MiniRBT中文小型预训练模型:结合了全词掩码技术和两段式知识蒸馏技术,加快推理速度
MiniRBT中文小型预训练模型:结合了全词掩码(Whole Word Masking)技术和两段式知识蒸馏(Knowledge Distillation)技术,加快推理速度

在自然语言处理领域中,预训练语言模型(Pre-trained Language Models)已成为非常重要的基础技术。为了进一步促进中文信息处理的研究发展,哈工大讯飞联合实验室(HFL)基于自主研发的知识蒸馏工具TextBrewer,结合了全词掩码(Whole Word Masking)技术和知识蒸馏(Knowledge Distillation)技术推出中文小型预训练模型MiniRBT。
中文LERT | 中英文PERT | 中文MacBERT | 中文ELECTRA | 中文XLNet | 中文BERT | 知识蒸馏工具TextBrewer | 模型裁剪工具TextPruner
1.简介
目前预训练模型存在参数量大,推理时间长,部署难度大的问题,为了减少模型参数及存储空间,加快推理速度,我们推出了实用性强、适用面广的中文小型预训练模型MiniRBT,我们采用了如下技术:
全词掩码技术:全词掩码技术(Whole Word Masking)是预训练阶段的训练样本生成策略。简单来说,原有基于WordPiece的分词方式会把一个完整的词切分成若干个子词,在生成训练样本时,这些被分开的子词会随机被mask(替换成[MASK];保持原词汇;随机替换成另外一个词)。而在WWM中,如果一个完整的词的部分WordPiece子词被mask,则同属该词的其他部分也会被mask。更详细的说明及样例请参考:Chinese-BERT-wwm,本工作中我们使用哈工大LTP作为分词工具。
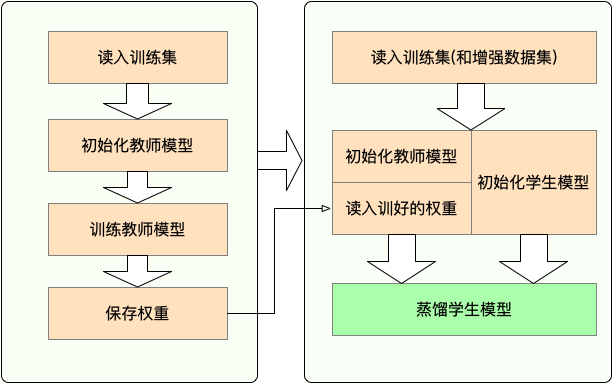
两段式蒸馏:相较于教师模型直接蒸馏到学生模型的传统方法,我们采用中间模型辅助教师模型到学生模型蒸馏的两段式蒸馏方法,即教师模型先蒸馏到助教模型(Teacher Assistant),学生模型通过对助教模型蒸馏得到,以此提升学生模型在下游任务的表现。并在下文中贴出了下游任务上两段式蒸馏与一段式蒸馏的实验对比,结果表明两段式蒸馏能取得相比一段式蒸馏更优的效果。
构建窄而深的学生模型。相较于宽而浅的网络结构,如TinyBERT结构(4层,隐层维数312),我们构建了窄而深的网络结构作为学生模型MiniRBT(6层,隐层维数256和288),实验表明窄而深的结构下游任务表现更优异。
MiniRBT目前有两个分支模型,分别为MiniRBT-H256和MiniRBT-H288,表示隐层维数256和288,均为6层Transformer结构,由两段式蒸馏得到。同时为了方便实验效果对比,我们也提供了TinyBERT结构的RBT4-H312模型下载。
我们会在近期提供完整的技术报告,敬请期待。
2.模型下载
| 模型简称 | 层数 | 隐层大小 | 注意力头 | 参数量 | Google下载 | 百度盘下载 |
|---|---|---|---|---|---|---|
| MiniRBT-h288 | 6 | 288 | 8 | 12.3M | [PyTorch] | [PyTorch] (密码:7313) |
| MiniRBT-h256 | 6 | 256 | 8 | 10.4M | [PyTorch] | [PyTorch] (密码:iy53) |
| RBT4-h312 (TinyBERT同大小) | 4 | 312 | 12 | 11.4M | [PyTorch] | [PyTorch] (密码:ssdw) |
也可以直接通过huggingface官网下载模型(PyTorch & TF2):https://huggingface.co/hfl
下载方法:点击任意需要下载的模型 → 选择"Files and versions"选项卡 → 下载对应的模型文件。
3.快速加载
3.1使用Huggingface-Transformers
依托于transformers库,可轻松调用以上模型。
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained("MODEL_NAME")
model = BertModel.from_pretrained("MODEL_NAME")
注意:本目录中的所有模型均使用BertTokenizer以及BertModel加载,请勿使用RobertaTokenizer/RobertaModel!
