【大数据实战】将普通文本文件导入ElasticSearch
以《刑法》文本.txt为例。
一、格式化数据
1,首先,ElasticSearch只能接收格式化的数据,所以,我们需要将文本文件转换为格式化的数据---json。
下图为未处理的文本文件。

2,这里,使用python文件操作,将文本格式化为ElasticSearch可识别的json格式。
#python 3.6
#!/usr/bin/env python # -*- coding:utf-8 -*-
__author__ = 'BH8ANK'
'''
最终将输出格式改为
{"index":{"_index":"xingfa","_id":1}}
{"text_entry":"犯罪的行为或者结果有一项发生在中华人民共和国领域内的,就认为是在中华人民共和国领域内犯罪。"} ''' '''读取文件
'''
a = open(r"D:\xingfa.txt", "r",encoding='utf-8')
out = a.read()
#print(out)
TypeList = out.split('\n')
#print(TypeList) lenth = len(TypeList)
print(lenth) number = 1
ju_1 = '{"index":{"_index":"xingfa","_id":'
ju_2 = '{"text_entry":"' # print(ju_1)
for x in TypeList: res_1 = ju_1 + str(number) + '}}'+'\n'
print(res_1)
a = open(r"D:\out.json", "a", encoding='UTF-8')
a.write(res_1) res_2 = ju_2 + x + '"}'+'\n'
print(res_2)
a = open(r"D:\out.json", "a", encoding='UTF-8')
a.write(res_2) a.close()
number+=1
3,执行后,输出的json内容为:
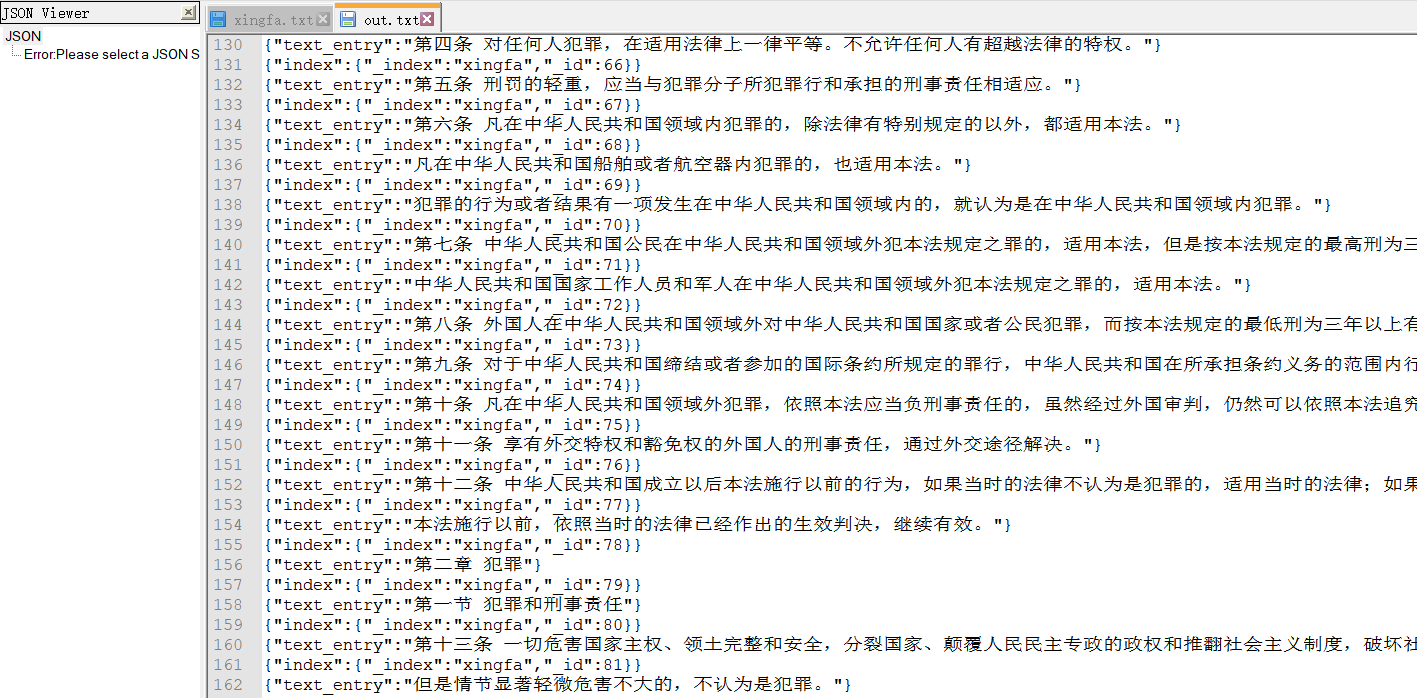
二、将数据导入ElasticSearch
1,我们要为即将导入的数据,建立映射。此操作可以在kibana或命令行完成。
PUT /xingfa
{
"mappings": {
"doc": {
"properties": {
"text_entry":{"type":"keyword"}
}
}
}
}
2,登录虚拟机,将之前生成的out.json文件,导入到对应ElasticSearch集群中。
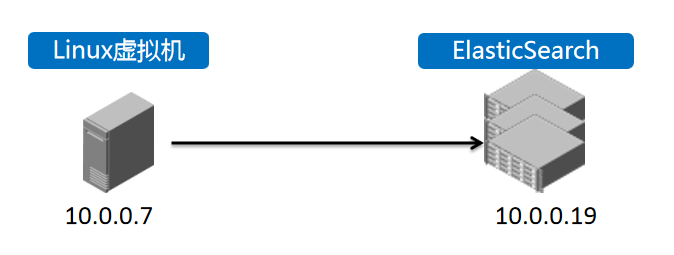
我们的ES组网情况如上图。
操作如下:
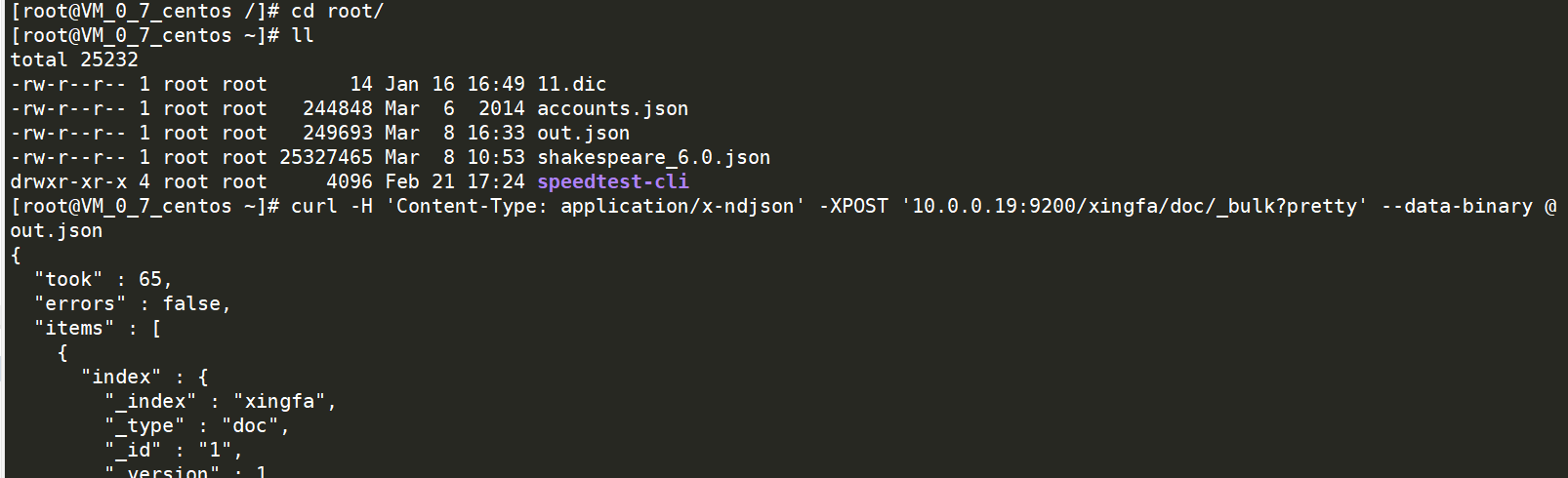
命令如下:
curl -H 'Content-Type: application/x-ndjson' -XPOST '10.0.0.19:9200/xingfa/doc/_bulk?pretty' --data-binary @out.json
等待命令执行完成后,即可登录kibana去查询对应的数据了。
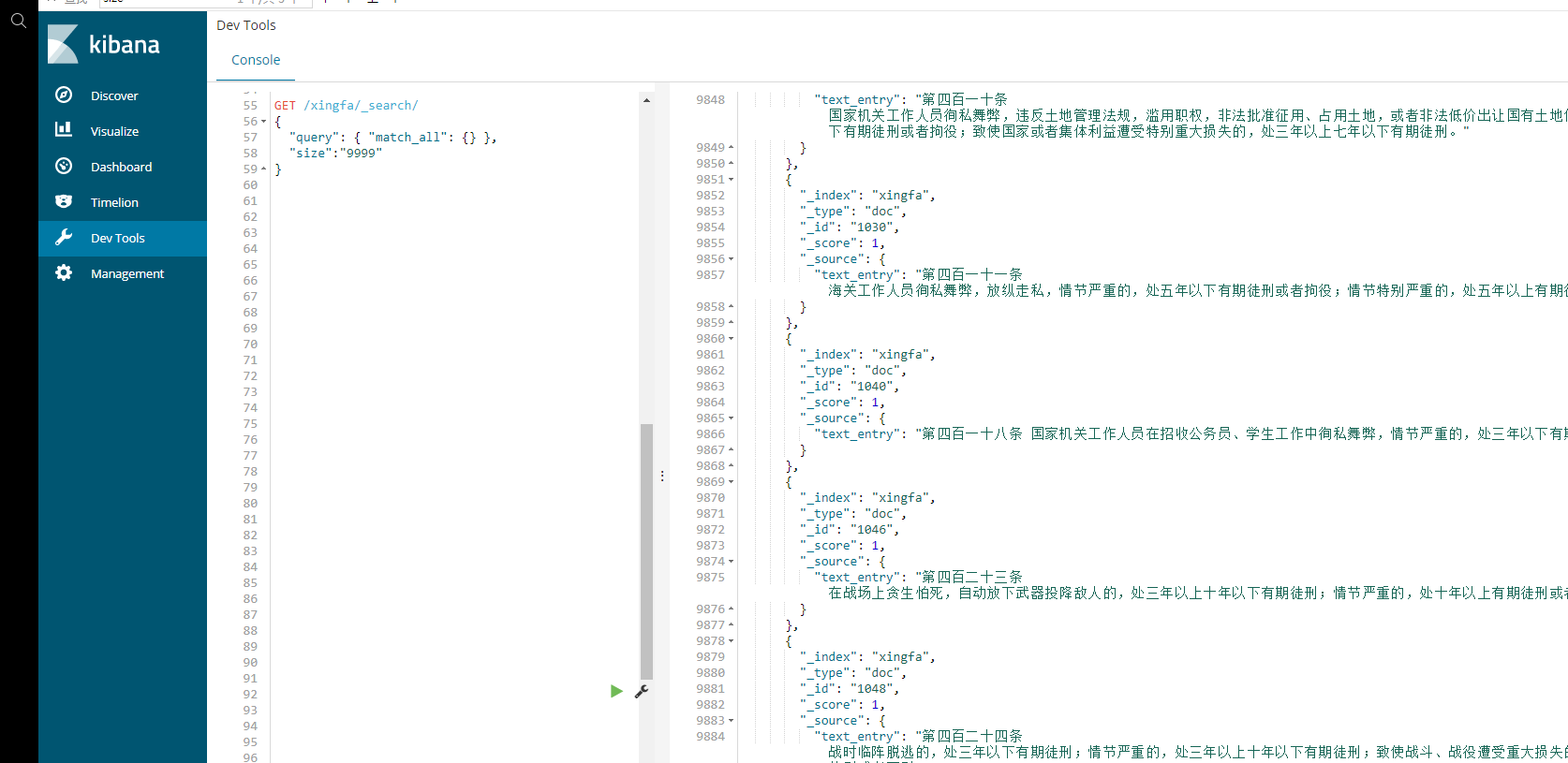
使用查询语句:
GET /xingfa/_search/
{
"query": { "match_all": {} },
"size":"" //此处设置为9999,主要原因是,不加参数的话,默认搜索结果仅显示部分,一般是5.
}
也可以直接在虚拟机命令行里,查询这个索引,确认数据是否已经完成上传。
使用查询语句:
curl -XGET "http://10.0.0.19:9200/xingfa/_search/" -H 'Content-Type: application/json' -d'
{
"query": {
"match_all": {}
},
"size": ""
}'
至此,完成数据导入。
【大数据实战】将普通文本文件导入ElasticSearch的更多相关文章
- SparkSQL大数据实战:揭开Join的神秘面纱
本文来自 网易云社区 . Join操作是数据库和大数据计算中的高级特性,大多数场景都需要进行复杂的Join操作,本文从原理层面介绍了SparkSQL支持的常见Join算法及其适用场景. Join背景介 ...
