【大数据实战】将普通文本文件导入ElasticSearch
以《刑法》文本.txt为例。
一、格式化数据
1,首先,ElasticSearch只能接收格式化的数据,所以,我们需要将文本文件转换为格式化的数据---json。
下图为未处理的文本文件。

2,这里,使用python文件操作,将文本格式化为ElasticSearch可识别的json格式。
#python 3.6
#!/usr/bin/env python # -*- coding:utf-8 -*-
__author__ = 'BH8ANK'
'''
最终将输出格式改为
{"index":{"_index":"xingfa","_id":1}}
{"text_entry":"犯罪的行为或者结果有一项发生在中华人民共和国领域内的,就认为是在中华人民共和国领域内犯罪。"} ''' '''读取文件
'''
a = open(r"D:\xingfa.txt", "r",encoding='utf-8')
out = a.read()
#print(out)
TypeList = out.split('\n')
#print(TypeList) lenth = len(TypeList)
print(lenth) number = 1
ju_1 = '{"index":{"_index":"xingfa","_id":'
ju_2 = '{"text_entry":"' # print(ju_1)
for x in TypeList: res_1 = ju_1 + str(number) + '}}'+'\n'
print(res_1)
a = open(r"D:\out.json", "a", encoding='UTF-8')
a.write(res_1) res_2 = ju_2 + x + '"}'+'\n'
print(res_2)
a = open(r"D:\out.json", "a", encoding='UTF-8')
a.write(res_2) a.close()
number+=1
3,执行后,输出的json内容为:
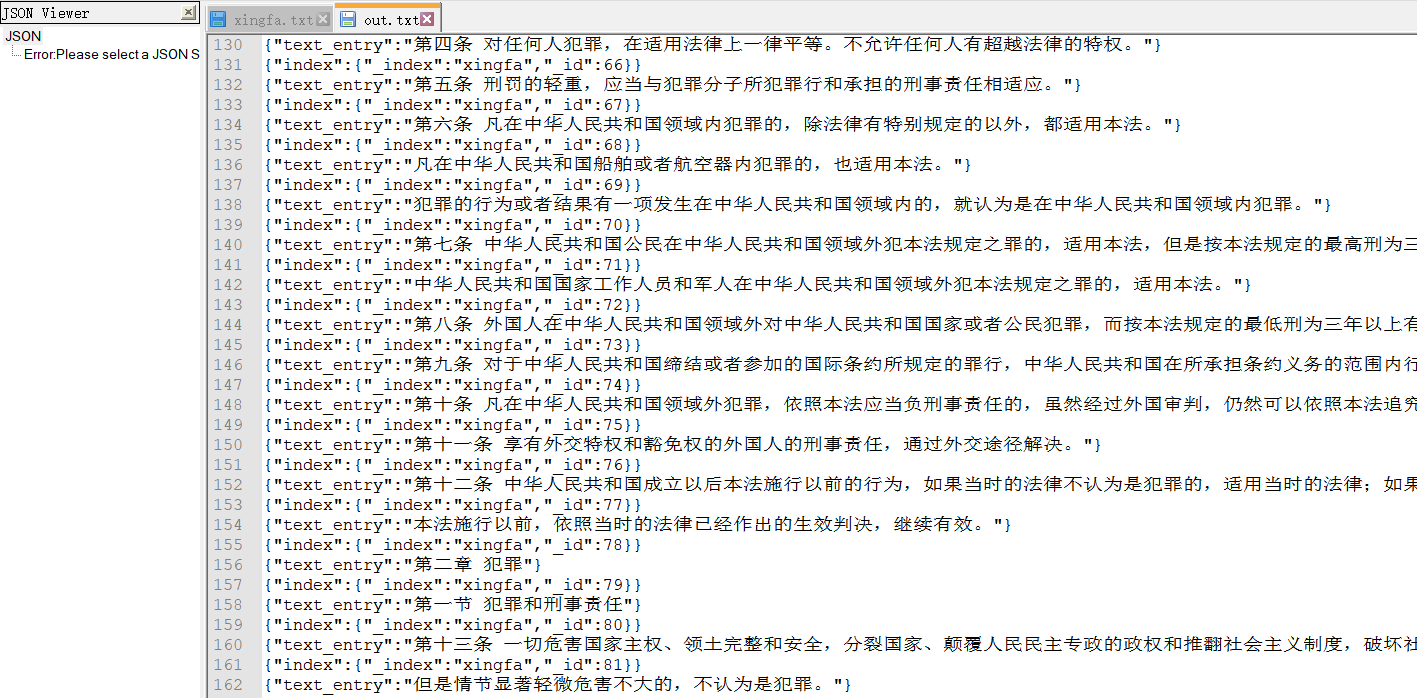
二、将数据导入ElasticSearch
1,我们要为即将导入的数据,建立映射。此操作可以在kibana或命令行完成。
PUT /xingfa
{
"mappings": {
"doc": {
"properties": {
"text_entry":{"type":"keyword"}
}
}
}
}
2,登录虚拟机,将之前生成的out.json文件,导入到对应ElasticSearch集群中。
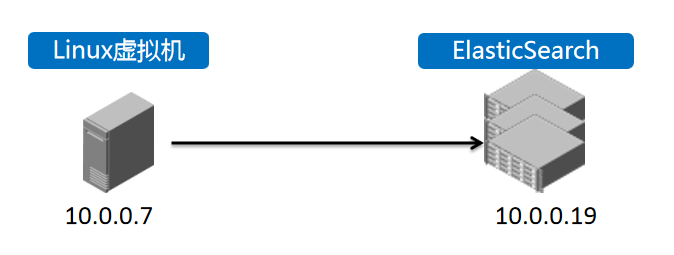
我们的ES组网情况如上图。
操作如下:
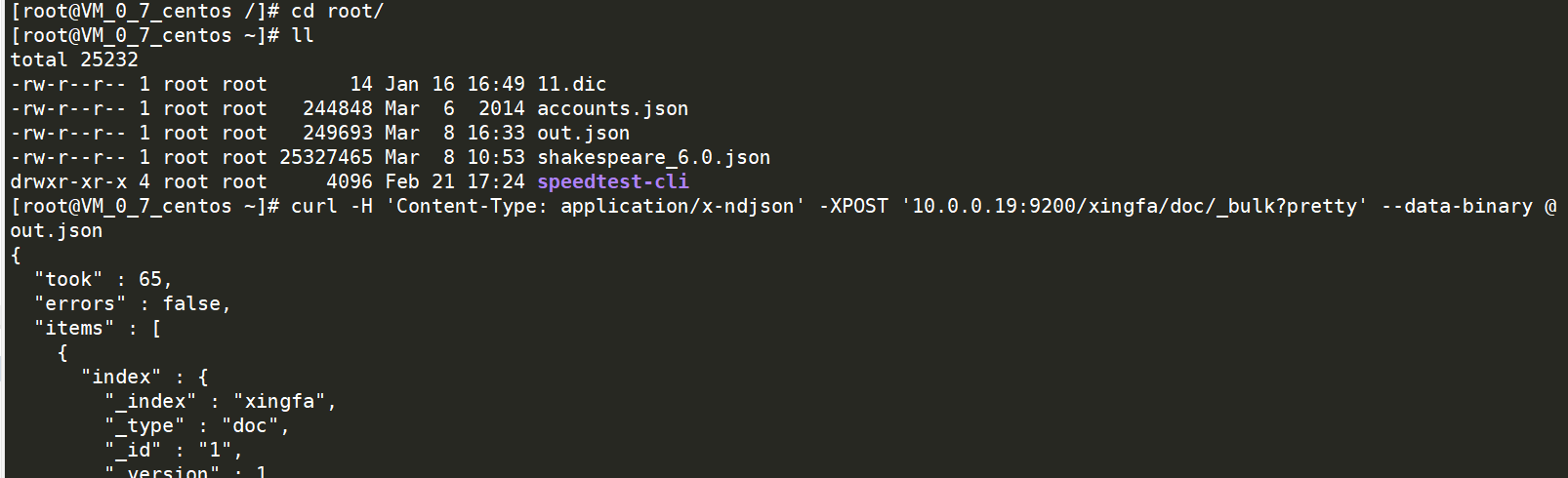
命令如下:
