论文阅读 | FoveaBox: Beyond Anchor-based Object Detector
论文阅读——FoveaBox: Beyond Anchor-based Object Detector
概述
这是一篇ArXiv 2019的文章,作者提出了一种新的anchor-free的目标检测框架FoveaBox,直接学习目标存在的可能性(预测类别敏感的语义map)和bbox的坐标(为可能存在目标的每个位置生成无类别的bbox)。该算法的单模型(基于ResNeXt-101-FPN )在COCO数据集上的AP达到42.1%。代码尚未开源。
介绍
anchor弊端:额外的超参数设计很复杂;设计的anchor泛化能力差;密集的anchor采样使得正负样本严重失衡。
受人眼的启发,视觉区域(目标)的中心有着最高的视觉灵敏度。FoveaBox联合预测对象的中心区域可能存在的位置以及每个有效位置的边界框。
FoveaBox
FoveaBox的框架:
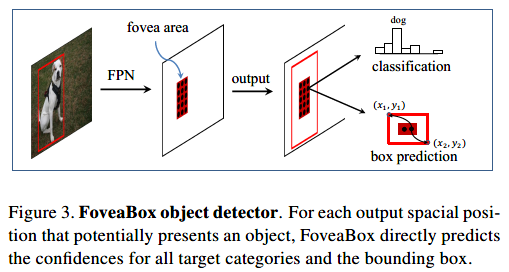
FoveaBox包括一个backbone和两个子网。第一个子网对主干网的输出执行每个像素的分类,第二个子网预测相应位置的bbox。
FPN的使用:
每层金字塔用于检测不同大小的目标,论文中作者设计的金字塔{Pl},其中l=3,4,5,6,7,Pl的分辨率是输入的1/2^l。金字塔所有层的通道数都是256。

每层特征金字塔的box的有效尺度范围:
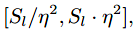

S0取16,η取2.
Object Fovea
从gt box到特征金字塔Pl的映射:
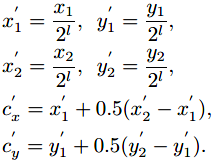
正样本区域(fovea):

正样本区域相比于原始区域有一定程度的缩小。σ1是收缩因子(文中取0.3)。同样使用上面的公式,因子记为σ2(文中取0.4),产生负样本区域。训练时类别损失采用focal loss。
Box Prediction
位置回归则是学习一个变换:

其中z=sqrt(Sl)是归一化因子,将输出空间投影到以1为中心的空间,使学习过程更稳定。函数首先将feature map的坐标(x,y)映射到输入图像,然后计算归一化的偏移,最后正则化到log空间。回归损失采用Smooth L1损失。
优化
4GPUs,SGD,8 imgs/minibatch
训练细节:270k次迭代(180k前:lr=0.005,180k-240k:lr=0.0005,240k后:lr=5e-5)
使用权值衰减(0.0001),momentum(0.9)
ignore区域的location不参与类别训练,但参与回归训练(标注为对应的位置目标)。
推理
置信度阈值:0.05,NMS阈值:0.5,没有使用bbox voting、Soft-NMS、测试阶段图像扩增等策略。
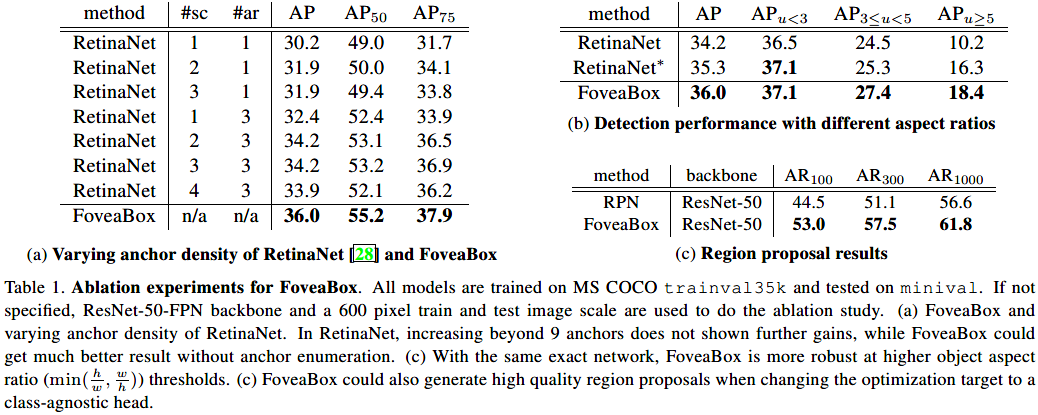
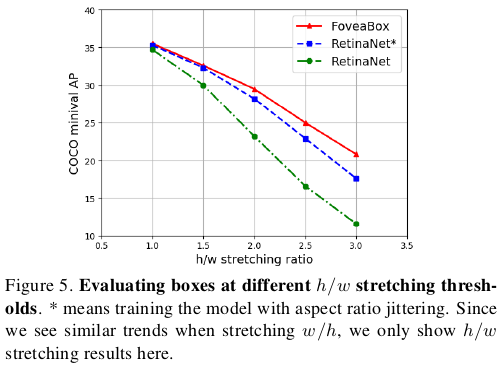
RetinaNet与FoveaBox检测对比:

FoveaBox检测结果:
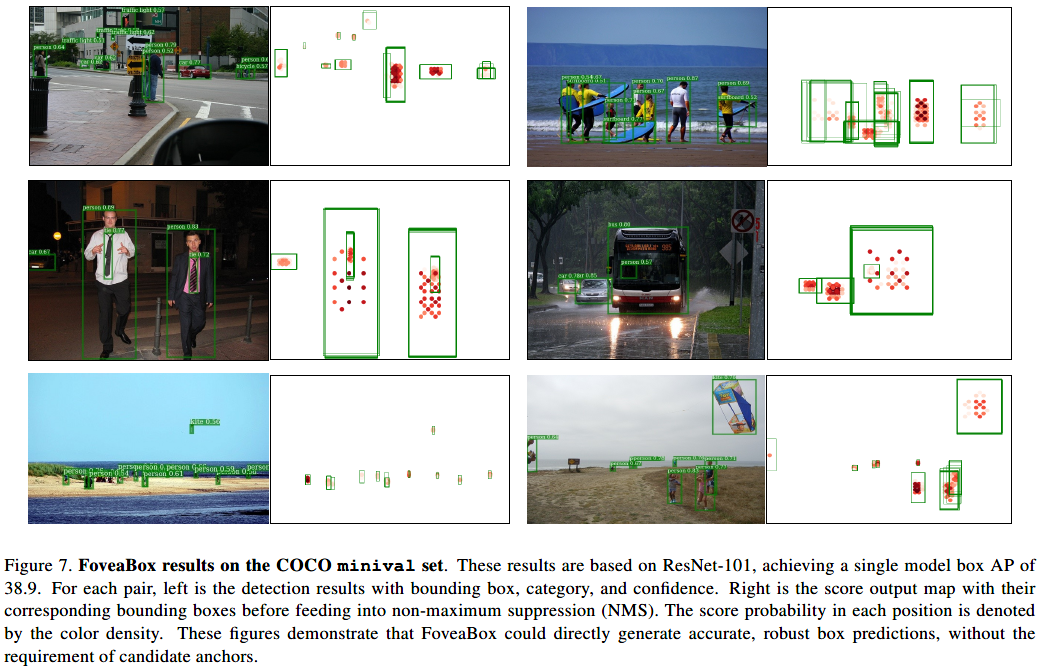
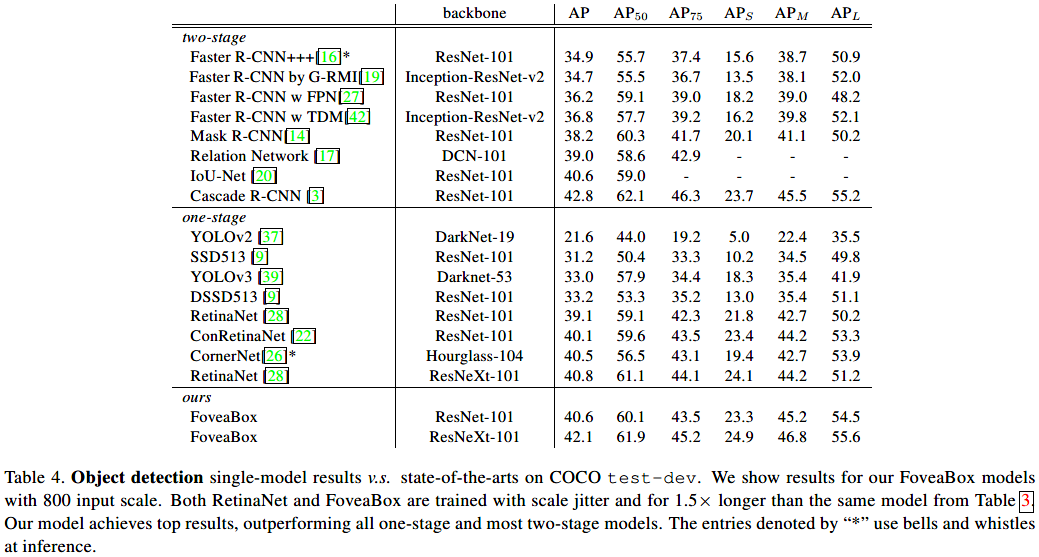
SOTA对比:
与FSAF的对比:
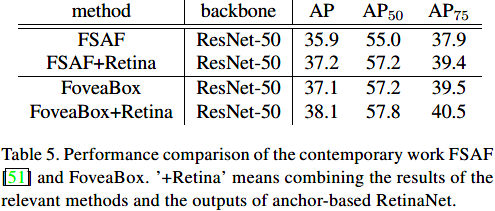
总的来说,这是一篇利用语义分割的思想来做目标检测的文章,通过定义fovea区域(也就是正样本区域)来限制类别学习和预测的大致范围,所以没有出现类似于FCOS算法中远离目标中心的位置会产生大量低置信度bbox的情况。
论文阅读 | FoveaBox: Beyond Anchor-based Object Detector的更多相关文章
- 论文阅读 | FCOS: Fully Convolutional One-Stage Object Detection
论文阅读——FCOS: Fully Convolutional One-Stage Object Detection 概述 目前anchor-free大热,从DenseBoxes到CornerNet. ...
- 论文阅读之 DECOLOR: Moving Object Detection by Detecting Contiguous Outliers in the Low-Rank Representation
DECOLOR: Moving Object Detection by Detecting Contiguous Outliers in the Low-Rank Representation Xia ...
- SSD: Single Shot MultiBox Detector论文阅读摘要
论文链接: https://arxiv.org/pdf/1512.02325.pdf 代码下载: https://github.com/weiliu89/caffe/tree/ssd Abstract ...
- [论文理解] FoveaBox: Beyond Anchor-based Object Detector
FoveaBox: Beyond Anchor-based Object Detector Intro 本文是一篇one-stage anchor free的目标检测文章,大体检测思路为,网络分两路, ...
- 论文阅读:Prominent Object Detection and Recognition: A Saliency-based Pipeline
论文阅读:Prominent Object Detection and Recognition: A Saliency-based Pipeline 如上图所示,本文旨在解决一个问题:给定一张图像, ...
- YOLO: You Only Look Once论文阅读摘要
论文链接: https://arxiv.org/pdf/1506.02640.pdf 代码下载: https://github.com/gliese581gg/YOLO_tensorflow Abst ...
- YOLO 论文阅读
YOLO(You Only Look Once)是一个流行的目标检测方法,和Faster RCNN等state of the art方法比起来,主打检测速度快.截止到目前为止(2017年2月初),YO ...
