从标准到开发,解读基于MOF的应用模型管理
摘要:为了打破技术与业务的壁垒,搭建技术与业务的桥梁,因此基于如下流程实现应用业务模型管理 ROMA ABM。
在数字经济时代,数据正在成为企业极其重要的战略性资产。在政府方面,数据第一次作为新型生产要素,列为比肩土地、劳动力、资本、技术的“第五要素”。随着数据增多,越来越难弄清楚这些数据背后的具体含义,从而引发一些下列问题:
- 查找信息难 大数据时代,政企数据量呈爆发式增长,在海量信息中快速、精确查找数据显得不尽如人意。
- 理解不一致 业务理解存在差异,让IT与业务脱节成为“两张皮”,从而造成大量重复工作,甚至影响业务决策。
- 学习成本高 员工具有一定的流动性,如缺乏业务的管理办法,对于新员工需要花费大量时间和成本做培训,造成严重的知识流失和金钱消耗。
对于上述的问题,构建以业务模型突破语义屏障、运营管理驱动高质量发展的思路,构建一套完善的资产管理方法。

为了打破技术与业务的壁垒,搭建技术与业务的桥梁,因此基于如下流程实现应用业务模型管理 ROMA ABM(Application Business Model),

如下对关键的流程做了说明和解读,方便大家更好的理解:
1. 模型标准
先解释下什么模型,模型是描述数据的数据,也统称为元数据,比如书的目录(作者、ISBN、价格等),简单对应对物理表的表字段,API的输入输出等。
业界OMG规范组织对模型有专门的定义,在MOF 2.5规范中模型术语M1层。
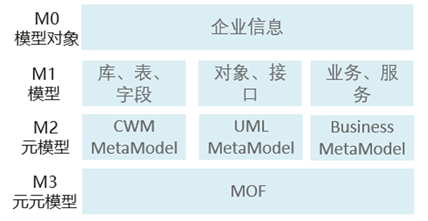
- M3是元元模型用于定义元模型,提供基础模型快速组装一个元模型包,例如定义元模型需要的领域、类、属性、关系等等;
- M2是元模型,是M3的实例,是一种模型的规范,具体来说就是描述组成模型的元素和元素之间的关系,如关系数据库元模型,从库到表、实例、表、字段、索引之间的关系;
- M1是模型,是用于描述数据的数据,比如一本书的目录信息(作者、ISBN、价格等),一般对应到物理表的表字段、API响应的字段等;
- M0是基于此模型的对象,也就是物理世界中的数据,一般对应到物理表中的数据。
2. 模型分类
ROMA ABM定义了业界比较认可分类方式,主要分为:技术模型,业务模型两种。
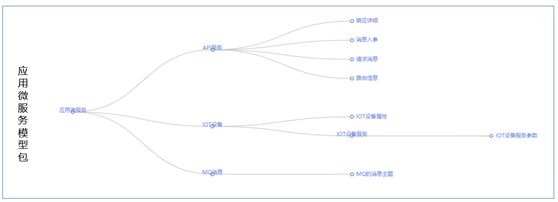
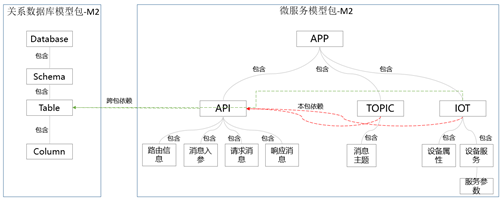
- 技术模型包括:字段名称、字段长度、数据库表结构、API描述、消息描述、文件描述等。技术模型通常通过自动化的任务完成对模型的采集,也可以通过文件导入等其他方式完成模型的获取,如下是关系型数据库、微服务模型包的样例供参考;

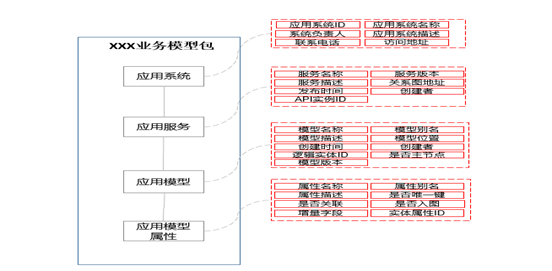
- 业务模型包括:业务名称、业务定义、业务描述、安全策略等给其他使用者能够看懂的业务属性,使用者可根据自己的业务线或者领域快速定位到自己想要获取的数据模型,通如下是业务模型的样例包供参考;
3. 模型设计
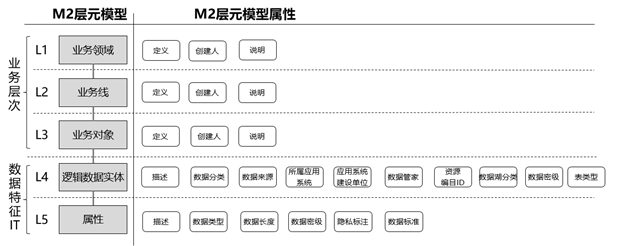
