在centos7上安装部署hadoop2.7.3和spark2.0.0
一、安装装备
下载安装包:
vmware workstations pro 12
三台centos7.1 mini 虚拟机
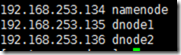
网络配置NAT网络如下:
二、创建hadoop用户和hadoop用户组
1. groupadd hadoop
2. useradd hadoop
3. 给hadoop用户设置密码
在root用户下:passwd hadoop设置新密码
三、关闭防火墙和selinux
1. yum install -y firewalld
2. systemctl stop firewalld
3. systemctl disable firewalld
4. vi /etc/selinux/config
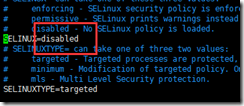
5.全部设置好重启虚拟机
四、三台虚拟机之间ssh互通
1. 在hadoop用户下
1. ssh-keygen -t rsa
2. ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub hadoop@虚拟机ip
3. ssh namenode/dnode1/dnode2
五、安装Java
1. 官网下载jdk1.8.rpm包
2. rpm -ivh jdk1.8.rpm
六、安装hadoop
1. 官网下载hadoop2.7.3.tar.gz
2. tar xzvf hadoop2.7.3.tar.gz
3. mv hadoop2.7.3 /usr/local/
4. chown -R hadoop:hadoop /usr/local/hadoop-2.7.3
七、环境变量配置
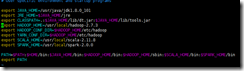
1.vim /home/hadoop/.bash_profile
source /home/hadoop/.bash_profile
export JAVA_HOME=/usr/java/jdk1.8.0_101export JRE_HOME=$JAVA_HOME/jreexport CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarexport HADOOP_HOME=/usr/local/hadoop-2.7.3export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoopexport YARN_CONF_DIR=$HADOOP_HOME/etc/hadoopexport SCALA_HOME=/usr/local/scala-2.11.8export SPARK_HOME=/usr/local/spark-2.0.0PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SCALA_HOME/bin:$SPARK_HOME/binexport PATH
八、建立hadoop相关目录
mkdir -p /home/hadoop/hd_space/tmpmkdir -p /home/hadoop/hd_space/hdfs/namemkdir -p /home/hadoop/hd_space/hdfs/datamkdir -p /home/hadoop/hd_space/mapred/localmkdir -p /home/hadoop/hd_space/mapred/systemchown -R hadoop:hadoop /home/hadoop
注意:至此,可以克隆虚拟机,不必每台都安装centos,克隆之后再建立互通
九、配置hadoop
1. 配置core-site.xml
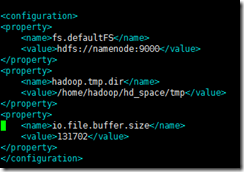
vim /usr/local/hadoop-2.7.3/etc/hadoop/core-site.xml
<configuration><property><name>fs.defaultFS</name><value>hdfs://namenode:9000</value></property><property><name>hadoop.tmp.dir</name><value>/home/hadoop/hd_space/tmp</value></property><property><name>io.file.buffer.size</name><value>131702</value></property></configuration>
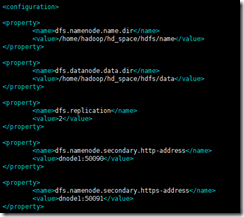
2. 配置hdfs-site.xml
<property><name>dfs.namenode.name.dir</name><value>/home/hadoop/hd_space/hdfs/name</value>?</property><property><name>dfs.datanode.data.dir</name><value>/home/hadoop/hd_space/hdfs/data</value></property><property><name>dfs.replication</name><value>2</value></property><property><name>dfs.namenode.secondary.http-address</name><value>dnode1:50090</value></property><property><name>dfs.namenode.secondary.https-address</name><value>dnode1:50091</value></property>
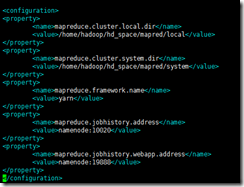
3. 配置mapred-site.xml
<configuration><property><name>mapreduce.cluster.local.dir</name><value>/home/hadoop/hd_space/mapred/local</value></property><property><name>mapreduce.cluster.system.dir</name><value>/home/hadoop/hd_space/mapred/system</value></property><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>namenode:10020</value></property>?<property><name>mapreduce.jobhistory.webapp.address</name><value>namenode:19888</value></property>?</configuration>
