【JS 逆向百例】拉勾网爬虫,traceparent、__lg_stoken__、X-S-HEADER 等参数分析

关注微信公众号:K哥爬虫,持续分享爬虫进阶、JS/安卓逆向等技术干货!
声明
本文章中所有内容仅供学习交流,抓包内容、敏感网址、数据接口均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关,若有侵权,请在公众号联系我立即删除!
逆向目标
本次的目标是拉勾网职位的爬取,涉及到的一些关键参数如下:
- 请求头参数:
traceparent、X-K-HEADER、X-S-HEADER、X-SS-REQ-HEADER、x-anit-forge-code、x-anit-forge-token - Cookie 值:
user_trace_token、X_HTTP_TOKEN、__lg_stoken__ - POST 请求数据加密,返回的加密职位信息解密,AES 算法
参数比较多,但事实上有些参数固定、或者直接不要,也是可以的,比如 Cookie 的三个值,请求头的 X-K-HEADER、X-SS-REQ-HEADER 等可以固定,x-anit-forge-code 和 x-anit-forge-token 可有可无。尽管如此,本文还是把每个参数的来源都分析了,可根据你实际情况灵活处理。
另外即便是把所有参数都补齐了,拉勾网对于单个 IP 还有频率限制,抓不了几次就要求登录,可自行搭配代理进行抓取,或者复制账号登录后的 cookies 到代码里,可以解除限制,如果是账号登录后访问,请求头多了两个参数,即 x-anit-forge-code 和 x-anit-forge-token,经过测试这两个参数其实不要也行。
抓包分析
搜索职位,点击翻页,就可以看到一条名为 positionAjax.json 的 Ajax 请求,不难判断这就是返回的职位信息。重点参数已在图中框出来了。
未登录,正常 IP,正常请求,Header 以及 Cookies:
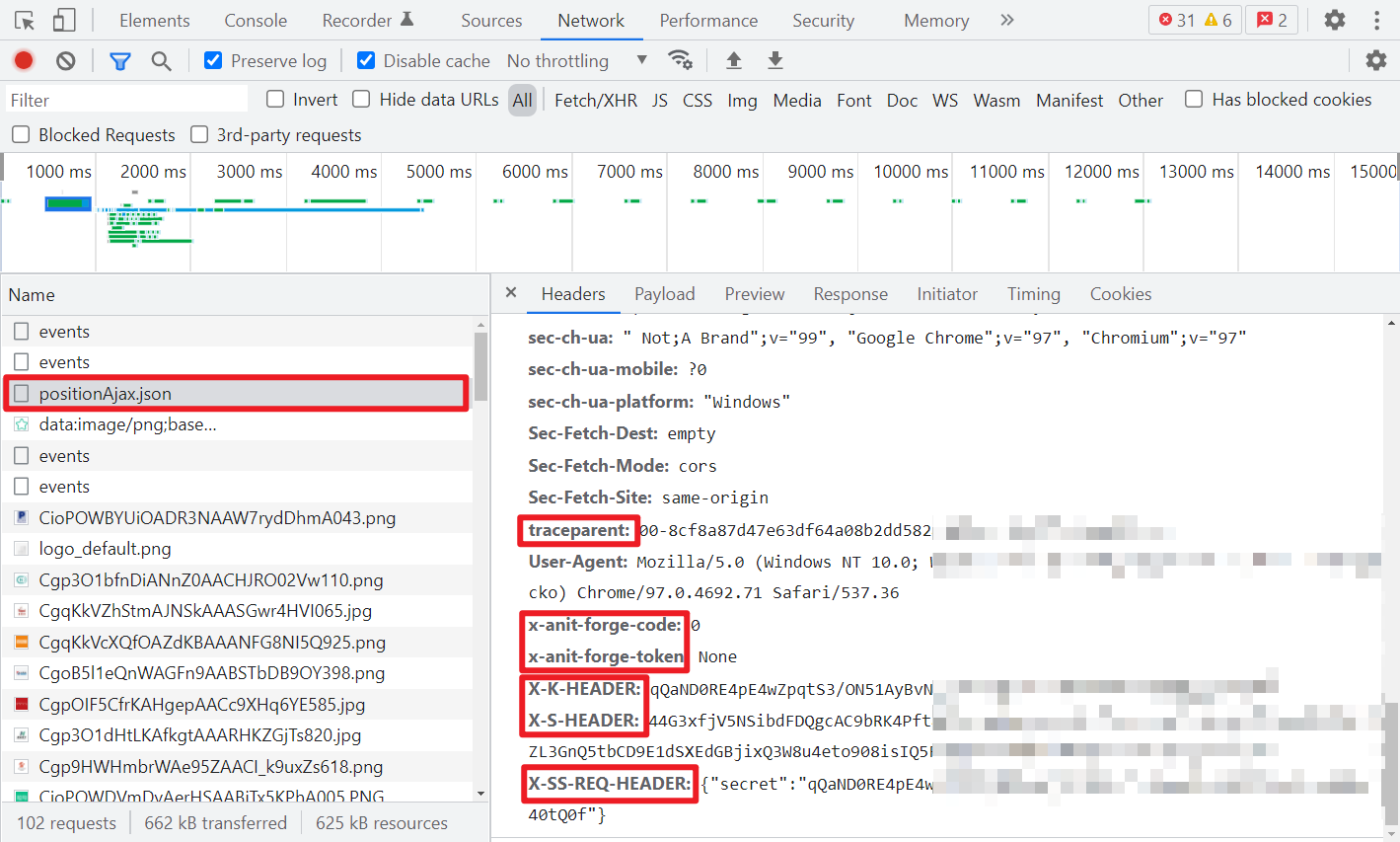
异常 IP,登录账号后再请求,Header 以及 Cookies:
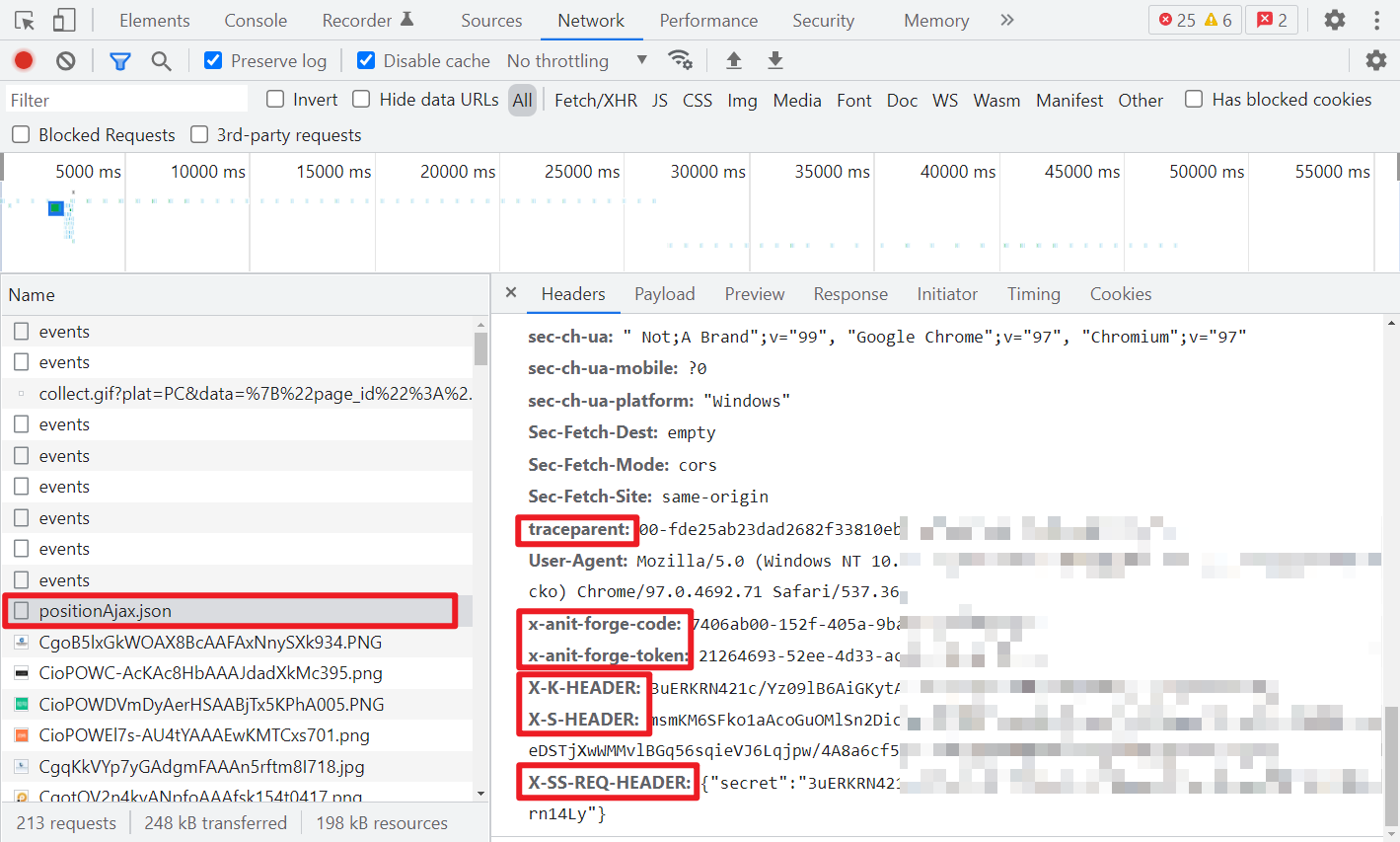
请求数据和返回数据都经过了加密:
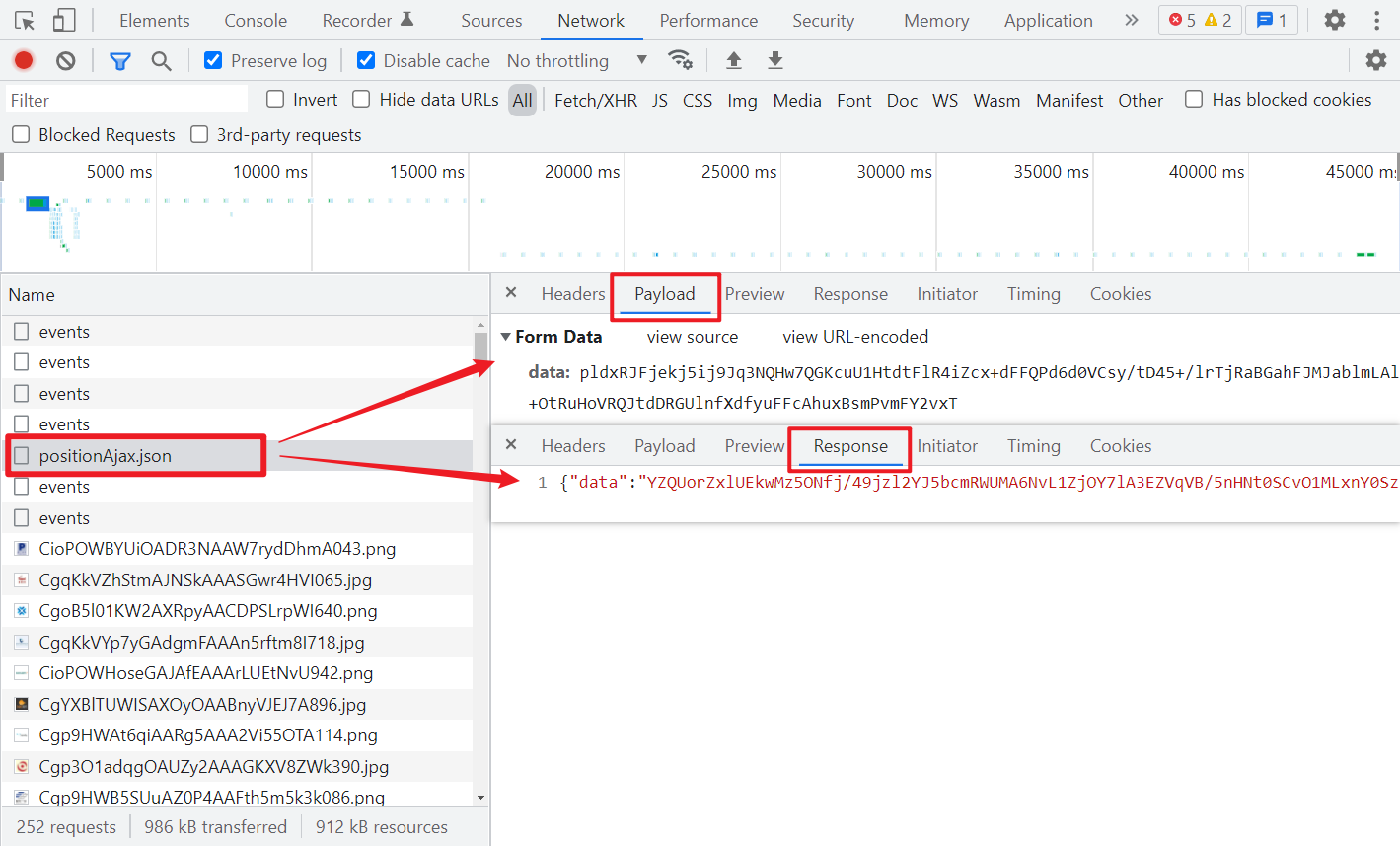
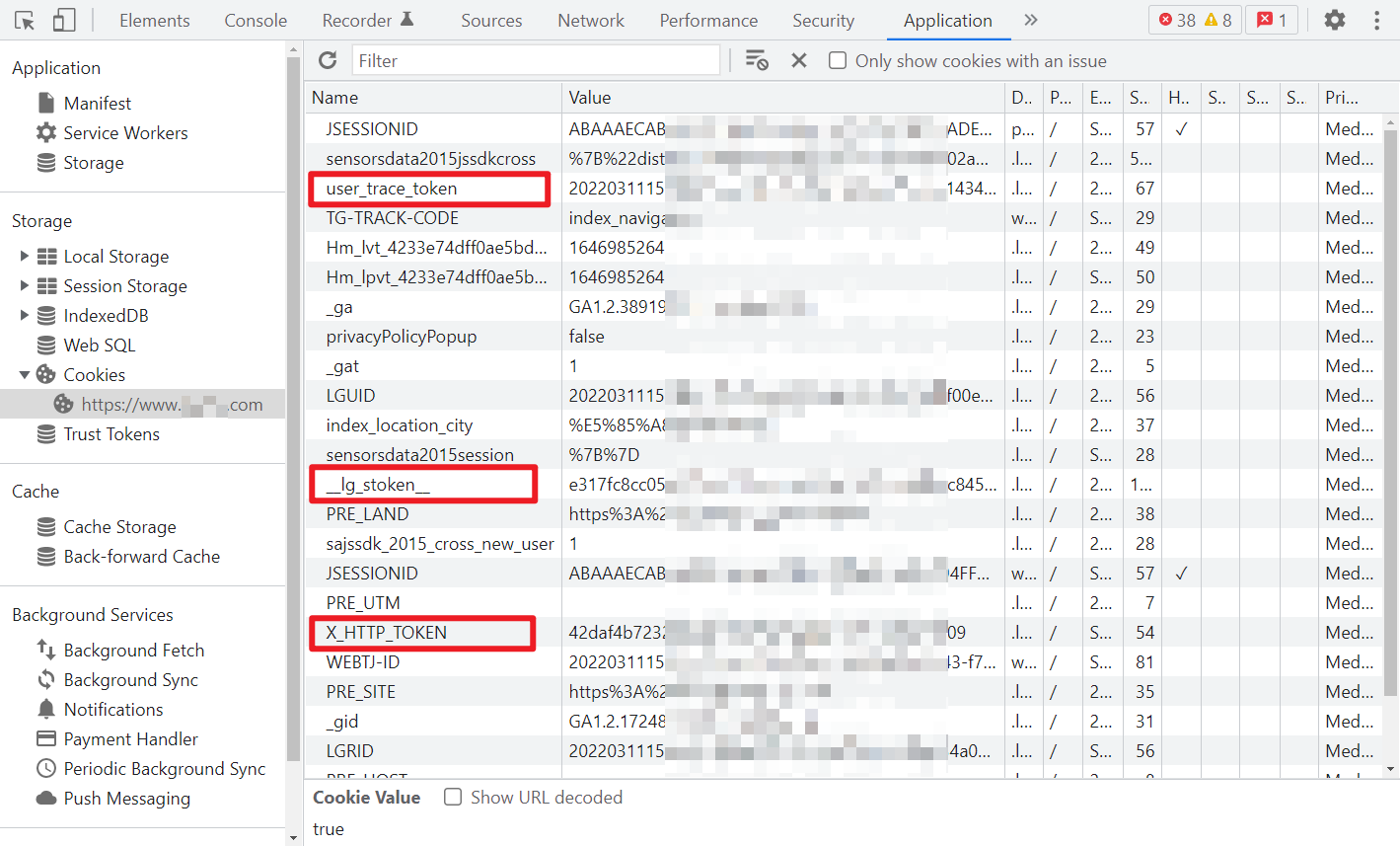
Cookies 参数
先看 cookies 里的关键参数,主要是 user_trace_token、X_HTTP_TOKEN 和 __lg_stoken__。
user_trace_token
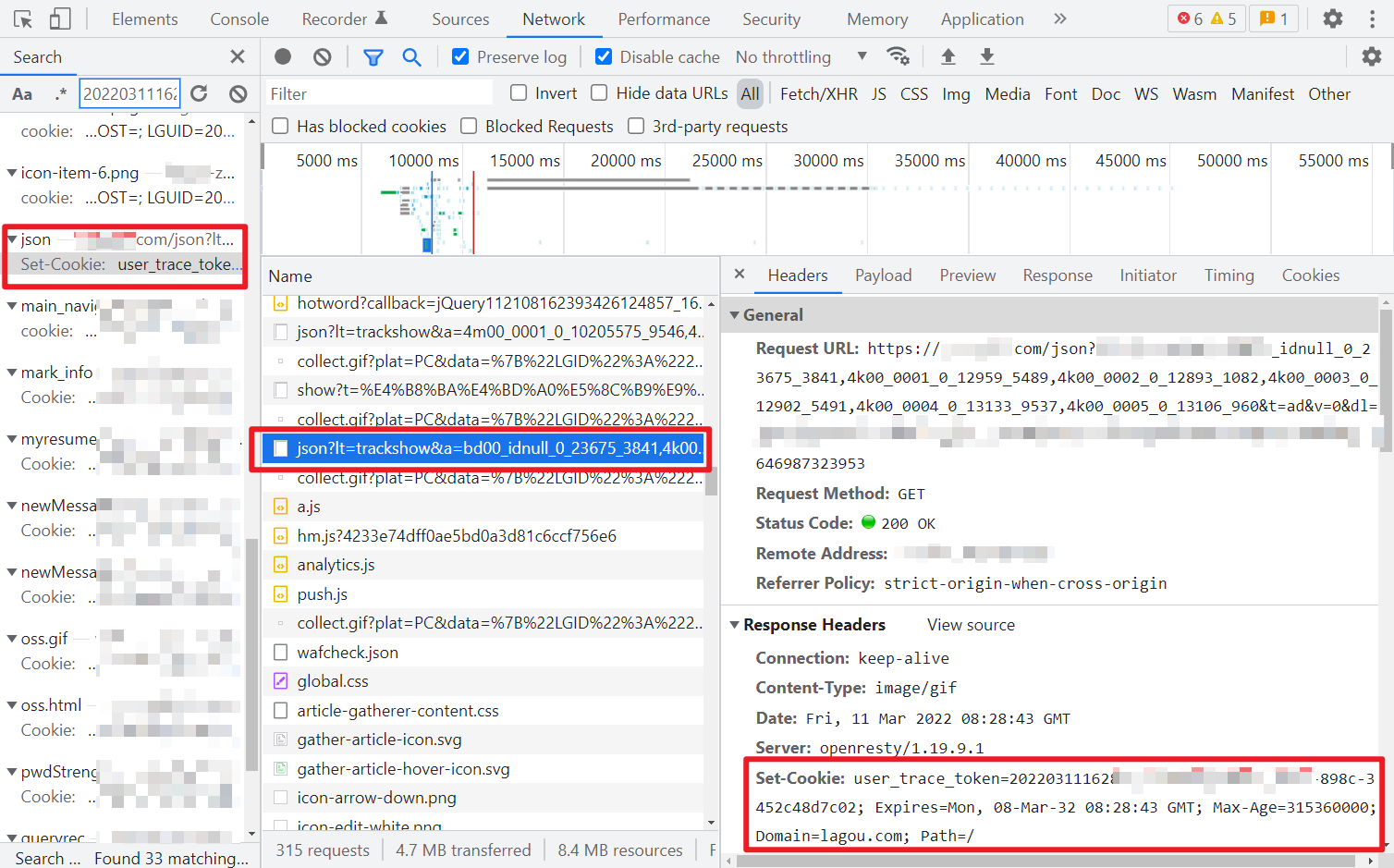
通过接口返回的,直接搜索就可以找到,如下图所示:
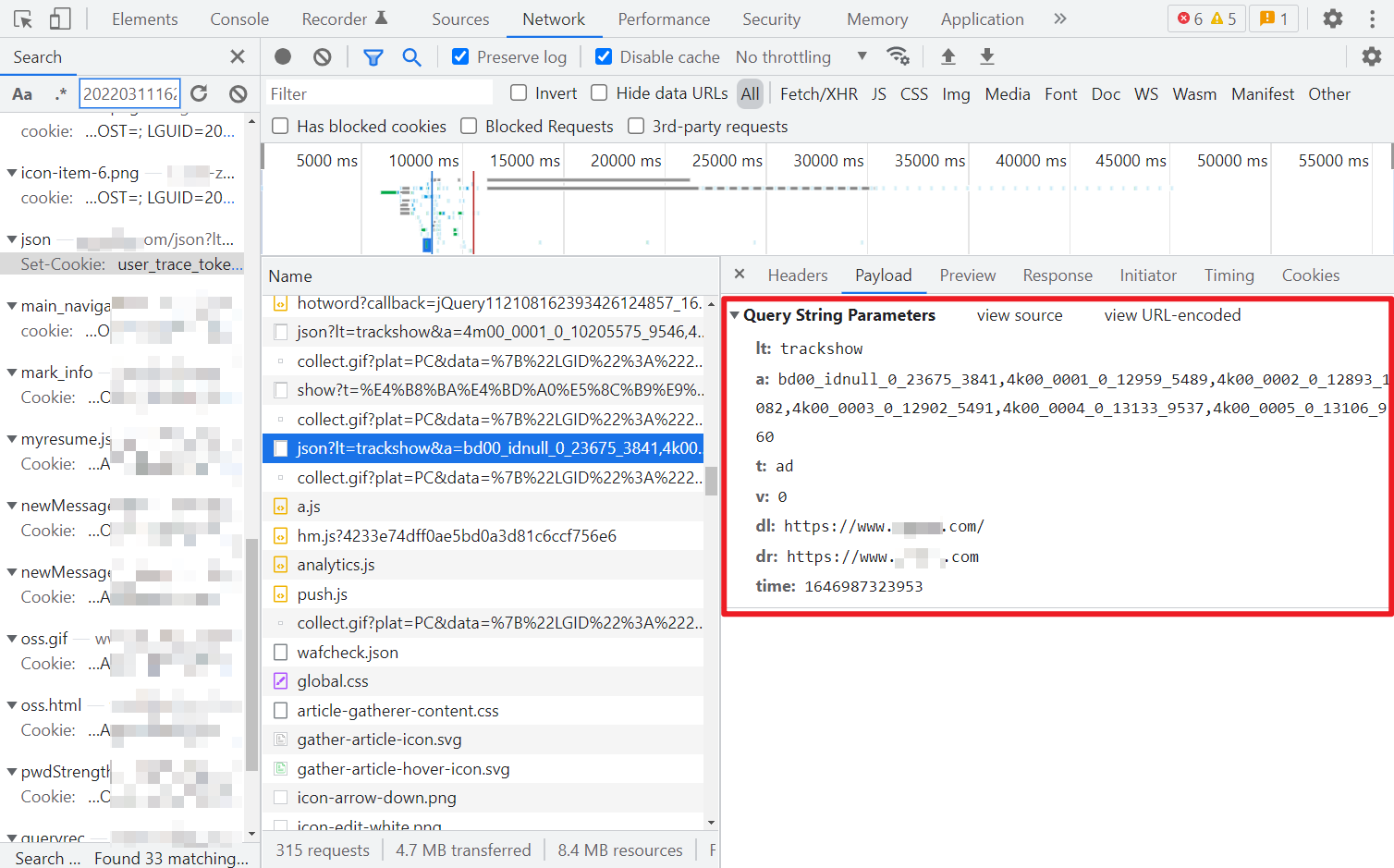
请求参数,time 是时间戳,a 值随便,没有都可以,不影响,其他值都是定值,获取的关键代码如下:
def get_user_trace_token() -> str:
# 获取 cookie 中的 user_trace_token
json_url = "https://a.脱敏处理.com/json"
headers = {
