[转帖]细说ASCII、GB2312/GBK/GB18030、Unicode、UTF-8/UTF-16/UTF-32编码
参考:
《编码标准-GB2312 GBK GB18030》
《字符编码笔记:ASCII,Unicode 和 UTF-8》
《字体编辑用中日韩汉字Unicode编码表》
《程序员趣味读物:谈谈Unicode编码》
1. 最简单的ASCII码。
ASCII码使用1个字节记录了128个常用的字符(ASCII规定第一个bit位固定为0,2^7=128),包含控制字符(如:键盘的空格、Tab键),以及打印字符(如:数字、英文字母等)。
看下面的表格:
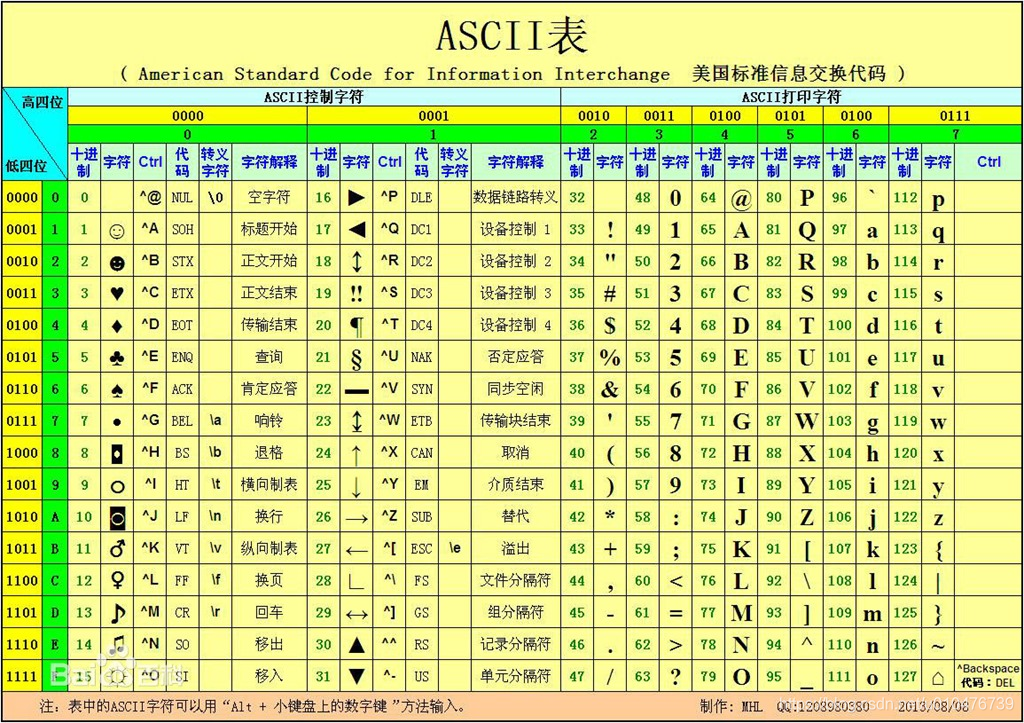
2. 汉字编码,从GB2312说起
1980年,为了使每个汉字有一个全国统一的代码,我国颁布了汉字编码的国家标准:GB2312-80《信息交换用汉字编码字符集》基本集,这个字符集是我国中文信息处理技术的发展基础,也是国内所有汉字系统的统一标准。
在这个标准中,我们规定使用两个字节表示一个字符,又为了兼容ASCII码,规定每个字节的首bit位固定为1。这样最终编码后的范围是:0xA1A1 - 0xFEFE(共94*94=8836个码位),其中收录了汉字6763个(其中一级汉字3755,二级汉字3008个),覆盖率达到了99.75% 。
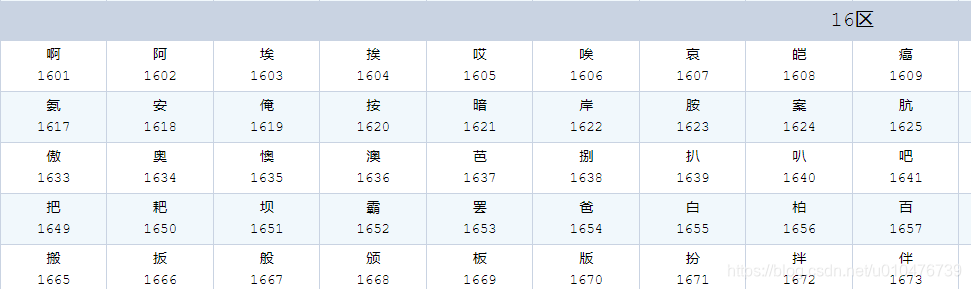
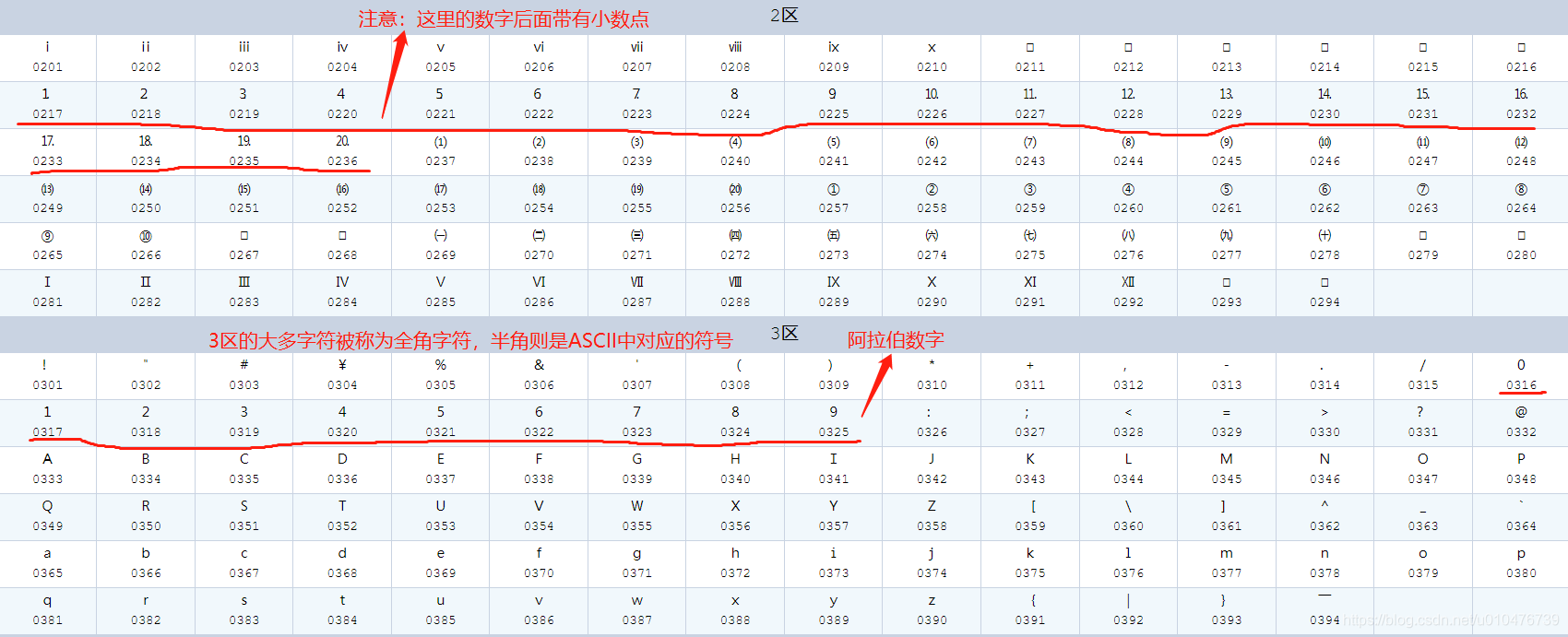
其实,在GB2312中还有区位表的概念:
将所有的字符都分为94区,每区又有94位,
- 01-09 区为特殊符号
- 10-15 区为用户自定义符号区(未编码)
- 16-55 区为一级汉字,按拼音排序
- 56-87 区为二级汉字,按部首/笔画排序
- 88-94 区为用户自定义汉字区(未编码)
.
