【阅读笔记】RAISR
RAISR:
- RAISR: Rapid and Accurate Image Super Resolution --Yaniv Romano, 2017(211 Citations)
核心思想
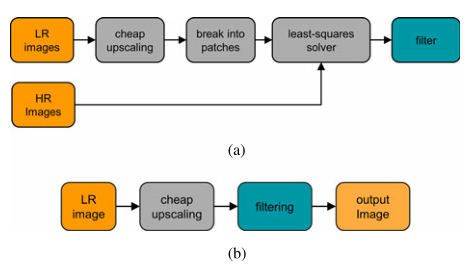
LR patch
A
A
A与滤波器
h
h
h 卷积 = HR像素
b
b
b
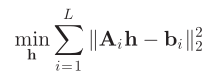
算法流程
offline阶段:X2SR
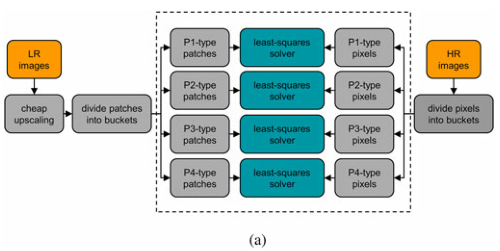
1、LR图通过bicubic插值,得HR初始图
Y
Y
Y,
Y
Y
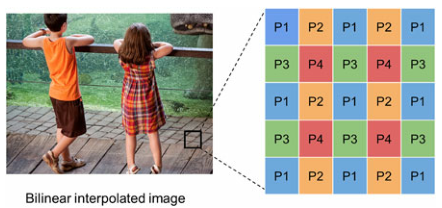
Y的像素分为4个像素类型(P1-P4),分切
n
∗
n
\sqrt{n}*\sqrt{n}
n
∗n
的patch
2、统计以P1像素类的像素
y
i
y_i
yi的patch内的h、v方向梯度信息
g
h
g_h
gh、
g
v
g_v
gv
3、根据
g
h
g_h
gh、
g
v
g_v
gv使用公式计算
y
i
y_i
yi的梯度angle、梯度strength、梯度coherence三种特征(类特征信息),P1像素类的像素根据三种特征归类;

其中,设置梯度Angle范围为[0,180],分为24段;梯度Strength和梯度Coherence范围为[0, 1.0],范围各分成3段。每个像素类的LR patch及其对应的HR patch可以分24x3x3=216梯度特征类中
4、假设Q包含一种梯度特征类的LR patch数据,V包含LR patch对应的HR patch数据,解最小二乘公式,得到每梯度特征类对应的h
m
i
n
h
∥
Q
h
−
V
∥
2
2
min_h \lVert Qh − V\rVert_2^2
minh∥Qh−V∥22
其中,h表示每个梯度特征类对应的滤波器(类映射关系)
online阶段:
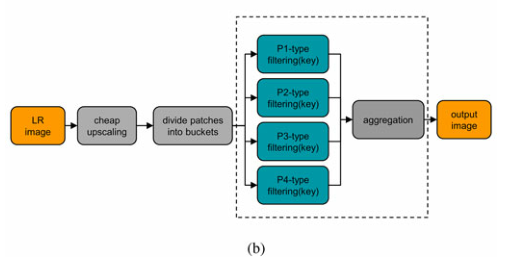
1、input图用bilinear插值得到HR初始图
Y
Y
Y,分切patch
y
i
y_i
yi
2、找到
y
i
y_i
yi的中心像素对应的像素类型
3、统计patch
y
i
y_i
yi的梯度信息,求出梯度(Angle,Strength,Coherence)
4、根据像素类型和梯度(Angle,Strength,Coherence),在864个分类中,找到
y
i
y_i
yi对应的特征类型,提取对应滤波器
5、
y
i
y_i
yi和它对应的滤波器做卷积操作,得到patch
y
i
y_i
yi中心像素对应的HR图像素
x
i
x_i
xi
6、循环2-5步遍历全图
Y
Y
Y,输出HR图
X
X
X
(1-6步流程图见上图)
7、根据局部结构相似度修正HR图像异常像素点
(1-7步流程图见下图)
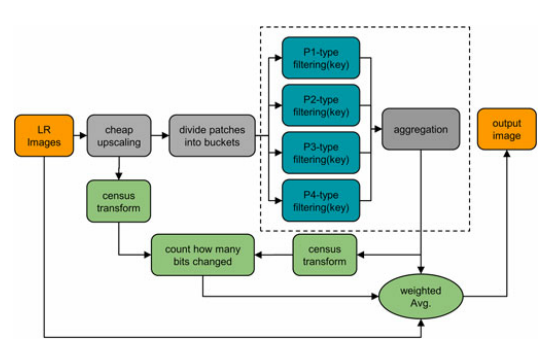
对训练图像集HR做锐化或对比度增强操作之后,再做训练。得到的滤波器可以使得重建图像清晰度、对比度更好,且不增加重建时间。
实验效果
filter滤波器大小 11x11,文本的滤波器用大小9x9
【阅读笔记】RAISR的更多相关文章
- 阅读笔记 1 火球 UML大战需求分析
伴随着七天国庆的结束,紧张的学习生活也开始了,首先声明,阅读笔记随着我不断地阅读进度会慢慢更新,而不是一次性的写完,所以会重复的编辑.对于我选的这本 <火球 UML大战需求分析>,首先 ...