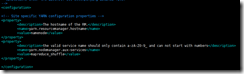
4.配置yarn-site.xml
<configuration><!-- Site specific YARN configuration properties --><property><description>The?hostname?of?the?RM.</description><name>yarn.resourcemanager.hostname</name><value>namenode</value></property><property><description>the?valid?service?name?should?only?contain?a-zA-Z0-9_?and?can?not?start?with?numbers</description><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>?</configuration>
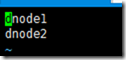
5. 配置slaves,两个数据节点dnode1,dnode2
6. 拷贝配置文件目录到另外两台数据节点
for target in dnode1 dnode2 doscp -r /usr/local/hadoop-2.7.3/etc/hadoop $target:/usr/local/hadoop-2.7.3/etcdone
十、启动hadoop
1. 用户登陆hadoop
2. 格式化hdfs
hdfs namenode -format
3. 启动dfs
start-dfs.sh
4. 启动yarn
start-yarn.sh
十一、错误解决
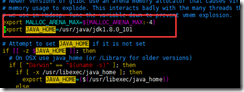
1. 出现以下环境变量JAVA_HOME找不到。
解决办法:需要重新配置/usr/local/hadoop-2.7.3/libexec/hadoop-config.sh

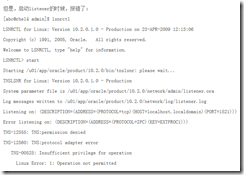
2. oracle数据出现以下错误解决
TNS-12555: TNS:permission denied,监听器启动不了 lsnrctl start(启动)/status(查看状态)/stop(停止)
解决办法:chown -R hadoop:hadoop /var/tmp/.oracle
chmod 777 /var/tmp/.oracle

问题:
十二、客户端验证
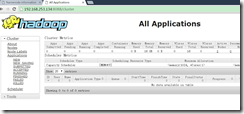
1. jps检查进程
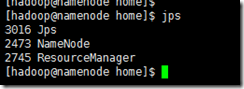
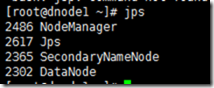
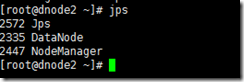
至此,hadoop已经安装完毕
十三、测试hadoop,hadoop用户登陆
运行hadoop自带的wordcount实例
1. 建立输入文件
mkdir -p -m 755 /home/hadoop/test
cd /home/hadoop/test
echo "My first hadoop example. Hello Hadoop in input. " > testfile.txt
2. 建立目录
hadoop fs -mkdir /test
#hadoop fs -rmr /test 删除目录
3. 上传文件
hadoop fs -put testfile.txt /test
4. 执行wordcount程序
hadoop jar /usr/local/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /test/testfile.txt /test/output
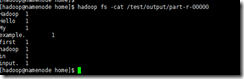
5. 查看结果
hadoop fs -cat /test/output/part-r-00000
十四、安装Spark2.0.0
1. 解压scala-2.11.8.tar.gz到/usr/local
tar xzvf scala-2.11.8
mv scala-2.11.8 /usr/local
2. 解压spark-2.0..0.tgz 到/usr/local
tar xzvf spark-2.0.0.tar.gz
mv spark-2.0.0 /usr/local
3.配置spark
cd /usr/local/spark-2.0.0/conf
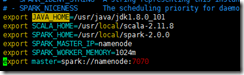
vim spark-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_101export SCALA_HOME=/usr/local/scala-2.11.8export SPARK_HOME=/usr/local/spark-2.0.0export SPARK_MASTER_IP=namenodeexport SPARK_WORKER_MEMORY=1024mexport master=spark://namenode:7070
vim slaves

同步资源及配置文件到其它两个节点(hadoop用户)
for target in dnode1 dnode2 doscp -r /usr/local/scala-2.11.8 $target:/usr/localscp -r /usr/local/spark-2.0.0 $target:/usr/localdone
4.启动spark集群
cd $SPARK_HOME
# Start Master
./sbin/start-master.sh
# Start Workers
./sbin/start-slaves.sh
5.客户端验证


在centos7上安装部署hadoop2.7.3和spark2.0.0的更多相关文章
- Docker(2)--Centos7 上安装部署
Centos7 上安装docker Docker从1.13版本之后采用时间线的方式作为版本号,分为社区版CE和企业版EE. 社区版是免费提供给个人开发者和小型团体使用的,企业版会提供额外的收费服务,比 ...