示例如下:
可以通过这里查看完整的区位码列表:《区位码全表》
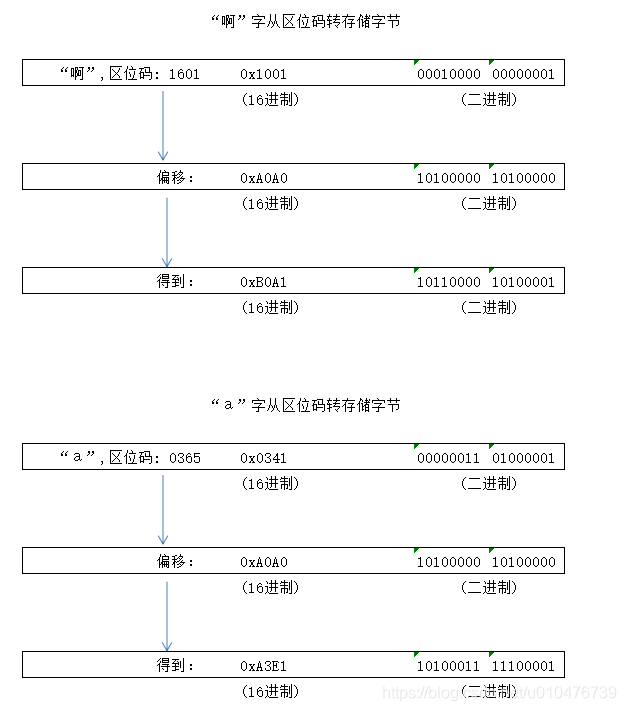
实际计算机存储的时候肯定不是按照区位码存的(还要避开ASCII的字符嘛),所以GB2312的存储规则如下:
注意:上面的“a”不是ASCII中的a,而是GB2312中的“a”。
另外,我们知道ASCII码的"a"其实就是0x61(即:97,01000001)。
基于以上三个字符的分析,我们新建一个文本文件并输入:“aa啊”,并另存为“ANSI”编码(其实就是GBK编码,GBK兼容GB2312,这里就把GBK当做GB2312),如下:
保存后,我们换个软件打开,观察下16进制,这里我使用editplus,如下:
这里实验的结果和我们分析的结果正好一致。
0x61:表示ASCII中的a
0xA3E1:表示GB2312中的a
0xB0A1:表示汉字“a”
.
注意:
现在已经不用区位码表示了,也不用再考虑区位码到二进制存储的转换了。后面的GBK编码就是直接在GB2312的二进制存储上做的扩展。

3. 全角和半角?
对于英文字母和部分标点符号有全角和半角的区别,这是因为这些字母和符号在ASCII中已经定义了一遍,但GB2312中又把这些字母和符号重新定义了一遍(应该是因为中文排版显示不同吧),所以为了区分字母和标点符号究竟是指ASCII中的还是GB2312中的,出现了全角和半角的说法。
- 半角:指ASCII中的字符;
- 全角:指GB2312中的字符;
而对于汉字来说,是没有全角和半角的区别的,因为ASCII中本就没有汉字。
4. GBK编码
GBK全称《汉字内码扩展规范》(GBK即“国标”、“扩展”汉语拼音的第一个字母,英文名称:Chinese Internal Code Specification) ,中华人民共和国全国信息技术标准化技术委员会1995年12月1日制订。
指定它的原因?
虽然GB2312中已覆盖了99.75% 的汉字,但仍然有不少生僻字不在规范里面,作为计算机标准不能漏掉这些。
编码特点:
- GBK编码,是在GB2312-80标准基础上的内码扩展规范,使用了双字节编码方案,其编码范围从8140至FEFE(剔除xx7F),共23940个码位,共收录了21003个汉字,完全兼容GB2312-80标准,支持国际标准ISO/IEC10646-1和国家标准GB13000-1中的全部中日韩(CJK)汉字,并包含了BIG5编码中的所有汉字;
- GBK编码方案于1995年10月制定, 1995年12月正式发布,中文版的WIN95、WIN98、WINDOWS NT以及WINDOWS 2000、WINDOWS XP、WIN 7等都支持GBK编码方案;
GBK对应的区位码?
从上面GBK的描述中,没有发现区位码的信息,没错,GBK是《汉字内码扩展规范》,也就是说GBK不再使用区位码,而是直接对GB2312的转储二进制进行的扩展。
GBK是如何扩展的GB2312,为什么GB2312最多存储8836个码位,而GBK可以存储23940个?
