Apache Flume的介绍安装及简单案例
概述
Flume 是 一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的软件。Flume 的核心是把数据从数据源(source)收集过来,再将收集到的数据送到指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,flume 在删除自己缓存的数据。
Flume 支持定制各类数据发送方,用于收集各类型数据;同时,Flume 支持定制各种数据接受方,用于最终存储数据。一般的采集需求,通过对 flume 的简单配置即可实现。针对特殊场景也具备良好的自定义扩展能力。因此,flume 可以适用于大部分的日常数据采集场景。
运行机制
Flume 系统中核心的角色是 agent,agent 本身是一个 Java 进程,一般运行在日志收集节点。
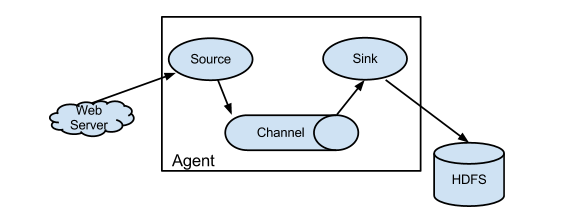
每一个 agent 相当于一个数据传递员,内部有三个组件:
- Source:采集源,用于跟数据源对接,以获取数据;
- Sink:下沉地,采集数据的传送目的,用于往下一级 agent 传递数据或者往最终存储系统传递数据;
- Channel:agent 内部的数据传输通道,用于从 source 将数据传递到 sink;
在整个数据的传输的过程中,流动的是 event,它是 Flume 内部数据传输的最基本单元。event 将传输的数据进行封装。如果是文本文件,通常是一行记录,event 也是事务的基本单位。event 从 source,流向 channel,再到 sink,本身为一个字节数组,并可携带 headers(头信息)信息。event 代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。
一个完整的 event 包括:event headers、event body、event 信息,其中event 信息就是 flume 收集到的日记记录。
Flume 采集系统结构图
简单结构(单个agent采集数据)
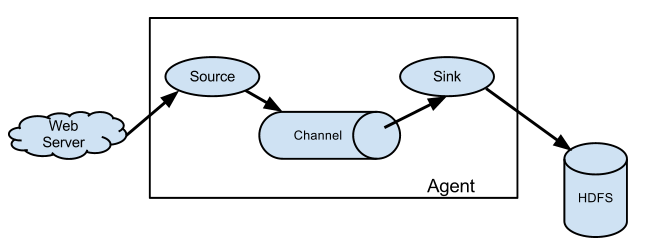
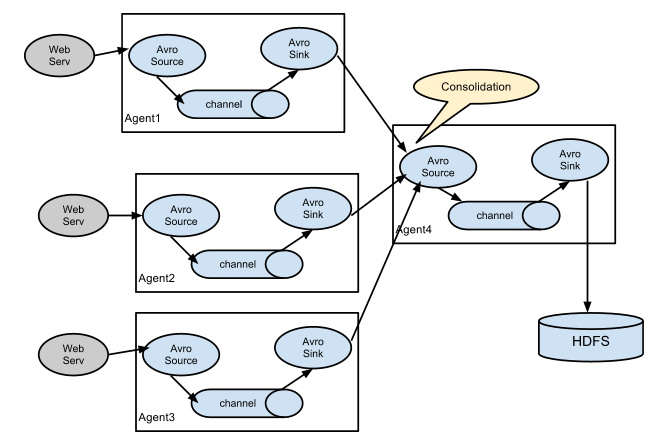
复杂结构(多级agent之间串联)
Flume的安装部署
安装
1,上传安装包到数据源所在节点
2,解压安装包 tar -zxvf apache-flume-xxxx-bin.tar.gz
采集方案部署
1,根据数据采集需求 配置采集方案,描述在conf文件夹 配置文件中(文件名可任意自定义)
2,指定采集方案配置文件,在相应的节点上启动 flume agent
简单方案部署:
1,采集文件目录到HDFS:
需求:服务器的某特定目录下,会不断产生新的文件,每当有新文件出现,就需要把文件采集到 HDFS 中去
根据需求,首先定义以下 3 大要素:
- 采集源,即 source——监控文件目录 : spooldir
- 下沉目标,即 sink——HDFS 文件系统 : hdfs sink
- source 和 sink 之间的传递通道——channel,可用 file channel 也可以用内存 channel
配置文件(spooldir-hdfs.conf)编写:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # Describe/configure the source
##注意:不能往监控目中重复丢同名文件
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /root/logs2
a1.sources.r1.fileHeader = true # Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.rollInterval = 3
a1.sinks.k1.hdfs.rollSize = 20
a1.sinks.k1.hdfs.rollCount = 5
a1.sinks.k1.hdfs.batchSize = 1
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是Sequencefile,可用DataStream,则为普通文本
a1.sinks.k1.hdfs.fileType = DataStream # Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
然后启动
cd /export/servers/flume/
bin/flume-ng agent -c ./conf -f ./conf/spooldir-hdfs.conf -n a1 -Dflume.root.logger=INFO,console
