大数据实战手册-开发篇之spark实战案例:实时日志分析
2.6 spark实战案例:实时日志分析
- 2.6.1 交互流程图
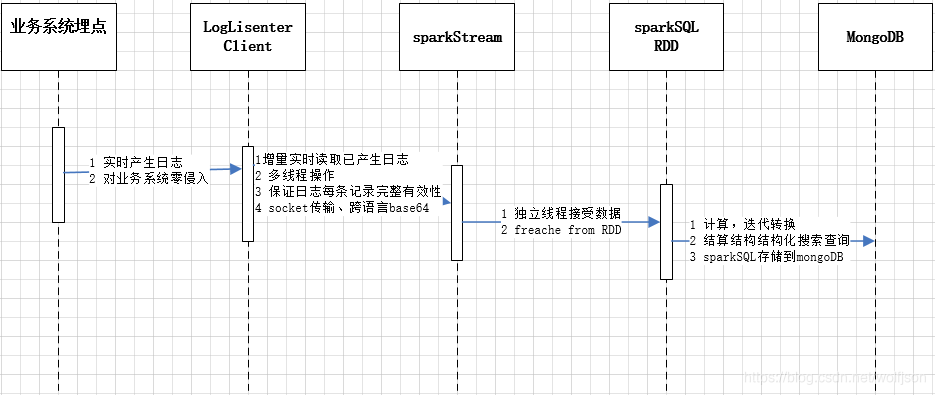
- 2.6.2 客户端监听器(java)
@SuppressWarnings("static-access")
private void handleSocket() {
lock.lock();
Writer writer = null;
RandomAccessFile raf = null; try {
File file = new File(filepath);
raf = new RandomAccessFile(file, "r");
raf.seek(pointer);
writer = new OutputStreamWriter(socket.getOutputStream(), "UTF-8"); String line = null; while ((line = raf.readLine()) != null) {
if (Strings.isBlank(line)) {
continue;
} line = new String(line.getBytes("ISO-8859-1"), "UTF-8");
writer.write(line.concat("\n"));
writer.flush();
logger.info("线程:{}----起始位置:{}----读取文件\n{} :",Thread.currentThread().getName(), pointer, line); pointer = raf.getFilePointer();
}
Thread.currentThread().sleep(2000);
} catch (Exception e) {
logger.error(e.getMessage());
e.printStackTrace();
} finally {
lock.unlock();
fclose(writer, raf);
} }
- 2.6.3 sparkStream实时数据接收(python)
conf = SparkConf()
conf.setAppName("HIS实时日志分析")
conf.setMaster('yarn') # spark standalone
conf.set('spark.executor.instances', 8) # cluster on yarn
conf.set('spark.executor.memory', '1g')
conf.set('spark.executor.cores', '1')
# conf.set('spark.cores.max', '2')
# conf.set('spark.logConf', True)
conf.set('spark.streaming.blockInterval', 1000*4) # restart receiver interval sc = SparkContext(conf = conf)
sc.setLogLevel('ERROR')
sc.setCheckpointDir('hdfs://hadoop01:9000/hadoop/upload/checkpoint/') ssc = StreamingContext(sc, 30) # time interval at which splits streaming data into block lines = ssc.socketTextStream(str(ip), int(port))
# lines.pprint()
lines.foreachRDD(requestLog)
lines.foreachRDD(errorLog)
ssc.start()
ssc.awaitTermination()
- 2.6.4 sparklSQL、RDD结算、结构化搜索、结构存储mongoDB(python)
def getSparkSessionInstance(sparkConf):
'''
:@desc 多个RDD全局共享sparksession
.config("spark.mongodb.input.uri", "mongodb://127.0.0.1/test.coll") \
.config("spark.mongodb.output.uri", "mongodb://adxkj:123456@192.168.0.252:27017/") \
:param sparkConf:
:return:
'''
if ('sparkSessionSingletonInstance' not in globals()):
globals()['sparkSessionSingletonInstance'] = SparkSession \
.builder \
.config(conf=sparkConf) \
.getOrCreate()
return globals()['sparkSessionSingletonInstance'] def timeFomate(x):
'''
:@desc 处理时间
:param x:
:return:
'''
if not isinstance(x, list):
return None # filter microsenconds
x.insert(0, ' '.join(x[0:2]))
x.pop(1)
x.pop(1) # filter '[]'
rx = re.compile('([\[\]\',])')
# text = rx.sub(r'\\\1', text)
x = [rx.sub(r'', x[i]) for i in range(len(x))] # string to time
x[0] = x[0][: x[0].find('.')]