对应的MODEL_NAME 如下所示:
| 原模型 | 模型调用名 |
|---|---|
| MiniRBT-H256 | "hfl/minirbt-h256" |
| MiniRBT-H288 | "hfl/minirbt-h288" |
| RBT4-H312 | "hfl/rbt4-h312" |
3.2模型对比
模型结构细节与参数量汇总如下。
| 模型 | 层数 | 隐层大小 | FFN大小 | 注意力头数 | 模型参数量 | 参数量(除去嵌入层) | 加速比 |
|---|---|---|---|---|---|---|---|
| RoBERTa | 12 | 768 | 3072 | 12 | 102.3M (100%) | 85.7M (100%) | 1x |
| RBT6 (KD) | 6 | 768 | 3072 | 12 | 59.76M (58.4%) | 43.14M (50.3%) | 1.7x |
| RBT3 | 3 | 768 | 3072 | 12 | 38.5M (37.6%) | 21.9M (25.6%) | 2.8x |
| RBT4-H312 | 4 | 312 | 1200 | 12 | 11.4M (11.1%) | 4.7M (5.5%) | 6.8x |
| MiniRBT-H256 | 6 | 256 | 1024 | 8 | 10.4M (10.2%) | 4.8M (5.6%) | 6.8x |
| MiniRBT-H288 | 6 | 288 | 1152 | 8 | 12.3M (12.0%) | 6.1M (7.1%) | 5.7x |
括号内参数量百分比以原始base模型(即RoBERTa-wwm-ext)为基准
- RBT的名字是RoBERTa三个音节首字母组成
- RBT3:由RoBERTa-wwm-ext 3层进行初始化继续预训练得到,更详细的说明请参考:Chinese-BERT-wwm 小参数量模型
- RBT6 (KD):助教模型,由RoBERTa-wwm-ext 6层进行初始化,通过对RoBERTa-wwm-ext蒸馏得到
- MiniRBT-*:通过对助教模型RBT6(KD)蒸馏得到
- RBT4-H312: 通过对RoBERTa直接蒸馏得到
3.3蒸馏设置
| 模型 | Batch Size | Training Steps | Learning Rate | Temperature | Teacher |
|---|---|---|---|---|---|
| RBT6 (KD) | 4096 | 100KMAX512 | 4e-4 | 8 | RoBERTa-wwm-ext |
| RBT4-H312 | 4096 | 100KMAX512 | 4e-4 | 8 | RoBERTa-wwm-ext |
| MiniRBT-H256 | 4096 | 100KMAX512 | 4e-4 | 8 | RBT6 (KD) |
| MiniRBT-H288 | 4096 | 100KMAX512 | 4e-4 | 8 | RBT6 (KD) |
3.4中文基线系统效果
为了对比基线效果,我们在以下几个中文数据集上进行了测试。
- CMRC 2018:篇章片段抽取型阅读理解(简体中文)
- DRCD:篇章片段抽取型阅读理解(繁体中文)
- OCNLI:原生中文自然语言推断
- LCQMC:句对匹配
- BQ Corpus:句对匹配
- TNEWS:文本分类
- ChnSentiCorp: 情感分析
经过学习率搜索,我们验证了小参数量模型需要更高的学习率和更多的迭代次数,以下是各数据集的学习率。
最佳学习率:
| 模型 | CMRC 2018 | DRCD | OCNLI | LCQMC | BQ Corpus | TNEWS | ChnSentiCorp |
|---|---|---|---|---|---|---|---|