- Centos7.5安装分布式Hadoop2.6.0+Hbase+Hive(CDH5.14.2离线安装tar包)
Tags: Hadoop Centos7.5安装分布式Hadoop2.6.0+Hbase+Hive(CDH5.14.2离线安装tar包) Centos7.5安装分布式Hadoop2.6.0+Hbase ...
- 在Centos7上安装漏洞扫描软件Nessus
本文摘要:简单叙述了在Centos7上安装Nessus扫描器的过程 Nessus 是目前全世界最多人使用的系统漏洞扫描与分析软件,Nessus的用户界面是基于Web界面来访问Nessus漏洞扫描器 ...
- CentOS7.4安装部署openstack [Liberty版] (二)
继上一篇博客CentOS7.4安装部署openstack [Liberty版] (一),本篇继续讲述后续部分的内容 一.添加块设备存储服务 1.服务简述: OpenStack块存储服务为实例提供块存储 ...
- CentOS7.4安装部署openstack [Liberty版] (一)
一.OpenStack简介 OpenStack是一个由NASA(美国国家航空航天局)和Rackspace合作研发并发起的,以Apache许可证授权的自由软件和开放源代码项目. OpenStack是一个 ...
- centos7.8 安装部署 k8s 集群
centos7.8 安装部署 k8s 集群 目录 centos7.8 安装部署 k8s 集群 环境说明 Docker 安装 k8s 安装准备工作 Master 节点安装 k8s 版本查看 安装 kub ...
- 怎么在linux上安装部署jenkins
怎么在linux上安装部署jenkins 作为一个非科班出身自学的小白,踩过很多的坑,特此留下记录 以下在虚拟机上示例 系统:linux(centos7) 操作方式:xshell连接终端操作 教程之前 ...
- 在centos7上安装Jenkins
在centos7上安装Jenkins 安装 添加yum repos,然后安装 sudo wget -O /etc/yum.repos.d/jenkins.repo http://pkg.jenkins ...
- 在 CentOS7 上安装 zookeeper-3.4.9 服务
在 CentOS7 上安装 zookeeper-3.4.9 服务 1.创建 /usr/local/services/zookeeper 文件夹: mkdir -p /usr/local/service ...
随机推荐
- js当前页面刷新并且清空文本内容的方法
js当前页面刷新并且清空文本内容的方法: 1.js代码:location.reload(); 2.html:<body onload="document.forms[0].reset( ...
- 挂载xfs磁盘
# 磁盘初始化 [root@localhost ~]# fdisk /dev/sdb Welcome to fdisk (util-linux 2.23.2). Changes will remain ...
- 对Numpy数组按axis运算的理解
Python的Numpy数组运算中,有时会出现按axis进行运算的情况,如 >>> x = np.array([[1, 1], [2, 2]]) >>> x arr ...
- PAT 1115 Counting Nodes in a BST[构建BST]
1115 Counting Nodes in a BST(30 分) A Binary Search Tree (BST) is recursively defined as a binary tre ...
- django xadmin的全局配置
在adminx.py中增加 class BaseSetting(object): enable_themes = True use_bootswatch = True class GlobalSett ...
- MySQL 参数
I see a lot of people filtering replication with binlog-do-db, binlog-ignore-db, replicate-do-db, an ...
- 1、初识JavaScript
前端之 JavaScript 1.存在方式. <!-- 导入javascript脚本方法 --><script type="text/javascript" sr ...
- java实现FTP下载文件
ftp上传下载文件,是遵照ftp协议上传下载文件的,本例仅以下载文件为例. 重要的方法解释: 1.FTP功能相关依赖路径:org.apache.commons.net.ftp.*: 2.ftp默认端口 ...
- Git-基本操作(同SVN)
本人拜读了廖雪峰老师关于Git的讲述后整理所得 1.创建版本库: 版本库又名仓库,英文名repository,你可以简单理解成一个目录,这个目录里面的所有文件都可以被Git管理起来,每个文件的修改.删 ...
- PL/SQL编程—函数
SQL> select * from mytest; ID NAME PASSWD SALARY ----- -------------------- -------------------- ...