 线下数据挖掘和分析使用的工具
解释器: 解释sql语句
编译器: (将sql编译为maperduce),
优化器: 对编译过程优化
2, hive结构
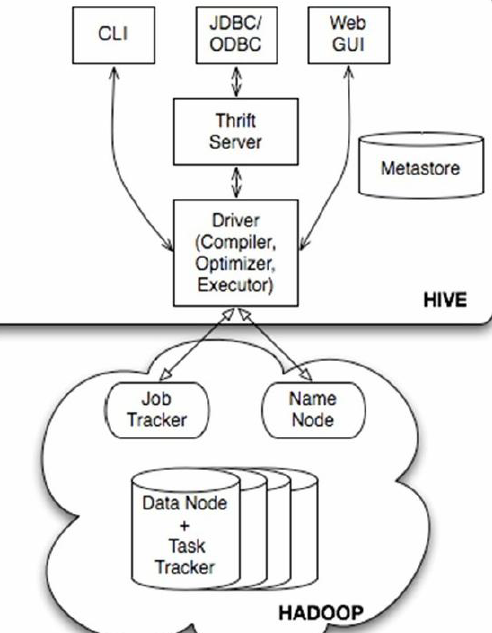
(1)用户接口主要有三个:CLI,Client 和WUI。其中最常用的是CLI,Cli启动的时候,会同时启动一个Hive副本。Client是Hive的客户端,用户连接至Hive Server。在启动Client模式的时候,需要指出Hive Server所在节点,并且在该节点启动Hive Server。WUI是通过浏览器访问Hive。
(2)Hive将元数据存储在数据库中,如mysql、derby。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
(3)解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。
(4)Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成(包含*的查询,比如select * from tbl不会生成MapRedcue任务)。
执行:
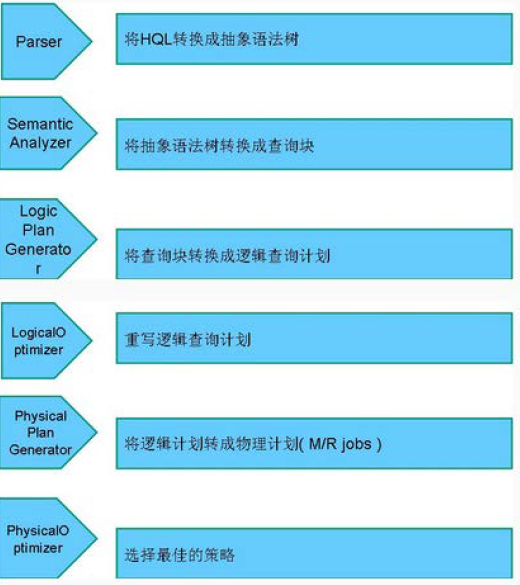
•编译器将一个Hive QL转换操作符
•操作符是Hive的最小的处理单元
•每个操作符代表HDFS的一个操作或者一道MapReduce作业
3, 实现原理
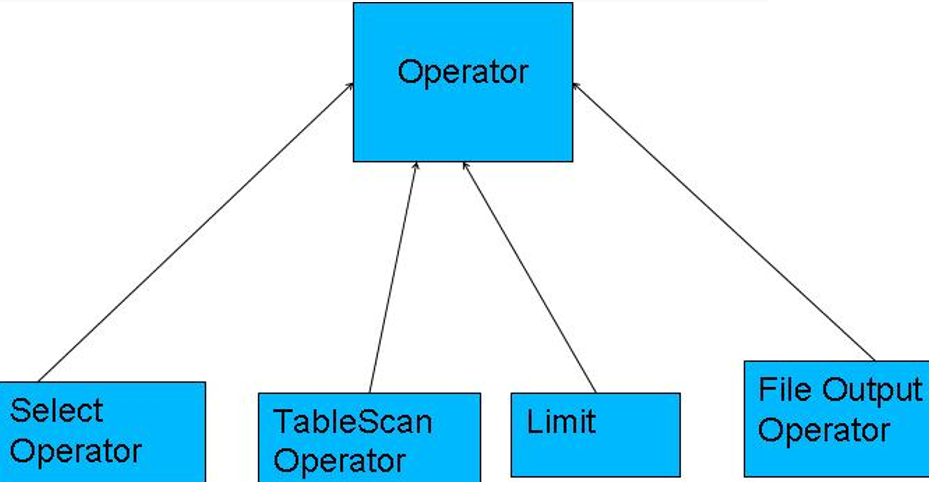
Operator都是hive定义的一个处理过程
•Operator都定义有:
•protected List <Operator<? extends Serializable >> childOperators;
•protected List <Operator<? extends Serializable >> parentOperators;
•protected boolean done; // 初始化值为false
•所有的操作构成了 Operator图,hive正是基于这些图关系来处理诸如limit, group by, join等操作
使用Antlr解析hql语句的
4, 执行流程
hive通过 ExecMapper 和 ExecReduce 执行mapreduce任务
TableScanOperator 扫描hive表数据
ReduceSinkOperator 创建将发送到Reducer端的<Key,Value>对
JoinOperator Join两份数据
SelectOperator 选择输出列
FileSinkOperator 建立结果数据,输出至文件
FilterOperator 过滤输入数据
GroupByOperator GroupBy语句
MapJoinOperator /*+mapjoin(t) */
LimitOperator Limit语句
UnionOperator Union语句
5, 三种模式
Derby: 单用户, 内置数据库
Mysql: 单用户, 使用mysql
meta: 多用户, 区分客户端和服务端
需要Mysql, ( http://www.cnblogs.com/wenbronk/p/6840484.html )
1) derby模式的搭建:
1, 上传解压

2, 修改配置文件
cp hive-default.xml.template hive-site.xml
将hive-site.xml中的所有信息删除, 更换为一下配置文件
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby:;databaseName=metastore_db;create=true</value>
</property> <property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.apache.derby.jdbc.EmbeddedDriver</value>
</property> <property>
<name>hive.metastore.local</name>
<value>true</value>
</property> <property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
</configuration>
3, 更改hadoop的jline.jar
因为hadoop安装的为2.5.1, hive的版本是1,2,1 , 所以更换hadoop的hive链接包, jline
将 HADOOP_HOME//share/hadoop/yarn/lib 下的jline 更换为 jline.2.12.jar
4, 添加环境变量(可选)
将 HIVE_HOME 添加到环境变量中
export HIVE_HOME=/opt/apache-hive-1.2.-bin
export PATH=$PATH:$HIVE_HOME/bin