| RoBERTa | 3e-5 | 3e-5 | 2e-5 | 2e-5 | 3e-5 | 2e-5 | 2e-5 |
| * | 1e-4 | 1e-4 | 5e-5 | 1e-4 | 1e-4 | 1e-4 | 1e-4 |
*代表所有小型预训练模型 (RBT3, RBT4-H312, MiniRBT-H256, MiniRBT-H288)
实验结果(开发集):
| Task | CMRC 2018 | DRCD | OCNLI | LCQMC | BQ Corpus | TNEWS | ChnSentiCorp |
|---|---|---|---|---|---|---|---|
| RoBERTa | 87.3/68 | 94.4/89.4 | 76.58 | 89.07 | 85.76 | 57.66 | 94.89 |
| RBT6 (KD) | 84.4/64.3 | 91.27/84.93 | 72.83 | 88.52 | 84.54 | 55.52 | 93.42 |
| RBT3 | 80.3/57.73 | 85.87/77.63 | 69.80 | 87.3 | 84.47 | 55.39 | 93.86 |
| RBT4-H312 | 77.9/54.93 | 84.13/75.07 | 68.50 | 85.49 | 83.42 | 54.15 | 93.31 |
| MiniRBT-H256 | 78.47/56.27 | 86.83/78.57 | 68.73 | 86.81 | 83.68 | 54.45 | 92.97 |
| MiniRBT-H288 | 80.53/58.83 | 87.1/78.73 | 68.32 | 86.38 | 83.77 | 54.62 | 92.83 |
相对效果:
| Task | CMRC 2018 | DRCD | OCNLI | LCQMC | BQ Corpus | TNEWS | ChnSentiCorp |
|---|---|---|---|---|---|---|---|
| RoBERTa | 100%/100% | 100%/100% | 100% | 100% | 100% | 100% | 100% |
| RBT6 (KD) | 96.7%/94.6% | 96.7%/95% | 95.1% | 99.4% | 98.6% | 96.3% | 98.5% |
| RBT3 | 92%/84.9% | 91%/86.8% | 91.1% | 98% | 98.5% | 96.1% | 98.9% |
| RBT4-H312 | 89.2%/80.8% | 89.1%/84% | 89.4% | 96% | 97.3% | 93.9% | 98.3% |
| MiniRBT-H256 | 89.9%/82.8% | 92%/87.9% | 89.7% | 97.5% | 97.6% | 94.4% | 98% |
| MiniRBT-H288 | 92.2%/86.5% | 92.3%/88.1% | 89.2% | 97% | 97.7% | 94.7% | 97.8% |
- 两段式蒸馏对比
我们对两段式蒸馏(RoBERTa→RBT6(KD)→MiniRBT-H256)与一段式蒸馏(RoBERTa→MiniRBT-H256)做了比较。实验结果证明两段式蒸馏效果较优。
| 模型 | CMRC 2018 | OCNLI | LCQMC | BQ Corpus | TNEWS |
|---|---|---|---|---|---|
| MiniRBT-H256(两段式) | 77.97/54.6 | 69.11 | 86.58 | 83.74 | 54.12 |
| MiniRBT-H256(一段式) | 77.57/54.27 | 68.32 | 86.39 | 83.55 | 53.94 |
:该表中预训练模型经过3万步蒸馏,不同于中文基线效果中呈现的模型。
4.预训练
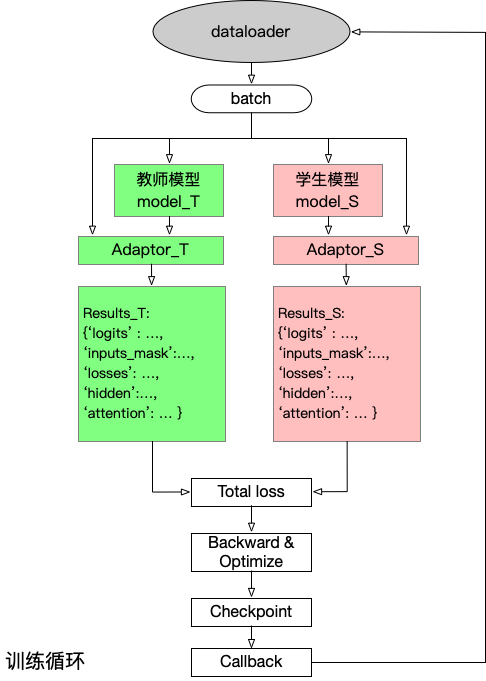