通过ROMA ABM的元模型可视化配置能力能够快速的完成元模型的设计,元模型的设计体现了设计者对整个业务系统的理解程度,从业务视角整理出的数据分类,这里我们可以称之为业务模型,它使得整个组织统一数据语言,是业务流打通、消除信息孤岛和提升业务流集成效率的关键要素。在设计业务模型之前,需要对组织的业务做端到端的梳理,例如有哪些业务范围、业务过程、业务发生主体、业务事件等等,然后将以上整理内容做归纳总结,设计出符合自己组织特有的业务模型(元模型),这里以智慧城市的场景为例,整理设计归纳出数字政府的业务模型:

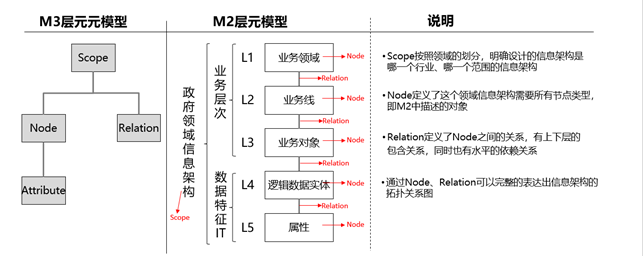
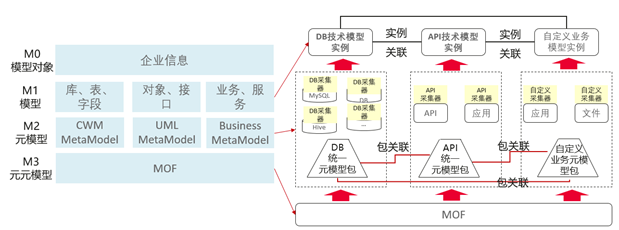
通过ROMA ABM可视化元模型配置能力完成数字政府业务模型的M2元模型配置、属性配置,为了帮助大家更好的理解元模型的设计,通过数字政府业务模型对M2、M3层做详细说明, M3层为M2层建模提供通用的元模型设计元素,具体参考如下:
M3层设计结构如下图:
M2层设计结构如下图:

M2层除了对业务条线做了抽象以外,还定义了业务属性,帮助使用者获取库表、API等底层结构依赖的业务附加属性,这些类内容通过底层的系统是无法获取的,具体需要附加哪些属性,需要数据管理者结合业务场景做梳理,如下是数字政府业务模型包中提供的通用属性,供参考;
通过上面的数字政府业务模型我们其实不难发现,模型管理的核心能力就是从抽象逐步分解到实现,M0、M1、M2、M3对象在真实系统中的关系可以总结如下:
- M1是M0层抽象,M0代表实际存储的数据,M1代表存储这组数据需要的结构,通常对应到业务系统中就是一组表结构、一组API、一组文件等等;
- M2是M1层的抽象,M2代表对M1这些表结构、API、文件等的存储模型,M2层虽然是元模型,但同时M2也是数据,因此元模型也需要统一的存储结构并且具备扩展性;
- M3是M2层的抽象,M3代表对M2的抽象,具有通用型,就和设计工具类似,可以设计各式各样的元模型;
4. 模型关联
通过以上设计完成了业务模型与技术模型的设计以及配置,但是这个时候两类模型之间并没有发生任何关系,因此我们需要将业务模型与技术模型关联起来,让技术语言走向业务语言,通过工具提供快速、稳定、多样的关联显得非常的重要。
在整个MOF框架中,M3-元模型是整个模型管理的核心, 那么如何构建“可配+多样+稳定”模型采集框架就很关键,我们可以参考如下原则:
- M3元模型能力图形组件化,通过拖拽方式完成对元模型包的构建;
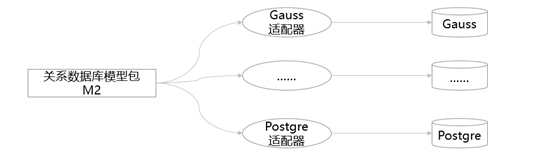
- 同类型元模型下的多套采集适配器共用“一套程序”,实现各种介质中的模型与关系进行采集与解析,重点用于对技术模的多样化采集,如下是关系型数据库的适配样例图:
- 元模型包设计过程中支持跨包关联,即当前元模型可以和其他元模型发生依赖关系,模型采集完成后自动实现跨包关联;
基于上述原则从而形成下列模型采集过程:
经过以上步骤处理以后,将本身不可读的表、字段、API等信息全部转化为带有业务语义的模型,让各个部门、各个系统、各个开发者在用数的查找上更简单、效率更高,彻底实现技术模型到业务模型的扭转。
5. 模型生态
应用业务模型管理(ROMA ABM)作为元模型驱动开发的载体,与周边系统或者伙伴形成良好的生态循环:
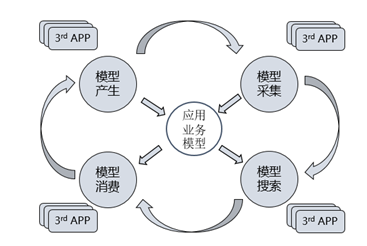