GBK在扩展GB2312的时候,移除了第二个字节首bit位必须为1的限制,且又做了其他扩展,所以GBK的编码范围是:0x8140 - 0xFEFE,最多能表示的码位:
(0xFE-0x81+1)*(0xFE-0x40+1) => 126*191=24066
然后,GBK又规定去除0x xx7F 一条线,所以GBK最终表示126*190=23940个码位,共收入 21886 个汉字和图形符号,其中汉字(包括部首和构件)21003 个,图形符号 883 个。
5. GB18030编码
随着计算机的普及,我国后来又在GBK上扩展字符,这被称为GB18030,如:GB18030-2000(2000年发布),GB18030-2005(2005年发布),同时兼容ASCII、GB2312、GBK、基本兼容Unicode,特点如下:
- 采用变长多字节编码,每个字可以由1个、2个或4个字节组成。;
- 编码空间庞大,最多可定义161万个字符;
- 基本完全支持Unicode,无需动用造字区即可支持中国国内少数民族文字、中日韩和繁体汉字以及emoji等字符;
另外,GB18030在微软视窗系统中的代码页为54936。
6. Big5
已被GBK包含。
Big5,又称为大五码或五大码,是使用繁体中文(正体中文)社区中最常用的电脑汉字字符集标准,共收录13,060个汉字。
7. 大端存储和小端存储
参考:《大小端(数据在内存中的存储)》
如果有一个编码单元需要用大于1个字节表示,那么要说明这个编码单元放在这几个字节内的顺序是怎样的。
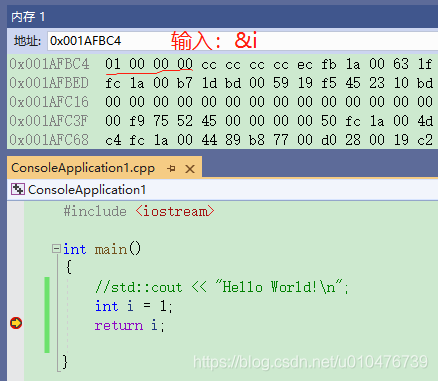
比如说,int类型占用四个字节,那么这四个字节就是一个编码单元,内存中这四个字节排列如下:

小端存储如下(int i=0x00000001; //数字1):

大端存储如下(int i=0x00000001; //数字1):

如果我们在调试中观察内存(使用c++)就能观察到效果了:
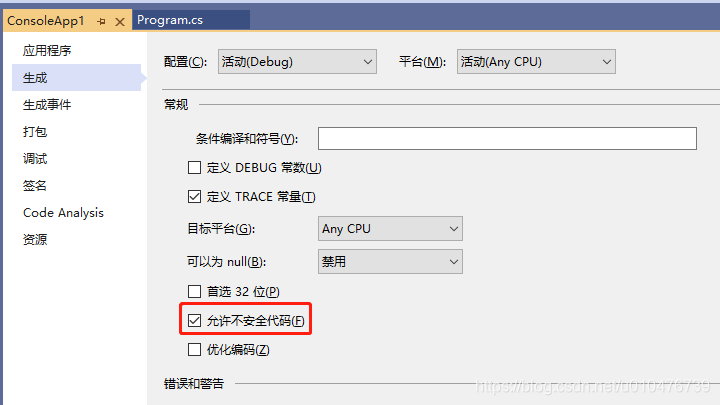
如果想使用c#看,需要使用unsafe模式,先设置工程属性:
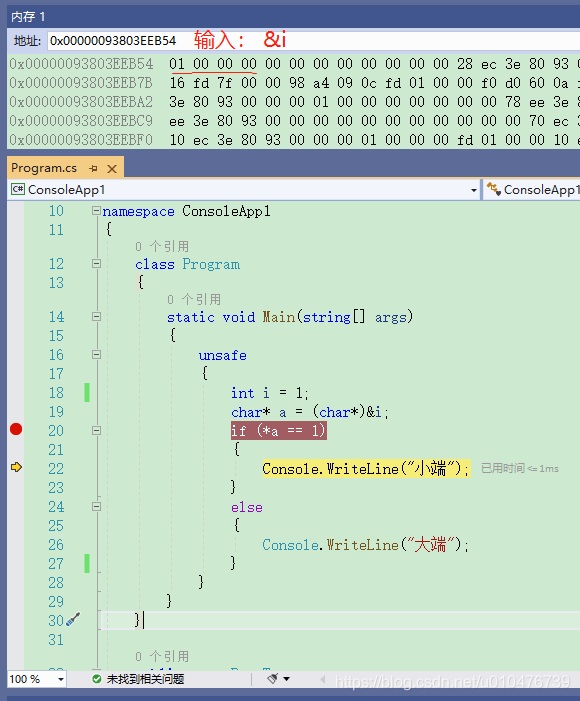
然后代码如下:
8. Unicode
Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。Unicode用数字0-0x10FFFF来映射这些字符,最多可以容纳1114112个字符,或者说有1114112个码位(17*256*256=1114112)。码位就是可以分配给字符的数字。
Unicode的学名是"Universal Multiple-Octet Coded Character Set",简称为UCS。UCS可以看作是"Unicode Character Set"的缩写。
前面提到从ASCII、GB2312、GBK到GB18030的编码方法是向下兼容的。而Unicode只与ASCII兼容,与GB码不兼容。例如“汉”字的Unicode编码是6C49,而GB码是BABA。
Unicode 在1990年开始研发,1994年正式公布。
2005年3月31日推出的Unicode 4.1.0。
2020年3月10日推出的Unicode 13.0.0。
Unicode 13.0.0的官方文档:
https://www.unicode.org/versions/Unicode13.0.0/UnicodeStandard-13.0.pdf
Unicode的编码范围:
完整的范围,请参考:《百度百科:统一码》
0000-007F:C0控制符及基本拉丁文 (C0 Control and Basic Latin):也即ASCII码
0080-00FF:C1控制符及拉丁文补充-1 (C1 Control and Latin 1 Supplement)
0100-017F:拉丁文扩展-A (Latin Extended-A)
0180-024F:拉丁文扩展-B (Latin Extended-B)
0250-02AF:国际音标扩展 (IPA Extensions)
02B0-02FF:空白修饰字母 (Spacing Modifiers)
…此处省略
4E00-9FFF:CJK 统一表意符号 (CJK Unified Ideographs):中文汉字大多在这个区
…此处省略
10000–1FFFF: 第1辅助平面,多文种补充平面(Supplementary Multilingual Plane, SMP) [2]
20000–2FFFF: 第2辅助平面,表意文字补充平面(Supplementary Ideographic Plane, SIP) [2]