我们使用了TextBrewer工具包实现知识蒸馏预训练过程。完整的训练代码位于pretraining目录下。
- 代码结构
dataset:train: 训练集dev: 验证集
distill_configs: 学生模型结构配置文件jsons: 数据集配置文件pretrained_model_path:ltp: ltp分词模型权重,包含pytorch_model.bin,vocab.txt,config.json,共计3个文件RoBERTa: 教师模型权重,包含pytorch_model.bin,vocab.txt,config.json,共计3个文件
scripts: 模型初始化权重生成脚本saves: 输出文件夹config.py: 训练参数配置matches.py: 教师模型和学生模型的匹配配置my_datasets.py: 训练数据处理文件run_chinese_ref.py: 生成含有分词信息的参考文件train.py:预训练主函数utils.py: 预训练蒸馏相关函数定义distill.sh: 预训练蒸馏脚本
4.1环境准备
预训练代码所需依赖库仅在python3.8,PyTorch v1.8.1下测试过,一些特定依赖库可通过pip install -r requirements.txt命令安装。
- 预训练模型准备
可从huggingface官网下载ltp分词模型权重与RoBERTa-wwm-ext预训练模型权重,并存放至${project-dir}/pretrained_model_path/目录下相应文件夹。
4.2数据准备
对于中文模型,我们需先生成含有分词信息的参考文件,可直接运行以下命令:
python run_chinese_ref.py
因为预训练数据集较大,推荐生成参考文件后进行预处理,仅需运行以下命令:
python my_datasets.py
4.3运行训练脚本
一旦你对数据做了预处理,进行预训练蒸馏就非常简单。我们在distill.sh中提供了预训练示例脚本。该脚本支持单机多卡训练,主要包含如下参数:
teacher_name or_path:教师模型权重文件student_config: 学生模型结构配置文件num_train_steps: 训练步数ckpt_steps:每ckpt_steps保存一次模型learning_rate: 预训练最大学习率train_batch_size: 预训练批次大小data_files_json: 数据集json文件data_cache_dir:训练数据缓存文件夹output_dir: 输出文件夹output encoded layers:设置隐层输出为Truegradient_accumulation_steps:梯度累积temperature:蒸馏温度fp16:开启半精度浮点数训练
直接运行以下命令可实现MiniRBT-H256的预训练蒸馏:
sh distill.sh
提示:以良好的模型权重初始化有助于蒸馏预训练。在我们的实验中使用教师模型的前6层初始化助教模型RBT6(KD) ! 请参考scripts/init_checkpoint_TA.py来创建有效的初始化权重,并使用--student_pretrained_weights参数将此初始化用于蒸馏训练!
4.4 使用建议
- 初始学习率是非常重要的一个参数,需要根据目标任务进行调整。
- 小参数量模型的最佳学习率和
RoBERT-wwm相差较大,所以使用小参数量模型时请务必调整学习率(基于以上实验结果,小参数量模型需要的初始学习率高,迭代次数更多)。 - 在参数量(不包括嵌入层)基本相同的情况下,MiniRBT-H256的效果优于RBT4-H312,亦证明窄而深的模型结构优于宽而浅的模型结构
- 在阅读理解相关任务上,MiniRBT-H288的效果较好。其他任务MiniRBT-H288和MiniRBT-H256效果持平,可根据实际需求选择相应模型。
5.FAQ
Q: 这个模型怎么用?
