MSSQL批量写入数据方案
近来有一个项目Feature需要有批量写入数据的场景,正巧整理资料发现自己以前也类似实现的项目,在重构的同时把相关资料做了一个简单的梳理,方便大家参考。
- 循环写入(简单粗暴,毕业设计就这样干的)(不推荐)
- Bulk Copy写入(>1000K 记录一次性写入推荐)
- 表值参数方式写入(mssql 2008新特性)(强烈推荐)
在SQL Server 2008未提供表值参数之前,需要将多行数据传递到存储过程或参数化sql命令我们一般会采用以下几个方法:
- 使用一系列单参数来表示多个数据列和行中的值。但使用这个方法会受所允许参数数量限制。Sql server 程序最多可以有2100个参数。服务器必须将这些参数进行再组织成临时表或表变量再进行后续处理。
- 将多个数据增加分隔字符串或序列化为xml字符串,然后将这些字符回传服务器。服务器根据解析字符串与xml进行处理。
- 将多条写入语句包装在一个单条语句当中。这种方式同sqldataadapter当中的update方法的实现逻辑,可以标识批次处理的个数。不过就算按照包装多个语句进行批次提交,每个语句仍然会分别在服务器上执行。(只是节约了请求的次数而已)
- 使用BCP实用工具或SqlBulkCopy对象将很多行数据加载到表中。尽管这荐技术非常有效,但不支持服务器处理,除非将数据加载到临时表或表变量中。
方案一
作为早期学习时出镜率最高的的实现方法我在这里就不特别说明了,在这里直接上码及测试数据:
public static void NormalInsertDate(DataTable dt)
{
using (var sqlConn = new SqlConnection(_testDataConnectionString))
{
var sql = "INSERT INTO Student(Name,Age) VALUES(@Name,@Age)";
using (var cmd = new SqlCommand(sql, sqlConn))
{
sqlConn.Open();
cmd.Parameters.Add("@Name", SqlDbType.NVarChar, );
cmd.Parameters.Add("@Age", SqlDbType.Int);
for (int i = ; i < dt.Rows.Count; i++)
{
cmd.Parameters["@Name"].Value = dt.Rows[i]["Name"];
cmd.Parameters["@Age"].Value = dt.Rows[i]["Age"];
cmd.ExecuteNonQuery();
} }
}
}
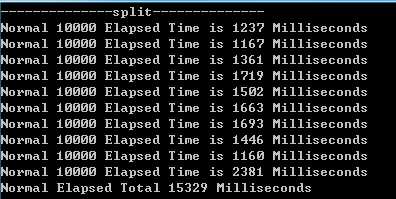
图一为每次10k条,写10次共计100k条数据总计15329ms
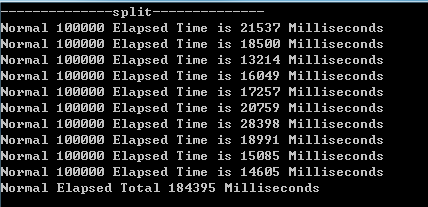
图二为每次100k条,写10次共计1000k条数据总计184395ms
方案二
作为早期批量写入的救星,批量写入的出镜指数4颗星。以下为测试数据:
public static void BulkInsertData(DataTable dt)
{
using (var sqlConn = new SqlConnection(_testDataConnectionString))
{
using (var bulkCopy = new SqlBulkCopy(sqlConn)
{
DestinationTableName = "Student",
BatchSize = dt.Rows.Count
})
{
sqlConn.Open();
bulkCopy.WriteToServer(dt);
}
}
}
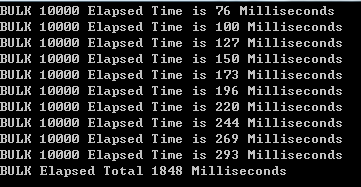
图一为每次10k条,写10次共计100k条数据总计1848ms
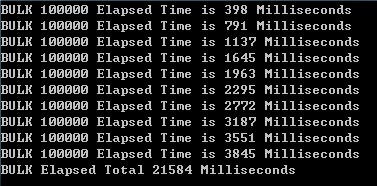
图二为每次100k条,写10次共计1000k条数据总计21584ms
方案三表值参数方式写入