30000–3FFFF: 第3辅助平面,表意文字第三平面(Tertiary Ideographic Plane, TIP)
40000–DFFFF:第4-13辅助平面,尚未使用
E0000–EFFFF: 第14辅助平面,特别用途补充平面(Supplementary Special-purpose Plane, SSP)
F0000–FFFFF:第15辅助平面,保留作为私人使用区(Private Use Area, PUA)
100000–10FFFF:第16辅助平面,保留作为私人使用区(Private Use Area, PUA)
9. Unicode中的Emoji表情
由于Emoji符号是互联网文化的产物,所以它在Unicode表的后面部分,以下是部分Emoji表情在Unicode表中的排列:
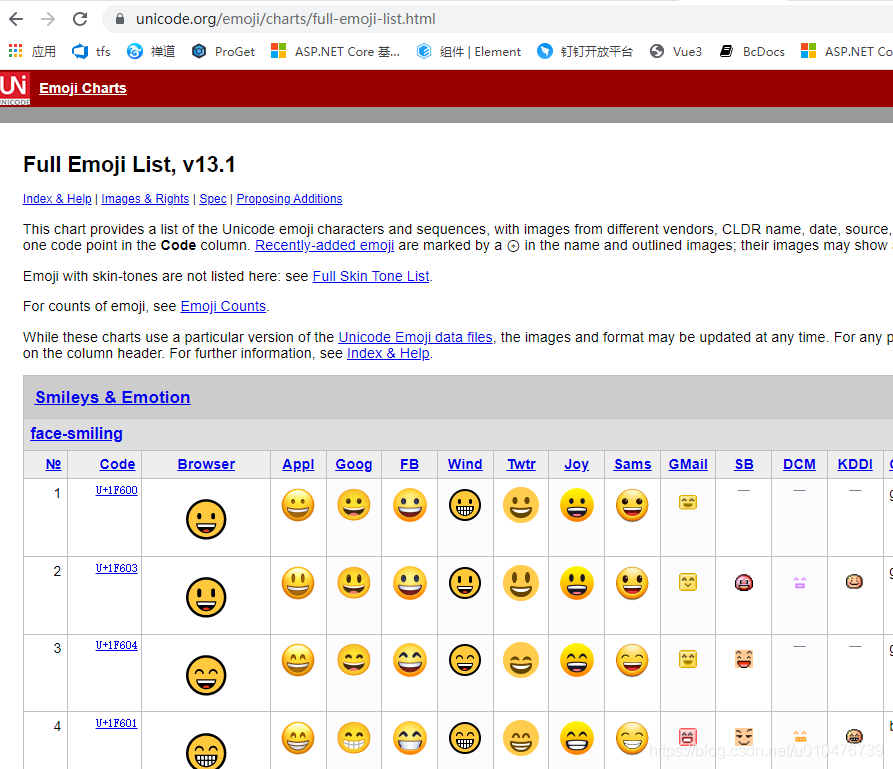
完整的列表,参见Unicode官方文档:《Full Emoji List, v13.1》
10. UCS-2和UTF-16、UCS-4和UTF-32、UTF-8
上节说到Unicode统一了世界字符的编码标准,但是没有提到这些字符应该怎样转储到计算机中。
Unicode中包含1个字节(如:ASCII码)、两个字节(如:中文)和三个字节(如:第一辅助平面)的长度,为了将Unicode存储到计算机中出现了UCS-2、UCS-4、UTF-16、UTF-32、UTF-8几种算法。其中UTF-8已成事实上的流行者。
UCS-2 和 UTF-16编码方式
UCS-2 的编码固定占用2个字节,它包含65536个编码空间。但固定的两个字节不足以覆盖所有的Unicode字符,于是UTF-16诞生了,与UCS-2一样,它使用两个字节为全世界最常用的63K字符编码,不同的是,它使用4个字节对不常用的字符进行编码。UTF-16属于变长编码。
UCS-4 和 UTF-32编码方式
UCS-4的编码固定占用4个字节,编码空间为0x00000000 - 0x7FFFFFFF(可以编码20多亿个字符)。但实际使用范围并不超过0x10FFFF,并且为了兼容Unicode标准,ISO也承诺将不会为超出0x10FFFF的UCS-4编码赋值。由此UTF-32编码被提出来了,它的编码值与UCS-4相同,只不过其编码空间被限定在了0~0x10FFFF之间。因此也可以说:UTF-32是UCS-4的一个子集。
UTF-8
也是使用变长字节表示(1-4个字节表示)。
根据 Unicode 编号的大小,编号小的使用的字节就少,编号大的使用的字节就多。使用的字节个数从 1 到 4 个不等。
UTF-8 的编码规则是:- ① 对于单字节的符号,字节的第一位设为 0,后面的7位为这个符号的 Unicode 码,。
- ② 对于n字节的符号 (n>1),第一个字节的前 n 位都设为 1,第 n+1 位设为 0,后面字节的前两位一律设为 10,剩下的没有提及的二进制位,全部为这个符号的 Unicode 码 。

UTF-8编码实例:
严的 Unicode 是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800 - 0000 FFFF),因此严的 UTF-8 编码需要三个字节,即格式是1110xxxx 10xxxxxx 10xxxxxx。然后,从严的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,严的 UTF-8 编码是11100100 10111000 10100101,转换成十六进制就是E4B8A5。
11. UTF-16 LE、UTF-16 BE、UTF-32 LE和UTF-32 BE
我们在记事本另存为的时候还能看到UTF-16 LE 和 UTF-16 BE的选项,这是因为在制定UTF-16编码的时候允许自己指定字节的存放顺序,这和上面说的大小端存储是一个意思。
UTF-32的和UTF-16一样也有这个特点。
而GBK和UTF-8均没有大小端存储的区别,因为它们都是按照字节的顺序从低位开始排列的。
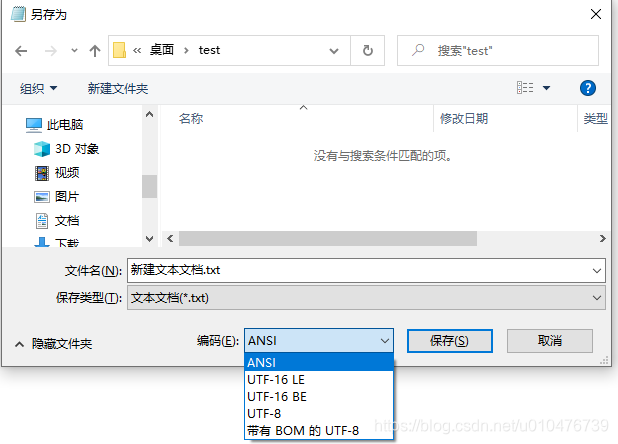
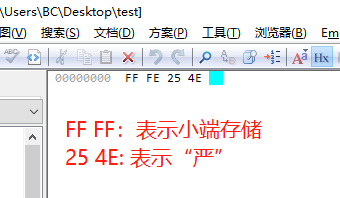
以汉字 “严” 为例,它的Unicode编码为4E25,我们打开记事本,写入汉字 “严” ,并另存为 UTF-16 LE:

然后,我们使用editplus打开,观察它的16进制如下:
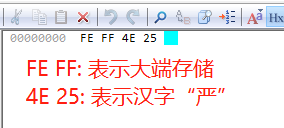
如果,我们另存为UTF-16 BE,那么16进制显示如下:
12. UTF-8和UTF-8-BOM
虽然UTF-8没有大小端存储的区别,但是我们会看到UTF-8-BOM类型的编码,那么有BOM和无BOM的啥区别呢?