- 《OD大数据实战》HDFS入门实例
一.环境搭建 1. 下载安装配置 <OD大数据实战>Hadoop伪分布式环境搭建 2. Hadoop配置信息 1)${HADOOP_HOME}/libexec:存储hadoop的默认环境 ...
- 《OD大数据实战》驴妈妈旅游网大型离线数据电商分析平台
一.环境搭建 1. <OD大数据实战>Hadoop伪分布式环境搭建 2. <OD大数据实战>Hive环境搭建 3. <OD大数据实战>Sqoop入门实例 4. &l ...
- 《OD大数据实战》Hive环境搭建
一.搭建hadoop环境 <OD大数据实战>hadoop伪分布式环境搭建 二.Hive环境搭建 1. 准备安装文件 下载地址: http://archive.cloudera.com/cd ...
- 【大数据实战】Logstash采集->Kafka->ElasticSearch检索
1. Logstash概述 Logstash的官网地址为:https://www.elastic.co/cn/products/logstash,以下是官方对Logstash的描述. Logstash ...
- Azure HDInsight 和 Spark 大数据实战(一)
What is HDInsight? Microsoft Azure HDInsight 是基于 Hortonoworks Data Platform (HDP) 的 Hadoop 集群,包括Stor ...
- 大数据入门第二十五天——elasticsearch入门
一.概述 推荐路神的ES权威指南翻译:https://es.xiaoleilu.com/010_Intro/00_README.html 官网:https://www.elastic.co/cn/pr ...
- 《OD大数据实战》环境整理
一.关机后服务重新启动 1. 启动hadoop服务 sbin/hadoop-daemon.sh start namenode sbin/hadoop-daemon.sh start datanode ...
- 【若泽大数据实战第二天】Linux命令基础
Linux基本命令: 查看IP: ifconfig 或者 hostname -i(需要配置文件之后才可以使用) ipconfig(Windows) 关闭防火墙: Service iptables st ...
随机推荐
- ZooKeeper 的读写操作 & 选举机制
0. 说明 记录 ZooKeeper 的读写操作和选举机制 1. ZooKeeper 的读写操作 读操作:所有 ZooKeeper 节点都可以提供读请求(包括 follower 和 leader ) ...
- Redis学习---面试基础知识点总结
[学习参考] https://www.toutiao.com/i6566017785078481422/ https://www.toutiao.com/i6563232898831352323/ 0 ...
- app的描述-软件的描述
app的描述=需求文档+接口文档+程序架构+工程结构. 程序架构:类结构图: 需求文档:业务逻辑-->时序图.
- 20165318 2017-2018-2《Java程序设计》课程总结
20165318 2017-2018-2<Java程序设计>课程总结 一.每周作业链接汇总 每周作业链接汇总 预备作业1:我期望的师生关系 预备作业2:C语言基础调查和java学习展望 预 ...
- PAT B1007 素数对猜想 (20 分)
让我们定义dn为:dn=pn+1−pn,其中pi是第i个素数.显然有d1=1,且对于n>1有dn是偶数.“素数对猜想”认为“存在无穷多对相邻且差为2的素 ...
- Android解决Intent中的数据重复问题
转载地址:http://www.cnblogs.com/anrainie/articles/2383941.html 最近在研究Android,遇到了一些Notification(通知)的问题: .N ...
- DQN(Deep Reiforcement Learning) 发展历程(四)
目录 不基于模型的控制 选取动作的方法 在策略上的学习(on-policy) 不在策略上的学习(off-policy) 参考 DQN发展历程(一) DQN发展历程(二) DQN发展历程(三) DQN发 ...
- day48
flex布局 响应式布局 过度 动画 flex布局 学习目的:基于之前所学的盒模型布局(display).浮动布局(float).定位布局(position),都不能很好的解决block垂直居中的问题 ...
- Swift10大开源项目记录
Alamofire : Swift编写的HTTP网络库,用于异步网络通信. Surge: Surge基于Accelerate框架开发,用于执行矩阵数学.数字信号处理以及图像处理等方面. SwiftyJ ...
- odoo销售转生产
<!--form view 一个form视图足以--><record id="view_sale_tomrp_form" model="ir.ui.vi ...