5, 启动
hive
2) mysql模式安装
1, 需要mysql的环境
此处mysql和hive为同一台机器
/* 创建hive的专用数据库(需要创建, 不然报错) */
create database hive;
2, 将 mysql的链接jar放进jdbc中

3, 更改配置文件
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_remote/warehouse</value>
</property> <property>
<name>hive.metastore.local</name>
<value>true</value>
</property> <property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.208.109:3306/hive_remote?createDatabaseIfNotExist=true</value>
</property> <property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property> <property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property> <property>
<name>javax.jdo.option.ConnectionPassword</name>
<value></value>
</property> </configuration>
4, 启动
./hive
3), metastore 模式
配置文件不同:
service端
<configuration> <property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property> <property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.208.109:3306/hive?createDatabaseIfNotExist=true</value>
</property> <property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property> <property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property> <property>
<name>javax.jdo.option.ConnectionPassword</name>
<value></value>
</property>
</configuration>
client端:
<configuration> <property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property> <property>
<name>hive.metastore.local</name>
<value>false</value>
</property> <property>
<name>hive.metastore.uris</name>
<value>thrift://192.168.208.109:9083</value>
</property> </configuration>
2, 启动hive服务端程序
hive --service metastore
3, 客户端直接使用hive命令即可
root@my188:~$ hive
Hive history file=/tmp/root/hive_job_log_root_201301301416_955801255.txt
hive> show tables;
OK
test_hive
Time taken: 0.736 seconds
4, 验证是否成功
进入hive后, 创建一个表, 看表信息是否存储在mysql中了( 此处使用的第二种模式)
CREATE TABLE xp(id INT,name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
然后进入mysql下, 在hive或 hive_remote 数据库下, 有hive自己创建的表信息

系列来自尚学堂视频
22-hadoop-hive搭建的更多相关文章
- 服务器Hadoop+Hive搭建
出于安全稳定考虑很多业务都需要服务器服务器Hadoop+Hive搭建,但经常有人问我,怎么去选择自己的配置最好,今天天气不错,我们一起来聊一下这个话题. Hadoop+Hive环境搭建 1虚拟机和系统 ...
- 通过hadoop + hive搭建离线式的分析系统之快速搭建一览
最近有个需求,需要整合所有店铺的数据做一个离线式分析系统,曾经都是按照店铺分库分表来给各自商家通过highchart多维度展示自家的店铺经营 数据,我们知道这是一个以店铺为维度的切分数据,非常适合目前 ...
