python学习(十七) 爬取MM图片
这一篇巩固前几篇文章的学到的技术,利用urllib库爬取美女图片,其中采用了多线程,文件读写,目录匹配,正则表达式解析,字符串拼接等知识,这些都是前文提到的,综合运用一下,写个爬虫
示例爬取美女图片。
先定义几个匹配规则和User_Agent
1 |
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0' |
读者可以根据不同网站的代码去修改这些规则,达到匹配一些网站的目的。
1定义抓图类
1 |
class GetMMPic(object): |
初始化构造函数中设置了路径和网络地址,以及请求的user_agent。
2封装信息请求和读取函数
1 |
def requestData(self,url, user_agent): |
这个函数功能主要是请求url网络地址,加上user_agent后,获取数据,并且采用utf-8
编码方式解析。
3封装创建目录函数
1 |
def makedir(self,dirname): |
该函数主要是完成在GMMPic类配置的路径下(默认是./),生成子目录,子目录的名字由
参数决定。简单地说就是要在当前目录下生成文件名对应的文件夹,保存不同的图片。
4 获取当前页面信息保存图片
1 |
def getPageData(self,httpstr): |
getPageData()函数根据PATTERN2匹配页面符合条件的图片资源,根据PATTERN5取出图片名字(不含类型),
通过for循环一个一个保存。
运行程序,提示输入网址,
这里输入男人装某篇文章的地址,效果如下:
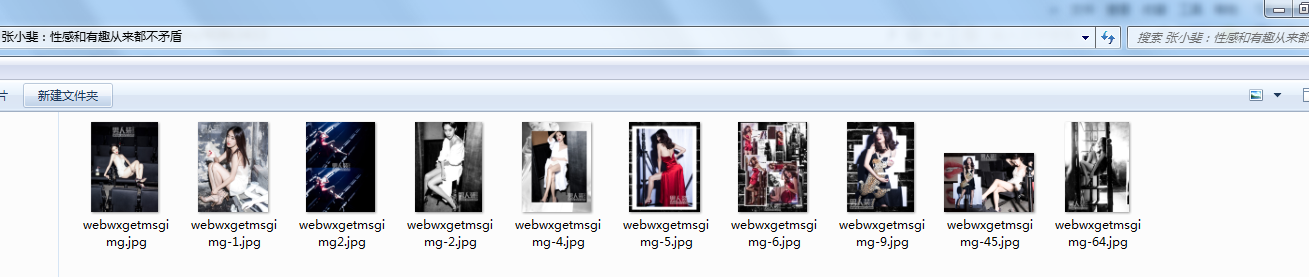
5 采用多线程提高并发能力
编写线程回调函数 workthread, 每个线程去爬不同的文章
1 |
def workthread(item, user_agent,path): |
开辟多个线程,去爬首页各个分栏,实现自动化抓图
1 |
def getDetailList(self,content): |
源码下载地址:
https://github.com/secondtonone1/python-
谢谢关注我的公众号:

python学习(十七) 爬取MM图片的更多相关文章
- Python爬虫学习(6): 爬取MM图片
为了有趣我们今天就主要去爬取以下MM的图片,并将其按名保存在本地.要爬取的网站为: 大秀台模特网 1. 分析网站 进入官网后我们发现有很多分类: 而我们要爬取的模特中的女模内容,点进入之后其网址为:h ...
- 百度图片爬虫-python版-如何爬取百度图片?
上一篇我写了如何爬取百度网盘的爬虫,在这里还是重温一下,把链接附上: http://www.cnblogs.com/huangxie/p/5473273.html 这一篇我想写写如何爬取百度图片的爬虫 ...
- [Python学习] 简单爬取CSDN下载资源信息
这是一篇Python爬取CSDN下载资源信息的样例,主要是通过urllib2获取CSDN某个人全部资源的资源URL.资源名称.下载次数.分数等信息.写这篇文章的原因是我想获取自己的资源全部的评论信息. ...
- python学习之——爬取网页信息
爬取网页信息 说明:正则表达式有待学习,之后完善此功能 #encoding=utf-8 import urllib import re import os #获取网络数据到指定文件 def getHt ...
- python爬虫之爬取百度图片
##author:wuhao##爬取指定页码的图片,如果需要爬取某一类的所有图片,整体框架不变,但需要另作分析#import urllib.requestimport urllib.parseimpo ...
- Python 学习笔记---爬取海贼王动漫
最近无聊整理的爬虫代码,可以自动爬取腾讯动漫的任意漫画,思路如下: 1. 先获取想下载的动漫url, 这里用了 getUrls ,直接获取动漫的最后一章 2. 然后进入到该动漫去获取要下载的图片url ...
- Python多线程爬虫爬取网页图片
临近期末考试,但是根本不想复习!啊啊啊啊啊啊啊!!!! 于是做了一个爬虫,网址为 https://yande.re,网页图片为动漫美图(图片带点颜色........宅男福利 github项目地址为:h ...
- [python] 常用正则表达式爬取网页信息及分析HTML标签总结【转】
[python] 常用正则表达式爬取网页信息及分析HTML标签总结 转http://blog.csdn.net/Eastmount/article/details/51082253 标签: pytho ...
- python 3 爬取百度图片
python 3 爬取百度图片 学习了:https://blog.csdn.net/X_JS612/article/details/78149627
随机推荐
- 【BUG】12小时制和24小时制获取当天零点问题
[BUG]12小时制和24小时制获取当天零点问题 最近在写定时服务的时候,要获取当天的零点这个时间,但是是这样获取的 DateTime dt = DateTime.Parse(DateTime.Now ...
- hdu - 6281,2018CCPC湖南全国邀请赛F题,快排
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=6281 题意: 根据已给出的式子,进行排序,然后输出排完序后原先的下表. 题解:用结构体保存,在用结构体 ...
- JAVA学习笔记--组合与继承
JAVA一个很重要的功能就是代码的可复用性,代码复用可以大大提升编程效率.这里主要介绍两种代码复用方式:组合和继承. 一.组合 组合比较直观,只需在新的类中产生现有类的对象,新的类由现有类的对象组成, ...
- 译 - Cassandra 数据建模的基本规则
Basic Rules of Cassandra Data Modeling 原文地址:http://www.datastax.com/dev/blog/basic-rules-of-cassandr ...
- Centos7 Zabbix监控部署
Zabbix监控 官方文档 https://www.zabbix.com/documentation/3.4/zh/manual https://www.zabbix.com/documentatio ...
- 经验之谈:10位顶级PHP大师的开发原则
导读:在Web开发世界里,PHP是最流行的语言之一,从PHP里,你能够很容易的找到你所需的脚本,遗憾的是,很少人会去用“最佳做法”去写一个PHP程序.这里,我们向大家介绍PHP的10种最佳实践,当然, ...
- 团队项目成员与题目(本地地铁查询app)
团队名称:Daydreaming团队成员及其特点:张运涛:能快速与团队成员中的每一位进行合作,能全面考虑遇到的问题,善于总结积累.能较好的理解老师与其他人员的想法要求.刘瑞欣:做事果断,善于领导,有想 ...
- struts通配符*的使用
<action name="user_*" class="com.wangcf.UserAction" method="{1}"> ...
- OpenCV学习笔记——imread、imwrite以及imshow
1.imread Loads an image from a file. 从文件中读取图像. C++: Mat imread(const string& filename, int flags ...
- Spring学习(六)—— Spring注解(二)
核心原理 1. 用户发送请求给服务器.url:user.do 2. 服务器收到请求.发现Dispatchservlet可以处理.于是调用DispatchServlet. 3. ...