带BOM的会在文本的前面添加EF BB BF 三个字节以表示这是UTF-8编码。
还是以汉字“严”为例,我们知道“严”的UTF-8编码为:0xE4B8A5,下面我们打开记事本,输入汉字“严”,将它保存为UTF-8编码:
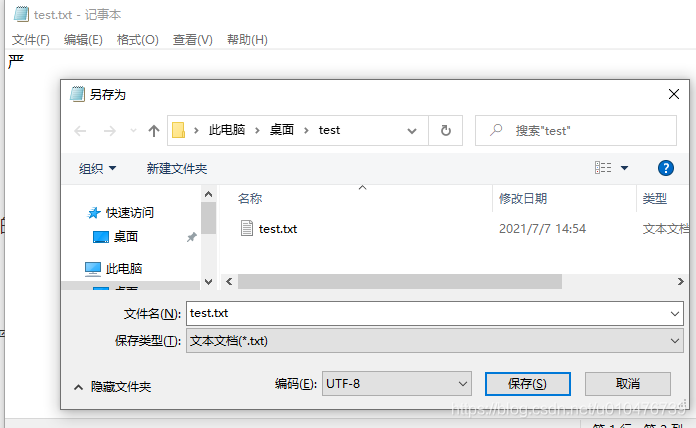
然后,用editplus打开观察16进制,如下:
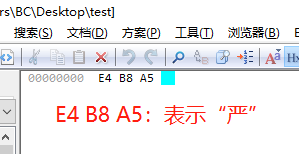
如果,我们将它保存为带BOM的UTF-8,然后观察16进制,会发现在首部多了3个字节,如下:
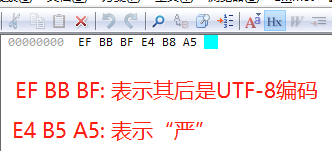
虽然,带BOM的UTF-8编码能更好的表示文本文件,但带bom的shell脚本在linux执行的时候却会报错,所以除非必须,不要使用带BOM的UTF-8编码。
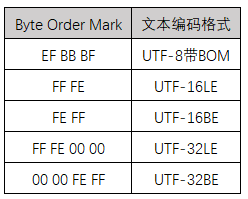
13. 如何根据文本首字节确定其编码方式
首先,由于GBK不存在字节序,文本前端不需要加字节说明,不带BOM的UTF-8编码文本也不需要加字节说明,所以下面的判断只能是识别已经指明编码格式的文本。
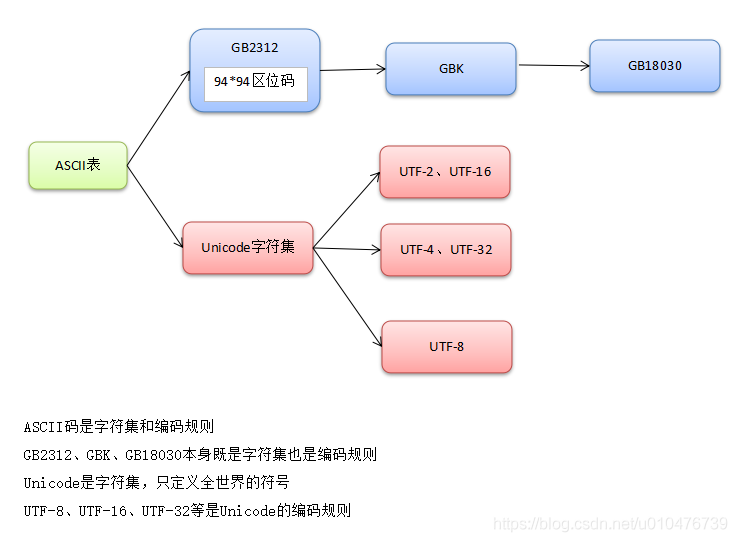
14. 编码总结(字符集和字符编码)
区分字符集和字符编码的概念:
- 字符集:定义了一套字符,比如:GB2312、GBK等定义了一整套的中文符号,Unicode定义了全世界的符号;
- 字符编码:将一个字符集转储成二进制的规则,比如:GB2312、GBK自带编码规则,可以将字符转储成二进制,而UTF-8、UTF-16则是Unicode的编码规则,负责将Unicode中的字符转储成二进制。
如下图所示:
15. 如何查看字符对应的各种类型编码?
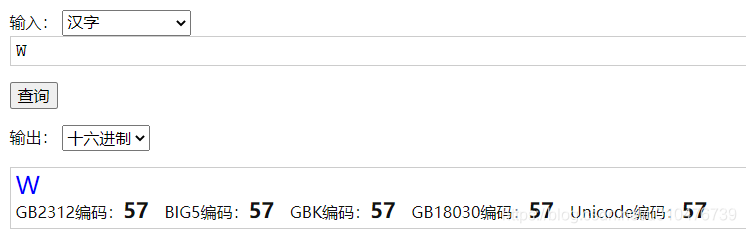
方法一: 直接在网站:https://www.qqxiuzi.cn/bianma/zifuji.php 上搜索即可得某个字符的 ASCII、GB2312、BIG-5、GBK、GB18030、Unicode编码;
比如,大写英文字母“W”:
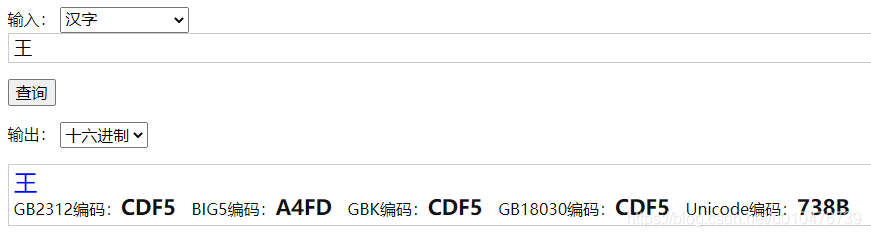
又比如汉字“王”:
还有emoji表情:

方法二:上面虽然有常规的编码转换,但是没有关于UTF-16、UTF-8的转换,下面借助c#程序得到字符的UTF-16和UTF-8编码:
class Program
{
static void Main(string[] args)
{
Console.WriteLine($"W Unicode =>{ConvertToHex("W", "Unicode")}");
Console.WriteLine($"W UTF-16 =>{ConvertToHex("W", "UTF-16")}");
Console.WriteLine($"W UTF-32 =>{ConvertToHex("W", "UTF-32")}");
Console.WriteLine($"W UTF-8 =>{ConvertToHex("W", "UTF-8")}");Console<span class="token punctuation">.</span><span class="token function">WriteLine</span><span class="token punctuation">(</span><span class="token interpolation-string"><span class="token string">$"王 Unicode =></span><span class="token interpolation"><span class="token punctuation">{<!-- --></span><span class="token expression language-csharp"><span class="token function">ConvertToHex</span><span class="token punctuation">(</span><span class="token string">"王"</span><span class="token punctuation">,</span> <span class="token string">"Unicode"</span><span class="token punctuation">)</span></span><span class="token punctuation">}</span></span><span class="token string">"</span></span><span class="token punctuation">)</span><span class="token punctuation">;</span>
Console<span class="token punctuation">.</span><span class="token function">WriteLine</span><span class="token punctuation">(</span><span class="token interpolation-string"><span class="token string">$"王 UTF-16 =></span><span class="token interpolation"><span class="token punctuation">{<!-- --></span><span class="token expression language-csharp"><span class="token function">ConvertToHex</span><span class="token punctuation">(</span><span class="token string">"王"</span><span class="token punctuation">,</span> <span class="token string">"UTF-16"</span><span class="token punctuation">)</span></span><span class="token punctuation">}</span></span><span class="token string">"</span></span><span class="token punctuation">)</span><span class="token punctuation">;</span>
Console<span class="token punctuation">.</span><span class="token function">WriteLine</span><span class="token punctuation">(</span><span class="token interpolation-string"><span class="token string">$"王 UTF-32 =></span><span class="token interpolation"><span class="token punctuation">{<!-- --></span><span class="token expression language-csharp"><span class="token function">ConvertToHex</span><span class="token punctuation">(</span><span class="token string">"王"</span><span class="token punctuation">,</span> <span class="token string">"UTF-32"</span><span class="token punctuation">)</span></span><span class="token punctuation">}</span></span><span class="token string">"</span></span><span class="token punctuation">)</span><span class="token punctuation">;</span>
Console<span class="token punctuation">.</span><span class="token function">WriteLine</span><span class="token punctuation">(</span><span class="token interpolation-string"><span class="token string">$"王 UTF-8 =></span><span class="token interpolation"><span class="token punctuation">{<!-- --></span><span class="token expression language-csharp"><span class="token function">ConvertToHex</span><span class="token punctuation">(</span><span class="token string">"王"</span><span class="token punctuation">,</span> <span class="token string">"UTF-8"</span><span class="token punctuation">)</span></span><span class="token punctuation">}</span></span><span class="token string">"</span></span><span class="token punctuation">)</span><span class="token punctuation">;</span> Console<span class="token punctuation">.</span><span class="token function">WriteLine</span><span class="token punctuation">(</span><span class="token interpolation-string"><span class="token string">$" Unicode =></span><span class="token interpolation"><span class="token punctuation">{<!-- --></span><span class="token expression language-csharp"><span class="token function">ConvertToHex</span><span class="token punctuation">(</span><span class="token string">""</span><span class="token punctuation">,</span> <span class="token string">"Unicode"</span><span class="token punctuation">)</span></span><span class="token punctuation">}</span></span><span class="token string">"</span></span><span class="token punctuation">)</span><span class="token punctuation">;</span>
