EAST 自然场景文本检测
刚好看到国内的旷视今年在CVPR2017的一篇文章:EAST: An Efficient and Accurate Scene Text Detector。而且有开放的代码,学习和测试了下。
题目说的是比较高效,它的高效主要体现在对一些过程的消除,其架构就是下图中对应的E部分,跟上面的比起来的确少了比较多的过程。这与去年经典的CTPN架构类似。不过CTPN只支持水平方向,而EAST在论文中指出是可以支持多方向文本的定位的。
对于长文本效果不好。

优势:
提供了方向信息,可以检测各个方向的文本
缺点:
对较长的文本检测效果不好,感受野不够长
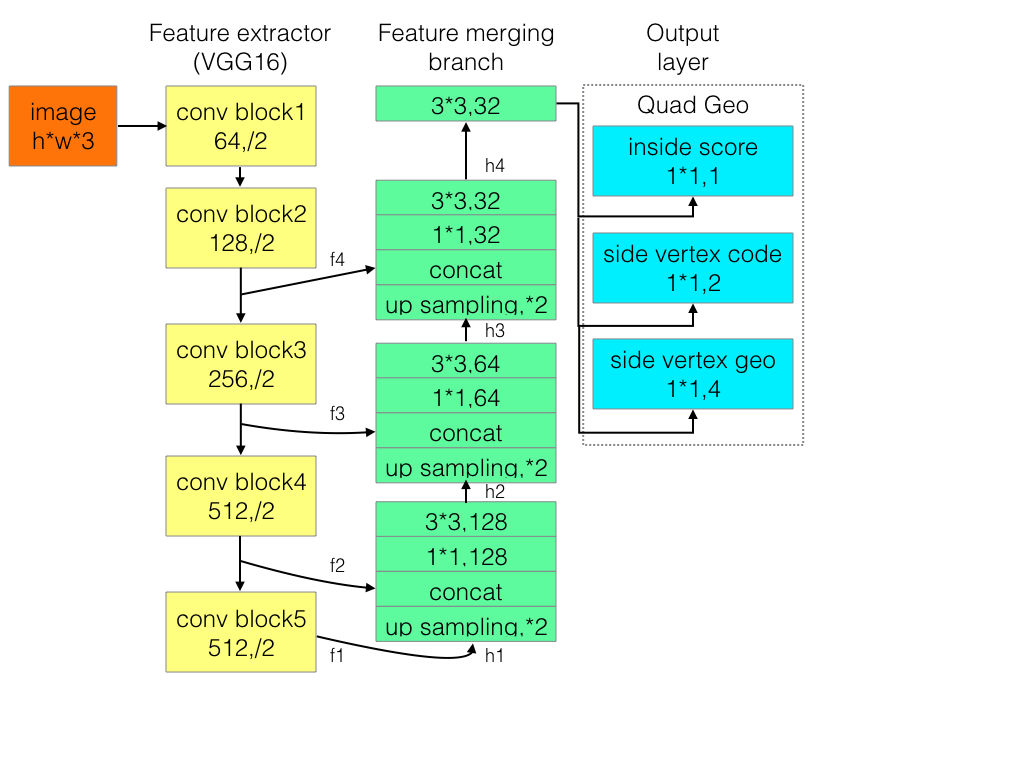
整体网络结构分为3个部分
(1) 特征提取层:
使用的基础网络结构是PVANet,分别从stage1,stage2,stage3,stage4抽出特征,一种FPN(feature pyramid network)的思想。
(2) 特征融合层:
第一步抽出的特征层从后向前做上采样,然后concat
(3) 输出层:
输出一个score map和4个回归的框+1个角度信息,或者输出,一个scoremap和8个坐标信息。
由于程序实现使用的基础网络不是pvanet网络,而是resnet50-v1。
在caffe版本的resnet50实现中,只有第一个卷积后面的pooling和最后一层的gloabl pooling,详细结构见reference,网络通过卷积层的stride=2操作实现类似pooling的效果
而本程序使用的slim中带的resnet50包含了5个pooling。
Resnet50结构,最后一个featuremap本质上将输入图像缩小16倍(4个pooling),最后一个gloabl pooling,类似于vgg中的全连接。gloabl pooling是googlenet和Resnet的专利。
本文网络结构主要取了pool2,pool3,pool4,pool5,的featuremap引出,分别进行uppooling,concat,conv操作,得到最终的featuremap,然后进行卷积,分别输出channel=1的F_score
,channel=4的geo_map,channel=1的angle_map。
