MSSQL批量写入数据方案
近来有一个项目Feature需要有批量写入数据的场景,正巧整理资料发现自己以前也类似实现的项目,在重构的同时把相关资料做了一个简单的梳理,方便大家参考。
- 循环写入(简单粗暴,毕业设计就这样干的)(不推荐)
- Bulk Copy写入(>1000K 记录一次性写入推荐)
- 表值参数方式写入(mssql 2008新特性)(强烈推荐)
在SQL Server 2008未提供表值参数之前,需要将多行数据传递到存储过程或参数化sql命令我们一般会采用以下几个方法:
- 使用一系列单参数来表示多个数据列和行中的值。但使用这个方法会受所允许参数数量限制。Sql server 程序最多可以有2100个参数。服务器必须将这些参数进行再组织成临时表或表变量再进行后续处理。
- 将多个数据增加分隔字符串或序列化为xml字符串,然后将这些字符回传服务器。服务器根据解析字符串与xml进行处理。
- 将多条写入语句包装在一个单条语句当中。这种方式同sqldataadapter当中的update方法的实现逻辑,可以标识批次处理的个数。不过就算按照包装多个语句进行批次提交,每个语句仍然会分别在服务器上执行。(只是节约了请求的次数而已)
- 使用BCP实用工具或SqlBulkCopy对象将很多行数据加载到表中。尽管这荐技术非常有效,但不支持服务器处理,除非将数据加载到临时表或表变量中。
方案一
作为早期学习时出镜率最高的的实现方法我在这里就不特别说明了,在这里直接上码及测试数据:
public static void NormalInsertDate(DataTable dt)
{
using (var sqlConn = new SqlConnection(_testDataConnectionString))
{
var sql = "INSERT INTO Student(Name,Age) VALUES(@Name,@Age)";
using (var cmd = new SqlCommand(sql, sqlConn))
{
sqlConn.Open();
cmd.Parameters.Add("@Name", SqlDbType.NVarChar, );
cmd.Parameters.Add("@Age", SqlDbType.Int);
for (int i = ; i < dt.Rows.Count; i++)
{
cmd.Parameters["@Name"].Value = dt.Rows[i]["Name"];
cmd.Parameters["@Age"].Value = dt.Rows[i]["Age"];
cmd.ExecuteNonQuery();
} }
}
}
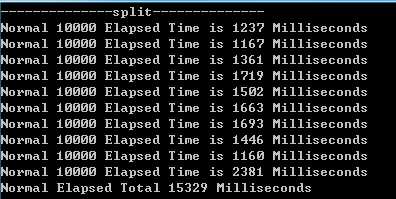
图一为每次10k条,写10次共计100k条数据总计15329ms
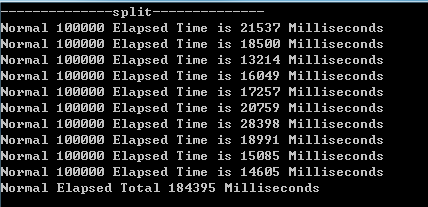
图二为每次100k条,写10次共计1000k条数据总计184395ms
方案二
作为早期批量写入的救星,批量写入的出镜指数4颗星。以下为测试数据:
public static void BulkInsertData(DataTable dt)
{
using (var sqlConn = new SqlConnection(_testDataConnectionString))
{
using (var bulkCopy = new SqlBulkCopy(sqlConn)
{
DestinationTableName = "Student",
BatchSize = dt.Rows.Count
})
{
sqlConn.Open();
bulkCopy.WriteToServer(dt);
}
}
}
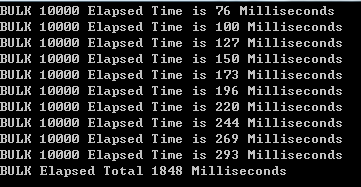
图一为每次10k条,写10次共计100k条数据总计1848ms
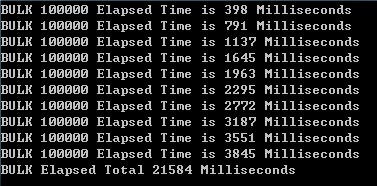
图二为每次100k条,写10次共计1000k条数据总计21584ms
方案三表值参数方式写入