- [阅读笔记]Software optimization resources
http://www.agner.org/optimize/#manuals 阅读笔记Optimizing software in C++ 7. The efficiency of differe ...
- 《uml大战需求分析》阅读笔记05
<uml大战需求分析>阅读笔记05 这次我主要阅读了这本书的第九十章,通过看这章的知识了解了不少的知识开发某系统的重要前提是:这个系统有谁在用?这些人通过这个系统能做什么事? 一般搞清楚这 ...
- <<UML大战需求分析>>阅读笔记(2)
<<UML大战需求分析>>阅读笔记(2)> 此次读了uml大战需求分析的第三四章,我发现这本书讲的特别的好,由于这学期正在学习设计模式这本书,这本书就讲究对uml图的利用 ...
- uml大战需求分析阅读笔记01
<<UML大战需求分析>>阅读笔记(1) 刚读了uml大战需求分析的第一二章,读了这些内容之后,令我深有感触.以前学习uml这门课的时候,并没有好好学,那时我认为这门课并没有什 ...
- Hadoop阅读笔记(七)——代理模式
关于Hadoop已经小记了六篇,<Hadoop实战>也已经翻完7章.仔细想想,这么好的一个框架,不能只是流于应用层面,跑跑数据排序.单表链接等,想得其精髓,还需深入内部. 按照<Ha ...
- Hadoop阅读笔记(六)——洞悉Hadoop序列化机制Writable
酒,是个好东西,前提要适量.今天参加了公司的年会,主题就是吃.喝.吹,除了那些天生话唠外,大部分人需要加点酒来作催化剂,让一个平时沉默寡言的码农也能成为一个喷子!在大家推杯换盏之际,难免一些画面浮现脑 ...
- Hadoop阅读笔记(五)——重返Hadoop目录结构
常言道:男人是视觉动物.我觉得不完全对,我的理解是范围再扩大点,不管男人女人都是视觉动物.某些场合(比如面试.初次见面等),别人没有那么多的闲暇时间听你诉说过往以塑立一个关于你的完整模型.所以,第一眼 ...
- Hadoop阅读笔记(四)——一幅图看透MapReduce机制
时至今日,已然看到第十章,似乎越是焦躁什么时候能翻完这本圣经的时候也让自己变得更加浮躁,想想后面还有一半的行程没走,我觉得这样“有口无心”的学习方式是不奏效的,或者是收效甚微的.如果有幸能有大牛路过, ...
- Hadoop阅读笔记(三)——深入MapReduce排序和单表连接
继上篇了解了使用MapReduce计算平均数以及去重后,我们再来一探MapReduce在排序以及单表关联上的处理方法.在MapReduce系列的第一篇就有说过,MapReduce不仅是一种分布式的计算 ...
随机推荐
- win11 计算器的进制转换
- Claude:除ChatGPT外的另一种选择
前言 Claude 是 Anthropic 开发的人工智能产品.Anthropic 是由 11 名前 OpenAI 员工于 2022 年创立的人工智能公司,旨在构建安全.可解释和有益于人类的人工智能系 ...
- 笔记:设置redhat 7.2 默认root用户启动以及网络服务自启动
笔记:设置redhat 7.2 默认root用户启动以及网络服务自启动 1.root用户启动 root用户下打开 /etc/gdm/custom.conf文件,添加字段如下: [daemo ...
- 我的第一个项目(十二) :分数和生命值的更新(后端增删查改的"改")
好家伙,写后端,这多是一件美逝. 关于这个项目的代码前面的博客有写 我的第一个独立项目 - 随笔分类 - 养肥胖虎 - 博客园 (cnblogs.com) 现在,我们登陆进去了,我开始和敌人战斗,诶 ...
- [Pytorch框架] 5.3 Fashion MNIST进行分类
文章目录 5.3 Fashion MNIST进行分类 Fashion MNIST 介绍 数据集介绍 分类 格式 数据提交 数据加载 创建网络 损失函数 优化器 开始训练 训练后操作 可视化损失函数 保 ...
- Python网页应用开发神器fac 0.2.6版本重要新功能一览
fac项目地址:https://github.com/CNFeffery/feffery-antd-components ,欢迎star支持 大家好我是费老师,距离我的开源Python网页应用通用组件 ...
- 【Linux】sed文本处理及软件管理
软件管理 1.编译安装http2.4,实现可以正常访问 安装编译相关工具包 root@mirror-centos8-p11 ~]# yum install gcc make autoconf apr- ...
- 文心一言 VS chatgpt (4)-- 算法导论2.2 1~2题
一.用O记号表示函数(n ^ 3)/1000-100(n^2)-100n十3. 文心一言: chatgpt: 可以使用大 O 记号表示该函数的渐进复杂度,即: f ( n ) = n 3 1000 − ...
- pgadmin数据输出不存在了?
菜单栏→文件→重置布局.这样数据输出就显示了.
- 2022-06-26:以下golang代码输出什么?A:true;B:false;C:编译错误。 package main import “fmt“ func main() { type
2022-06-26:以下golang代码输出什么?A:true:B:false:C:编译错误. package main import "fmt" func main() { t ...