JuiceFS 在大搜车数据平台的实践
大搜车已经搭建起比较完整的汽车产业互联网协同生态。在这一生态中,不仅涵盖了大搜车已经数字化的全国 90% 中大型二手车商、9000+ 家 4S 店和 70000+ 家新车二网,还包括大搜车旗下车易拍、车行168、运车管家、布雷克索等具备较强产业链服务能力的公司, 与大搜车在新零售解决方案上达成深度战略合作的长城汽车、长安汽车、英菲尼迪等主机厂商,以及与中石油昆仑好客等产业链上下游的合作伙伴。基于这样的生态布局,大搜车数字化了汽车流通链条上的每个环节,进而为整个行业赋能。
说到大数据,对于每个公司都不陌生。存储组件 HDFS,计算资源管理 YARN,离线计算 Hive、Spark、Spark SQL,列存储数据库 HBase,实时计算Spark Streaming、Flink等。这些组件在集群稳定情况下维护还算比较轻松,但是在公司快速发展过程中,集群容量的高速增长是不可避免的,作为大数据的设计者不得不从集群的成本和效益上思考两者的权衡。
大数据集群现状
大搜车目前大数据集群分为离线计算集群和实时计算集群,离线计算基于 Hive 和 Spark,实时计算基于 Flink,这两类集群分别基于 HDP 和 CDH 两套管理方式。早期离线计算选用了 HDP,实时计算后来选用 CDH 的初衷是多集群管理比较方便。由于离线计算引擎两者是有区别的,迁移会有兼容性问题,两套集群一直并存,集群间资源完全隔离。
集群维护痛点
数据量持续增长,成本一定的情况下做集群扩容耗时耗力
