【奶奶看了都会】Meta开源大模型LLama2部署使用教程,附模型对话效果
1.写在前面
就在7月19日,MetaAI开源了LLama2大模型,Meta 首席科学家、图灵奖获得者 Yann LeCun在推特上表示Meta 此举可能将改变大模型行业的竞争格局。一夜之间,大模型格局再次发生巨变。

推文上列了Llama2的网站和论文,小卷给大家贴一下,感兴趣的友友可以自己看看
论文:https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
Github页:https://github.com/facebookresearch/llama
2.LLama2是什么
Llama官网的说明是Llama2下一代开源大语言模型,可免费用于学术研究或商业用途。
目前模型有7B、13B、70B三种规格,预训练阶段使用了2万亿Token,SFT阶段使用了超过10w数据,人类偏好数据超过100w。

另外大家最关心的Llama2和ChatGPT模型的效果对比,在论文里也有提到,
对比GPT-4,Llama2评估结果更优,绿色部分表示Llama2优于GPT4的比例

虽然中文的占比只有0.13%,但后续会有一大推中文扩充词表预训练&领域数据微调的模型被国人放出。这不才开源几天而已,GIthub上就已经有基于Llama2的中文大模型了。。。
3.部署使用
关于LLama2的技术细节就不再多说了,大家可以自行查阅。接下来就教大家怎么自己玩一玩LLama2对话大模型。
大部分人都是没有本地GPU算力的,我们选择在云服务器上部署使用。我这里用的是揽睿星舟平台的GPU服务器(便宜好用,3090只要1.9/小时,且已在平台上预设了模型文件,无需再次下载)
新用户注册还送2小时的3090算力,记得邀请码写4104
3.1新建空间
登录:https://www.lanrui-ai.com/console/workspace
创建一个工作空间,运行环境镜像挂载公有镜像:pytorch: official-torch2.0-cu1117。选择预训练模型:llama-2-7b 和 llama-2-7b-chat。然后创建实例

3.2下载代码
实例创建完成后,以jupyterLab方式登录服务器,新建一个Terminal,然后进入到data目录下