表值参数提供一种将客户端应用程序中的多行数据封送到 SQL Server 的简单方式,而不需要多次往返或特殊服务器端逻辑来处理数据。您可以使用表值参数来包装客户端应用程序中的数据行,并使用单个参数化命令将数据发送到服务器。传入的数据行存储在一个表变量中,然后您可以通过使用 Transact-SQL 对该表变量进行操作。
可以使用标准的 Transact-SQL SELECT 语句来访问表值参数中的列值。表值参数为强类型,其结构会自动进行验证。表值参数的大小仅受服务器内存的限制。
注意:表值参数只能是输入参数,不能作为输出参数。
以下为相关实现:
1.创建表值参数类型(UDT)
USE Test
--CREATE TABLE
CREATE TABLE Student
(
Id INT IDENTITY(1,1) PRIMARY KEY,
Name NVARCHAR(50),
Age INT
)
--create table parameter type
CREATE TYPE StudentUDT AS TABLE
(
Name NVARCHAR(50),
Age INT
)
public static void TableParameterInsertData(DataTable dt)
{
using (var sqlConn = new SqlConnection(_testDataConnectionString))
{
var sql = "INSERT INTO Student(Name,Age) SELECT Name, Age FROM @StudentTVPS";//在这里直接访问表值参数
using (var cmd = new SqlCommand(sql, sqlConn))
{
var catParam = cmd.Parameters.AddWithValue("@StudentTVPS", dt);
catParam.SqlDbType = SqlDbType.Structured;
catParam.TypeName = "StudentUDT";//我们自定义的表值参数类型名称
sqlConn.Open();
cmd.ExecuteNonQuery();
}
}
}

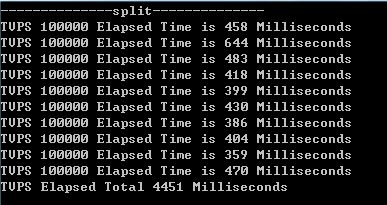
图一为每次10k条,写10次共计100k条数据总计390ms
图二为每次100k条,写10次共计1000k条数据总计4451ms
最后我们再横向比较一下:


就我本机测试的情况来看,normal=9*bulk=42*tvps
另外我就一次性大量数据写入对bulk和tvps单独进行了测试,一次性写入100K条数据两种方案基本持平490ms




但在一次性写入1000K条数据时差距又再次被拉开,bulk=1.5tvps
就测试数据表明bulk在一次性大量写入依然有不小的优势,毕竟ms就是专门让他来做这个事情的。
然而也可以通过tvps进行分范围写入的方式,总消耗时间有小幅度改善。
所有呢,有大量数据一次性写入场景直接使用bulk copy方式吧。他当仁不让可以高效完成使命。
如果就一些普通业务批量场景无需考虑直接上TVPS方式。他的效率相对于较之前xml参数,复杂参数实现批量写入已经是数量级的提升。
你绝对值得拥有。
由于客户端硬件环境原因,测试环境应该不能非常精确。所以以上数据仅供参考。
欢迎大家一起分享交流。
附件本机测试硬件环境:i7 4770+128 ssd+8G内存;
MSSQL批量写入数据方案的更多相关文章
- 使用XML向SQL Server 2005批量写入数据——一次有关XML时间格式的折腾经历
原文:使用XML向SQL Server 2005批量写入数据——一次有关XML时间格式的折腾经历 常常遇到需要向SQL Server插入批量数据,然后在存储过程中对这些数据进行进一步处理的情况.存储过 ...
- HBase BulkLoad批量写入数据实战
1.概述 在进行数据传输中,批量加载数据到HBase集群有多种方式,比如通过HBase API进行批量写入数据.使用Sqoop工具批量导数到HBase集群.使用MapReduce批量导入等.这些方式, ...
- 使用XML向SQL Server 2005批量写入数据——一次有关XML时间格式的折腾经历
使用XML向SQL Server 2005批量写入数据——一次有关XML时间格式的折腾经历 原文:使用XML向SQL Server 2005批量写入数据——一次有关XML时间格式的折腾经历 常常遇 ...