这时,如果这个服务器节点下/root/logs2文件夹内有新文件产生,就会上传到HDFS上去。(当然前提你得启动hadoop的HDFS集群)
2,采集文件到HDFS
需求:比如业务系统使用 log4j 生成的日志,日志内容不断增加,需要把追加到日志文件中的数据实时采集到HDFS
根据需求,首先定义以下 3 大要素
- 采集源,即 source——监控文件内容更新 : exec 'tail -F file'
- 下沉目标,即 sink——HDFS 文件系统 : hdfs sink
- Source 和 sink 之间的传递通道——channel,可用 file channel 也可以用内存 channel
配置文件(tail-hdfs.conf)编写:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /root/logs/test.log
a1.sources.r1.channels = c1 # Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = /flume/tailout/%y-%m-%d/%H-%M/
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.rollInterval = 3
a1.sinks.k1.hdfs.rollSize = 20
a1.sinks.k1.hdfs.rollCount = 5
a1.sinks.k1.hdfs.batchSize = 1
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是Sequencefile,可用DataStream,则为普通文本
a1.sinks.k1.hdfs.fileType = DataStream # Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
然后启动
cd /export/servers/flume/
bin/flume-ng agent -c conf -f conf/tail-hdfs.conf -n a1
参数解析
rollInterval
默认值:30
HDFS sink 间隔多长将临时文件滚动成最终目标文件,单位:秒;
如果设置成 0,则表示不根据时间来滚动文件;
注:滚动(roll)指的是,hdfs sink 将临时文件重命名成最终目标文件,并新打开一个临时文件来写入数据。 rollSize
默认值:1024
当临时文件达到该大小(单位:bytes)时,滚动成目标文件;
如果设置成 0,则表示不根据临时文件大小来滚动文件。 rollCount
默认值:10
当 events 数据达到该数量时候,将临时文件滚动成目标文件;
如果设置成 0,则表示不根据 events 数据来滚动文件。 round
默认值:false
是否启用时间上的“舍弃”,这里的“舍弃”,类似于“四舍五入”。 roundValue
默认值:1
时间上进行“舍弃”的值; roundUnit
默认值:seconds
时间上进行"舍弃"的单位,包含:second,minute,hour
控制文件在hdfs上以何种方式滚动
a1.sinks.k1.hdfs.rollInterval = 3 根据时间间隔滚动 3s
a1.sinks.k1.hdfs.rollSize = 20 根据文件大小滚动
a1.sinks.k1.hdfs.rollCount = 5 根据events数量控制滚动 如果以上三个属性都有值 谁先满足谁触发滚动
若要求只按照某个属性滚动,只要把其他的设置为0
a1.sinks.k1.hdfs.rollInterval = 60
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
------------------------------------------
控制文件夹的滚动方式 如果是舍弃10分钟 意味着 10分钟一个目录
a1.sinks.k1.hdfs.round = true 是否开启时间上的舍弃
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
Apache Flume的介绍安装及简单案例的更多相关文章
- Apache Flume简介及安装部署
概述 Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的软件. Flume 的核心是把数据从数据源(source)收集过来,再将收集到的数据送到指定的目 ...
- Ansible自动化运维之介绍安装与简单使用
参考:http://blog.51cto.com/191226139/2066936 Ansible是什么 Ansible 简单的说是一个配置管理系统(configuration management ...