"Host": "a.脱敏处理.com",
"Referer": "https://www.脱敏处理.com/",
"User-Agent": UA
}
params = {
"lt": "trackshow",
"t": "ad",
"v": 0,
"dl": "https://www.脱敏处理.com/",
"dr": "https://www.脱敏处理.com",
"time": str(int(time.time() * 1000))
}
response = requests.get(url=json_url, headers=headers, params=params)
user_trace_token = response.cookies.get_dict()["user_trace_token"]
return user_trace_token
X_HTTP_TOKEN
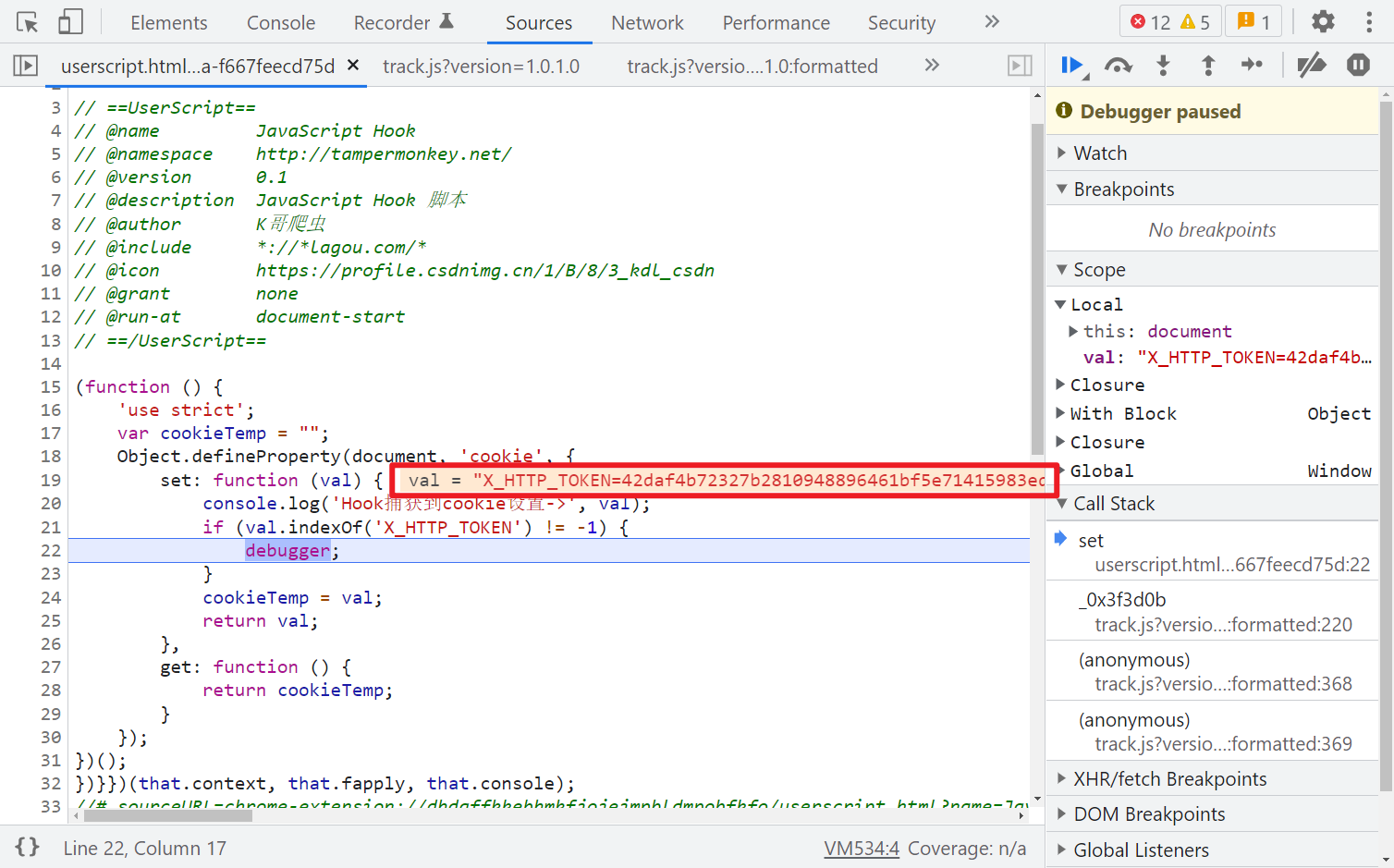
直接搜索没有值,直接上 Hook 大法,小白朋友不清楚的话可以看 K 哥以前的文章,都有详细教程,这里不再细说。
(function () {
'use strict';
var cookieTemp = "";
Object.defineProperty(document, 'cookie', {
set: function (val) {
console.log('Hook捕获到cookie设置->', val);
if (val.indexOf('X_HTTP_TOKEN') != -1) {
debugger;
}
cookieTemp = val;
return val;
},
get: function () {
return cookieTemp;
}
});
})();
往上跟栈调试,是一个小小的 OB 混淆,_0x32e0d2 就是最后的 X_HTTP_TOKEN 值了,如下图所示:
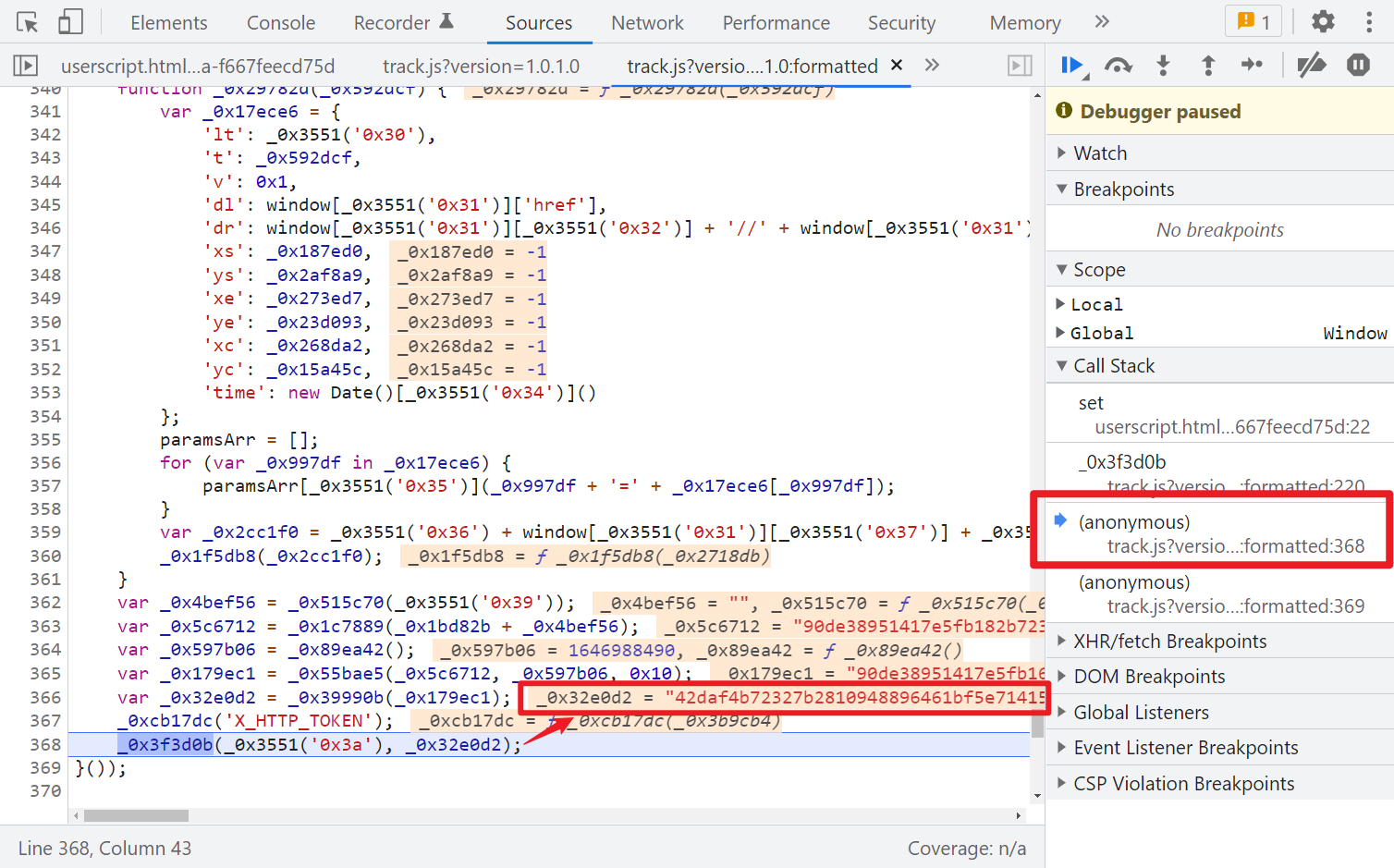
直接梭哈,才300多行,不必扣了,全部 copy 下来,本地运行,发现会报错 document 未定义,定位到代码位置,下断点调试一下,发现是正则匹配 cookie 中的 user_trace_token 的值,那么我们直接定义一下即可:var document = {"cookie": cookie},cookie 值把 user_trace_token 传过来即可。
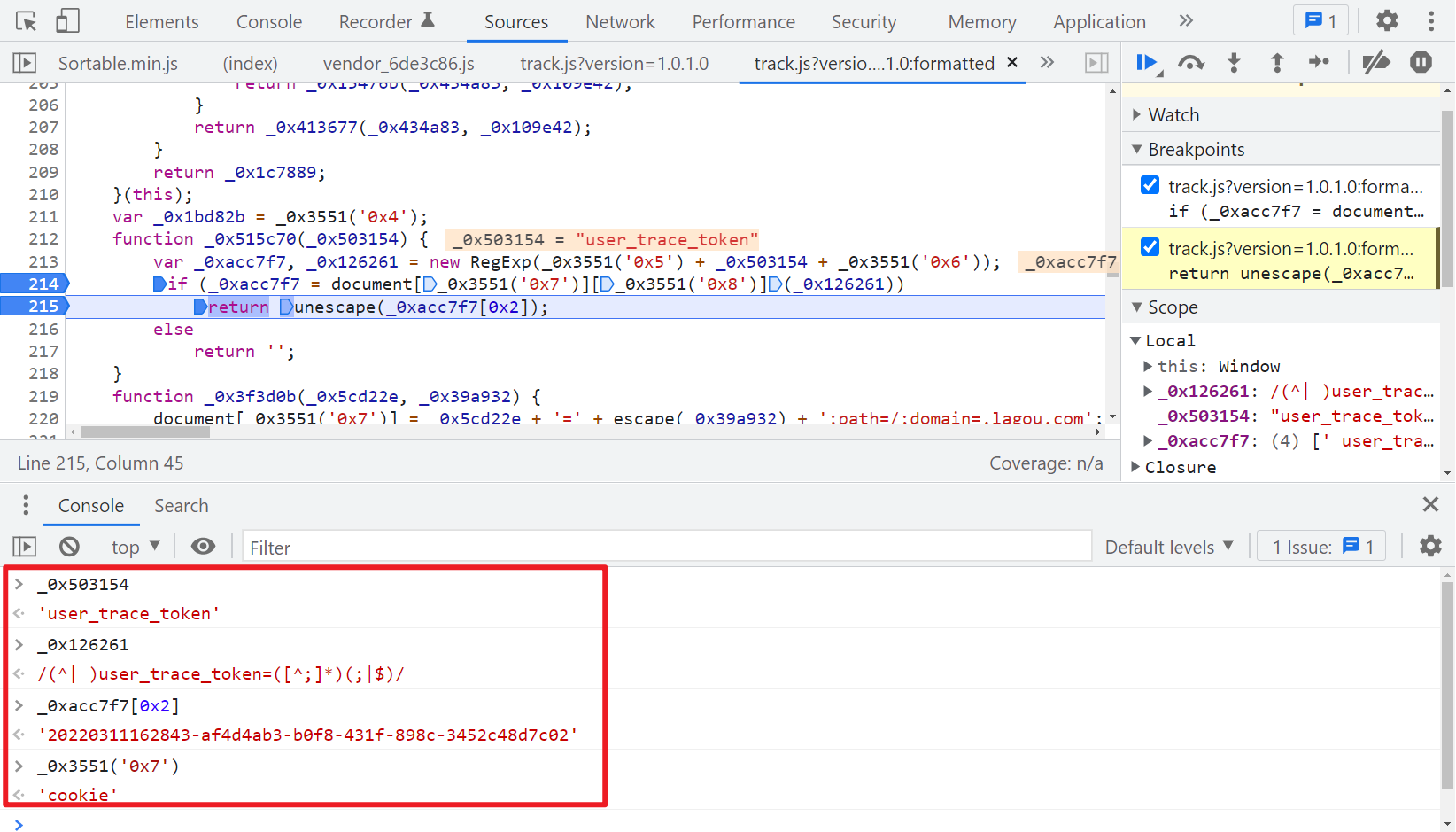
补全 document 后,再次运行,又会报错 window 未定义,再次定位到源码,如下图所示:
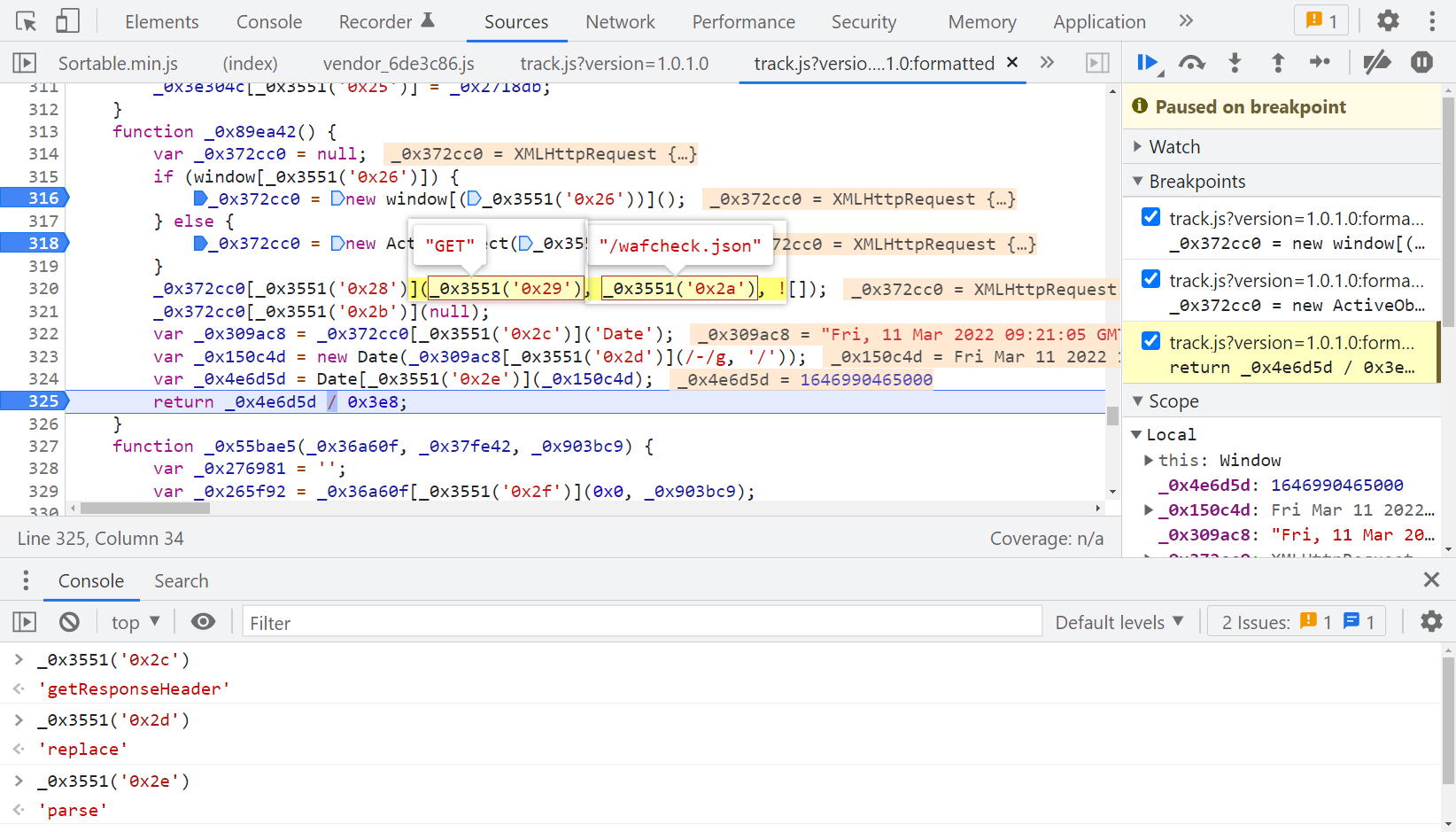
分析一下,取了 window XMLHttpRequest 对象,向 wafcheck.json 这个接口发送了一个 Ajax GET 请求,然后取了 Response Header 的 Date 值赋值给 _0x309ac8,注意这个 Date 值比正常时间晚了8个小时,然而取 Date 值并没有什么用,因为后面又 new 了一个新 Date 标准时间,赋值给了 _0x150c4d,new Date(_0x309ac8[_0x3551('0x2d')](/-/g, '/')) 语句虽然用到了前面的旧 Date,然而实际上是 replace() 替换方法,与旧的 Date 并没有什么关系,然后调用 Date.parse() 方法将新 Date 转换成时间戳赋值给 _0x4e6d5d,所以不需要这么复杂,直接本地把 _0x89ea429 方法修改一下就行了:
// 原方法
// function _0x89ea42() {
// var _0x372cc0 = null;
// if (window[_0x3551('0x26')]) {
// _0x372cc0 = new window[(_0x3551('0x26'))]();
// } else {
// _0x372cc0 = new ActiveObject(_0x3551('0x27'));
// }
// _0x372cc0[_0x3551('0x28')](_0x3551('0x29'), _0x3551('0x2a'), ![]);
// _0x372cc0[_0x3551('0x2b')](null);
// var _0x309ac8 = _0x372cc0[_0x3551('0x2c')]('Date');
// var _0x150c4d = new Date(_0x309ac8[_0x3551('0x2d')](/-/g, '/'));
// var _0x4e6d5d = Date[_0x3551('0x2e')](_0x150c4d);
// return _0x4e6d5d / 0x3e8;
// }
// 本地改写
function _0x89ea42() {
var _0x150c4d = new Date();
var _0x4e6d5d = Date.parse(_0x150c4d);
return _0x4e6d5d / 0x3e8;
}
本地测试 OK:
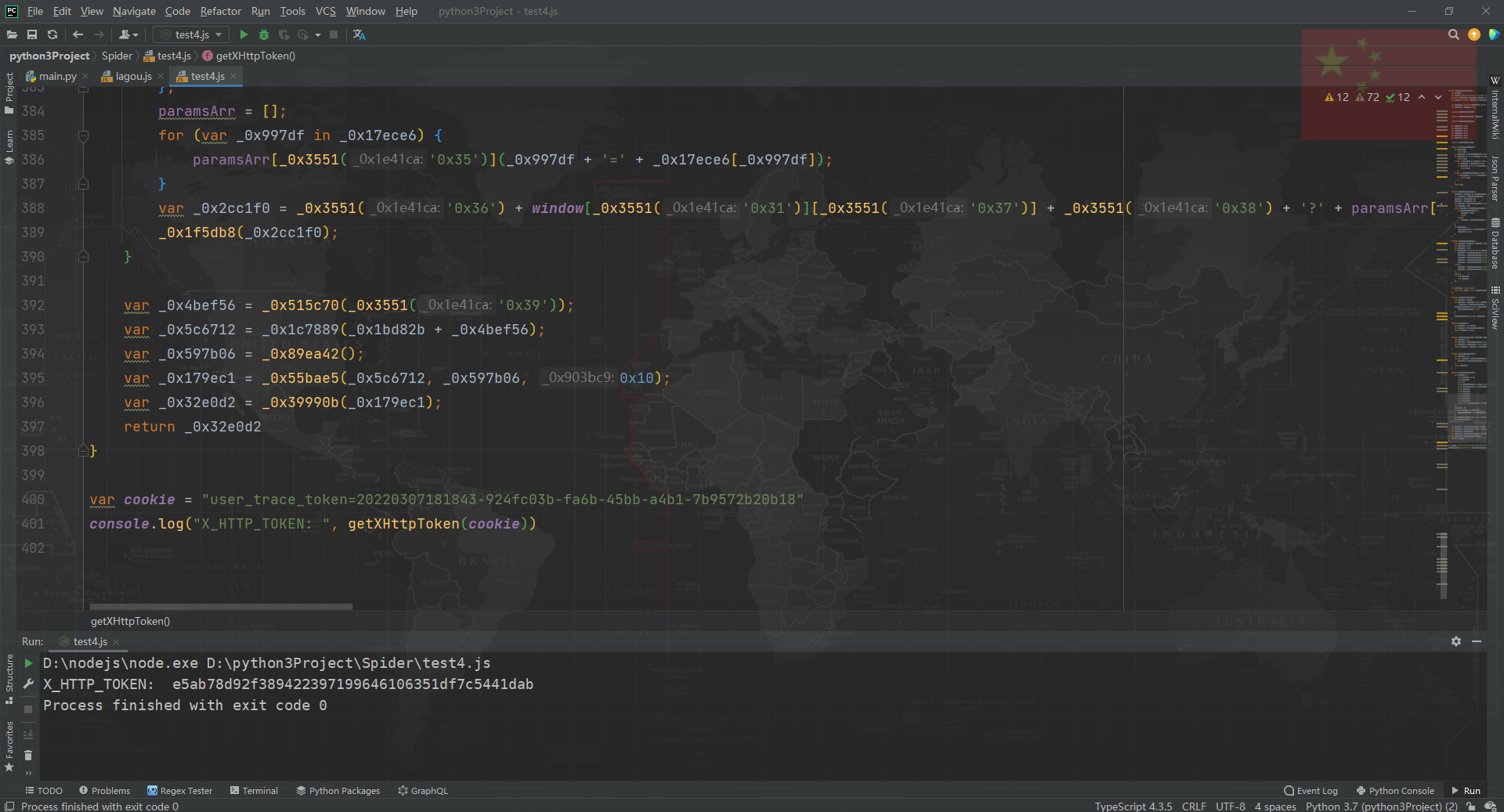
__lg_stoken__
__lg_stoken__ 这个参数是在点击搜索后才开始生成的,直接搜索同样没值,Hook 一下,往上跟栈,很容易找到生成位置:
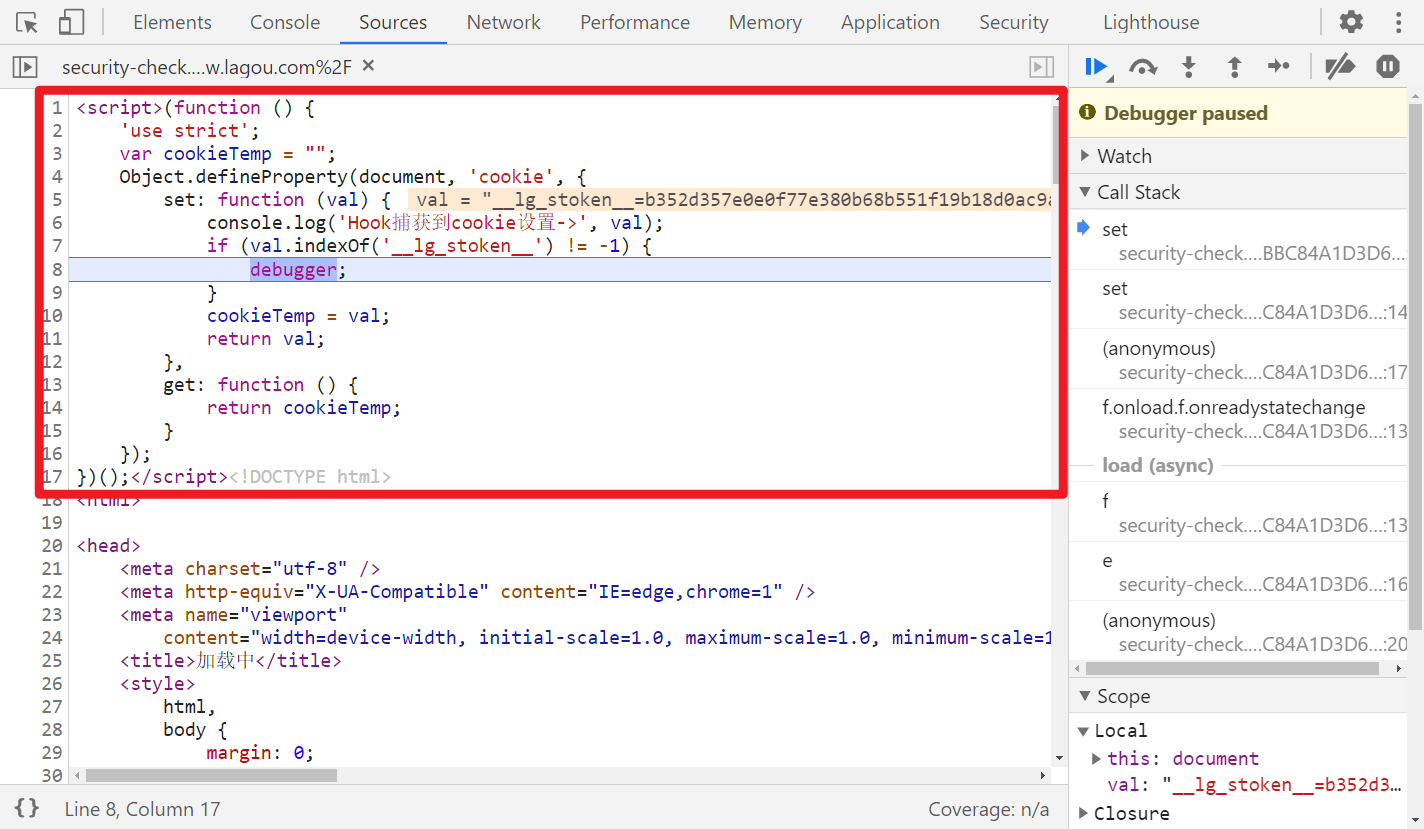
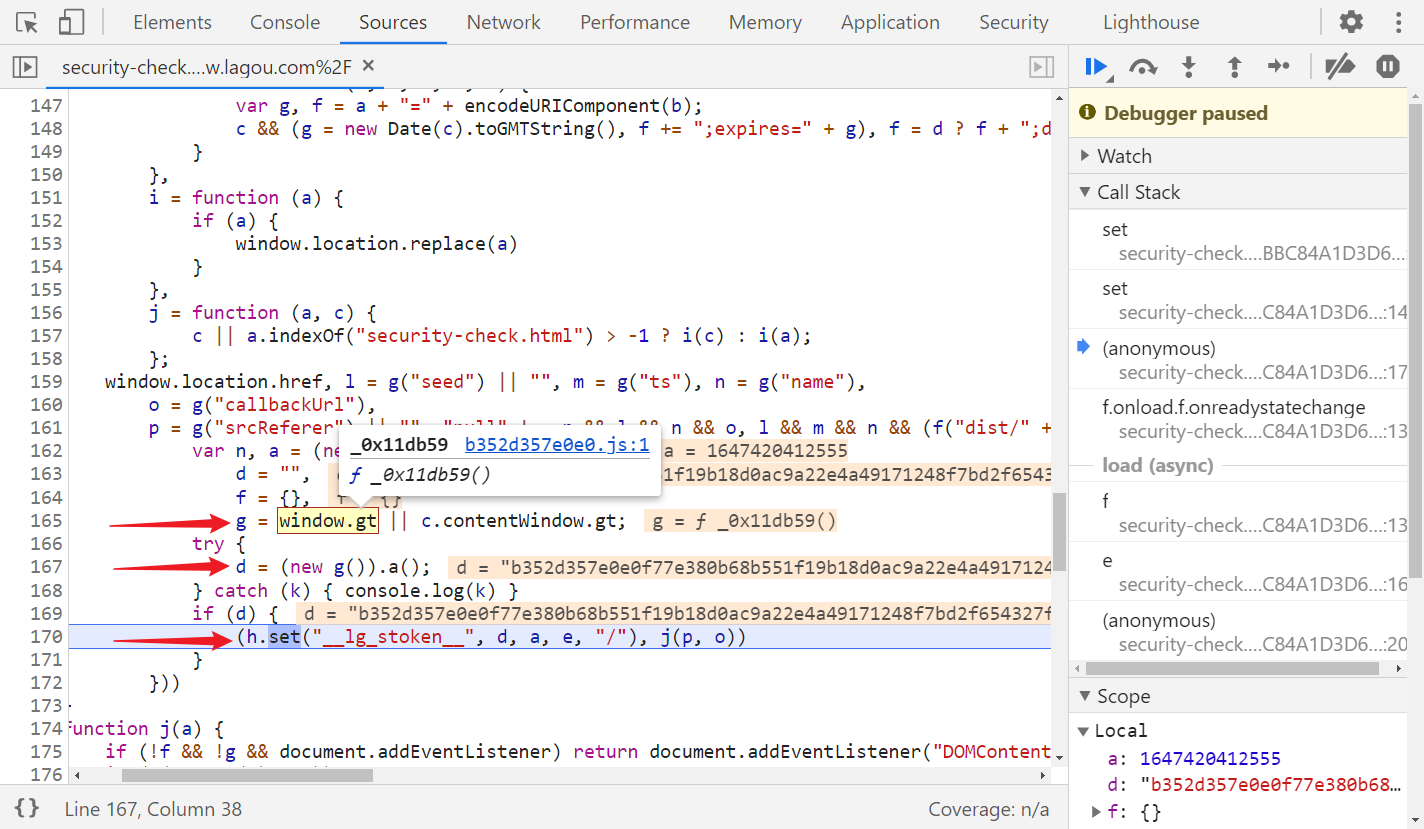
可以看到 d 就是 __lg_stoken__ 的值,d = (new g()).a()、g = window.gt,window.gt 实际上是调用了 _0x11db59
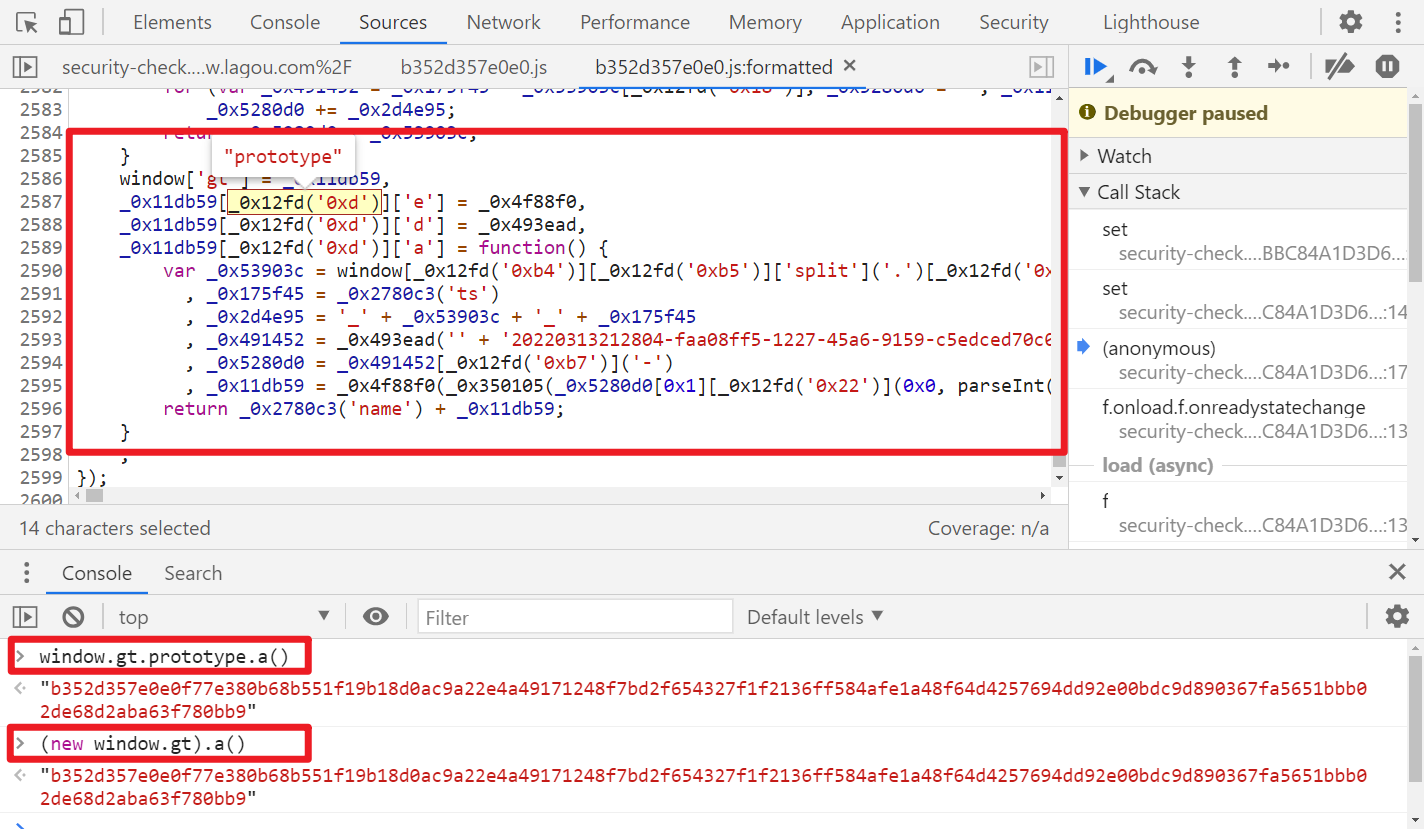
跟进混淆的 JS 看一下,就会发现末尾的这段代码是关键,这里用到了 prototype 原型对象,我们直接 window.gt.prototype.a() 或者 (new window.gt).a() 就能获取到 __lg_stoken__,如下图所示:
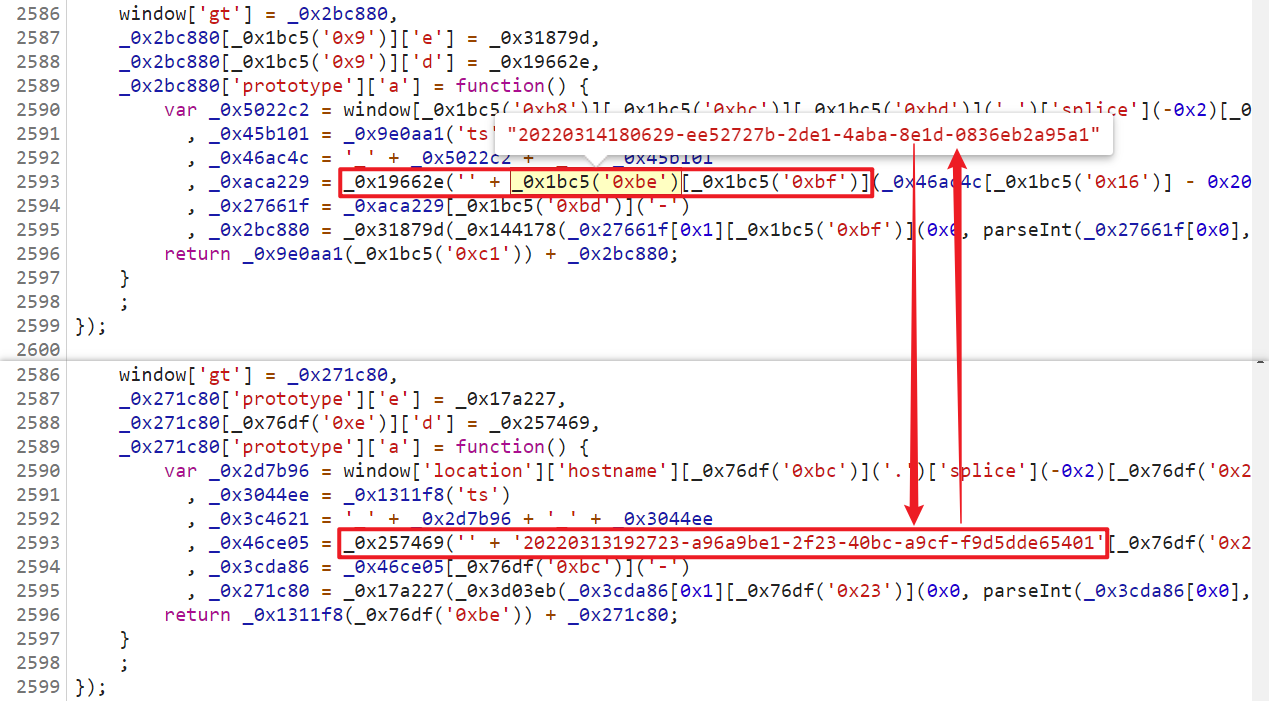
到这里也许你想下断点去调试一下,看看能不能扣个逻辑出来,但是你会发现刷新之后断不下,因为这个混淆 JS 文件是一直在变化的,之前的断点就不管用了,然后你就可能会想到直接替换掉这个 JS,让文件名固定下来,就可以断点调试了,如果你这样操作的话,重新刷新会发现一直在加载中,打开控制台会发现报错了,造成这样的原因就在于这个混淆 JS 不仅文件名会改变,他的内容也会改变,当然,内容也不仅仅是改变了变量名那么简单,有些值也是动态变化的,比如:
这里我们先不管那么多,直接把所有的混淆代码 copy 下来,先在本地调试一下,看看能不能跑通,调试过程中,先后会提示 window is not defined、Cannot read properties of undefined (reading 'hostname'),定位到代码,有个取 window.location.hostname 的操作,本地定义一下就行了:
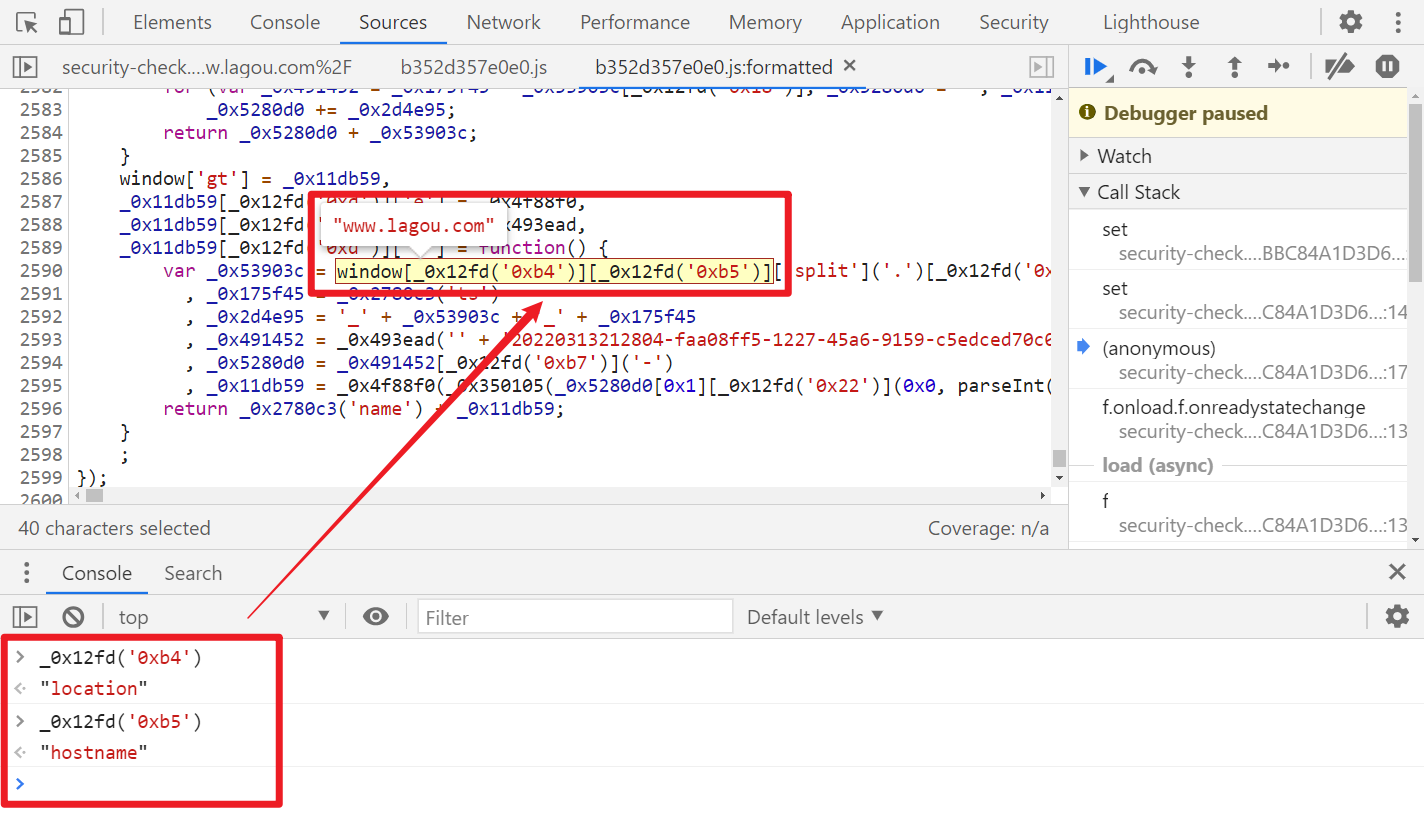
再次调试又会报错 Cannot read properties of undefined (reading 'substr'),substr() 方法可在字符串中抽取从指定下标开始的、指定数目的字符,是字符串对象 stringObject 具有的方法,我们定位到代码,发现是 window.location.search 对象调用了 substr() 方法,所以同样的,我们本地也要补齐。
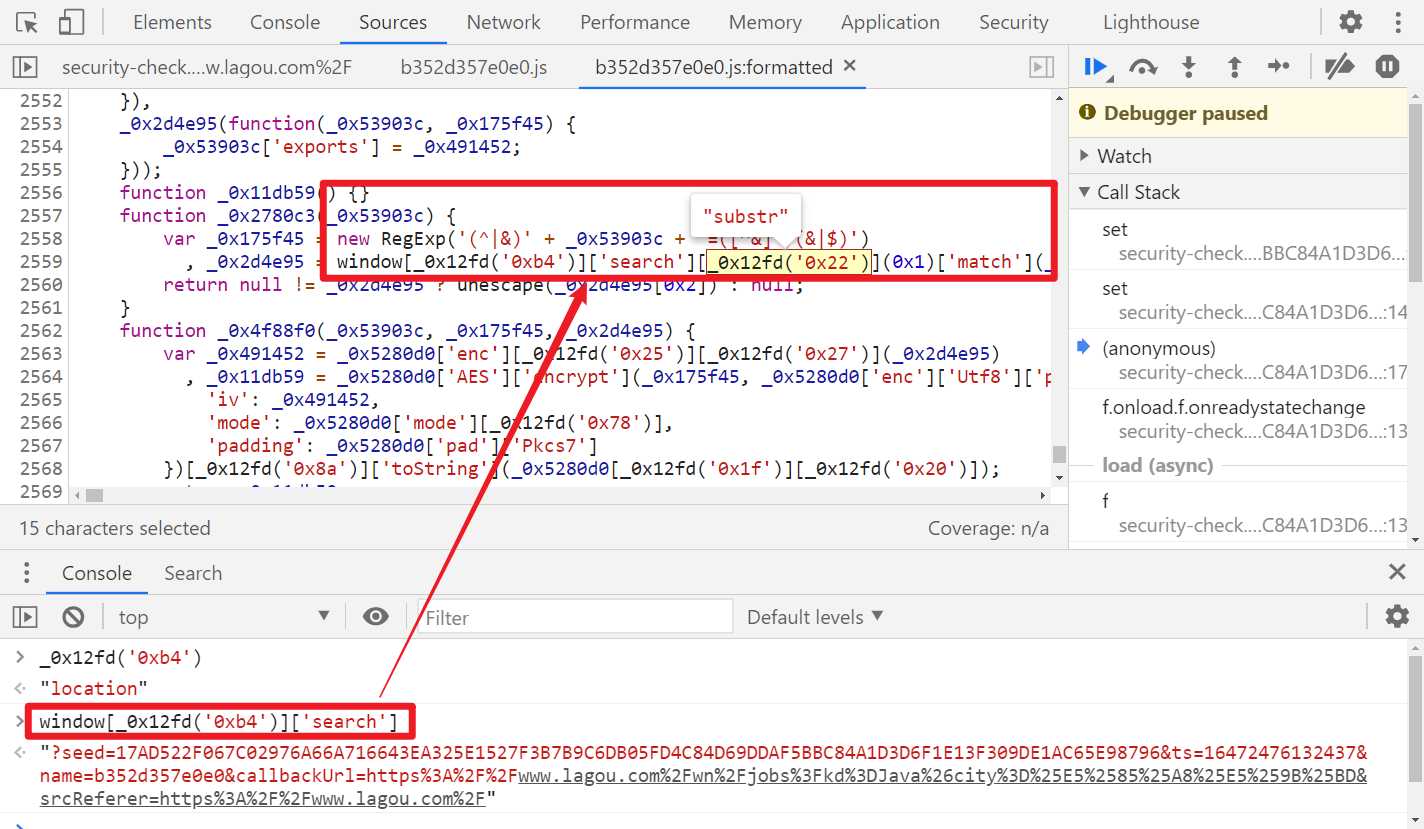
本地补齐参数后,运行结果与网页一致:
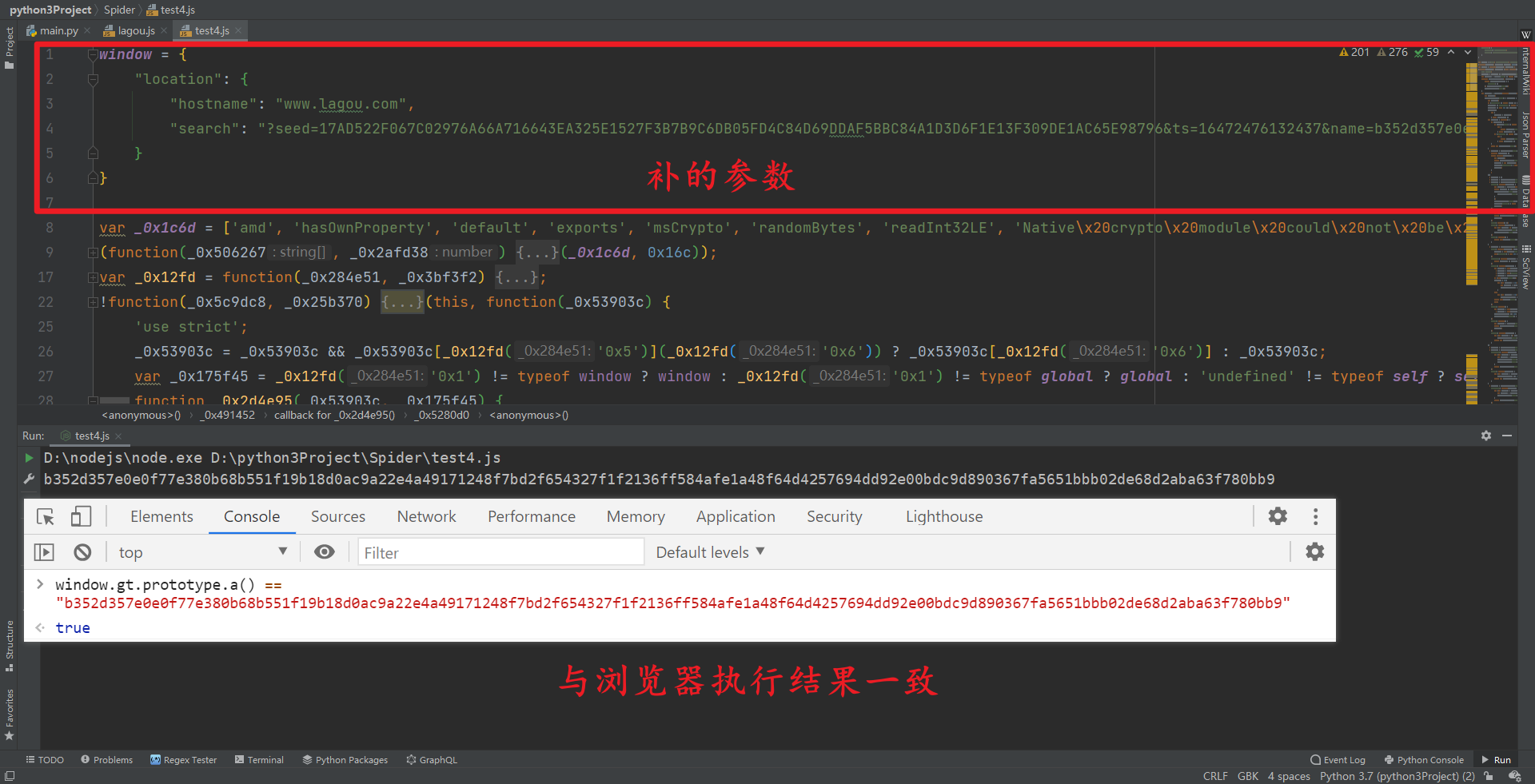
执行结果没问题了,那么还有一个问题,window.location.search 的值就是待加密参数了,是咋来的呢?我们直接搜索,就可以看到是一个接口302跳转的地址,用的时候直接取就行了,这个接口是你搜索内容组成的,搜索不同参数,这个跳转地址也是不一样的:
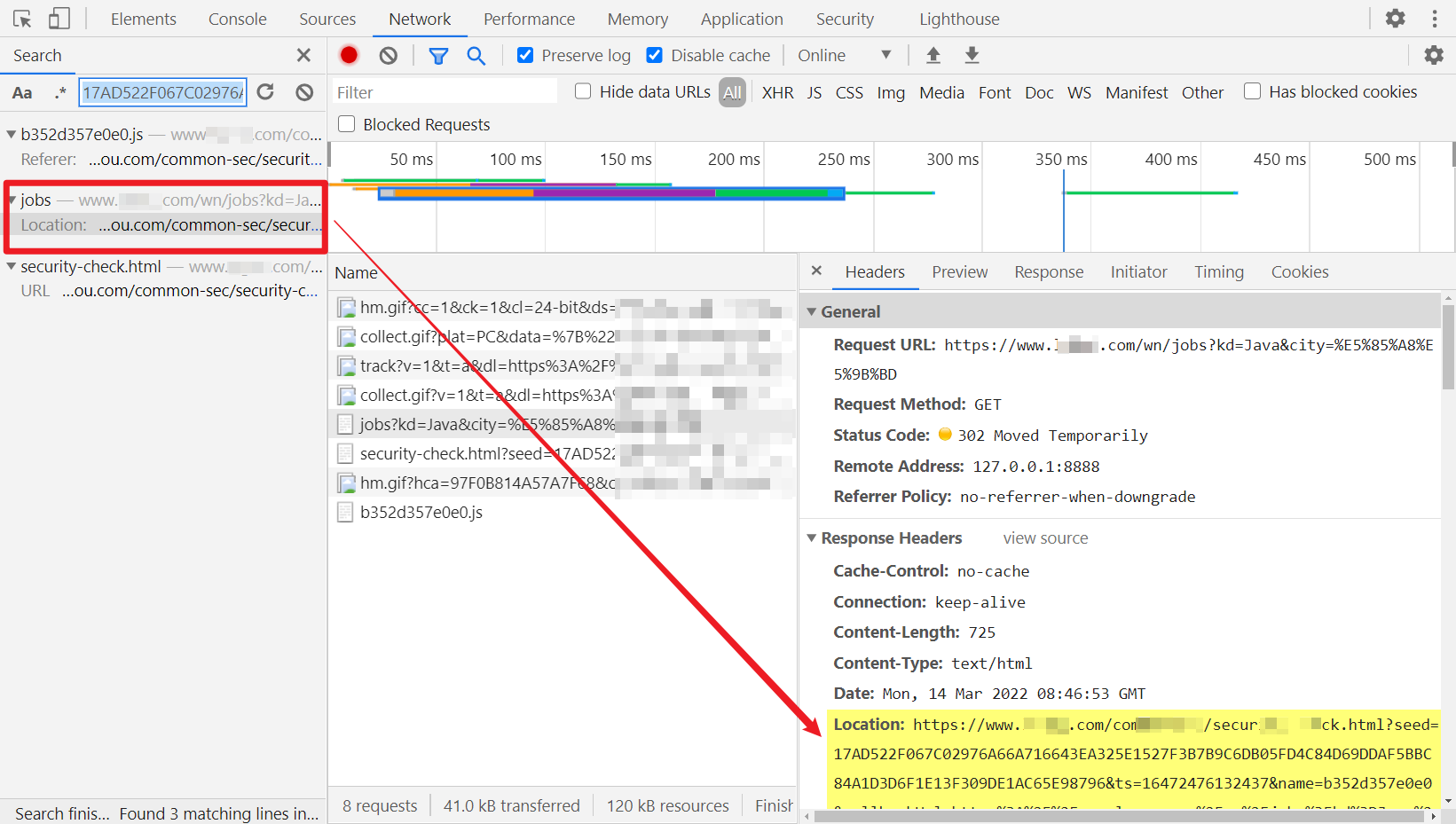
调试成功后,我们随便换一个搜索关键词,将得到的302跳转地址拿到这个 JS 中,加密一下,发现会报错,这说明混淆 JS 传入的参数和 JS 内容应该是相对应的,这里的做法是直接请求拿到这个 JS 文件内容,然后把要补的 window 和获取 __lg_stoken__ 的方法加进去,然后直接执行就行了。
获取 __lg_stoken__ 的关键代码如下(original_data 为原始搜索数据):
def get_lg_stoken(original_data: dict) -> str:
# 获取 cookie 中的 __lg_stoken__
token_url = "https://www.脱敏处理.com/wn/jobs"
token_headers = {
"Host": "www.脱敏处理.com",
"Referer": "https://www.脱敏处理.com/",
"User-Agent": UA
}
params = {
"kd": original_data["kd"],
"city": original_data["city"]
}
token_response = requests.get(url=token_url, params=params, headers=token_headers, cookies=global_cookies, allow_redirects=False)
if token_response.status_code != 302:
raise Exception("获取跳转链接异常!检查 global_cookies 是否已包含 __lg_stoken__!")