Console<span class="token punctuation">.</span><span class="token function">WriteLine</span><span class="token punctuation">(</span><span class="token interpolation-string"><span class="token string">$" UTF-16 =></span><span class="token interpolation"><span class="token punctuation">{<!-- --></span><span class="token expression language-csharp"><span class="token function">ConvertToHex</span><span class="token punctuation">(</span><span class="token string">""</span><span class="token punctuation">,</span> <span class="token string">"UTF-16"</span><span class="token punctuation">)</span></span><span class="token punctuation">}</span></span><span class="token string">"</span></span><span class="token punctuation">)</span><span class="token punctuation">;</span>
Console<span class="token punctuation">.</span><span class="token function">WriteLine</span><span class="token punctuation">(</span><span class="token interpolation-string"><span class="token string">$" UTF-32 =></span><span class="token interpolation"><span class="token punctuation">{<!-- --></span><span class="token expression language-csharp"><span class="token function">ConvertToHex</span><span class="token punctuation">(</span><span class="token string">""</span><span class="token punctuation">,</span> <span class="token string">"UTF-32"</span><span class="token punctuation">)</span></span><span class="token punctuation">}</span></span><span class="token string">"</span></span><span class="token punctuation">)</span><span class="token punctuation">;</span>
Console<span class="token punctuation">.</span><span class="token function">WriteLine</span><span class="token punctuation">(</span><span class="token interpolation-string"><span class="token string">$" UTF-8 =></span><span class="token interpolation"><span class="token punctuation">{<!-- --></span><span class="token expression language-csharp"><span class="token function">ConvertToHex</span><span class="token punctuation">(</span><span class="token string">""</span><span class="token punctuation">,</span> <span class="token string">"UTF-8"</span><span class="token punctuation">)</span></span><span class="token punctuation">}</span></span><span class="token string">"</span></span><span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token keyword">private</span> <span class="token keyword">static</span> <span class="token return-type class-name"><span class="token keyword">string</span></span> <span class="token function">ConvertToHex</span><span class="token punctuation">(</span><span class="token class-name"><span class="token keyword">string</span></span> str<span class="token punctuation">,</span> <span class="token class-name"><span class="token keyword">string</span></span> encodingStr<span class="token punctuation">)</span>
<span class="token punctuation">{<!-- --></span>
<span class="token class-name"><span class="token keyword">var</span></span> encoding <span class="token operator">=</span> System<span class="token punctuation">.</span>Text<span class="token punctuation">.</span>Encoding<span class="token punctuation">.</span><span class="token function">GetEncoding</span><span class="token punctuation">(</span>encodingStr<span class="token punctuation">)</span><span class="token punctuation">;</span>
<span class="token keyword">return</span> <span class="token function">ConvertToHex</span><span class="token punctuation">(</span>str<span class="token punctuation">,</span> encoding<span class="token punctuation">)</span><span class="token punctuation">;</span>
<span class="token punctuation">}</span> <span class="token keyword">private</span> <span class="token keyword">static</span> <span class="token return-type class-name"><span class="token keyword">string</span></span> <span class="token function">ConvertToHex</span><span class="token punctuation">(</span><span class="token class-name"><span class="token keyword">string</span></span> str<span class="token punctuation">,</span> <span class="token class-name">Encoding</span> encoding<span class="token punctuation">)</span>
<span class="token punctuation">{<!-- --></span>
<span class="token class-name"><span class="token keyword">var</span></span> bs <span class="token operator">=</span> encoding<span class="token punctuation">.</span><span class="token function">GetBytes</span><span class="token punctuation">(</span>str<span class="token punctuation">)</span><span class="token punctuation">;</span>
<span class="token keyword">return</span> <span class="token string">"0x"</span> <span class="token operator">+</span> <span class="token keyword">string</span><span class="token punctuation">.</span><span class="token function">Join</span><span class="token punctuation">(</span><span class="token string">""</span><span class="token punctuation">,</span> bs<span class="token punctuation">.</span><span class="token function">ToList</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">.</span><span class="token function">Select</span><span class="token punctuation">(</span>i <span class="token operator">=></span> i<span class="token punctuation">.</span><span class="token function">ToString</span><span class="token punctuation">(</span><span class="token string">"X2"</span><span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">;</span>
<span class="token punctuation">}</span>
}

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
打印的结果:
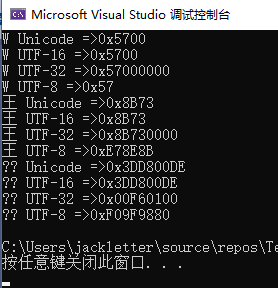
这里有乱码,是因为控制台使用的ANSI编码,即:GBK编码,GBK中没有emoji的字符,所有显示乱码。
方法三:我们也可以借助notepad++的16进制插件或editplus等编辑器查看,参照:《新版Notepad++加十六进制查看的插件HexEditor》
最终,我们总结得出英文大写字母“M”、汉字“王”、emoji表情“”的各个编码如下:
| 字符 | ASCII | GB2312 | Big5 | GBK | GB18030 | Unicode | UTF-16 | UTF-8 |
|---|---|---|---|---|---|---|---|---|
| W | 0x57 | 0x57 | 0x57 | 0x57 | 0x57 | 0x57 | 0x57 | 0x57 |
| 王 | 无 | 0xCDF5 | 0xA4FD | 0xCDF5 | 0xCDF5 | 0x738B | 0x8B73 | 0xE78E8B |
| 无 | 无 | 无 | 无 | 0x9439FC36 | 0x1F6001 | 0x3DD800DE | 0xF09F9880 |
16. ANSI编码、代码页为何物?
先说下代码页:
可以把代码页当做字符集编码的别名,比如:
- 936:代表中文简体;
- 437:代表ASCII;
- 65001:代表UTF-8;
完整的代码页列表,参考微软网站:《代码页标识符》
再来看ANSI:
参考:《ANSI是什么编码?》
在window环境下经常见到 “ANSI”标志,如:
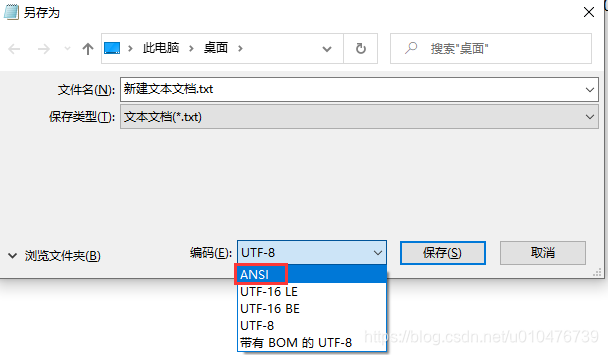
乍一看,ANSI和ASCII好像,但它们不是同一个意思。
ANSI编码解释:
ANSI并不是某一种特定的字符编码,它表示的是你的系统中设置的国家区域对应的字符编码。比如你的美国同事Bob的系统中ANSI编码其实是ASCII编码(ASCII编码不能表示汉字,所以汉字为乱码),而你的系统中(“汉字”正常显示)ANSI编码其实是GBK编码,而韩文系统中(“한국어”正常显示)ANSI编码其实是EUC-KR编码。
我们打开cmd窗口,查看cmd用的什么字符集编码:
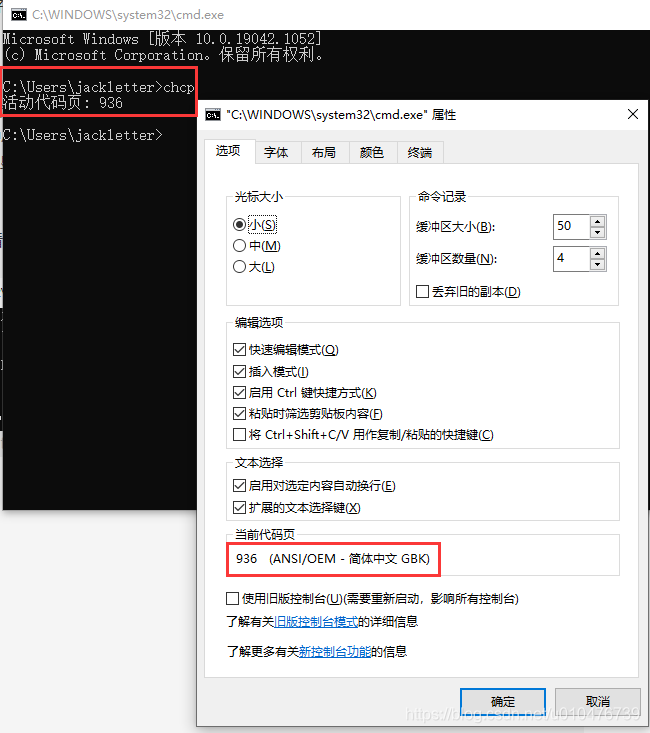
如何修改window操作系统的区域?
看下图:
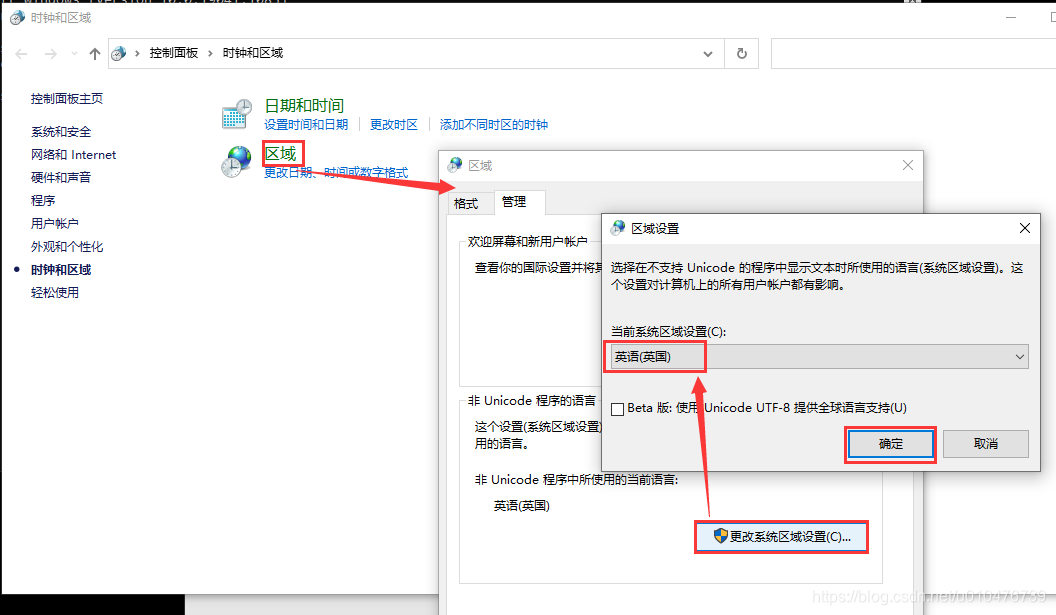
当我们把区域改成英语(美国)后,重启电脑,再次打开命令行,如下:
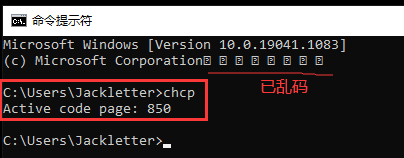
然后,打开window记事本,输入汉字“什么”,然后保存,再次打开,发现正常显示中文,但这里能正常显示却是因为保存的格式是UTF-8,如下:
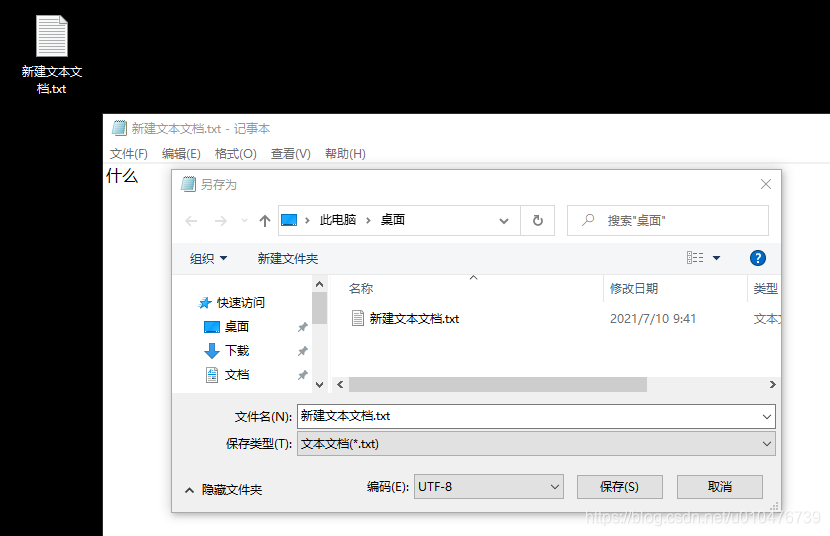
当我们把它保存成ANSI时:
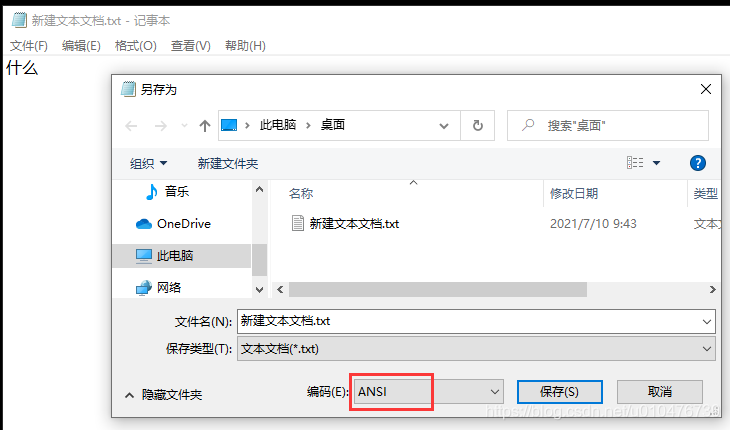
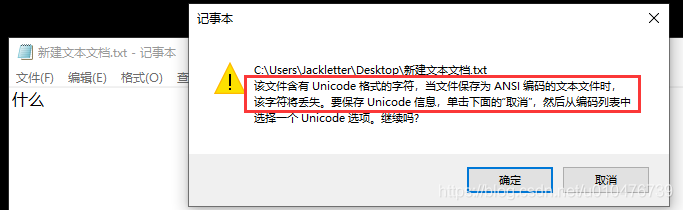
这里提示我们,因为里面有Unicode格式的字符(Unicode中有中文字符),而此时的ANSI表示的是ASCII码(已设置区域为英语美国),所以会提示我们会有字符丢失的风险,点击确定继续:

</article>
[转帖]细说ASCII、GB2312/GBK/GB18030、Unicode、UTF-8/UTF-16/UTF-32编码的更多相关文章
- 字符编码-ASCII,GB2312,GBK,GB18030
ASCII ASCII,GB2312,GBK,GB18030依次增加,向下兼容. 手机只需要支持GB2312 电脑中文windows只支持GBK 发展历程 如果你使用编译器是python2.0版本,默 ...