curl -H 'Content-Type: application/x-ndjson' -XPOST '10.0.0.19:9200/xingfa/doc/_bulk?pretty' --data-binary @out.json
等待命令执行完成后,即可登录kibana去查询对应的数据了。
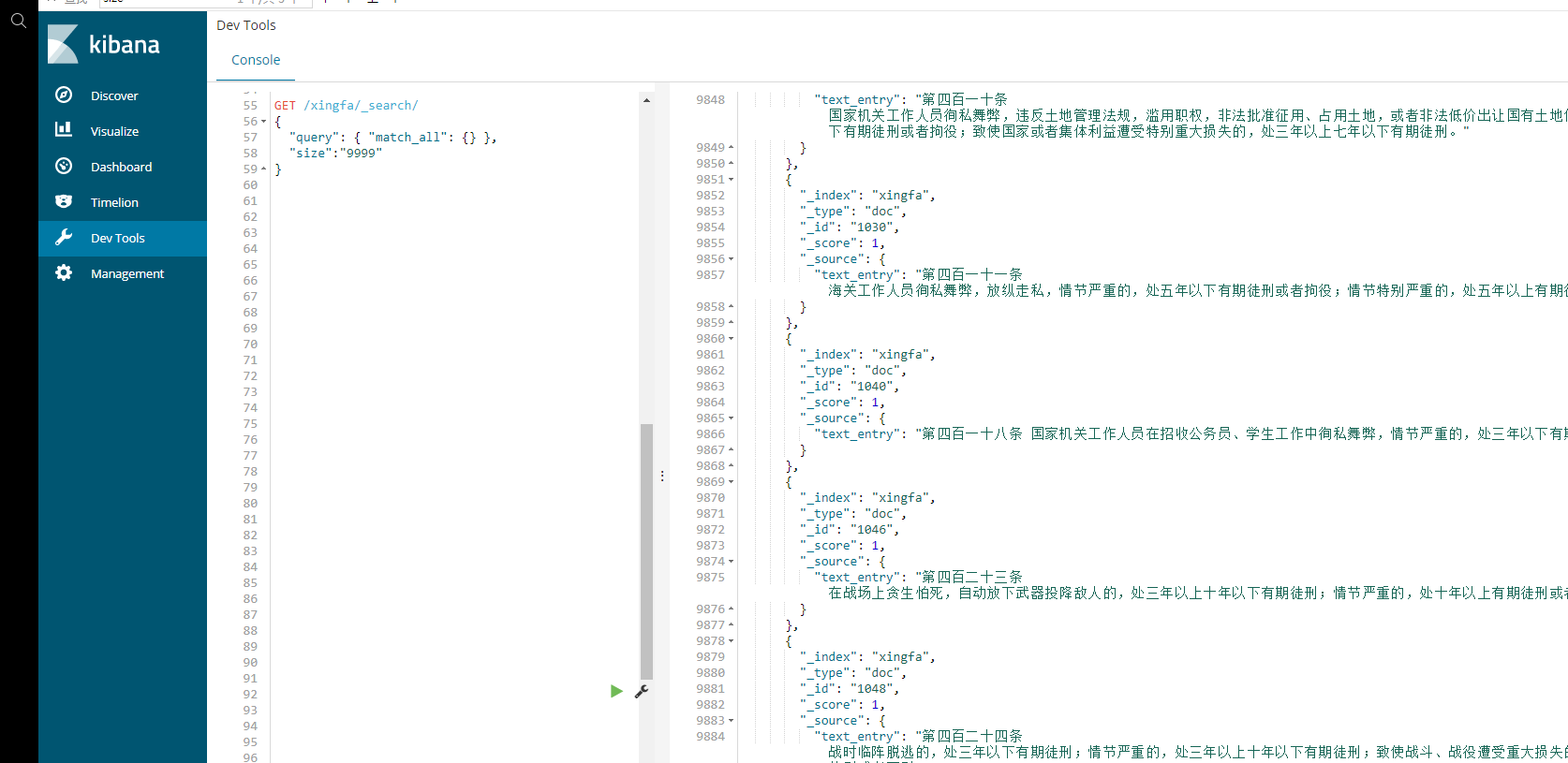
使用查询语句:
GET /xingfa/_search/
{
"query": { "match_all": {} },
"size":"" //此处设置为9999,主要原因是,不加参数的话,默认搜索结果仅显示部分,一般是5.
}
也可以直接在虚拟机命令行里,查询这个索引,确认数据是否已经完成上传。
使用查询语句:
curl -XGET "http://10.0.0.19:9200/xingfa/_search/" -H 'Content-Type: application/json' -d'
{
"query": {
"match_all": {}
},
"size": ""
}'
至此,完成数据导入。
【大数据实战】将普通文本文件导入ElasticSearch的更多相关文章
- SparkSQL大数据实战:揭开Join的神秘面纱
本文来自 网易云社区 . Join操作是数据库和大数据计算中的高级特性,大多数场景都需要进行复杂的Join操作,本文从原理层面介绍了SparkSQL支持的常见Join算法及其适用场景. Join背景介 ...