# 获取 302 跳转的地址
security_check_url = token_response.headers["Location"]
if "login" in security_check_url:
raise Exception("IP 被关进小黑屋啦!需要登录!请补全登录后的 Cookie,或者自行添加代理!")
parse_result = parse.urlparse(security_check_url)
# url 的参数为待加密对象
security_check_params = parse_result.query
# 取 name 参数,为混淆 js 的文件名
security_check_js_name = parse.parse_qs(security_check_params)["name"][0]
# 发送请求,获取混淆的 js
js_url = "https://www.脱敏处理.com/common-sec/dist/" + security_check_js_name + ".js"
js_headers = {
"Host": "www.脱敏处理.com",
"Referer": security_check_url,
"User-Agent": UA
}
js_response = requests.get(url=js_url, headers=js_headers, cookies=global_cookies).text
# 补全 js,添加 window 参数和一个方法,用于获取 __lg_stoken__ 的值
lg_js = """
window = {
"location": {
"hostname": "www.脱敏处理.com",
"search": '?%s'
}
}
function getLgStoken(){
return window.gt.prototype.a()
}
""" % security_check_params + js_response
lg_stoken = execjs.compile(lg_js).call("getLgStoken")
return lg_stoken
请求头参数
请求头参数比较多,有 traceparent、X-K-HEADER、X-S-HEADER、X-SS-REQ-HEADER、x-anit-forge-code、x-anit-forge-token,其中最后两个 x-anit 开头的参数是登录后才有的,实际测试中,即便是登录了,不加这两个好像也行。不过还是分析一下吧。
x-anit-forge-code / x-anit-forge-token
这两个值是首次点击搜索生成的,第一次访问搜索接口,返回的 HTML 里面夹杂了一个 JSON 文件,里面的 submitCode 和 submitToken 就是 x-anit-forge-code 和 x-anit-forge-token 的值,如下图所示:
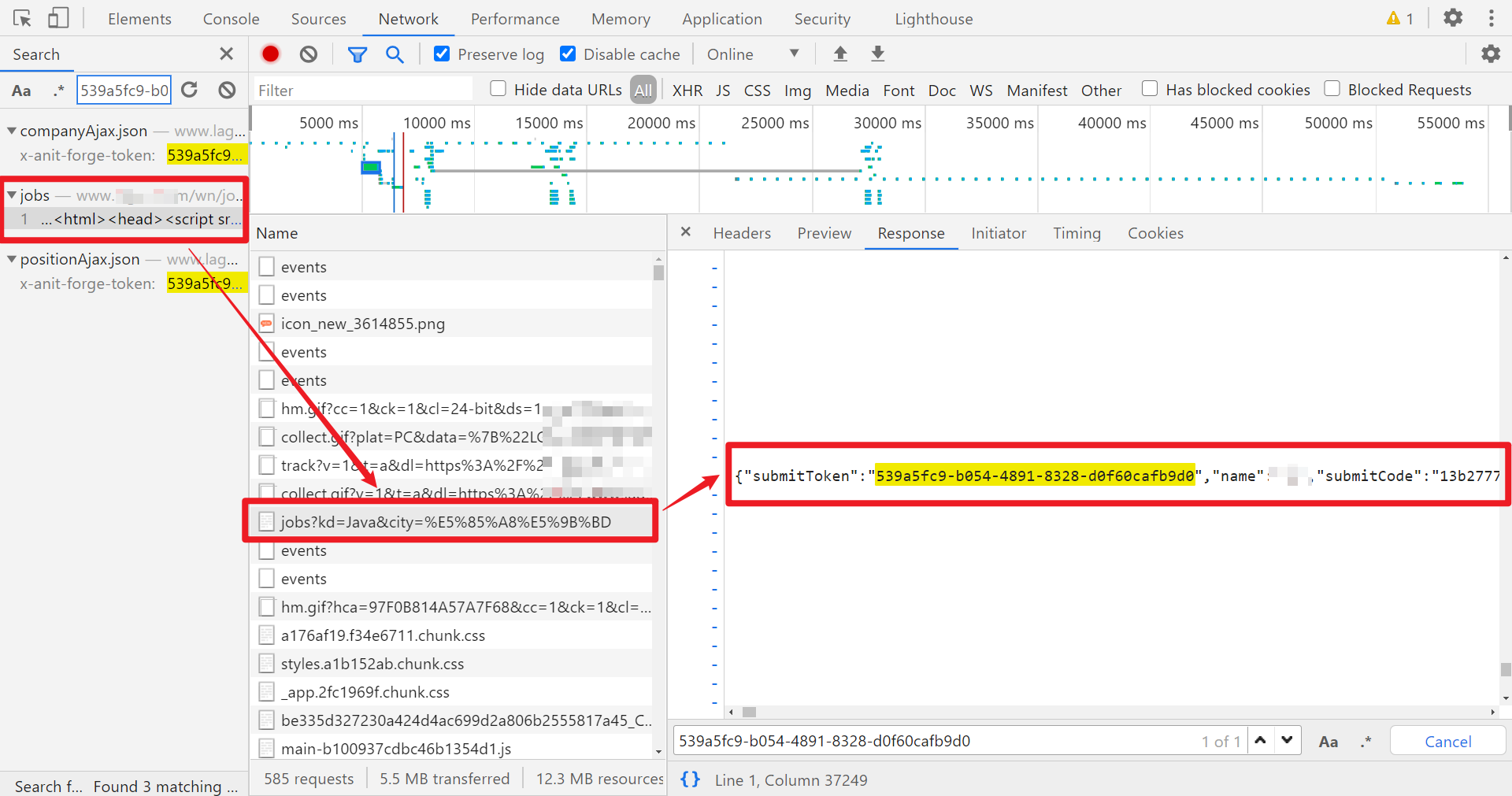
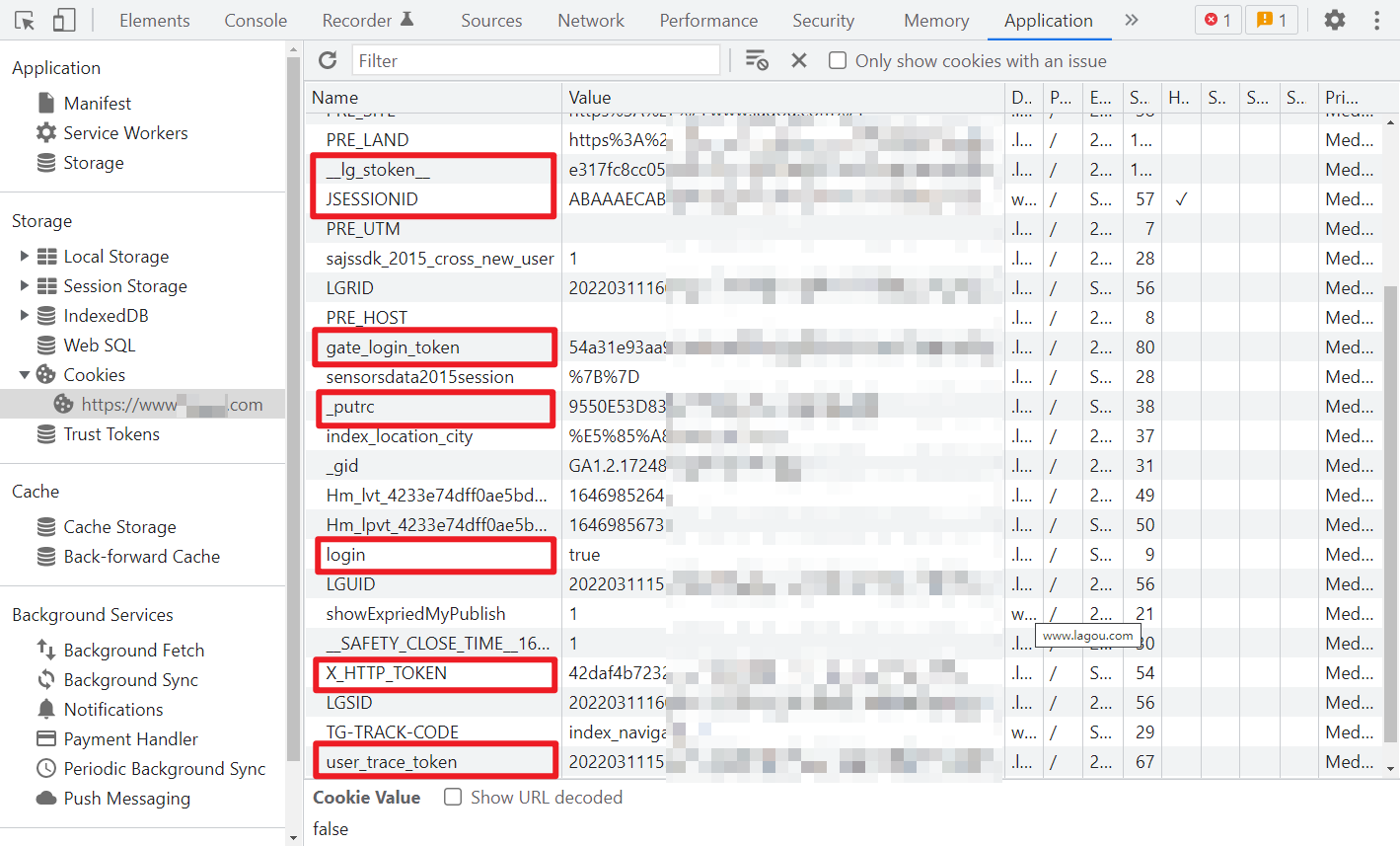
请求这个接口要注意带上登录后的 cookies,有用的只有四个值,正确的 cookies 类似于:
cookies = {
"login": "true",
"gate_login_token": "54a31e93aa904a6bb9731bxxxxxxxxxxxxxx",
"_putrc": "9550E53D830BE8xxxxxxxxxxxxxx",
"JSESSIONID": "ABAAAECABIEACCA79BFxxxxxxxxxxxxxx"
}
注意,JSESSIONID 即便不登录也会有,但是登录时应该会携带这个值,进行一个激活操作,如果你请求获取到的 submitCode、submitToken 为空,那么就有可能 JSESSIONID 是无效的,以上所有值都必须登录后复制过来!
获取 x-anit-forge-code、x-anit-forge-token 的关键代码如下(original_data 为原始搜索数据):
def update_x_anit(original_data: dict) -> None:
# 更新 x-anit-forge-code 和 x-anit-forge-token
url = "https://www.脱敏处理.com/wn/jobs"
headers = {
"Host": "www.脱敏处理.com",
"Referer": "https://www.脱敏处理.com/",
"User-Agent": UA
}
params = {
"kd": original_data["kd"],
"city": original_data["city"]
}
response = requests.get(url=url, params=params, headers=headers, cookies=global_cookies)
tree = etree.HTML(response.text)
next_data_json = json.loads(tree.xpath("//script[@id='__NEXT_DATA__']/text()")[0])
submit_code = next_data_json["props"]["tokenData"]["submitCode"]
submit_token = next_data_json["props"]["tokenData"]["submitToken"]
# 注意 JSESSIONID 必须是登录验证后的!
if not submit_code or not submit_token:
raise Exception("submitCode & submitToken 为空,请检查 JSESSIONID 是否正确!")