- 字符集、字符编码、国际化、本地化简要总结(UNICODE/UTF/ASCII/GB2312/GBK/GB18030)
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 环境说明 普通的linux 和 普通的windows. ...
- Ansi、GB2312、GBK、Unicode(utf8、16、32)
关于ansi,一般默认为本地编码方式,中文应该是gb编码 他们之间的关系在这边文章里描写的很清楚:http://blog.csdn.net/ldanduo/article/details/820353 ...
- 汉字编码:GB2312, GBK, GB18030, Big5
前一篇博文:ANSI是什么编码?中有这样一段小故事: 话说计算机是由美国佬搞出来的嘛,他们觉得一个字节(可以表示256个编码)表示英语世界里所有的字母.数字和常用特殊符号已经绰绰有余了(其实ASCII ...
- GB2312,GBK,GB18030,UTF8四种汉字编码标准有什么差别和联系
从GB2312.GBK 到 GB18030,这些编码方法是向下兼容的,即同一个字符在这些方案中总是有同样的编码,后面的标准支持很多其它的字符.在这些编码中,英文和中文能够统一地处理. 区分中文编 ...
- ASCII,unicode, utf8 ,big5 ,gb2312,gbk,gb18030等几种常用编码区别(转载)
原文出处:http://www.blogjava.net/xcp/archive/2009/10/29/coding2.html 最近老为编码问题而烦燥,下定决心一定要将其弄明白!本文主要总结网上一些 ...
- ASCII,GB2312,GBK,Unicode,Utf-8
1.ASCII:American Stardand Code for Information Interchange,是当时美国制定出来的一套编码系统,使用7位或8位二进制来表示西文字符,0-31以及 ...
- 汉字编码 (GB2312 GBK GB18030)
GB2312 收录简化汉字及符号.字母.日文假名等共7445个图形字符,其中汉字占6763个 每个符号都用两个字节表示,每个字节均采用七位编码表示,习惯上 第一个字节是高字节,第二个字节是低字节 GB ...
- 编码方式ASCII、GBK、Unicode、UTF-8比较
文章内容深度较浅,详细了解可到下链接:https://blog.csdn.net/QuinnNorris/article/details/78705723; 总结了以下几种编码方式: ASCII.GB ...
- [编码]ASCII、GBK、Unicode(万国码) 和 UTF-8
American ASCII编码 (American Standard Code for Information Interchange,美国信息互换标准代码) China gbk编码 ...
随机推荐
- 新报: 根据IP获取物理地址不需要调用接口啦
一. 复制data文件夹到自己的项目当中 可以进行加载到这个文件即可 博主放入在项目的根目录当中 请移步Gitee pull 该文件 https://gitee.com/yangbuyi/ip_fil ...
- 你真的会用 npx 吗❓❓❓
Hello,大家好! 日常开发中大家应该经常使用 npm install xxx 来安装包依赖,那是否注意到npm升级到 npm@5.2.0 之后,在 npm 二进制命令旁边安装了一个 npx 二进制 ...
- 27、flutter Dialog 弹窗
AlertDialog //放在State<>之下 void _alertDialog() async { var result = await showDialog( barrierDi ...
- antd5中文设定
antd5中文设定 import zhCN from "antd/lib/locale/zh_CN" <ConfigProvider locale={zhCN} theme= ...
- 为什么MySQL单表不能超过2000万行?
摘要:MySQL一张表最多能存多少数据? 本文分享自华为云社区<为什么MySQL单表不能超过2000万行?>,作者: GaussDB 数据库 . 最近看到一篇<我说MySQL每张表最 ...
- 云小课|MRS基础原理之CarbonData入门
阅识风云是华为云信息大咖,擅长将复杂信息多元化呈现,其出品的一张图(云图说).深入浅出的博文(云小课)或短视频(云视厅)总有一款能让您快速上手华为云.更多精彩内容请单击此处. 摘要:CarbonDat ...
- CISO 需考虑的五项 Kubernetes 安全措施
随着企业对软件开发的安全意识提高,开发和运维环节中各个团队也开始将安全嵌入他们正在使用或处理的平台或应用程序架构中.不同于各团队把对安全的关注放在自己所处理的环节,首席信息安全官(CISO)需要把握和 ...
- 火山引擎ByteHouse助力中国地震台网中心,快速构建一站式实时数仓
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 近日,中国地震台网中心与火山引擎达成合作,双方将围绕 ByteHouse 实时数仓展开合作. 中国地震台网中心为中国地震局 ...
- 2021 年如何学习 Android,一位 5 年中大厂老哥跟你聊聊
本文首发我的微信公众号:程序员徐公 大家好,我是程序员徐公,加上实习,有五年中大厂经验.今天,我们一起来聊一聊如何自学 Android. 光阴似箭,日月如梭,时间真的过得飞快. 加上实习,从事 And ...
- HDU - 1711:Number Sequence (KMP模板)
原题链接 KMP模板:AC,858ms,13112KB内存 消耗太大了 #include<bits/stdc++.h> using namespace std; using namespa ...