- 将存量系统中的库表、API、文件等技术模型自动化抽取,通过可视化的元模型设计器,让所有的技术模型能够按照业务领域统一存储,让开发者或者用户不需要关心实际的细节,屏蔽底层系统的差异;
- 通过模型扭转把技术模型与业务模型自动关联,让底层库表、API等这些无法理解的数据模型具有业务上的语义,同时让所有的底层数据模型回归到属于它自己的业务范围,让懂业务的开发者或用户可以在自己擅长的业务范围内,使用自己熟悉的业务语言完成数据模型的查找;
- 第三方应用或者系统可以通过统一的接口获取技术模型、业务模型,更进一步完成模型的消费,第三方应用或者系统基于已有的存量模型通过组合、编排等方式生成新的模型后,在回馈给应用业务模型管理服务,让所有模型像血液一样不停在整个系统中流动,最终形成完整的模型生态。
本文分享自华为云社区《基于MOF的应用模型管理》,原文作者:中间件小哥。
从标准到开发,解读基于MOF的应用模型管理的更多相关文章
- 开发《基于Arcgis Online的家政管理服务信息系统》随笔2
解决了三天的一个问题终于搞定了,和大家分享一下... 1.来点开胃菜, 在Sql server 2008中想要增加修改字段,有时不能修改,作如下操作即可搞定此问题, 启动MSSQL SERVER 2 ...
- 开发《基于Arcgis Online的家政管理服务信息系统》随笔1
1.在webservice中写的方法参数里面含有数组,如:public DataTable AdvSearch1(int ServiceArea, params string[] nas), 在发布之 ...
- XData -–无需开发、基于配置的数据库RESTful服务,可作为移动App和ExtJS、WPF/Silverlight、Ajax等应用的服务端
XData -–无需开发.基于配置的数据库RESTful服务,可作为移动App和ExtJS.WPF/Silverlight.Ajax等应用的服务端 源起一个App项目,Web服务器就一台,已经装了 ...
- 《深入浅出Windows Phone 8.1 应用开发》基于Runtime框架全新升级版
<深入浅出Windows Phone 8.1 应用开发>使用WP8.1 Runtime框架最新的API重写了上一本<深入浅出Windows Phone 8应用开发>大部分的的内 ...
- RabbitMQ是一个由erlang开发的基于AMQP(Advanced Message Queue )协议的开源实现。
RabbitMQ是一个由erlang开发的基于AMQP(Advanced Message Queue )协议的开源实现. 1. 介绍 RabbitMQ是一个由erlang开发的基于AMQP(Advan ...
- PLUTO平台是由美林数据技术股份有限公司下属西安交大美林数据挖掘研究中心自主研发的一款基于云计算技术架构的数据挖掘产品,产品设计严格遵循国际数据挖掘标准CRISP-DM(跨行业数据挖掘过程标准),具备完备的数据准备、模型构建、模型评估、模型管理、海量数据处理和高纬数据可视化分析能力。
http://www.meritdata.com.cn/article/90 PLUTO平台是由美林数据技术股份有限公司下属西安交大美林数据挖掘研究中心自主研发的一款基于云计算技术架构的数据挖掘产品, ...