cd data
下载代码
执行下面的命令从GIthub上拉取llama的代码
sudo git clone https://github.com/facebookresearch/llama.git
下载完成后,会多一个llama目录
3.3运行脚本
进入llama目录
cd llama
安装依赖
sudo pip install -e .
测试llama-2-7b模型的文本补全能力
命令行执行:
torchrun --nproc_per_node 1 example_text_completion.py \
--ckpt_dir ../../imported_models/llama-2-7b/Llama-2-7b \
--tokenizer_path ../../imported_models/llama-2-7b/Llama-2-7b/tokenizer.model \
--max_seq_len 128 --max_batch_size 4
文本补齐效果示例:
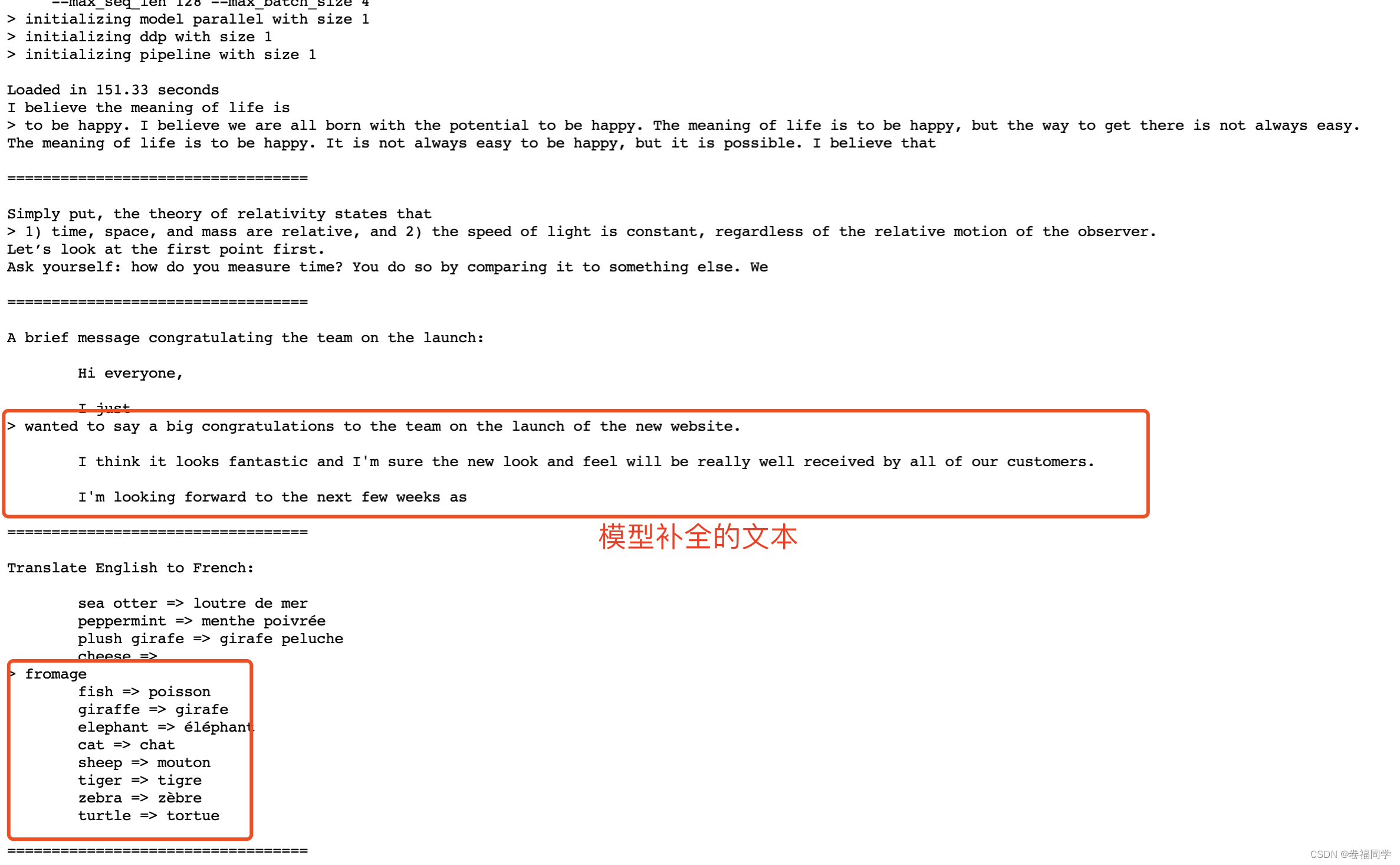
上面的例子是在python脚本里写了一段话,让模型补全后面的内容。
测试llama-2-7b模型的对话能力
修改llama目录权限为777,再修改example_chat_completion.py文件中的ckpt_dir和tokenizer_path路径为你的llama-2-7b-chat模型的绝对路径
// 1.修改目录权限为可写入
chmod 777 llama
//2.修改example_chat_completion.py文件里的参数
ckpt_dir: str = "/home/user/imported_models/llama-2-7b-chat/Llama-2-7b-chat/",
tokenizer_path: str = "/home/user/imported_models/llama-2-7b-chat/Llama-2-7b-chat/tokenizer.model"
//3.运行对话脚本
torchrun --nproc_per_node 1 example_chat_completion.py