从 18 年初到 19 年 6 月份,离线集群从最初的数十个节点持续增长到上百个节点,数据量也从数十 TiB 增长了 10 多倍,并且保持每天数 TiB 的速度增加。在节省开支的情况下,每月做一次集群扩容,形成了与数据增长速度赛跑的情况。每月固定工作差不多变成了接受磁盘告警狂炸、扩容、均衡数据、再均衡数据的情况。遇到一些极端情况,比如阿里云在某个可用区没有数据类型设备资源而要新在另一个可用区创建,还会涉及到数据网段变更,就更复杂了。
- 存储所需资源跟计算资源不同步
在对离线集群数据做分析过程中发现,热点数据仅占大约 20%。在集群不断扩容的情况下,计算资源会有较大冗余,产生了不必要的成本,另外每次均衡会占用节点网络带宽,影响任务读写数据的速度。
- 跨集群数据同步
为了减少了实时任务和离线任务的相互影响,方便资源控制和云资源选型价值最大化,实时计算和离线计算集群在物理上做了资源隔离,难点也随之出现,实时和离线集群的数据无法实时同步,造成一些需求无法实现。
- NameNode内存持续增长,重启时间过久
在文件存储中,文件数量过多导致 NameNode 管理内存持续增加,重启一次时间过长,势必影响数据同步;并且在数仓层面不严加控制数据生命周期,资源占用也会越来越大,在对集群中整个资源做分析时也会受到影响。
选择 JuiceFS
针对以上这些问题,选取一款产品做底层存储势在必行。存储选择上作为大数据的基石,需要遵从如下特点:
- 兼容Hadoop框架协议
- 多版本集群兼容
- 高吞吐、低延时
- 支持深度压缩减少资源使用