- SQL Server 批量插入数据方案 SqlBulkCopy 的简单封装,让批量插入更方便
一.Sql Server插入方案介绍 关于 SqlServer 批量插入的方式,有三种比较常用的插入方式,Insert.BatchInsert.SqlBulkCopy,下面我们对比以下三种方案的速度 ...
- java连接mysql批量写入数据
1.采用公认的MYSQL最快批量提交办法 public void index() throws UnsupportedEncodingException, Exception { //1000个一提交 ...
- Elasticsearch 5.4.3实战--Java API调用:批量写入数据
这个其实比较简单,直接上代码. 注意部分逻辑可以换成你自己的逻辑 package com.cs99lzzs.elasticsearch.service.imp; import java.sql.Tim ...
- 使用bulkload向hbase中批量写入数据
1.数据样式 写入之前,需要整理以下数据的格式,之后将数据保存到hdfs中,本例使用的样式如下(用tab分开): row1 N row2 M row3 B row4 V row5 N row6 M r ...
- python elasticsearch 批量写入数据
from elasticsearch import Elasticsearch from elasticsearch import helpers import pymysql import time ...
- Shell脚本:向磁盘中批量写入数据
一.关于本文 工作要做的监控系统需要监控磁盘空间的使用率并报警.在测试这个功能的时候需要模拟两个场景:一是磁盘空间不断增长超过设定的阈值时,需要触发报警机制:二是磁盘空间降落到低于报警阈值的时候,不再 ...
随机推荐
- MySQL基础之 LIKE操作符
LIKE操作符 作用:用于在WHERE子句中搜索列中的指定模式. 语法:SELECT COLUMN_NAME FROM TABLE_NAME WHERE COLUMN_NAME LIKE ...
- Hive 整合Hbase
摘要 Hive提供了与HBase的集成,使得能够在HBase表上使用HQL语句进行查询 插入操作以及进行Join和Union等复杂查询.同时也可以将hive表中的数据映射到Hbase中. 应用 ...
- FastDFS_v5.05+nginx+cache集群安装配置手册
转载请出自出处:http://www.cnblogs.com/hd3013779515/ 1.FastDFS简单介绍 FastDFS是由淘宝的余庆先生所开发,是一个轻量级.高性能的开源分布式文件系统, ...
- CSS样式定义的优先级顺序总结
CSS样式定义的优先级顺序总结 层叠优先级是: 浏览器缺省 < 外部样式表 < 内部样式表 < 内联样式 其中样式表又有: 类选择器 < 类派生选择器 < ID选择器 & ...
- Android常见UI组件之ListView(一)
使用ListView显示一个长的项列表 1.新建一个名为"BasicView5"的Android项目. 2.改动BasicView5.java文件.改动后的程序例如以下: pack ...
- AtCoder Regular Contest
一句话题解 因为上篇AGC的写的有点长……估计这篇也短不了所以放个一句话题解方便查阅啥的吧QwQ 具体的题意代码题解还是往下翻…… ARC 058 D:简单容斥计数. E:用二进制表示放的数字,然后状 ...
- BZOJ5368:[PKUSC2018]真实排名(组合数学)
Description 小C是某知名比赛的组织者,该比赛一共有n名选手参加,每个选手的成绩是一个非负整数,定义一个选手的排名是:成绩不小于他的选手的数量(包括他自己). 例如如果333位选手的成绩分别 ...
- debian文本配置网络备忘:/etc/network/interfaces
我装了wheezy有gnome3,xfce4: 郁闷的是,不论在gnome还是xfce4中 我都无法图形登录或者切换用户到root: 而且我无法在普通用户下图形修改网络配置: 我也搜索不到启用root ...
- -bash: start-all.sh: 未找到命令
解决方案:以root权限进入,找到hadoop安装的目录,进入sbin目录下 输入命令#start-all.sh 出现错误:-bash: start-all.sh: 未找到命令 百度了一下:原来需要输 ...
- [Usaco2009 Feb]Revamping Trails 道路升级 BZOJ1579
分析: 比较裸的分层图最短路,我的实现方式是,每次求出1所有节点的最短路,之后用每一个节点更新与其相连的节点(取较小值),之后做K次,就求出了分层图的最短路了. 附上代码: #include < ...