A: 参考快速加载。使用方式和HFL推出的中文预训练模型系列如RoBERTa-wwm相同。
Q:为什么要单独生成含有分词信息的参考文件?
A: 假设我们有一个中文句子:天气很好,BERT将它标记为['天','气','很','好'](字符级别)。但在中文中天气是一个完整的单词。为了实现全词掩码,我们需要一个参考文件来告诉模型应该在哪个位置添加##,因此会生成类似于['天','##气','很','好']的结果。
注意:此为辅助参考文件,并不影响模型的原始输入(即与分词结果无关)。
Q: 为什么RBT6 (KD)在下游任务中的效果相较RoBERTa下降这么多? 为什么miniRBT-H256/miniRBT-H288/RBT4-H312效果这么低?如何提升效果?
A: 上文中所述RBT6 (KD)直接由RoBERTa-wwm-ext在预训练任务上蒸馏得到,然后在下游任务中fine-tuning,并不是通过对下游任务蒸馏得到。其他模型类似,我们仅做了预训练任务的蒸馏。如果希望进一步提升在下游任务上的效果,可在fine-tuning阶段再次使用知识蒸馏。
Q: 某某数据集在哪里下载?
A: 部分数据集提供了下载地址。未标注下载地址的数据集请自行搜索或与原作者联系获取数据。
参考文献
[1] Pre-training with Whole Word Masking for Chinese BERT (Cui et al., IEEE/ACM TASLP 2021)
[2] TextBrewer: An Open-Source Knowledge Distillation Toolkit for Natural Language Processing (Yang et al., ACL 2020)
[3] CLUE: A Chinese Language Understanding Evaluation Benchmark (Xu et al., COLING 2020)
[4] TinyBERT: Distilling BERT for Natural Language Understanding (Jiao et al., Findings of EMNLP 2020)
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。


MiniRBT中文小型预训练模型:结合了全词掩码技术和两段式知识蒸馏技术,加快推理速度的更多相关文章
- 最强中文NLP预训练模型艾尼ERNIE官方揭秘【附视频】
“最近刚好在用ERNIE写毕业论文” “感觉还挺厉害的” “为什么叫ERNIE啊,这名字有什么深意吗?” “我想让艾尼帮我写作业” 看了上面火热的讨论,你一定很好奇“艾尼”.“ERNIE”到底是个啥? ...
- 【小白学PyTorch】5 torchvision预训练模型与数据集全览
文章来自:微信公众号[机器学习炼丹术].一个ai专业研究生的个人学习分享公众号 文章目录: 目录 torchvision 1 torchvision.datssets 2 torchvision.mo ...
- XLNet预训练模型,看这篇就够了!(代码实现)
1. 什么是XLNet XLNet 是一个类似 BERT 的模型,而不是完全不同的模型.总之,XLNet是一种通用的自回归预训练方法.它是CMU和Google Brain团队在2019年6月份发布的模 ...
- NLP与深度学习(五)BERT预训练模型
1. BERT简介 Transformer架构的出现,是NLP界的一个重要的里程碑.它激发了很多基于此架构的模型,其中一个非常重要的模型就是BERT. BERT的全称是Bidirectional En ...
- 中文预训练模型ERNIE2.0模型下载及安装
2019年7月,百度ERNIE再升级,发布持续学习的语义理解框架ERNIE 2.0,及基于此框架的ERNIE 2.0预训练模型, 它利用百度海量数据和飞桨(PaddlePaddle)多机多卡高效训练优 ...
- BERT预训练模型的演进过程!(附代码)
1. 什么是BERT BERT的全称是Bidirectional Encoder Representation from Transformers,是Google2018年提出的预训练模型,即双向Tr ...