global x_anit
x_anit["x-anit-forge-code"] = submit_code
x_anit["x-anit-forge-token"] = submit_token
traceparent
同样的 Hook 大法,跟栈:
(function () {
var org = window.XMLHttpRequest.prototype.setRequestHeader;
window.XMLHttpRequest.prototype.setRequestHeader = function (key, value) {
console.log('Hook 捕获到 %s 设置 -> %s', key, value);
if (key == 'traceparent') {
debugger;
}
return org.apply(this, arguments);
};
})();
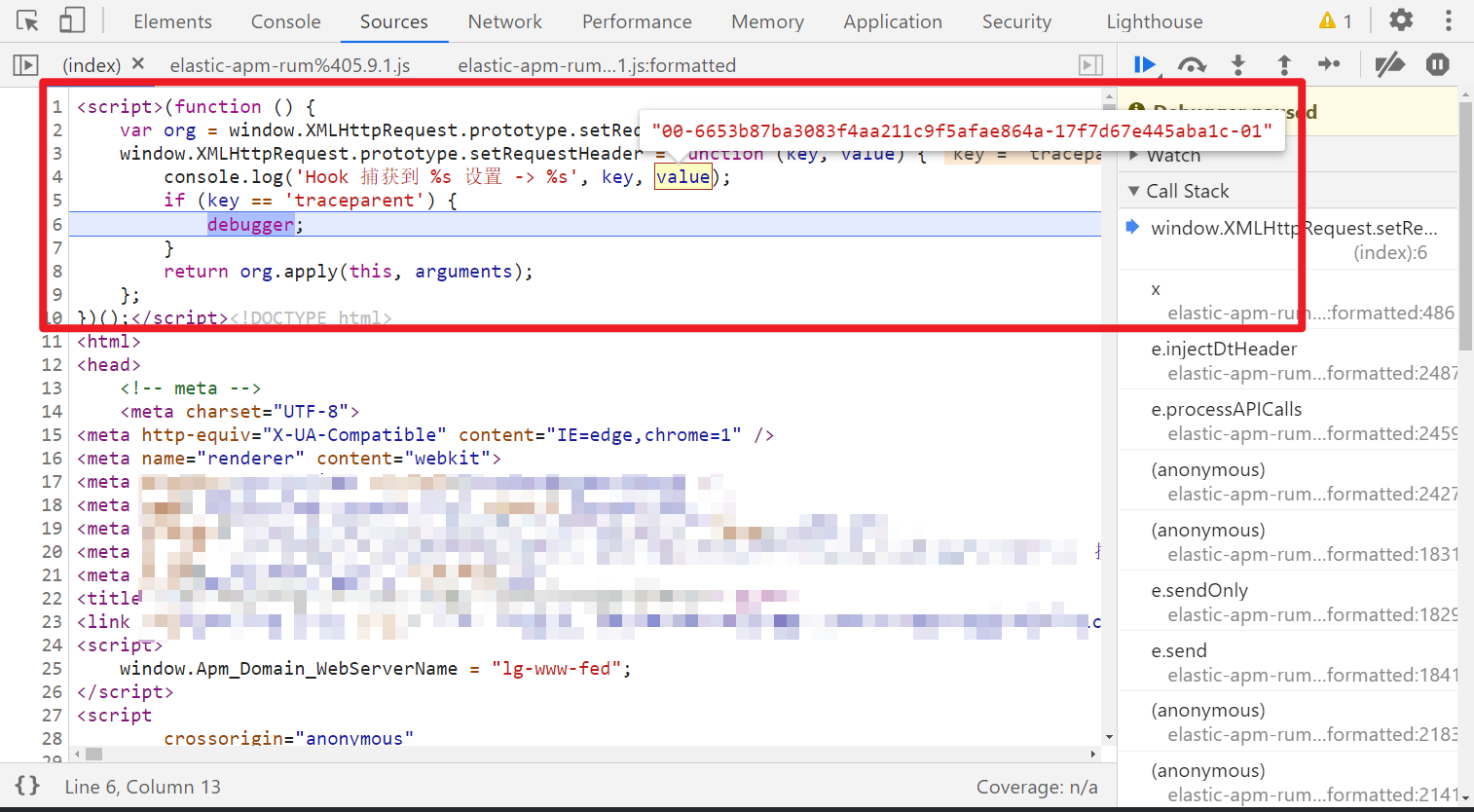
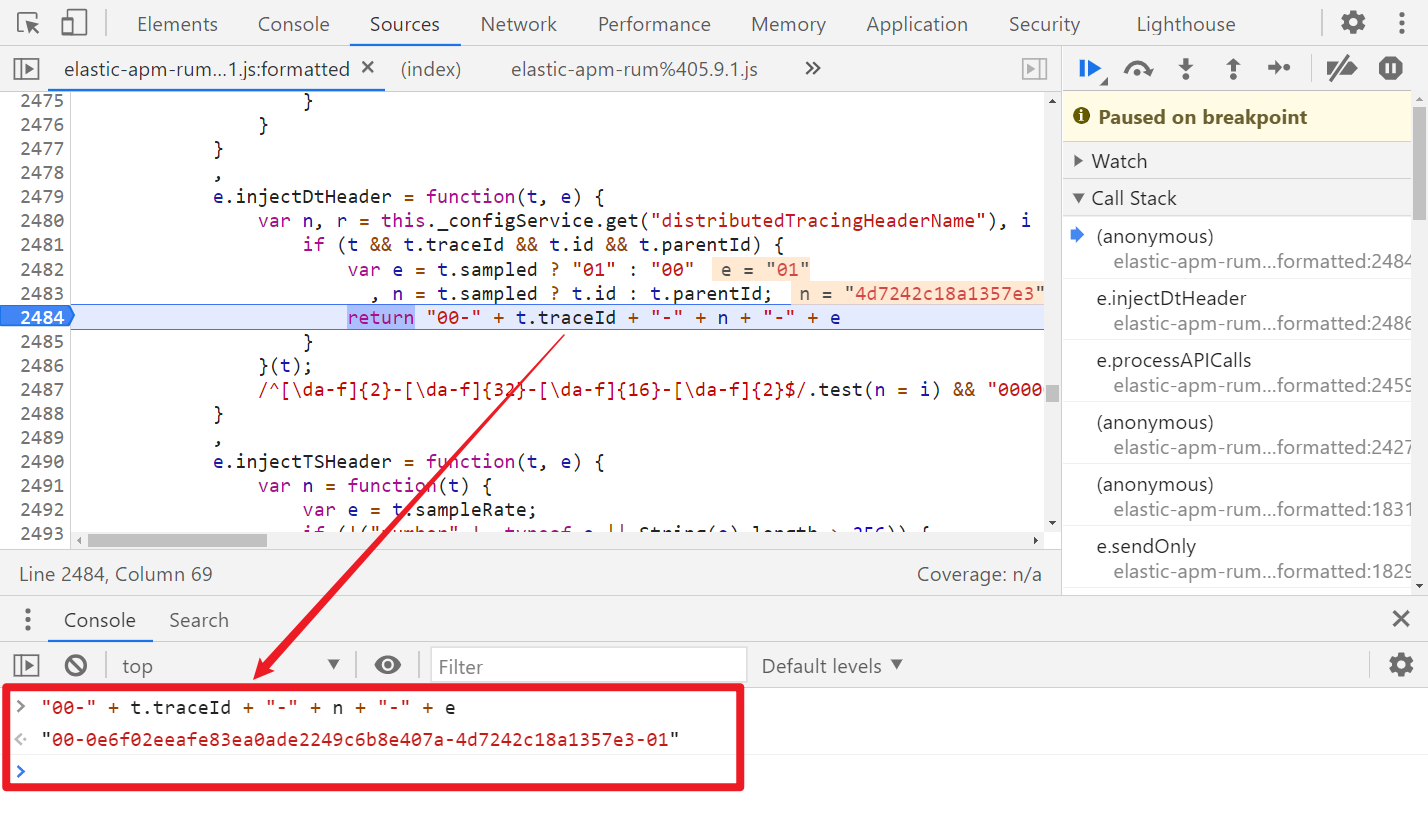
观察上面的代码,三元表达式,t.sampled 为 true,所以 e 值为 01,n 值为 t.id,重点在于 t.traceId 和 t.id 了,跟栈发现很难调,直接搜索关键字,可找到生成的位置:
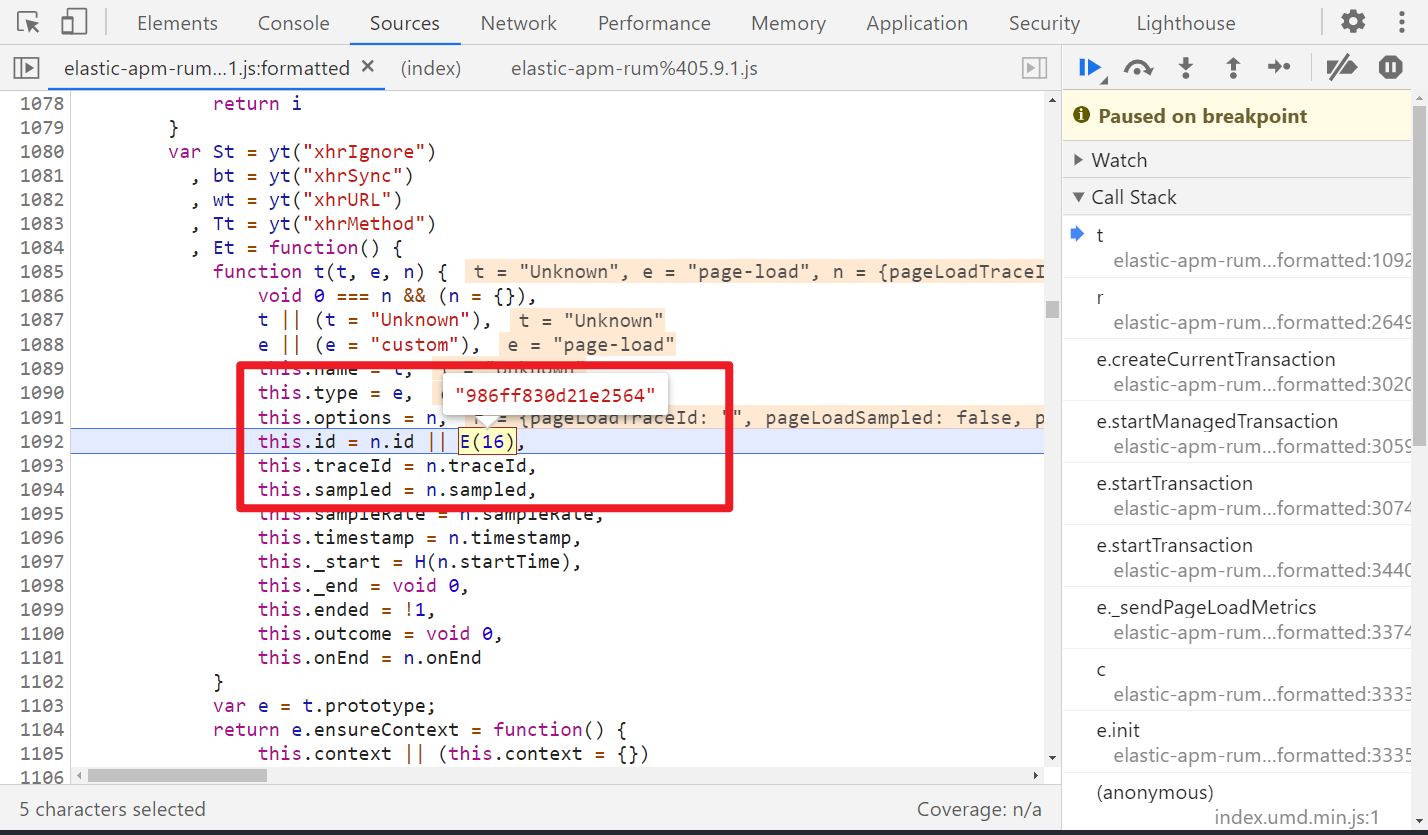
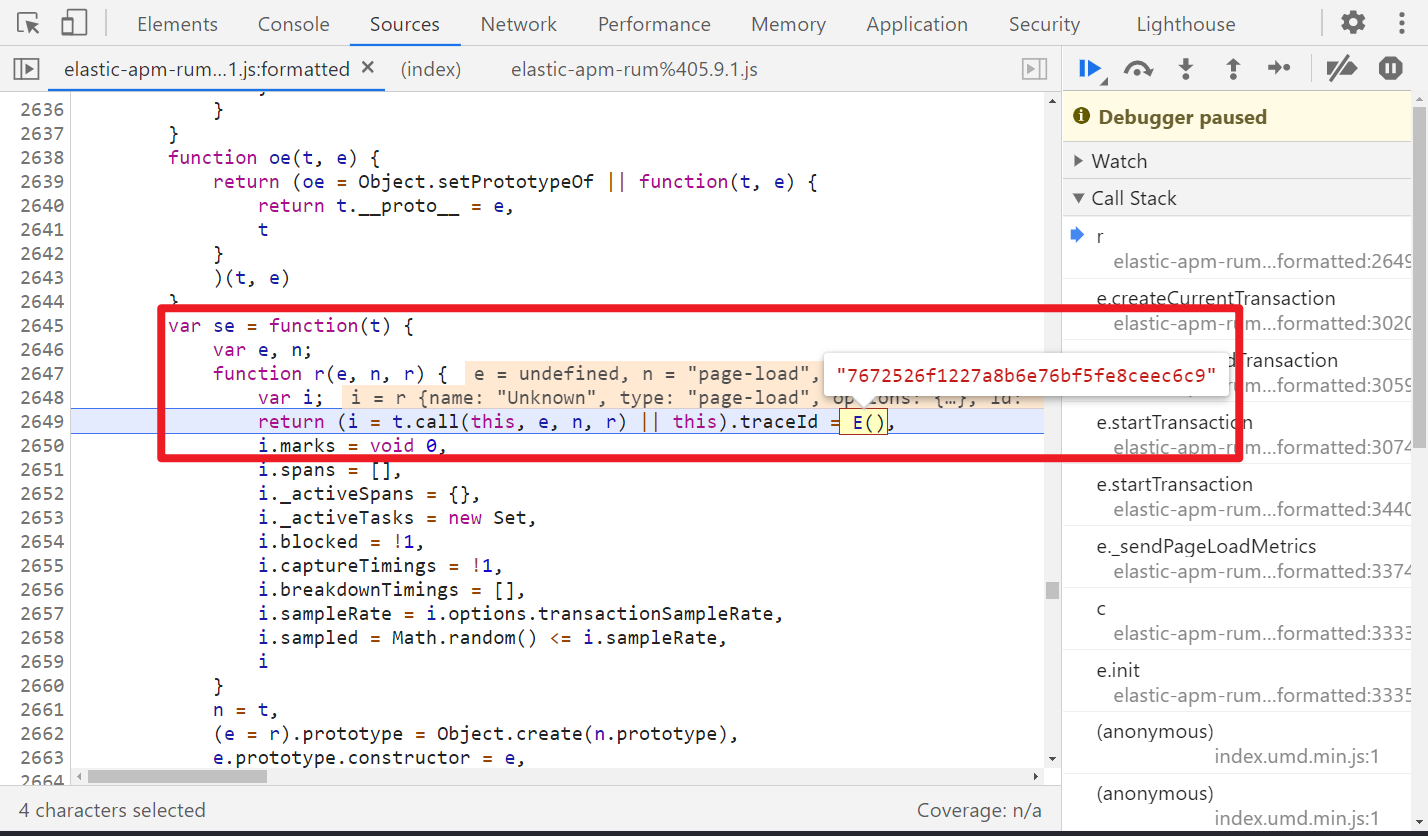
把 E() 方法扣出来就行了,改写一下即可:
getRandomValues = require('get-random-values')
function E(t) {
for (var b = [], w = 0; w < 256; ++w)
b[w] = (w + 256).toString(16).substr(1);
var T = new Uint8Array(16);
return function(t) {
for (var e = [], n = 0; n < t.length; n++)
e.push(b[t[n]]);
return e.join("")
}(getRandomValues(T)).substr(0, t)
}
function getTraceparent(){
return "00-" + E() + "-" + E(16) + "-" + "01"
}
// 测试输出
// console.log(getTraceparent())
X-K-HEADER / X-SS-REQ-HEADER
X-K-HEADER 和 X-SS-REQ-HEADER 数据是一样的,只不过后者是键值对形式,先直接全局搜索关键字,发现都是从本地拿这两个值,清除 cookie 就为空了,那么直接搜索值,发现是 agreement 这个接口返回的,secretKeyValue 值就是我们要的,有可能浏览器抓包直接搜索的话搜索不到,使用抓包工具,比如 Fiddler 就能搜到了,如下图所示:
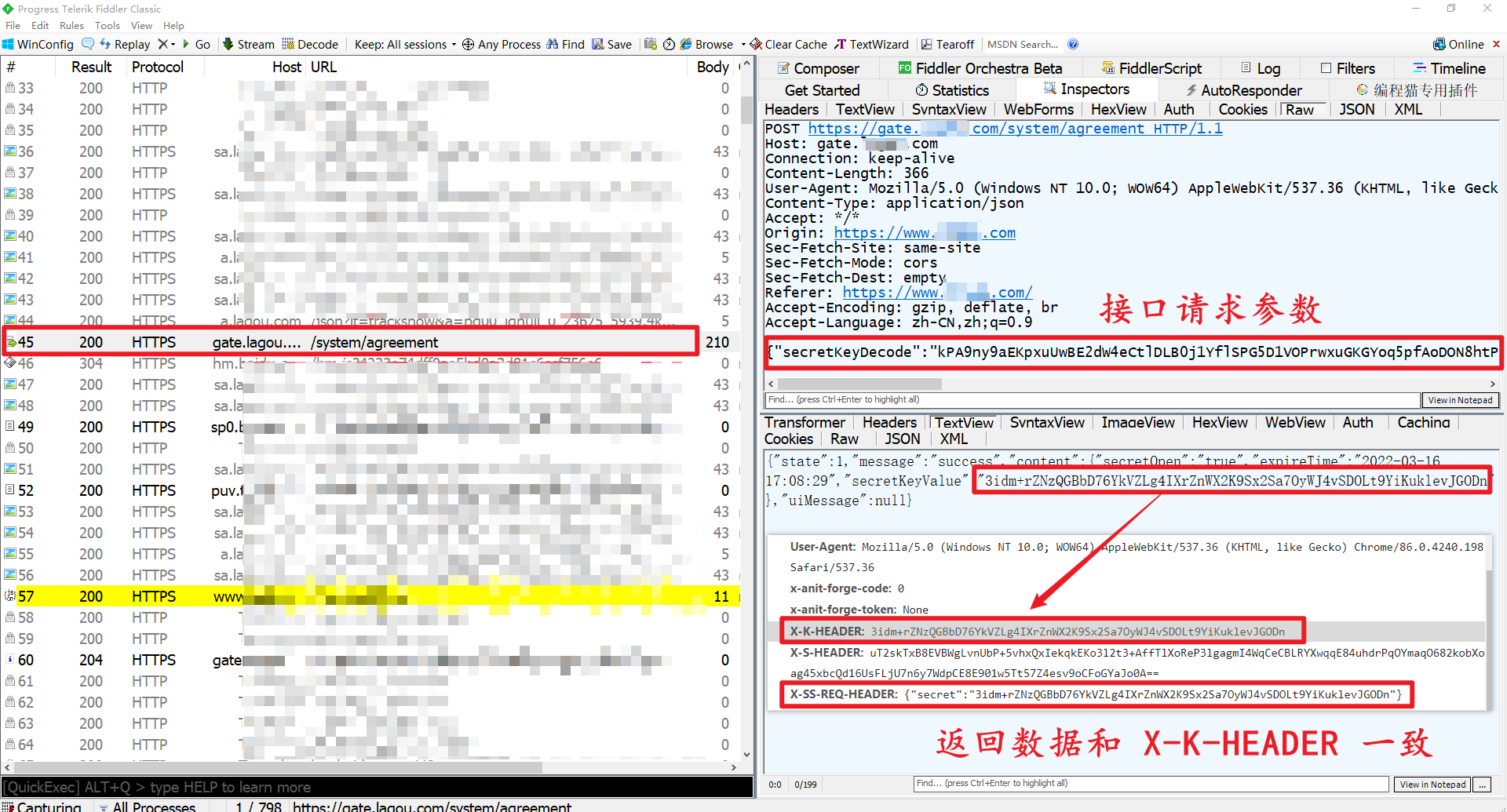
这个接口是 post 请求,请求带了一个 json 数据,secretKeyDecode,直接搜索关键字,就一个值,定位跟栈:
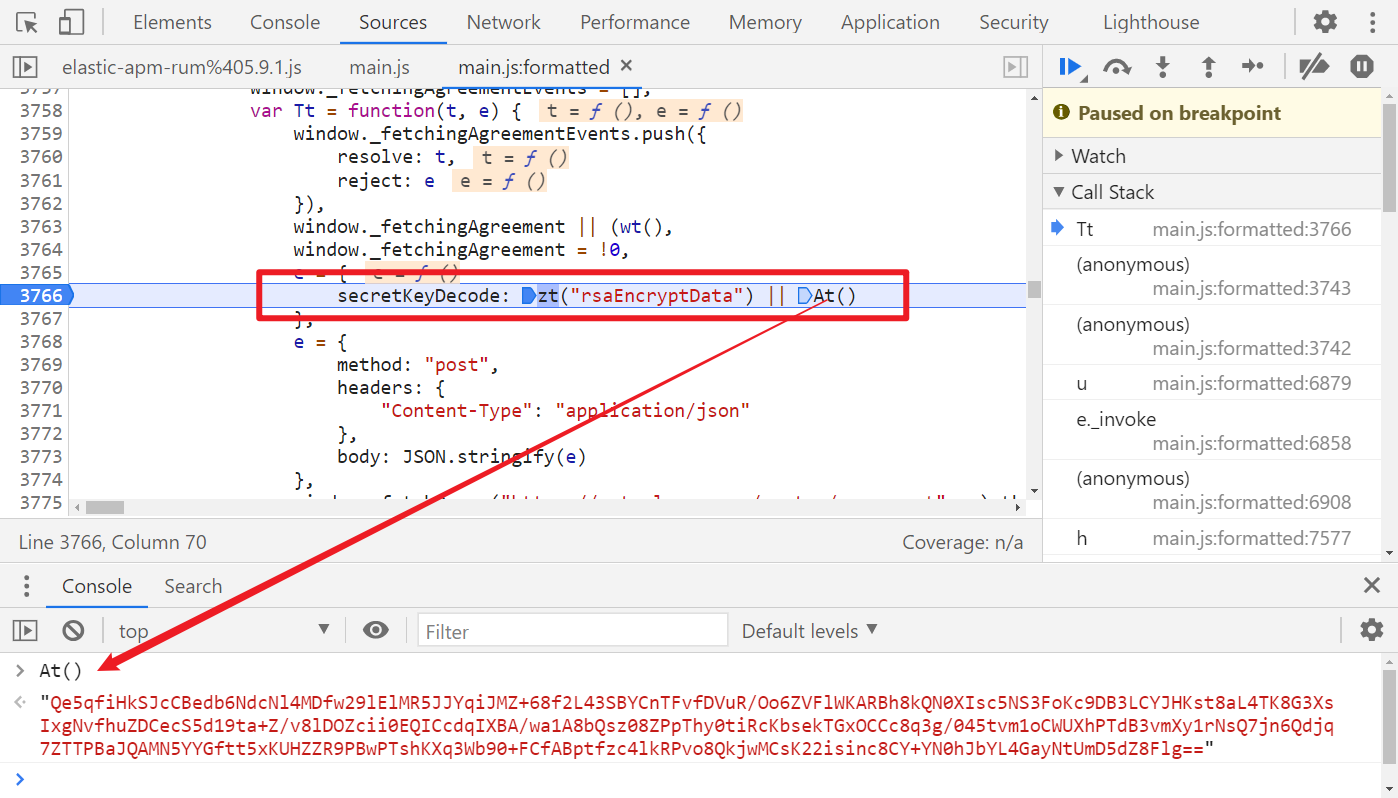
zt() 是从本地缓存中取,At() 是重新生成:
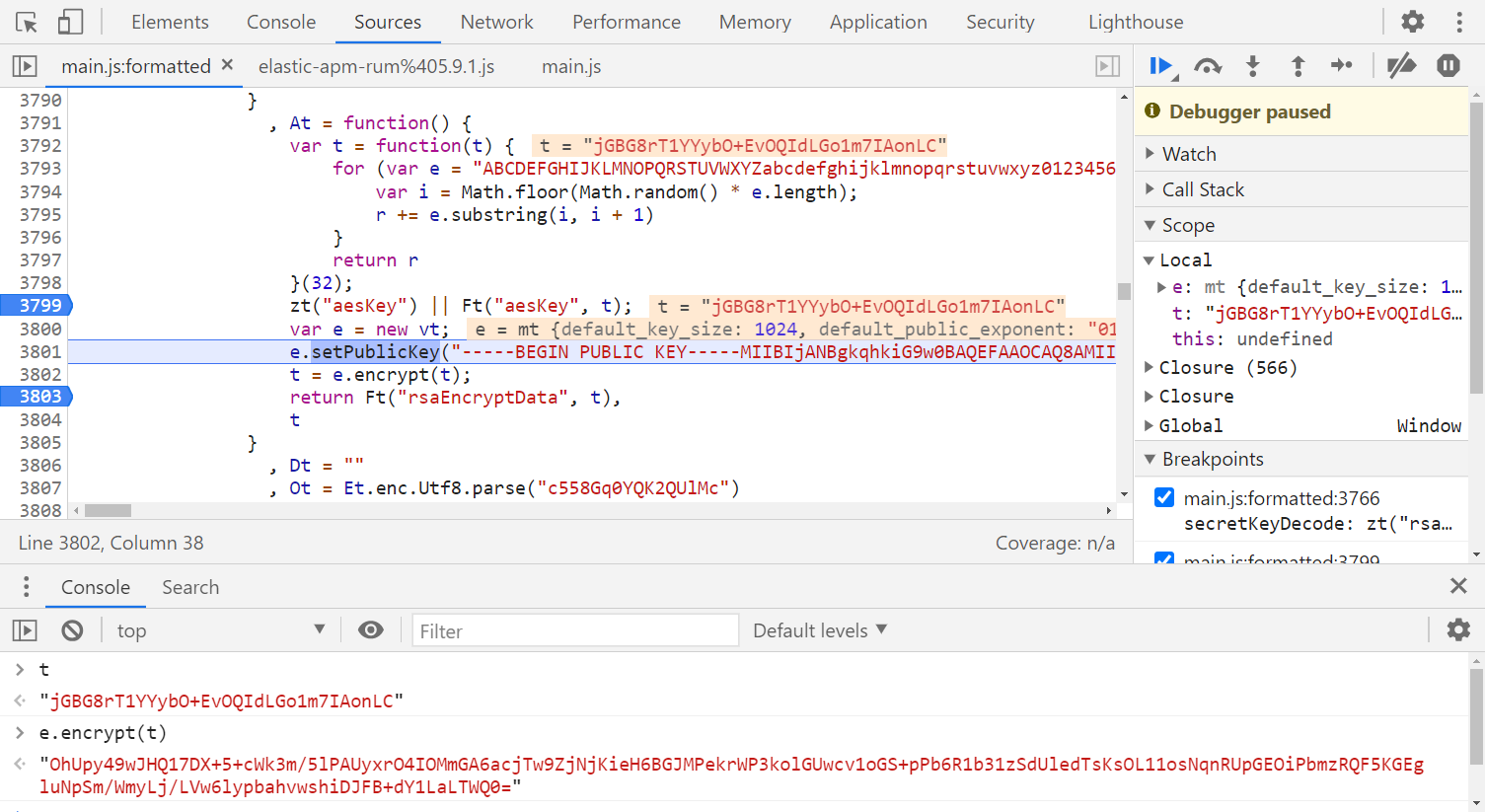
这里就非常明显了,t 是32位随机字符串,赋值为 aesKey,后面紧接着一个 RSA 加密了 aesKey,赋值为 rsaEncryptData,而 rsaEncryptData 就是前面 agreement 接口请求的 secretKeyValue 值。
这里先说一下,最终搜索职位请求的 data 和返回数据都是 AES 加密解密,会用到这个 aesKey,请求头的另一个参数 X-S-HEADER 也会用到,如果这个 key 没有经过 RSA 加密并通过 agreement 接口验证的话,是无效的,可以理解为 agreement 接口既是为了获取 X-K-HEADER 和 X-SS-REQ-HEADER,也是为了激活这个 aesKey。
这部分的 JS 代码和 Python 代码大致如下:
JSEncrypt = require("jsencrypt")
function getAesKeyAndRsaEncryptData() {
var aesKey = function (t) {
for (var e = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=", r = "", n = 0; n < t; n++) {
var i = Math.floor(Math.random() * e.length);
r += e.substring(i, i + 1)
}
return r
}(32);
var e = new JSEncrypt();
e.setPublicKey("-----BEGIN PUBLIC KEY-----MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAnbJqzIXk6qGotX5nD521Vk/24APi2qx6C+2allfix8iAfUGqx0MK3GufsQcAt/o7NO8W+qw4HPE+RBR6m7+3JVlKAF5LwYkiUJN1dh4sTj03XQ0jsnd3BYVqL/gi8iC4YXJ3aU5VUsB6skROancZJAeq95p7ehXXAJfCbLwcK+yFFeRKLvhrjZOMDvh1TsMB4exfg+h2kNUI94zu8MK3UA7v1ANjfgopaE+cpvoulg446oKOkmigmc35lv8hh34upbMmehUqB51kqk9J7p8VMI3jTDBcMC21xq5XF7oM8gmqjNsYxrT9EVK7cezYPq7trqLX1fyWgtBtJZG7WMftKwIDAQAB-----END PUBLIC KEY-----");
var rsaEncryptData = e.encrypt(aesKey);
return {
"aesKey": aesKey,
"rsaEncryptData": rsaEncryptData
}
}
// 测试输出
// console.log(getAesKeyAndRsaEncryptData())
def update_aes_key() -> None:
# 通过JS获取 AES Key,并通过接口激活,接口激活后会返回一个 secretKeyValue,后续请求头会用到
global aes_key, secret_key_value
url = "https://gate.脱敏处理.com/system/agreement"
headers = {
"Content-Type": "application/json",
"Host": "gate.脱敏处理.com",
"Origin": "https://www.脱敏处理.com",
"Referer": "https://www.脱敏处理.com/",
"User-Agent": UA
}
encrypt_data = lagou_js.call("getAesKeyAndRsaEncryptData")
aes_key = encrypt_data["aesKey"]
rsa_encrypt_data = encrypt_data["rsaEncryptData"]
data = {"secretKeyDecode": rsa_encrypt_data}
response = requests.post(url=url, headers=headers, json=data).json()
secret_key_value = response["content"]["secretKeyValue"]
X-S-HEADER
X-S-HEADER 你每次翻页都会改变,直接搜索关键字可定位:
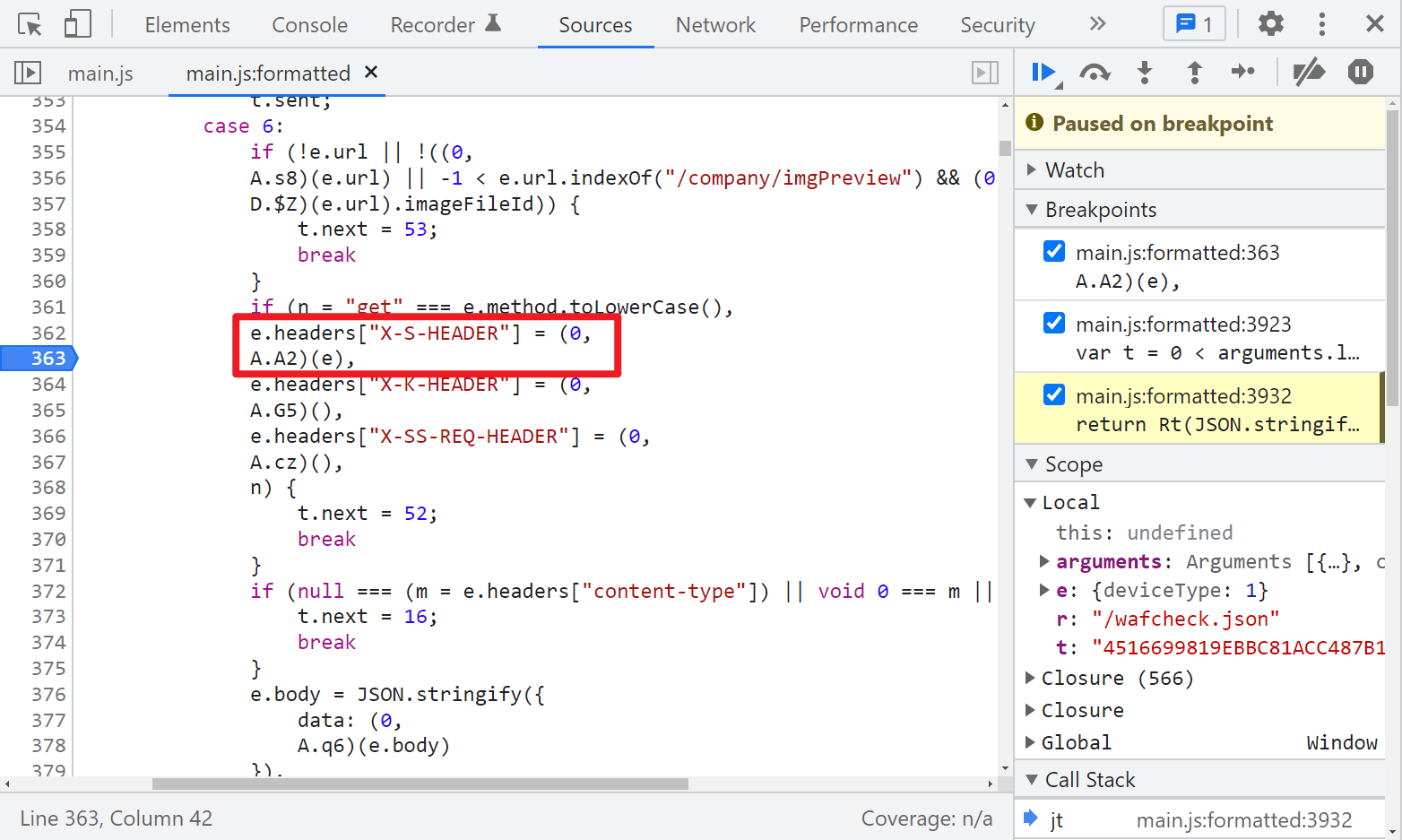
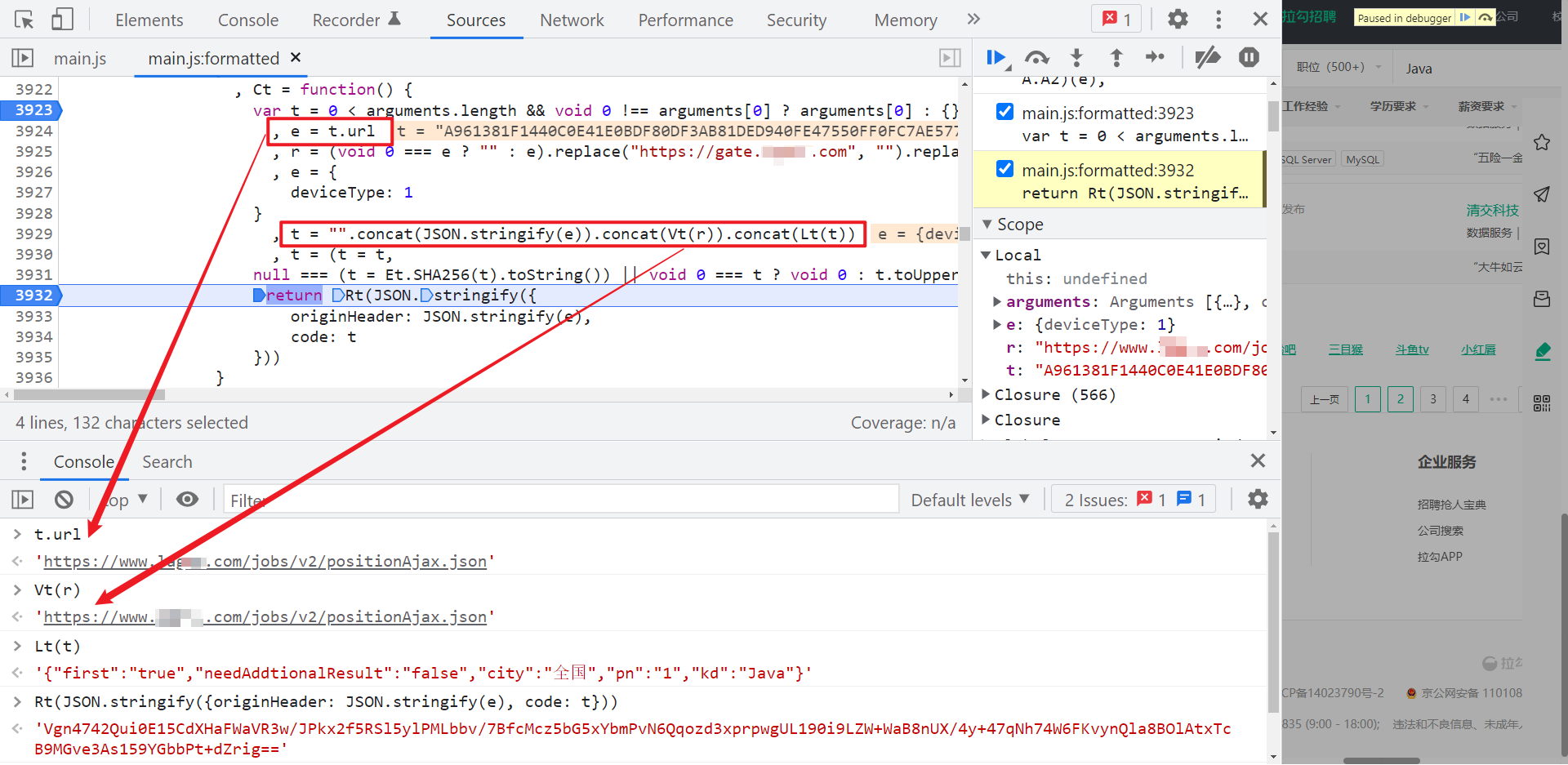
中间有一个 SHA256 加密,最后返回的 Rt(JSON.stringify({originHeader: JSON.stringify(e), code: t})) 就是 X-S-HEADER 的值了,Rt() 是一个 AES 加密,比较关键的,Vt(r) 是一个 URL,比如你搜索职位就是 positionAjax.json,搜索公司就是 companyAjax.json,可根据实际情况定制,然后 Lt(t) 就是搜索信息,字符串形式,包含了城市、页码、关键词等。
获取 X-S-HEADER 的 JS 代码大致如下:
CryptoJS = require('crypto-js')
jt = function(aesKey, originalData, u) {
var e = {deviceType: 1}
, t = "".concat(JSON.stringify(e)).concat(u).concat(JSON.stringify(originalData))
, t = (t = t, null === (t = CryptoJS.SHA256(t).toString()) || void 0 === t ? void 0 : t.toUpperCase());
return Rt(JSON.stringify({
originHeader: JSON.stringify(e),
code: t
}), aesKey)
}
Rt = function (t, aesKey) {
var Ot = CryptoJS.enc.Utf8.parse("c558Gq0YQK2QUlMc"),
Dt = CryptoJS.enc.Utf8.parse(aesKey),
t = CryptoJS.enc.Utf8.parse(t);
t = CryptoJS.AES.encrypt(t, Dt, {
iv: Ot,
mode: CryptoJS.mode.CBC,
padding: CryptoJS.pad.Pkcs7
});
return t.toString()
};
function getXSHeader(aesKey, originalData, u){
return jt(aesKey, originalData, u)
}
// 测试样例
// var url = "https://www.脱敏处理.com/jobs/v2/positionAjax.json"
// var aesKey = "dgHY1qVeo/Z0yDaF5WV/EEXxYiwbr5Jt"
// var originalData = {"first": "true", "needAddtionalResult": "false", "city": "全国", "pn": "2", "kd": "Java"}
// console.log(getXSHeader(aesKey, originalData, url))
请求/返回数据解密
前面抓包我们已经发现 positionAjax.json 是 POST 请求,Form Data 中的数据是加密的,返回的 data 也是加密的,我们分析请求头参数的时候,就涉及到 AES 加密解密,所以我们直接搜索 AES.encrypt、AES.decrypt,下断点调试:
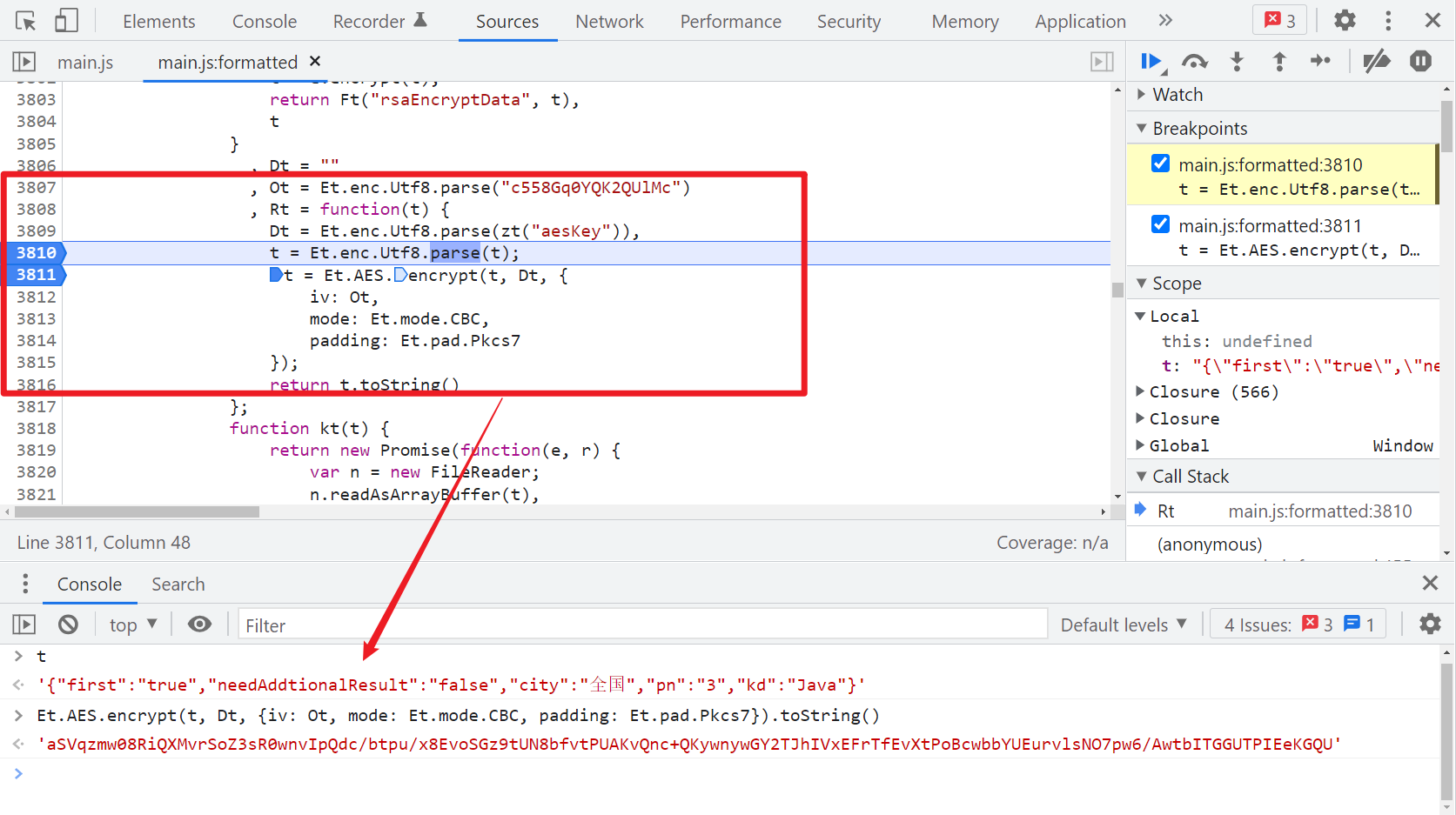
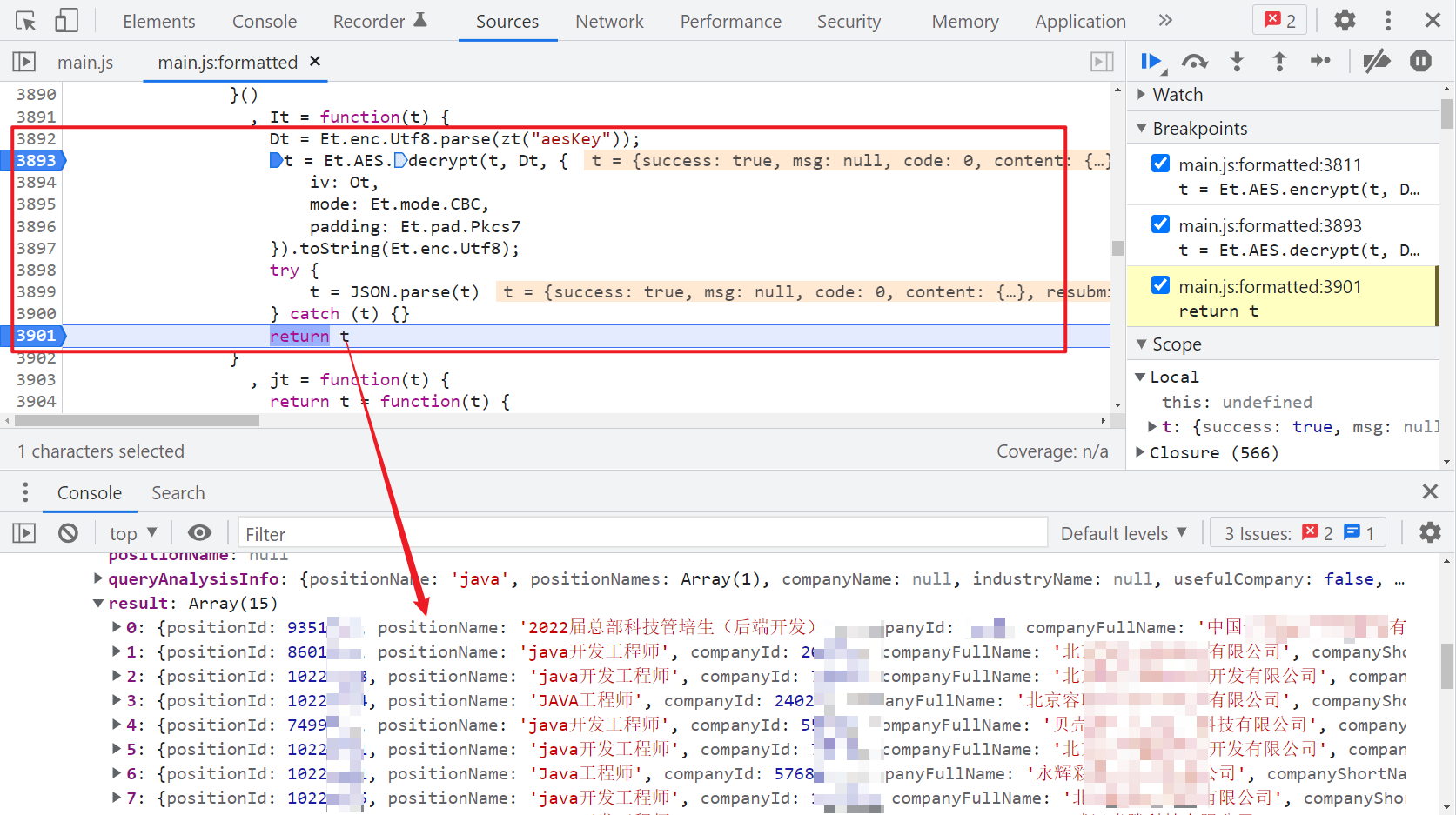
非常明显了,这部分的 JS 代码大致如下:
CryptoJS = require('crypto-js')
function getRequestData(aesKey, originalData){
return Rt(JSON.stringify(originalData), aesKey)
}
function getResponseData(encryptData, aesKey){
return It(encryptData, aesKey)
}
Rt = function (t, aesKey) {
var Ot = CryptoJS.enc.Utf8.parse("c558Gq0YQK2QUlMc"),
Dt = CryptoJS.enc.Utf8.parse(aesKey),
t = CryptoJS.enc.Utf8.parse(t);
t = CryptoJS.AES.encrypt(t, Dt, {
iv: Ot,
mode: CryptoJS.mode.CBC,
padding: CryptoJS.pad.Pkcs7
});
return t.toString()
};
It = function(t, aesKey) {
var Ot = CryptoJS.enc.Utf8.parse("c558Gq0YQK2QUlMc"),
Dt = CryptoJS.enc.Utf8.parse(aesKey);
t = CryptoJS.AES.decrypt(t, Dt, {
iv: Ot,
mode: CryptoJS.mode.CBC,
padding: CryptoJS.pad.Pkcs7
}).toString(CryptoJS.enc.Utf8);
try {
t = JSON.parse(t)
} catch (t) {}
return t
}
// 测试样例,注意,encryptedData 数据太多,省略了,直接运行解密是会报错的
// var aesKey = "dgHY1qVeo/Z0yDaF5WV/EEXxYiwbr5Jt"
// var encryptedData = "r4MqbduYxu3Z9sFL75xDhelMTCYPHLluKaurYgzEXlEQ1Rg......"
// var originalData = {"first": "true", "needAddtionalResult": "false", "city": "全国", "pn": "2", "kd": "Java"}
// console.log(getRequestData(aesKey, originalData))
// console.log(getResponseData(encryptedData, aesKey))
大致的 Python 代码如下:
def get_header_params(original_data: dict) -> dict:
# 后续请求数据所需的请求头参数
# 职位搜索 URL,如果是搜索公司,那就是 https://www.脱敏处理.com/jobs/companyAjax.json,根据实际情况更改
u = "https://www.脱敏处理.com/jobs/v2/positionAjax.json"
return {
"traceparent": lagou_js.call("getTraceparent"),
"X-K-HEADER": secret_key_value,
"X-S-HEADER": lagou_js.call("getXSHeader", aes_key, original_data, u),
"X-SS-REQ-HEADER": json.dumps({"secret": secret_key_value})
}
def get_encrypted_data(original_data: dict) -> str:
# AES 加密原始数据
encrypted_data = lagou_js.call("getRequestData", aes_key, original_data)
return encrypted_data
def get_data(original_data: dict, encrypted_data: str, header_params: dict) -> dict:
# 携带加密后的请求数据和完整请求头,拿到密文,AES 解密得到明文职位信息
url = "https://www.脱敏处理.com/jobs/v2/positionAjax.json"
referer = parse.urljoin("https://www.脱敏处理.com/wn/jobs?", parse.urlencode(original_data))
headers = {
# "content-type": "application/x-www-form-urlencoded; charset=UTF-8",
"Host": "www.脱敏处理.com",
"Origin": "https://www.脱敏处理.com",
"Referer": referer,
"traceparent": header_params["traceparent"],
"User-Agent": UA,
"X-K-HEADER": header_params["X-K-HEADER"],
"X-S-HEADER": header_params["X-S-HEADER"],
"X-SS-REQ-HEADER": header_params["X-SS-REQ-HEADER"],
}
# 添加 x-anit-forge-code 和 x-anit-forge-token
headers.update(x_anit)
data = {"data": encrypted_data}
response = requests.post(url=url, headers=headers, cookies=global_cookies, data=data).json()
if "status" in response:
if not response["status"] and "操作太频繁" in response["msg"]:
raise Exception("获取数据失败!msg:%s!可以尝试补全登录后的 Cookies,或者添加代理!" % response["msg"])
else:
raise Exception("获取数据异常!请检查数据是否完整!")
else:
response_data = response["data"]
decrypted_data = lagou_js.call("getResponseData", response_data, aes_key)
return decrypted_data
最终整合所有代码,成功拿到数据:
逆向小技巧
浏览器开发者工具 Application - Storage 选项,可以一键清除所有 Cookies,也可以自定义存储配额:
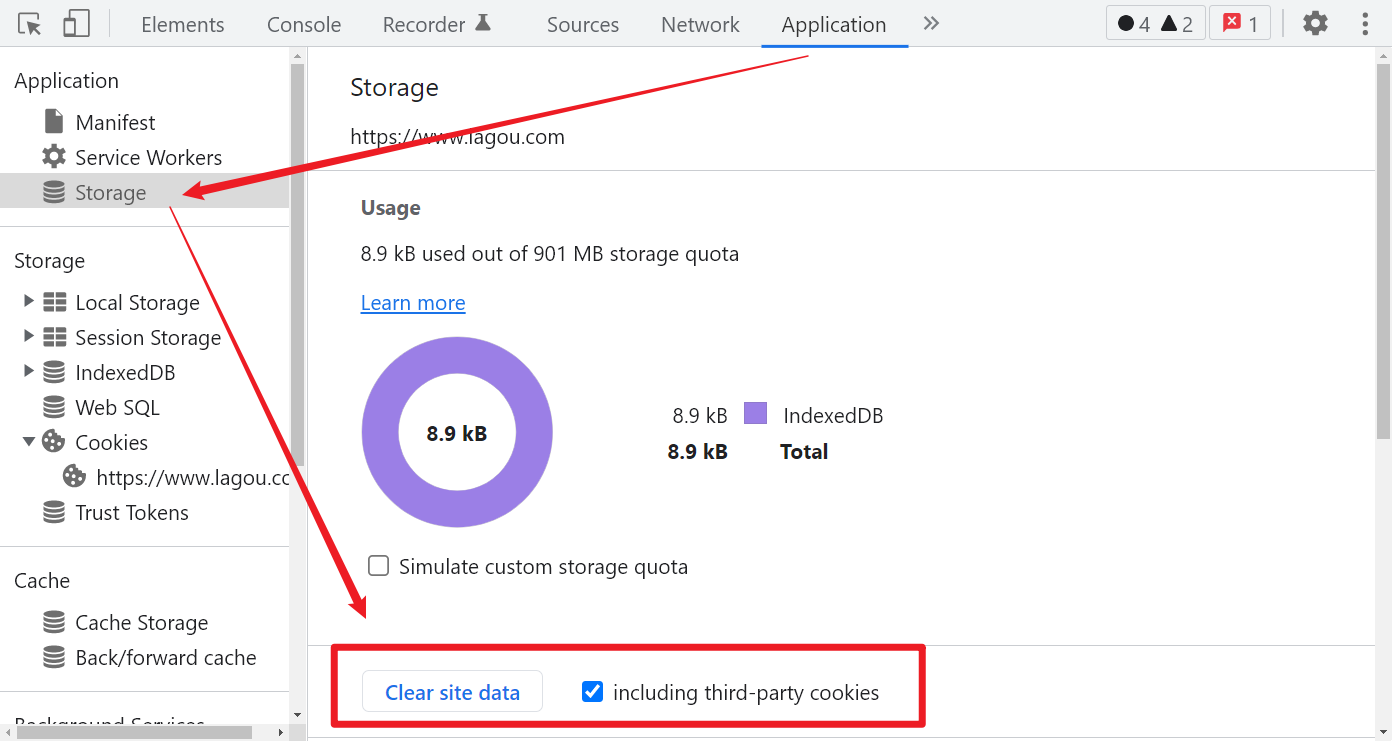
Storage - Cookies 可以查看每个站点的所有 Cookies,HttpOnly 打勾的表示是服务器返回的,选中一条 Cookie,右键可以直接定位到哪个请求带了这个 Cookie,也可以直接编辑值,还可以删除单个 Cookie,当你登录了账号,但又需要清除某个 Cookie,且不想重新登录时,这个功能或许有用。
完整代码
文中给出了部分关键代码,不能直接运行,部分细节可能没提及到,完整代码已放 GitHub,均有详细注释,欢迎 Star。所有内容仅供学习交流,严禁用于商业用途、非法用途,否则由此产生的一切后果均与作者无关,在仓库中下载的文件学习完毕之后请于 24 小时内删除!
仓库地址:https://github.com/kgepachong/crawler/
常见问题
JS 代码里引用了三个库,npm install 安装一下即可,如果安装了还提示找不到库,那就是路径问题,推荐在当前目录下执行命令安装,或者在 Python 代码里指定完整路径,具体方法可自行百度。
jsencrypt 这个库,本地运行可能会报错
window is not defined,在 \node_modules\jsencrypt\bin\jsencrypt.js 源码中加入var window = global;即可,这是实现 RSA 加密的库,当然还有很多其他实现方法或者库,都可以。execjs 执行 JS 的时候,可能会报编码错误
"gbk" can't decode byte...,有两种解决方法,一是找到官方源码 subprocess.py,搜索encoding=None改成encoding='utf-8',二是直接在 Python 代码里面加入以下代码即可:
import subprocess
from functools import partial
subprocess.Popen = partial(subprocess.Popen, encoding="utf-8")

【JS 逆向百例】拉勾网爬虫,traceparent、__lg_stoken__、X-S-HEADER 等参数分析的更多相关文章
- 我去!爬虫遇到JS逆向AES加密反爬,哭了
今天准备爬取网页时,遇到『JS逆向AES加密』反爬.比如这样的: 在发送请求获取数据时,需要用到参数params和encSecKey,但是这两个参数经过JS逆向AES加密而来. 既然遇到了这个情况,那 ...
- 网络爬虫之记一次js逆向解密经历
1 引言 数月前写过某网站(请原谅我的掩耳盗铃)的爬虫,这两天需要重新采集一次,用的是scrapy-redis框架,本以为二次爬取可以轻松完成的,可没想到爬虫启动没几秒,出现了大堆的重试提示,心里顿时 ...
- 爬虫05 /js加密/js逆向、常用抓包工具、移动端数据爬取
爬虫05 /js加密/js逆向.常用抓包工具.移动端数据爬取 目录 爬虫05 /js加密/js逆向.常用抓包工具.移动端数据爬取 1. js加密.js逆向:案例1 2. js加密.js逆向:案例2 3 ...
- 这个爬虫JS逆向加密任务,你还不来试试?逆向入门级,适合一定爬虫基础的人
友情提示:在博客园更新比较慢,有兴趣的关注知识图谱与大数据公众号吧.这次选择苏宁易购登录密码加密,如能调试出来代表你具备了一定的JS逆向能力,初学者建议跟着内容调试一波,尽量独自将JS代码抠出来,实在 ...
- python爬虫之企某科技JS逆向
python爬虫简单js逆向案例在学习时需要用到数据,学习了python爬虫知识,但是在用爬虫程序的时候就遇到了问题.具体如下,在查看请求数据时发现返回的数据是加密的信息,现将处理过程记录如下,以便大 ...
- python爬虫之JS逆向
Python爬虫之JS逆向案例 由于在爬取数据时,遇到请求头限制属性为动态生成,现将解决方式整理如下: JS逆向有两种思路: 一种是整理出js文件在Python中直接使用execjs调用js文件(可见 ...
- python爬虫之JS逆向某易云音乐
Python爬虫之JS逆向采集某易云音乐网站 在获取音乐的详情信息时,遇到请求参数全为加密的情况,现解解决方案整理如下: JS逆向有两种思路: 一种是整理出js文件在Python中直接使用execjs ...
- 兄弟,你爬虫基础这么好,需要研究js逆向了,一起吧(有完整JS代码)
这几天的确有空了,看更新多快,专门研究了一下几个网站登录中密码加密方法,比起滑块验证码来说都相对简单,适合新手js逆向入门,大家可以自己试一下,试不出来了再参考我的js代码.篇幅有限,完整的js代码在 ...
- 爬虫必看,每日JS逆向之爱奇艺密码加密,今天你练了吗?
友情提示:优先在公众号更新,在博客园更新较慢,有兴趣的关注一下知识图谱与大数据公众号,本次目标是抠出爱奇艺passwd加密JS代码,如果你看到了这一篇,说明你对JS逆向感兴趣,如果是初学者,那不妨再看 ...
- 通过JS逆向ProtoBuf 反反爬思路分享
前言 本文意在记录,在爬虫过程中,我首次遇到Protobuf时的一系列问题和解决问题的思路. 文章编写遵循当时工作的思路,优点:非常详细,缺点:文字冗长,描述不准确 protobuf用在前后端传输,在 ...
随机推荐
- Axure 形状交互
- DNS--安装&&配置文件
1 下载 #下载服务yum -y install bind#下载解析工具yum -y install bind-utils 2 配置文件 主配置文件 /etc/named.conf 区配置文件 /va ...
- 阿里云的“终端云化”实践,基于ENS进行边缘架构构建
终端无休止的更新迭代,是软件对计算资源的需求激增. 作者|王广芳 编辑|IMMENSE 终端云化:打破硬件的桎梏 近几年,"终端云化"技术开始规模化落地,其核心思想是"计 ...
- Codeforces Round #679 (Div. 2, based on Technocup 2021 Elimination Round 1) (个人题解)
1434A. Finding Sasuke // Author : RioTian // Time : 20/10/25 #include <bits/stdc++.h> using na ...
- Java字节码与反射机制
字节码(Byte Code)是Java语言跨平台特性的重要保障,也是反射机制的重要基础.通过反射机制,我们不仅能看到一个类的属性和方法,还能在一个类里调用另外一个类的方法,但前提是我们得有相关类的字节 ...
- 一、mysql5.7 rpm 安装(单机)
一.下载需要的rpm包mysql-community-client-5.7.26-1.el6.x86_64.rpmmysql-community-common-5.7.26-1.el6.x86_64. ...
- SpringBoot 动态多线程并发定时任务
一.简介 实现定时任务有多种方式: Timer:jdk 中自带的一个定时调度类,可以简单的实现按某一频度进行任务执行.提供的功能比较单一,无法实现复杂的调度任务. ScheduledExecutorS ...
- gitlab安装,移库,升级
概述 最近因为机房原因,需要把我们的本地代码库做移库操作. 针对gitlab的安装升级操作重新进行了梳理,记录一下. 环境 CENTOS6 CENTOS7 gitlab-ce-8.14.2 GITLA ...
- 定期发送邮件功能-outlook与腾讯邮箱
一.背景:定期发送邮件功能挺好用的,可以帮忙我们在特殊的时间点发送邮件,以及实现无人推送的功能 二.outlook的实现1.首先编辑好邮件保存至草稿 2.选项-延迟传递,设置不早于传递的时间,点击发送 ...
- Java21 + SpringBoot3集成Spring Data JPA
.markdown-body { line-height: 1.75; font-weight: 400; font-size: 16px; overflow-x: hidden; color: rg ...