- 新文预览 | IoU-aware Single-stage Object Detector for Accurate Localization
论文基于RetinaNet提出了IoU-aware sinage-stage目标检测算法,该算法在regression branch接入IoU predictor head并通过加权分类置信度和IoU ...
- 论文阅读笔记 Word Embeddings A Survey
论文阅读笔记 Word Embeddings A Survey 收获 Word Embedding 的定义 dense, distributed, fixed-length word vectors, ...
随机推荐
- log4j-over-slf4j工作原理详解
log4j-over-slf4j工作原理详解 摘自:https://blog.csdn.net/john1337/article/details/76152906 置顶 2017年07月26日 17: ...
- centos7用fdisk进行分区
1.查看分区信息:fdisk -l 从上面可以看到,/dev/sdb分区还没有使用,现在将其划分成2个10G的分区. 2.执行:fdisk /dev/sdb 1):fdisk命令参数 p:打印分区表. ...
- 搜狐 WEB 标准-前端技术应用规范
- 部分类Partial
Partial告诉编译器,一个类,结构,接口的定义源代码可能要分散到一个或者多个源文件中. 在下面的情况下用Partial类型: (1) 类型特别大,不宜放在一个文件中实现.(2) 一个类型中的一部分 ...
- [转]Linux Swap交换分区、交换文件
free -m 在日常应用中,通过上述命令看到交换空间的使用情况为0,那么你就不需要很大的虚拟内存,甚至可以完全不需要另辟硬盘空间作为虚拟内存.那么,万一有一天你需要了呢,难道要重装系统?大可不必,在 ...
- ScreenCapture-drupal 7.34-ckeditor4x整合教程
1.1. drupal 7x-ckeditor4x 插件下载:Drupal 7x, 1.1.1. 安装ckeditor4x 下载插件 说明:下载并解压 CKEditor4x插件:https://yun ...
- 基于FPGA的XPT2046触摸控制器设计
基于FPGA的XPT2046触摸控制器设计 小梅哥编写,未经许可,文章内容和所涉及代码不得用于其他商业销售的板卡 本实例所涉及代码均可通过向 xiaomeige_fpga@foxmail.com 发 ...
- thinkjs用户请求处理
- Application.DoEvent和定时刷新控件
我们写一个textbox,让其依循环递增,但每次都会出现假死现象,等循环结束后,变为最终值.今天总结一下: private void button3_Click(object sender, Even ...
- DateTime.Now.ToString("yyyy/MM/dd") 时间格式化中的MM为什么是大写的?
如果MM是小写,就表示时间里的分钟yyyy-MM-dd HH:mm:ss (年-月-日 时:分:秒) yyyy-MM-dd HH:mm:ss 年-月-日 时:分:秒大写是为了区分“月”与“分” 顺便说 ...