- Azkaban介绍+安装部署+实战案例
Azkaban介绍 什么是azkaban?1.工作流的作业调度系统2.通过k.v指令写法描述工作流节点3.可以通过web界面去管理工作流 Azkaban安装部署 2.3.1 准备工作 Azkaban ...
- Apache和mysql的安装设置
Apache和mysql的安装较简单,主要是安装前请保证80端口未被占用 比如 iis 以前安装过的apache mysql 先停止运行phpmyadmin,主要是配置文件的问题,把phpMyAdmi ...
- apache ab测试介绍
apache ab测试介绍 安装ab命令 环境为ubuntu16.04.2 LTS,安装的命令为: sudo apt-get install apache2-utils 使用说明 格式为:ab [op ...
- _00019 Storm架构介绍和Storm获取案例(简单的官方网站Java案例)
博文作者:妳那伊抹微笑 itdog8 地址链接 : http://www.itdog8.com(个人链接) 博客地址:http://blog.csdn.net/u012185296 博文标题:_000 ...
- Hadoop入门进阶课程12--Flume介绍、安装与应用案例
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan ...
- 分布式日志收集系统Apache Flume的设计详细介绍
问题导读: 1.Flume传输的数据的基本单位是是什么? 2.Event是什么,流向是怎么样的? 3.Source:完成对日志数据的收集,分成什么打入Channel中? 4.Channel的作用是什么 ...
- {MySQL数据库初识}一 数据库概述 二 MySQL介绍 三 MySQL的下载安装、简单应用及目录介绍 四 root用户密码设置及忘记密码的解决方案 五 修改字符集编码 六 初识sql语句
MySQL数据库初识 MySQL数据库 本节目录 一 数据库概述 二 MySQL介绍 三 MySQL的下载安装.简单应用及目录介绍 四 root用户密码设置及忘记密码的解决方案 五 修改字符集编码 六 ...
随机推荐
- imsl库的使用过程中遇到的问题
1,首先是安装,用的imsl7.0的库,网址:http://www.pipipan.com/file/87076708,里边有破解,但是这个安装文件只能装32位的,装不了64位的. 2,安装后找到lm ...
- Siddhi cep java 集成简单使用
Siddhi 是一个开源的cep (Complex Event Processing)类库,有一个明显的例子是uber 的事件处理,具体可以google 几张参考cep 以及siddhi 图 java ...
- Java变量类型之间的转换
int i; String s="134"; 1)String转换成int i=Integer.parseInt(s); 2)int转换成String(其他类型转String,都可 ...
- springboot各种集成
fastjson 两个方法 @Configuration public class WebMvcConfigurer extends WebMvcConfigurerAdapter { @Overri ...
- MEF学习总结(2)---Primitive层
Primitive层是属于依赖注入的通用模型,主要有如下核心类型: 1. ComposablePart是核心类,他表示组件容器中的每一个组件,是对真正组件实例的包装.ExportDefinition属 ...
- callback&&callback()
如果存在回调函数就执行!这是利用了 JS &&符号的一个小技巧&& 符号在前面为假时就不会执行后面的语句了所以这个就相当于 if(callback){ callback ...
- 【备忘:待完善】nsq集群初体验
本机的一个节点及监控与管理后台 虚拟机中的一个节点 命令: [root@vm-vagrant nsq]# nsqd --lookupd-tcp-address=192.168.23.150:4160 ...
- java代码---------实现File的目录下创建文本文档
总结:虽然他没教给我们很多,但是他已经很棒了 package com.a.b; import java.io.*; public class dd { public static void main( ...
- [转]SQLite 经验集
SQLite 的默认时间 转自:http://www.cnblogs.com/pennant/archive/2011/08/11/2134897.html select strftime('%Y-% ...
- 第二章 伪分布式安装hadoop hbase
安装单机模式的hadoop无须配置,在这种方式下,hadoop被认为是一个单独的java进程,这种方式经常用来调试.所以我们讲下伪分布式安装hadoop. 我们继续上一章继续讲解,安装完先试试SSH装 ...