表值参数提供一种将客户端应用程序中的多行数据封送到 SQL Server 的简单方式,而不需要多次往返或特殊服务器端逻辑来处理数据。您可以使用表值参数来包装客户端应用程序中的数据行,并使用单个参数化命令将数据发送到服务器。传入的数据行存储在一个表变量中,然后您可以通过使用 Transact-SQL 对该表变量进行操作。
可以使用标准的 Transact-SQL SELECT 语句来访问表值参数中的列值。表值参数为强类型,其结构会自动进行验证。表值参数的大小仅受服务器内存的限制。
注意:表值参数只能是输入参数,不能作为输出参数。
以下为相关实现:
1.创建表值参数类型(UDT)
USE Test
--CREATE TABLE
CREATE TABLE Student
(
Id INT IDENTITY(1,1) PRIMARY KEY,
Name NVARCHAR(50),
Age INT
)
--create table parameter type
CREATE TYPE StudentUDT AS TABLE
(
Name NVARCHAR(50),
Age INT
)
public static void TableParameterInsertData(DataTable dt)
{
using (var sqlConn = new SqlConnection(_testDataConnectionString))
{
var sql = "INSERT INTO Student(Name,Age) SELECT Name, Age FROM @StudentTVPS";//在这里直接访问表值参数
using (var cmd = new SqlCommand(sql, sqlConn))
{
var catParam = cmd.Parameters.AddWithValue("@StudentTVPS", dt);
catParam.SqlDbType = SqlDbType.Structured;
catParam.TypeName = "StudentUDT";//我们自定义的表值参数类型名称
sqlConn.Open();
cmd.ExecuteNonQuery();
}
}
}

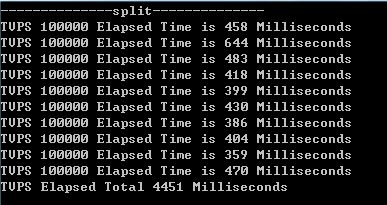
图一为每次10k条,写10次共计100k条数据总计390ms
图二为每次100k条,写10次共计1000k条数据总计4451ms
最后我们再横向比较一下:


就我本机测试的情况来看,normal=9*bulk=42*tvps
另外我就一次性大量数据写入对bulk和tvps单独进行了测试,一次性写入100K条数据两种方案基本持平490ms




但在一次性写入1000K条数据时差距又再次被拉开,bulk=1.5tvps
就测试数据表明bulk在一次性大量写入依然有不小的优势,毕竟ms就是专门让他来做这个事情的。
然而也可以通过tvps进行分范围写入的方式,总消耗时间有小幅度改善。
所有呢,有大量数据一次性写入场景直接使用bulk copy方式吧。他当仁不让可以高效完成使命。
如果就一些普通业务批量场景无需考虑直接上TVPS方式。他的效率相对于较之前xml参数,复杂参数实现批量写入已经是数量级的提升。
你绝对值得拥有。
由于客户端硬件环境原因,测试环境应该不能非常精确。所以以上数据仅供参考。
欢迎大家一起分享交流。
附件本机测试硬件环境:i7 4770+128 ssd+8G内存;
MSSQL批量写入数据方案的更多相关文章
- 使用XML向SQL Server 2005批量写入数据——一次有关XML时间格式的折腾经历
原文:使用XML向SQL Server 2005批量写入数据——一次有关XML时间格式的折腾经历 常常遇到需要向SQL Server插入批量数据,然后在存储过程中对这些数据进行进一步处理的情况.存储过 ...
- HBase BulkLoad批量写入数据实战
1.概述 在进行数据传输中,批量加载数据到HBase集群有多种方式,比如通过HBase API进行批量写入数据.使用Sqoop工具批量导数到HBase集群.使用MapReduce批量导入等.这些方式, ...