标签生成过程:
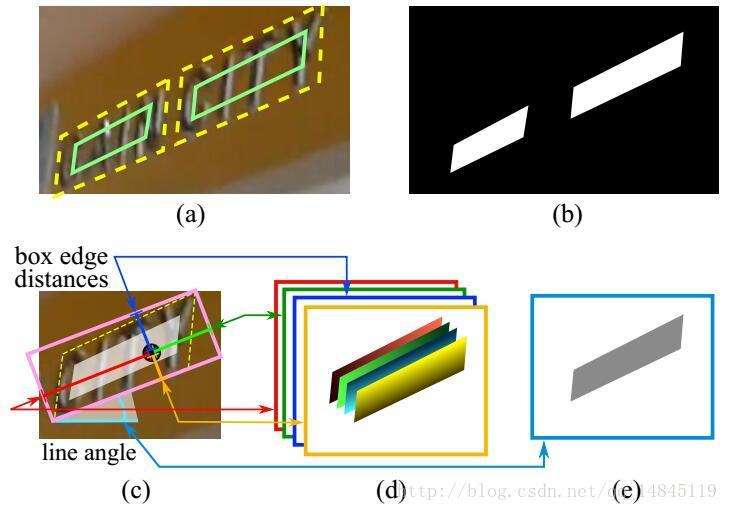
(a) 中黄色的为人工标注的框,绿色为对黄色框进行0.3倍边长的缩放后的框,这样做可以进一步去除人工标注的误差,拿到更准确的label信息。
(b) 为根据(a)中绿色框生成的label信息
(c) 中先生成一个(b)中白色区域的最小外接矩,然后算每一个(b)中白色的点到粉色最小外接矩的上下左右边的距离,即生成(d),然后生成粉色的矩形和水平方向的夹角,即生成角度信息(e),e中所有灰色部分的角度信息一样,都是同样的角度。
论文采用的架构如下:

后来,有大佬改进EAST针对长文本检测效果不好的缺陷,提出advancedEAST,结构如下:
开源源码:https://github.com/huoyijie/AdvancedEAST
仅为学习记录,侵删,感谢作者。
EAST 自然场景文本检测的更多相关文章
- 【OCR技术系列之五】自然场景文本检测技术综述(CTPN, SegLink, EAST)
文字识别分为两个具体步骤:文字的检测和文字的识别,两者缺一不可,尤其是文字检测,是识别的前提条件,若文字都找不到,那何谈文字识别.今天我们首先来谈一下当今流行的文字检测技术有哪些. 文本检测不是一件简 ...
- Scene Text Detection(场景文本检测)论文思路总结
任意角度的场景文本检测论文思路总结共同点:重新添加分支的创新更突出场景文本检测基于分割的检测方法 spcnet(mask_rcnn+tcm+rescore) psenet(渐进扩展) mask tex ...
- 使用Keras基于AdvancedEAST的场景图像文本检测
Blog:https://blog.csdn.net/linchuhai/article/details/84677249 GitHub:https://github.com/huoyijie/Adv ...
- OCR场景文本识别:文字检测+文字识别
一. 应用背景 OCR(Optical Character Recognition)文字识别技术的应用领域主要包括:证件识别.车牌识别.智慧医疗.pdf文档转换为Word.拍照识别.截图识别.网络图片 ...
- Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel Aggregation Network(利用像素聚合网络进行高效准确的任意形状文本检测)
PSENet V2昨日刚出,今天翻译学习一下. 场景文本检测是场景文本阅读系统的重要一步,随着卷积神经网络的快速发展,场景文字检测也取得了巨大的进步.尽管如此,仍存在两个主要挑战,它们阻碍文字检测部署 ...
- CVPR2020论文解读:OCR场景文本识别
CVPR2020论文解读:OCR场景文本识别 ABCNet: Real-time Scene Text Spotting with Adaptive Bezier-Curve Network∗ 论文 ...
- OpenCV_contrib里的Text(自然场景图像中的文本检测与识别)
平台:win10 x64 +VS 2015专业版 +opencv-3.x.+CMake 待解决!!!Issue说明:最近做一些字符识别的事情,想试一下opencv_contrib里的Text(自然场景 ...
- 应用笔画宽度变换(SWT)来检测自然场景中的文本
Introduction: 应用背景:是盲人辅助系统,城市环境中的机器导航等计算机视觉系统应用的重要一步.获取文本能够为许多视觉任务提供上下文的线索,并且,图像检索算法的性能很大部分都依赖于对应的文本 ...
- 使用Python基于VGG/CTPN/CRNN的自然场景文字方向检测/区域检测/不定长OCR识别
GitHub:https://github.com/pengcao/chinese_ocr https://github.com/xiaofengShi/CHINESE-OCR |-angle 基于V ...
随机推荐
- Low-cost ADC using only Digital I/O
http://letsmakerobots.com/node/13843 Reading A Sensor With Higher Accuracy – RC Timing Method RC Tim ...
- IDA64 Fatal error before kernel init
http://www.tuicool.com/articles/7FZVZna 第一次看到这个错误还以为是修改文件导致的,但是觉得又不大像,因为在Win7底下是完全正常的.搜索了一下才发现是由于插件导 ...
- XmlReader/XmlWriter 类
XmlReader用于读取Xml文件,XmlWriter用于将数据写到Xml文件.其实,在印象当中,XML很多的操作类都支持直接Save.Read也支持接受XmlReader与XmlWriter类的示 ...
- 用CSS3来代替JS实现交互
[CSS3和JS] 对于CSS了解的同学都知道,CSS的实现是最底层的,在实现方式和性能上都不是,JS这种提供接口的脚本可比的:从CSS3的动画和JS动画对比角度来看两者,会更清晰:而且随着前端框架的 ...
- 《C++反汇编与逆向分析技术揭秘》之十——析构函数
局部对象 当对象所在作用域结束之后,销毁栈空间,此时析构函数被调用. 举例: 函数返回时自动调用析构函数: 堆对象 调用析构代理函数来处理析构函数: 为什么使用析构代理函数来调用析构函数?考虑到如果d ...
- 全负荷的 Node.js[转载]
一个Node.JS 的进程只会运行在单个的物理核心上,就是因为这一点,在开发可扩展的服务器的时候就需要格外的注意. 因为有一系列稳定的API,加上原生扩展的开发来管理进程,所以有很多不同的方法来设计一 ...
- 数学图形(2.15)Spherical sinusoid球面正弦曲线
这个曲线与之前的数学图形(2.7)sphere sine wave很相似.而且个人觉得从其公式上看sphere sine wave更应该叫做球面正弦曲线.当然从渲染的曲线图上看,它是非常明显的贴在球上 ...
- 【Python】Django RestFramework资料
A ReSTful API is becoming a standard component of any modern web application. The Django Rest Frame ...
- XMPPFrameWork IOS 开发(四)消息和好友上下线
原始地址:XMPPFrameWork IOS 开发(四) 消息 //收到消息 - (void)xmppStream:(XMPPStream *)sender didReceiveMessage:(XM ...
- [Functional Programming] Async IO Functor
We will see a peculiar example of a pure function. This function contained a side-effect, but we dub ...