在一开始,我们尝试使用阿里云的 OSS 作为冷备存储。在测试过程中,由于没有元信息管理,在数据维护上很受限制。后来接触到了 JuiceFS 这款产品,在选择上很是满足上述要求。对此我们做了一些性能测试(均基于实际场景提取业务逻辑)。
实际场景性能测试
以下测试均选取实际业务数据,数据大小是 where 查询条件不同选取的,仅做两个文件系统性能对比:
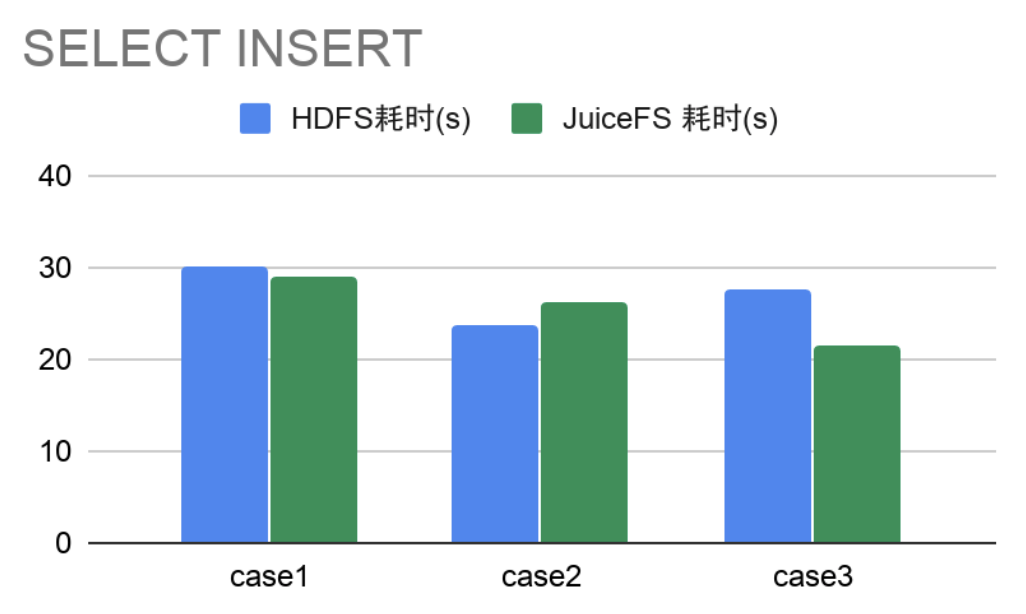
- SELECT + INSERT 操作
从 3000 万左右表中分别选取不同量级数据插入另一张表结构一样的表中,横向对比 HDFS 和 JuiceFS 耗时。
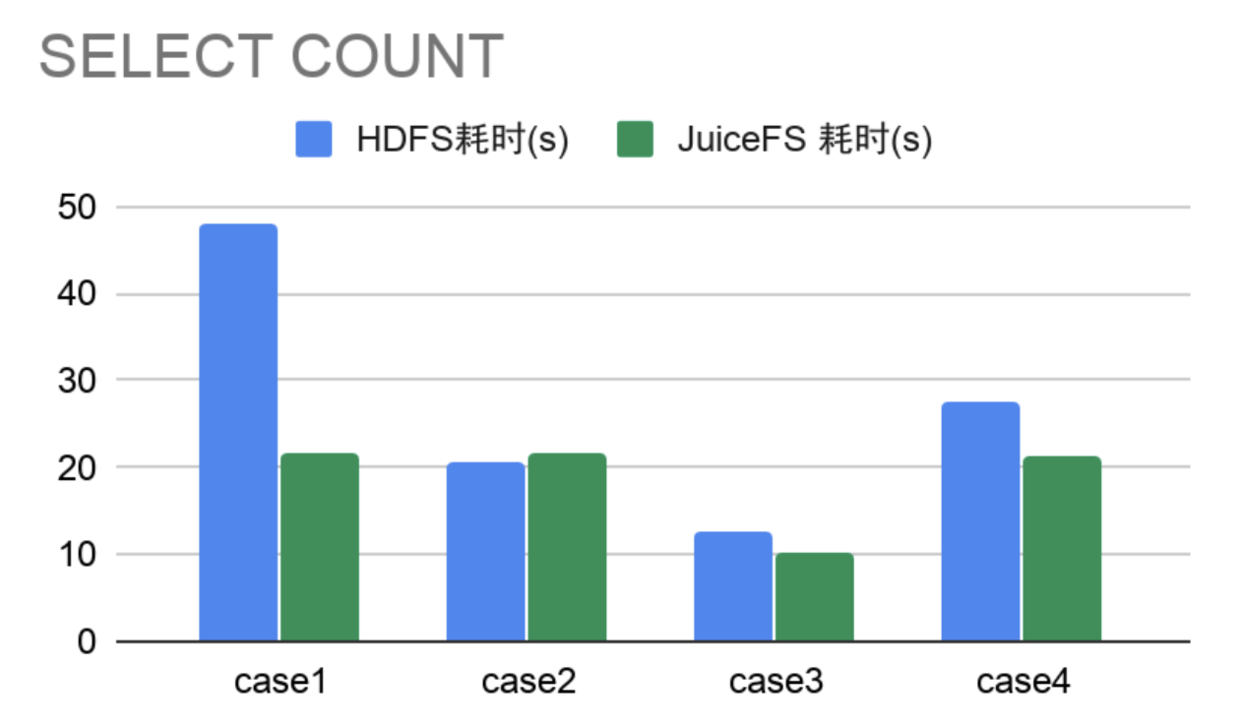
- SELECT + COUNT 操作
从3000万左右表中分别选取不同量级数据做 COUNT,横向对比 HDFS 和 JuiceFS 耗时。
- SELECT + ORDERBY
对 3000 万左右表中数据做排序,横向比较 HDFS 和 JuiceFS 的耗时。
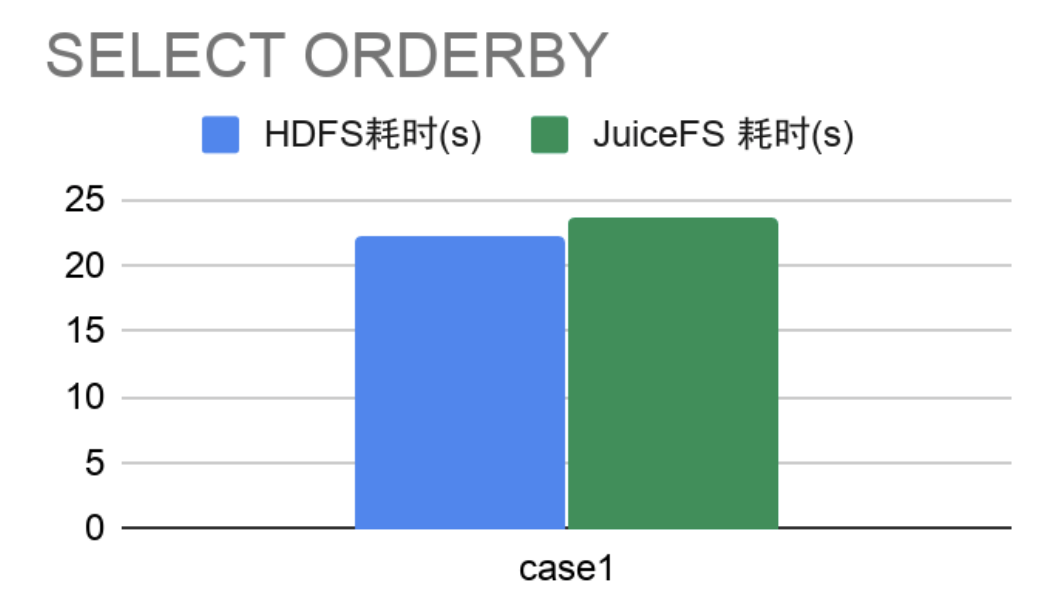
综上,JuiceFS 在查询、插入数据时多数耗时比较稳定且整体比HDFS耗时要少,在 SELECT 数据情况,多数性能相差不多极个别情况要优于 HDFS,单行做排序操作性能差不多。
成本控制
我们对比了采用 JuiceFS 和 HDFS 两种方案的费用(HDFS 集群保证存储冗余 20%)。在同等数据量(JuiceFS 会再次做深度压缩,压缩比大约为 3:1)和对等计算资源的情况下采用 JuiceFS 每月会比使用云主机部署 HDFS 节省至少 18%。