- 使用XML向SQL Server 2005批量写入数据——一次有关XML时间格式的折腾经历
使用XML向SQL Server 2005批量写入数据——一次有关XML时间格式的折腾经历 原文:使用XML向SQL Server 2005批量写入数据——一次有关XML时间格式的折腾经历 常常遇 ...
- SQL Server 批量插入数据方案 SqlBulkCopy 的简单封装,让批量插入更方便
一.Sql Server插入方案介绍 关于 SqlServer 批量插入的方式,有三种比较常用的插入方式,Insert.BatchInsert.SqlBulkCopy,下面我们对比以下三种方案的速度 ...
- java连接mysql批量写入数据
1.采用公认的MYSQL最快批量提交办法 public void index() throws UnsupportedEncodingException, Exception { //1000个一提交 ...
- Elasticsearch 5.4.3实战--Java API调用:批量写入数据
这个其实比较简单,直接上代码. 注意部分逻辑可以换成你自己的逻辑 package com.cs99lzzs.elasticsearch.service.imp; import java.sql.Tim ...
- 使用bulkload向hbase中批量写入数据
1.数据样式 写入之前,需要整理以下数据的格式,之后将数据保存到hdfs中,本例使用的样式如下(用tab分开): row1 N row2 M row3 B row4 V row5 N row6 M r ...
- python elasticsearch 批量写入数据
from elasticsearch import Elasticsearch from elasticsearch import helpers import pymysql import time ...
- Shell脚本:向磁盘中批量写入数据
一.关于本文 工作要做的监控系统需要监控磁盘空间的使用率并报警.在测试这个功能的时候需要模拟两个场景:一是磁盘空间不断增长超过设定的阈值时,需要触发报警机制:二是磁盘空间降落到低于报警阈值的时候,不再 ...
随机推荐
- Linux搭建kafka
一.安装Java 1.查看linux 的系统版本 root@aliyun:~# uname --m x86_64 2.安装java mkdir -p /usr/local/java tar -xf j ...
- Geometric Search
几何搜索 平衡搜索树(BST)在几何方面的应用,处理的内容变成几何对象,像点,矩形. 1d range search 先来看一维的情况,一维的范围搜索是后面的基础,处理的对象是在一条线上的点.这是符号 ...
- 复杂json的解析:jsonobject与jsonArray的使用
String parameter = { success : 0, errorMsg : "错误消息", data : { total : "总记录数", ro ...
- 【Alpha 冲刺】8/12
今日任务总结 人员 今日原定任务 完成情况 遇到问题 贡献值 胡武成 完善API文档,并初步使用SpringMVC产生编写部分API 未完成 白天有事外出,晚上因为jdk版本过高,配置SpringMV ...
- 团队作业——Alpha冲刺 8/12
团队作业--Alpha冲刺 冲刺任务安排 杨光海天 今日任务:将编辑界面与其中字体设置的弹窗合并,学习Android控件交互. 明日任务:希望完成编辑界面所有接口交互的功能. 郭剑南 今日任务:使用P ...
- 《python源代码剖析》笔记 python环境初始化
版权声明:本文为博主原创文章.未经博主同意不得转载. https://blog.csdn.net/zhsenl/article/details/33747209 本文为senlie原创.转载请保留此地 ...
- Volley源码分析(一)RequestQueue分析
Volley源码分析 虽然在2017年,volley已经是一个逐渐被淘汰的框架,但其代码短小精悍,网络架构设计巧妙,还是有很多值得学习的地方. 第一篇文章,分析了请求队列的代码,请求队列也是我们使用V ...
- mysql常用备份命令和shell备份脚本
备份多个数据库可以使用如下命令:mysqldump -uroot -p123456 --databases test1 test2 test3 > /home/test/dump.sql; 恢复 ...
- CentOS中安装Azkaban 2.5
必备软件 yum install git -y 单机安装步骤 git clone https://github.com/azkaban/azkaban.git cd azkaban; ./gradle ...
- jQuery封装自定义事件--valuechange(动态的监听input,textarea)之前值,之后值的变化
jQuery封装自定义事件--valuechange(动态的监听input,textarea)之前值,之后值的变化 js监听输入框值的即时变化 网上有很多关于 onpropertychange.oni ...