- 使用BERT预训练模型+微调进行文本分类
本文记录使用BERT预训练模型,修改最顶层softmax层,微调几个epoch,进行文本分类任务. BERT源码 首先BERT源码来自谷歌官方tensorflow版:https://github.co ...
- Pytorch——BERT 预训练模型及文本分类
BERT 预训练模型及文本分类 介绍 如果你关注自然语言处理技术的发展,那你一定听说过 BERT,它的诞生对自然语言处理领域具有着里程碑式的意义.本次试验将介绍 BERT 的模型结构,以及将其应用于文 ...
- Paddle预训练模型应用工具PaddleHub
Paddle预训练模型应用工具PaddleHub 本文主要介绍如何使用飞桨预训练模型管理工具PaddleHub,快速体验模型以及实现迁移学习.建议使用GPU环境运行相关程序,可以在启动环境时,如下图所 ...
- 管正雄:基于预训练模型、智能运维的QA生成算法落地
分享嘉宾:管正雄 阿里云 高级算法工程师 出品平台:DataFunTalk 导读:面对海量的用户问题,有限的支持人员该如何高效服务好用户?智能QA生成模型给业务带来的提效以及如何高效地构建算法服务,为 ...
随机推荐
- Java 网络编程 —— 实现非阻塞式的客户端
创建阻塞的 EchoClient 客户程序一般不需要同时建立与服务器的多个连接,因此用一个线程,按照阻塞模式运行就能满足需求 public class EchoClient { private Soc ...
- python sorted排序小结
转载至: https://blog.csdn.net/ray_up/article/details/42084863 在python中排序有两个专用函数,一个是sort,另一个sorted.其中sor ...
- GPT应用开发:运行你的第一个聊天程序
本系列文章介绍基于OpenAI GPT API开发大模型应用的方法,适合从零开始,也适合查缺补漏. 本文首先介绍基于聊天API编程的方法. 环境搭建 很多机器学习框架和类库都是使用Python编写的, ...
- CNS0项目创建交货单增加销售办事处
1.业务需求 1.1.销售办事处介绍 销售办事处是指在企业中负责销售活动的区域性单位或部门.在SD模块中,可以表示企业的不同销售地点.销售办公室.分销中心或分公司. 销售办事处扮演着多种角色和职责,例 ...
- 使用BAPI_NETWORK_COMP_*实现生产订单组件的增删改查
1.文档说明 对于生产订单组件的增删改有多种办法,比较常用的有使用内部函数CO_XT_COMPONENT_*,有改造BAPI_ALM_ORDER_MAINTAIN来实现,各有千秋. 本文档介绍,通过P ...
- Codeforces Round #704 (Div. 2) A~E
比赛链接:https://codeforces.com/contest/1492 1492A.Three swimmers 题意: 有三名游泳的人,他们分别需要 \(a,b,c\) 分钟才能在一个游泳 ...
- 题解| CF1561D2. Up the Strip(递推)
题目链接:Here 这个思路学习自 Harris-H ,考虑递推而不是DP 与 D1 不同,开始考虑 \(f_{i-1} \to f_i\) 显然操作 1 多了 \(f_{i-1}\) ,操作2 多了 ...
- 0x41 数据结构进阶-并查集
A题 程序自动分析 题目链接:https://ac.nowcoder.com/acm/contest/1031/A 题目描述 在实现程序自动分析的过程中,常常需要判定一些约束条件是否能被同时满足. 考 ...
- 题解 - Japanese Student Championship 2021
前言:这场的题解由于蓝桥杯比赛拖延几天才发 关于本篇题解,目前还是有部分题没有解答出来正在加油补题ing 补题链接:Here A - Competition 题意:给定 \(X,Y,Z\) 代表的意义 ...
- Codeforces Round #697 (Div. 3) A - G个人题解记录
Codeforces Round #697 (Div. 3) 1475A. Odd Divisor 问一个数是否有奇除数. 对 2 不断除,如果最后 n == 1即不可能存在,否在存在. int ma ...