综合看 JuiceFS 的性能和成本都非常满足公司对成本和产品性能的要求。
未来展望
存储计算分离
大数据集群引入 JuiceFS,存储和计算实际上已经分离。大数据集群灵活弹性扩展计算资源已经成为可能,在凌晨业务低谷期可以将业务机器的计算资源调度给大数据集群。
以下是目前整个大数据集群架构:
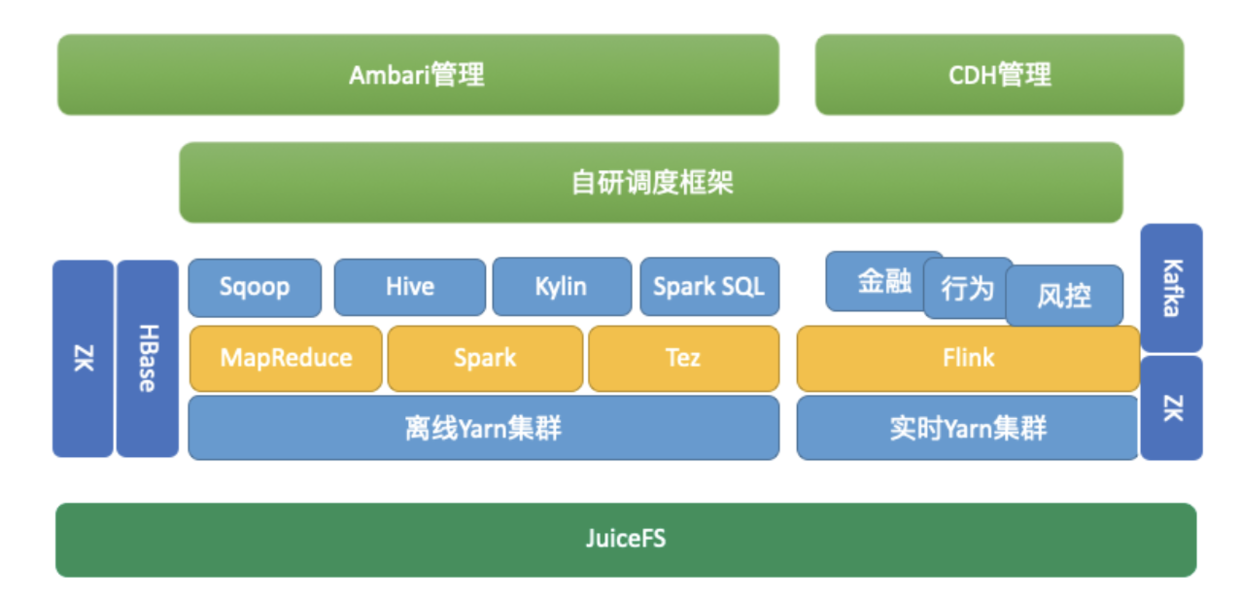
后续可以结合计算存储分离和动态伸缩设计为如下目标架构:
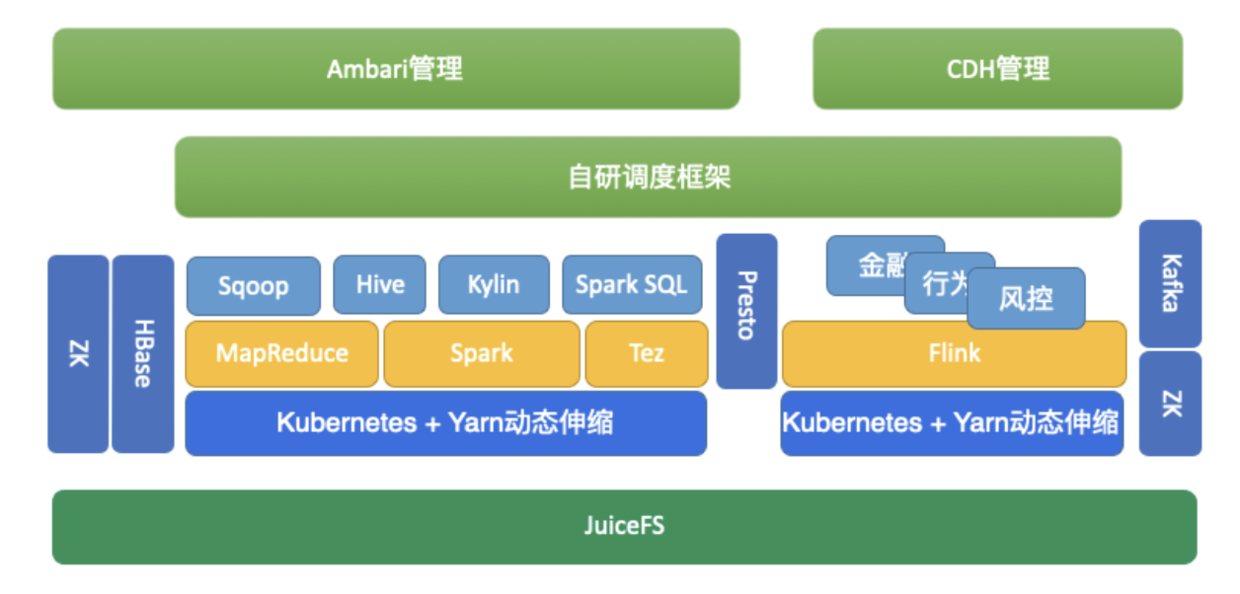
与 Kubernetes 做结合,按需申请资源,节省成本和减少维护成本。
推荐阅读:
JuiceFS CSI Driver 的最佳实践
项目地址: Github (https://github.com/juicedata/juicefs)如有帮助的话欢迎关注我们哟! (0ᴗ0✿)
JuiceFS 在大搜车数据平台的实践的更多相关文章
- 车架号VIN码识别,合格证,购车发票,房产证,车牌,驾驶证,行驶证,征信报告等等识别 从易鑫、大搜车、淘车网,看汽车金融发展新模式
随着我国汽车保有量和产销量的持续增长,汽车技术的日趋成熟,以及互联网+对汽车行业的不断影响,汽车金融的市场规模逐步扩大,市场主体逐步丰富,汽车金融模式也在不断演进. 2016年左右,美国主要汽车厂商通 ...
- HBase在大搜车金融业务中的应用实践