- 《OD大数据实战》HDFS入门实例
一.环境搭建 1. 下载安装配置 <OD大数据实战>Hadoop伪分布式环境搭建 2. Hadoop配置信息 1)${HADOOP_HOME}/libexec:存储hadoop的默认环境 ...
- 《OD大数据实战》驴妈妈旅游网大型离线数据电商分析平台
一.环境搭建 1. <OD大数据实战>Hadoop伪分布式环境搭建 2. <OD大数据实战>Hive环境搭建 3. <OD大数据实战>Sqoop入门实例 4. &l ...
- 《OD大数据实战》Hive环境搭建
一.搭建hadoop环境 <OD大数据实战>hadoop伪分布式环境搭建 二.Hive环境搭建 1. 准备安装文件 下载地址: http://archive.cloudera.com/cd ...
- 【大数据实战】Logstash采集->Kafka->ElasticSearch检索
1. Logstash概述 Logstash的官网地址为:https://www.elastic.co/cn/products/logstash,以下是官方对Logstash的描述. Logstash ...
- Azure HDInsight 和 Spark 大数据实战(一)
What is HDInsight? Microsoft Azure HDInsight 是基于 Hortonoworks Data Platform (HDP) 的 Hadoop 集群,包括Stor ...
- 大数据入门第二十五天——elasticsearch入门
一.概述 推荐路神的ES权威指南翻译:https://es.xiaoleilu.com/010_Intro/00_README.html 官网:https://www.elastic.co/cn/pr ...
- 《OD大数据实战》环境整理
一.关机后服务重新启动 1. 启动hadoop服务 sbin/hadoop-daemon.sh start namenode sbin/hadoop-daemon.sh start datanode ...
- 【若泽大数据实战第二天】Linux命令基础
Linux基本命令: 查看IP: ifconfig 或者 hostname -i(需要配置文件之后才可以使用) ipconfig(Windows) 关闭防火墙: Service iptables st ...
随机推荐
- centos中,tomcat项目创建文件的权限
参考文章:https://cloud.tencent.com/info/5f02caa932fd6dbfc46a3bb01af135e0.html 我们在centos中输入umask,会看到输出002 ...
- yaml格式
yaml中允许表示三种格式,分别为常量值.对象和数组 例如: 其中#作为注释,yaml中只有行注释 基本格式要求: 1.大小写敏感:2.使用缩进代表层级关系: 3.缩进只能使用空格,不能使用tab键, ...
- 3.Solr4.10.3目录结构
转载请出自出处:http://www.cnblogs.com/hd3013779515/ 1.整个目录结构 (1)bin:是脚本的启动目录 (2)contrib:第三方包存放的目录 (3)dist:编 ...
- zepto.js不支持scrollTop的解决办法
zepto.js不支持animate({ scrollTop: 100},1000); 可以在移动端使用原生window.scrollTop(x,y);简便
- 密码破解技术——P201421410029
学 号 201421410029 中国人民公安大学 Chinese people’ public security university 网络对抗技术 实验报告 实验三 密码破解技术 ...
- Mac svn使用学习-2-服务端
2.在mac环境下搭建一个SVN服务器环境 1)创建一个名为myCode的仓库——svnadmin命令 格式: svnadmin SUBCOMMAND REPOS_PATH [ARGS & O ...
- 21天,搞定软件测试从业者必备的Linux命令
开始之前,先同步一个结论: 对于软件测试从业者,如果你至今为止,还不懂Linux,或者完全没有接触Linux ,这是一件很危险和恐怖的事 . 此刻.现在.果断,学习Linux命令 . 如果你工作中,完 ...
- CentOS7服务器配置网络
Centos7最小化安装 [root@localhost ~]# vim /etc/sysconfig/network-scripts/ifcfg-enp5s0f0编辑如下:TYPE=Ethernet ...
- Java学习笔记--Java开发坏境搭建
一.安装JDK http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 根据自己系统选择 ...
- 609E- Minimum spanning tree for each edge
Connected undirected weighted graph without self-loops and multiple edges is given. Graph contains n ...