这里我修改提示语让它用中文回答,执行对话脚本后,对话效果如下:
torchrun --nproc_per_node 1 example_chat_completion.py

说明:目前官方还没有提供UI界面或是API脚本代码给咱使用,还没法进行对话交互,如果有懂python的友友,可以自行加个UI界面,欢迎大家留言讨论。
4.下载更多模型
llama代码里有download.sh脚本可以下载其他模型,但是下载需要的URL需要自行获取。下载步骤如下:
1.Meta AI网站获取下载URL
MetaAI下载模型页地址:https://ai.meta.com/llama/#download-the-model

点击Download后,要求填入一些信息和邮箱,提交后会给你的邮箱发一个下载URL,注意这个是你自己的下载链接哦~
下图是小卷邮箱里收到的模型下载链接

2.下载模型
服务器上命令行执行
sudo bash download.sh
接着按照提示粘贴下载URL和选择要下载的模型

总结
对于国内大模型使用来说,随着开源可商用的模型越来越多,国内大模型肯定会再次迎来发展机遇。
文章原创不易,欢迎多多转发,点赞,关注
也欢迎关注我的公众号卷福同学,技术问题都可在公众号内交流
【奶奶看了都会】Meta开源大模型LLama2部署使用教程,附模型对话效果的更多相关文章
- [奶奶看了都会]ChatGPT保姆级注册教程
大家好,我是小卷 最近几天OpenAI发布的ChatGPT聊天机器人火出天际了,连着上了各个平台的热搜榜.这个聊天机器人最大的特点是模仿人类说话风格同时回答大量问题. 有人说ChatGPT是真正的人工 ...
- [Hadoop大数据]——Hive部署入门教程
Hive是为了解决hadoop中mapreduce编写困难,提供给熟悉sql的人使用的.只要你对SQL有一定的了解,就能通过Hive写出mapreduce的程序,而不需要去学习hadoop中的api. ...
- 三分钟快速上手TensorFlow 2.0 (下)——模型的部署 、大规模训练、加速
前文:三分钟快速上手TensorFlow 2.0 (中)——常用模块和模型的部署 TensorFlow 模型导出 使用 SavedModel 完整导出模型 不仅包含参数的权值,还包含计算的流程(即计算 ...
- TensorFlow Serving实现多模型部署以及不同版本模型的调用
前提:要实现多模型部署,首先要了解并且熟练实现单模型部署,可以借助官网文档,使用Docker实现部署. 1. 首先准备两个你需要部署的模型,统一的放在multiModel/文件夹下(文件夹名字可以任意 ...
- 【转】使用Apache Kylin搭建企业级开源大数据分析平台
http://www.thebigdata.cn/JieJueFangAn/30143.html 本篇文章整理自史少锋4月23日在『1024大数据技术峰会』上的分享实录:使用Apache Kylin搭 ...
- [转载] 一共81个,开源大数据处理工具汇总(下),包括日志收集系统/集群管理/RPC等
原文: http://www.36dsj.com/archives/25042 接上一部分:一共81个,开源大数据处理工具汇总(上),第二部分主要收集整理的内容主要有日志收集系统.消息系统.分布式服务 ...
- Impala:新一代开源大数据分析引擎
Impala架构分析 Impala是Cloudera公司主导开发的新型查询系统,它提供SQL语义,能查询存储在Hadoop的HDFS和HBase中的PB级大数据.已有的Hive系统虽然也提供了SQL语 ...
- 一共81个,开源大数据处理工具汇总(下),包括日志收集系统/集群管理/RPC等
作者:大数据女神-诺蓝(微信公号:dashujunvshen).本文是36大数据专稿,转载必须标明来源36大数据. 接上一部分:一共81个,开源大数据处理工具汇总(上),第二部分主要收集整理的内容主要 ...
- 使用Apache Kylin搭建企业级开源大数据分析平台
转:http://www.thebigdata.cn/JieJueFangAn/30143.html 我先做一个简单介绍我叫史少锋,我曾经在IBM.eBay做过大数据.云架构的开发,现在是Kylige ...
- 模型的元数据Meta -- Django从入门到精通系列教程
该系列教程系个人原创,并完整发布在个人官网刘江的博客和教程 所有转载本文者,需在顶部显著位置注明原作者及www.liujiangblog.com官网地址. Python及Django学习QQ群:453 ...
随机推荐
- Oracle实例的启动和关闭
启动模式 1.NoMount 模式(启动实例不加载数据库) 命令:startup nomount 讲解:这种启动模式只会创建实例,并不加载数据库,Oracle仅为实例创建各种内存结构和服务进程,不会打 ...
- Laravel - 控制器的session ( 转载 )
设置路由 //使用session,需要开启session,//session的开始类在/app/Kernel下//protected $middlewareGroups = [// 'web' =&g ...
- [转帖]CPU写入512bit要多久:从AVX到NEON
https://zhuanlan.zhihu.com/p/677124882 写这篇文章的原因是有个项目需要降低延迟,希望能更快地把512bit的数据从内存搬进PCIe设备.原先的做法是软件写寄存器通 ...
- SQLServer数据库优化学习-总结
SQLServer数据库优化学习-总结 背景 各种能力都需要提升. 最近总是遇到SQLServer的问题 趁着周末进行一下学习与提高. 安装与优化 1. 数据库必须安装 64位, 不要安装成32位的版 ...
- [转帖]prometheus和node_exporter中的磁盘监控
https://www.ipcpu.com/2021/04/prometheus-node_exporter/ prometheus和node_exporter中的磁盘监控.md 对于磁盘问题,我们主 ...
- [转帖]crontab 定时任务,免交互式编写任务文件
https://www.jianshu.com/p/8eab68bcfc8e 正常添加定时任务是在命令行使用命令 crontab -ecrontab -e编写完的文件怎么找到?文件默认保存在/var/ ...
- [转帖]jmeter线程组与循环次数的区别
在压测的时候,有些接口需要携带登录信息,但是我们只想登录一次,然后其他接口进行多用户压测,此时你会怎么办?用仅一次控制器实现吗?下面我们来看看用仅一次控制器能不能实现 压测时jmeter中的线程数是模 ...
- [转帖]Jmeter之界面语言设置
https://developer.aliyun.com/article/1173114#:~:text=%E6%B0%B8%E4%B9%85%E6%80%A7%E8%AE%BE%E7%BD%AE%E ...
- 人大金仓学习之一_kwr的简单学习
人大金仓学习之一_kwr的简单学习 摘要 周末在家想着学习一下数据库相关的内容. 网上找了不少资料, 想着直接在本地机器上面进行一下安装与验证 理论上linux上面应该更加简单. windows 上面 ...
- [转帖]认识目标文件的格式——a.out COFF PE ELF
https://cloud.tencent.com/developer/article/1446849 1.目标文件的常用格式 目标文件是源代码编译后未进行链接的中间文件(Windows的.obj ...