摘要: 2017云栖大会HBase专场,大搜车高级数据架构师申玉宝带来HBase在大搜车金融业务中的应用实践.本文主要从数据大屏开始谈起,进而分享了GPS风控实践,包括架构.聚集分析等,最后还分享了流 ...
- 回客科技 面试的 实现ioc 容器用到的技术,简述BeanFactory的实现原理,大搜车面试的 spring 怎么实现的依赖注入(DI)
前言:这几天的面试,感觉自己对spring 的整个掌握还是很薄弱.所以需要继续加强. 这里说明一下spring的这几个面试题,但是实际的感觉还是不对的,这种问题我认为需要真正读了spring的源码后说 ...
- 大数据平台迁移实践 | Apache DolphinScheduler 在当贝大数据环境中的应用
大家下午好,我是来自当贝网络科技大数据平台的基础开发工程师 王昱翔,感谢社区的邀请来参与这次分享,关于 Apache DolphinScheduler 在当贝网络科技大数据环境中的应用. 本次演讲主要 ...
- 大搜车知乎live中的面试题结题方法记录
1.HTML&CSS(分别10分) 1. 一个div,宽度是100px,此时设置padding是20px,添加一个什么css属性可以让div的实际宽度仍然保持在100px,而不是140px? ...
- Kafka 集群在马蜂窝大数据平台的优化与应用扩展
马蜂窝技术原创文章,更多干货请订阅公众号:mfwtech Kafka 是当下热门的消息队列中间件,它可以实时地处理海量数据,具备高吞吐.低延时等特性及可靠的消息异步传递机制,可以很好地解决不同系统间数 ...