- Centos搭建mysql/Hadoop/Hive/Hbase/Sqoop/Pig
目录: 准备工作 Centos安装 mysql Centos安装Hadoop Centos安装hive JDBC远程连接Hive Hbase和hive整合 Centos安装Hbase 准备工作: 配置 ...
- 环境搭建 Hadoop+Hive(orcfile格式)+Presto实现大数据存储查询一
一.前言 Hadoop简介 Hadoop就是一个实现了Google云计算系统的开源系统,包括并行计算模型Map/Reduce,分布式文件系统HDFS,以及分布式数据库Hbase,同时Hadoop的相关 ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之八----- Hadoop、Spark、HBase、Hive搭建环境遇到的错误以及解决方法
前言 在搭建大数据Hadoop相关的环境时候,遇到很多了很多错误.我是个喜欢做笔记的人,这些错误基本都记载,并且将解决办法也写上了.因此写成博客,希望能够帮助那些搭建大数据环境的人解决问题. 说明: ...
- hadoop+hive+spark搭建(一)
1.准备三台虚拟机 2.hadoop+hive+spark+java软件包 传送门:Hadoop官网 Hive官网 Spark官网 一.修改主机名,hosts文件 主机名修改 hostnam ...
- 手把手教你搭建hadoop+hive测试环境(新手向)
本文由 网易云发布. 作者:唐雕龙 本篇文章仅限内部分享,如需转载,请联系网易获取授权. 面向新手的hadoop+hive学习环境搭建,加对我走过的坑总结,避免大家踩坑. 对于hive相关docke ...
- Hadoop Hive概念学习系列之hive三种方式区别和搭建、HiveServer2环境搭建、HWI环境搭建和beeline环境搭建(五)
说在前面的话 以下三种情况,最好是在3台集群里做,比如,master.slave1.slave2的master和slave1都安装了hive,将master作为服务端,将slave1作为服务端. 以 ...
- Mac OSX系统中Hadoop / Hive 与 spark 的安装与配置 环境搭建 记录
Mac OSX系统中Hadoop / Hive 与 spark 的安装与配置 环境搭建 记录 Hadoop 2.6 的安装与配置(伪分布式) 下载并解压缩 配置 .bash_profile : ...
随机推荐
- (转)ASP.NET MVC3 Razor视图引擎-基础语法
转自:http://kb.cnblogs.com/page/96883/ I:ASP.NET MVC3在Visual Studio 2010中的变化 在VS2010中新建一个MVC3项目可以看出与以往 ...
- web-day10
第10章WEB10-requet&response篇 今日任务 登录系统后完成文件下载 商城系统注册功能. 教学导航 教学目标 掌握response设置响应头 掌握response重定向和转发 ...
- 基于FPGA的I2C读写EEPROM
I2C在芯片的配置中应用还是很多的,比如摄像头.VGA转HDMI转换芯片,之前博主分享过一篇I2C协议的基础学习IIC协议学习笔记,这篇就使用Verilog来实现EEPROM的读写,进行一个简单的I2 ...
- Scala_控制结构
控制结构 if条件表达式 val x = 6 if (x>0){ println("This is a positive number") }else if(x== ...
- AngularJS 路由 resolve属性
当路由切换的时候,被路由的页面中的元素(标签)就会立马显示出来,同时,数据会被准备好并呈现出来.但是注意,数据和元素并不是同步的,在没有任何设置的情况下,AngularJS默认先呈现出元素,而后再呈现 ...
- MCU_数码管常用表
共阴极数码管编码(0---F) unsigned char code table[]={ 0x3f,0x06,0x5d,0x4f, 0x66,0x6d,0x77,0x7c, 0x39,0x5e,0x7 ...
- 1.html基础
认识html 1.1 Hyper text markup language 超文本标记语言. 超文本:超链接.(实现页面跳转) Html结构标准 < ! doctype html> ...
- Beta版本冲刺准备
1. 介绍小组新加入的成员,Ta担任的角色. 姓名 王华俊 爱好 PS ,听音乐等等 编程方向 Java小程序,GUI 团队内担任的角色 美工 让他担任这个角色的理由:不同于别人的直男审美 2. 讨论 ...
- python threading模块2
Thread 是threading模块中最重要的类之一,可以使用它来创建线程.有两种方式来创建线程:一种是通过继承Thread类,重写它的run方法:另一种是创建一个threading.Thread对 ...
- jQuery基础(3)- ajax
一.jQuery的ajax 1.什么是ajax AJAX = 异步的javascript和XML(Asynchronous Javascript and XML). 简言之,在不重载整个网页的情况下, ...