- 构建一个基本的前端自动化开发环境 —— 基于 Gulp 的前端集成解决方案(四)
通过前面几节的准备工作,对于 npm / node / gulp 应该已经有了基本的认识,本节主要介绍如何构建一个基本的前端自动化开发环境. 下面将逐步构建一个可以自动编译 sass 文件.压缩 ja ...
- Go 语言开发的基于 Linux 虚拟服务器的负载平衡平台 Seesaw
负载均衡系统 Seesaw Seesaw是由我们网络可靠性工程师用 Go 语言开发的基于 Linux 虚拟服务器的负载平衡平台,就像所有好的项目一样,这个项目也是为了解决实际问题而产生的. Seesa ...
- C++标准库开发心得
最近放弃MFC,改用C++标准库开发产品.毕竟MFC用熟了,马上改用STL还不太习惯.下面列出下总结的改用STL遇到的问题和解决办法: 1.清除空格 remove_if(iterBegin, iter ...
- Apache Solr采用Java开发、基于Lucene的全文搜索服务器
http://docs.spring.io/spring-data/solr/ 首先介绍一下solr: Apache Solr (读音: SOLer) 是一个开源.高性能.采用Java开发.基于Luc ...
随机推荐
- Godot - 通过C#实现类似Unity协程
参考博客Unity 协程原理探究与实现 Godot 3.1.2版本尚不支持C#版本的协程,仿照Unity的形式进行一个协程的尝试 但因为Godot的轮询函数为逐帧的_Process(float del ...
- Ubuntu22.04 rc-local 配置开机自启动脚本
1. rc-local服务简介Linux中的rc-local服务是一个开机自动启动的,调用开发人员或系统管理员编写的可执行脚本或命令的,它的启动顺序是在系统所有服务加载完成之后执行. ubuntu22 ...
- Unity学习笔记--基础
基础 3D数学 Mathf函数库 print(Mathf.PI); print(Mathf.Abs(-10)); print(Mathf.CeilToInt(1.2f));//向上取整 print(M ...
- JAVA类的加载(4) ——类之间能够隔离&类占用的资源能回收
一.类加载体系
- STM32CUBEIDE中 Debug 和 Release 的作用/区别/使用场景
基本主流IDE都有该功能选项例如Keil MDK, IAR, Eclipse, VS等, 这里使用STM32CUBEIDE来举例 创建STM32CUBEIDE工程后默认有2个目标选项 Debug / ...
- AI歌姬,C位出道,基于PaddleHub/Diffsinger实现音频歌声合成操作(Python3.10)
懂乐理的音乐专业人士可以通过写乐谱并通过乐器演奏来展示他们的音乐创意和构思,但不识谱的素人如果也想跨界玩儿音乐,那么门槛儿就有点高了.但随着人工智能技术的快速迭代,现在任何一个人都可以成为" ...
- 搭建Samba服务器笔记全套
Top 目录 安装 端口与服务管理 其他常用命令 配置 全局配置 共享库配置 用户名密码认证库配置 Samba 登录用户配置 防火墙配置 设定安全的上下文关系 本地系统设置访问读写权限 Pdbedit ...
- 牛客小白月赛43 F 全体集合
题目链接 F 全体集合 题目大意 给出\(n\)个点\(m\)条边的无向图,给出\(k\)个点上分别有一个人,每个人一次只能走到一个相邻的节点,问有没有一种可能让这些人都走到一个点. 思路 考虑使用二 ...
- DP:三角形的最小路径和
给定一个三角形,找出自顶向下的最小路径和.每一步只能移动到下一行中相邻的结点上. 例如,给定三角形: [ [2], [3,4], [6,5,7], [4,1,8,3]] 自顶向下的 ...
- Spring配置文件的魔法炼金术:如何制造容器化时代的完美配方
前言 基于现代服务的云原生十二要素理论,我们在采用容器化部署时,要保证同一个镜像可以满足不同环境的部署要求,而不是不同环境打包不同的镜像.本文档主要介绍一种基于spring框架的满足不同环境配置的编译 ...