- 海豚调度5月Meetup:6个月重构大数据平台,帮你避开调度升级改造/集群迁移踩过的坑
当今许多企业都有着技术架构的DataOps程度不够.二次开发成本高.迁移成本高.集群部署混乱等情况,团队在技术选型之后发现并不适合自己的需求,但是迁移成本和难度又比较大,甚至前团队还留下了不少坑,企业 ...
- 从 Hadoop 到云原生, 大数据平台如何做存算分离
Hadoop 的诞生改变了企业对数据的存储.处理和分析的过程,加速了大数据的发展,受到广泛的应用,给整个行业带来了变革意义的改变:随着云计算时代的到来, 存算分离的架构受到青睐,企业开开始对 Hado ...
- 大数据 > 数据平台方案评估
分类 当前措施 说明 百度竞价如何进行数据分析(SEM工程师)数据来源: 1. 百度后台推广数据:api 总展现 总点击 点击率 总消费 点击均价 BDP功能点 1. 串联百度->网站商务通-& ...
- 大数据平台R语言web UI应用架构 设计与开发
1. 系统拓扑图 在日常业务分析中,R是非常常用的分析工具,而当数据量较大时,用R语言需要需用更多的时间来完成训练模型,spark作为大规模数据处理框架,采用内存计算,可以短时间内完成大量的数据的处理 ...
随机推荐
- 前端科普系列(5):ESLint - 守住优雅的护城河
作者:Morrain [前端科普系列]帮助阅读者了解web前端,主要覆盖web前端的基础知识,但不深入讲解,定位为大而全并非细而精,适合非前端开发的同学对前端有一个系统的认识,能更好的与前端开发协作. ...
- freeswitch查看所有通道变量
概述 freeswitch 是一款好用的开源软交换平台. 实际应用中,我们经常需要对fs中的通道变量操作,包括设置和获取,set & get. 但是,fs中有众多的内部定义通道变量,也有外部传 ...
- HUD 5773 LIS(最长上升序列)
***关于lower_bound()的用法参见:http://blog.csdn.net/niushuai666/article/details/6734403 lower_bound用法:函数low ...
- python之数学函数应用
一.abs(x) 1.作用: 函数返回 x(数字)的绝对值,如果参数是一个复数,则返回它的大小(模) 2.举例说明: #1.abs() a = abs(-15) print(a) b = abs(1+ ...
- python 设计模式 开篇 第1篇
1. 设计模式的定义 软件设计中普遍存在的 反复出现的 各种问题 所提出的解决方案 首先,什么是软件设计? 系统开发 项目开始的时候 需要做 需求分析 软件系统设计 软件建模 类的设计 接口的设计 等 ...
- docker 原理之 namespace (上)
1. namespace 资源隔离 namespace 是内核实现的一种资源隔离技术,docker 使用 namespace 实现了资源隔离. Liunx 内核提供 6 种 namespace 隔离的 ...
- MyBatis 系列:MyBatis 源码环境搭建
目录 一.环境准备 二.下载 MyBatis 源码和 MyBatis-Parent 源码 三.创建空项目.导入项目 四.编译 mybatis-parent 五.编译 mybatis 六.测试 总结 一 ...
- .NET静态代码织入——肉夹馍(Rougamo)发布2.2
肉夹馍(https://github.com/inversionhourglass/Rougamo)通过静态代码织入方式实现AOP的组件,其主要特点是在编译时完成AOP代码织入,相比动态代理可以减少应 ...
- Makefile中的+=、:=、?=
1.= "="是最普通的等号,然而在Makefile中确实最容易搞错的赋值等号,使用"="进行赋值,变量的值是整个makefile中最后被指定的值.不太容易理解 ...
- 07-逻辑仿真工具VCS-Post processing with VCD+ files
逻辑仿真工具-VCS 编译完成不会产生波形,仿真完成之后,生成波形文件,通过dve产看波形 vcd是波形文件的格式,但是所占的内存比较大,后面出现了vpd(VCD+)波形文件 将一些系统函数嵌入到源代 ...