x[0] = ''.join(x[0])
x[0] = datetime.strptime(x[0], '%Y-%m-%d %H:%M:%S') return x def sqlMysql(sqlResult, table, url="jdbc:mysql://192.168.0.252:3306/hisLog", user='root', password=""):
'''
:@desc sql结果保存
:param sqlResult:
:param table:
:param url:
:param user:
:param password:
:return:
'''
try:
sqlResult.write \
.mode('append') \
.format("jdbc") \
.option("url", url) \
.option("dbtable", table) \
.option("user", user) \
.option("password", password) \
.save()
except:
excType, excValue, excTraceback = sys.exc_info()
traceback.print_exception(excType, excValue, excTraceback, limit=3)
# print(excValue)
# traceback.print_tb(excTraceback) def sqlMongodb(sqlResult, table):
'''
:@desc sql结果保存
:param sqlResult:
:param table:
:param url:
:param user:
:param password:
:return:
'''
try:
sqlResult.\
write.\
format("com.mongodb.spark.sql.DefaultSource"). \
options(uri="mongodb://adxkj:123456@192.168.0.252:27017/hislog",
database="hislog", collection=table, user="adxkj", password="123456").\
mode("append").\
save()
except:
excType, excValue, excTraceback = sys.exc_info()
traceback.print_exception(excType, excValue, excTraceback, limit=3)
# print(excValue)
# traceback.print_tb(excTraceback) def decodeStr(x) :
'''
:@desc base64解码
:param x:
:return:
''' try:
if x[9].strip() != '' :
x[9] = base64.b64decode(x[9].encode("utf-8")).decode("utf-8")
# x[9] = x[9][:5000] #mysql if x[11].strip() != '':
x[11] = base64.b64decode(x[11].encode("utf-8")).decode("utf-8")
# x[11] = x[11][:5000] #mysql if len(x) > 12 and x[12].strip() != '':
x[12] = base64.b64decode(x[12].encode("utf-8")).decode("utf-8") except Exception as e:
print("不能解码:", x, e) return x def analyMod(x) :
'''
:@desc 通过uri匹配模块
:param x:
:return:
'''
if x[6].strip() == ' ':
return None hasMatch = False for k, v in URI_MODULES.items() :
if x[6].strip().startswith('/' + k) :
hasMatch = True
x.append(v) if not hasMatch:
x.append('公共模块') return x def requestLog(time, rdd):
'''
:@desc 请求日志分析
:param time:
:param rdd:
:return:
''' logging.info("+++++handle request log:length:%d,获取内容:++++++++++" % (rdd.count())) if rdd.isEmpty():
return None logging.info("++++++++++++++++++++++处理requestLog+++++++++++++++++++++++++++++++") reqrdd = rdd.map(lambda x: x.split(' ')).\
filter(lambda x: len(x) > 12 and x[4].find('http-nio-') > 0 and x[2].strip() == 'INFO').\
filter(lambda x: x[8].strip().upper().startswith('POST') or x[8].strip().upper().startswith('GET')).\
map(timeFomate).\
map(decodeStr).\
map(analyMod) reqrdd.cache()
reqrdd.checkpoint() # checkpoint先cache避免计算两次,以前的rdd销毁 sqlRdd = reqrdd.map(lambda x: Row(time=x[0], level=x[1], clz=x[2], thread=x[3], user=x[4], depart=x[5],
uri=x[6], method=x[7], ip=x[8], request=x[9], oplen=x[10],
respone=x[11], mod=x[12])) # rdd持久化,降低内存消耗, cache onliy for StorageLevel.MEMORY_ONLY
# reqrdd.persist(storageLevel=StorageLevel.MEMORY_AND_DISK_SER) if reqrdd.isEmpty():
return None spark = getSparkSessionInstance(rdd.context.getConf())
df = spark.createDataFrame(sqlRdd)
df.createOrReplaceTempView(REQUEST_TABLE) # 结构化后再分析
sqlresult = spark.sql("SELECT * FROM " + REQUEST_TABLE)
sqlresult.show() # 保存
sqlMongodb(sqlresult, REQUEST_TABLE) def errorLog(time, rdd):
'''
:@desc 错误日志分析
:param time:
:param rdd:
:return:
''' logging.info("+++++handle error log:length:%d,获取内容:++++++++++" % (rdd.count())) if rdd.isEmpty():
return None logging.info("++++++++++++++++++++++处理errorLog+++++++++++++++++++++++++++++++") errorrdd = rdd.map(lambda x: x.split(' ')). \
filter(lambda x: len(x) > 13 and x[2].strip().upper().startswith('ERROR')). \
map(timeFomate). \
map(decodeStr). \
map(analyMod). \
map(lambda x: Row(time=x[0], level=x[1], clz=x[2], thread=x[3], user=x[4], depart=x[5],
uri=x[6], method=x[7], ip=x[8], request=x[9], oplen=x[10],
respone=x[11], stack=x[12], mod=x[13]))
# rdd持久化,降低内存消耗
errorrdd.persist(storageLevel=StorageLevel.MEMORY_AND_DISK_SER) if errorrdd.isEmpty():
return None spark = getSparkSessionInstance(rdd.context.getConf())
df = spark.createDataFrame(errorrdd)
df.createOrReplaceTempView(ERROR_TABLE) # 结构化后再分析
sqlresult = spark.sql("SELECT * FROM " + ERROR_TABLE)
sqlresult.show() # 保存
sqlMongodb(sqlresult, ERROR_TABLE)
备注:需要完整代码请联系作者@狼
大数据实战手册-开发篇之spark实战案例:实时日志分析的更多相关文章
- 苏宁基于Spark Streaming的实时日志分析系统实践 Spark Streaming 在数据平台日志解析功能的应用
https://mp.weixin.qq.com/s/KPTM02-ICt72_7ZdRZIHBA 苏宁基于Spark Streaming的实时日志分析系统实践 原创: AI+落地实践 AI前线 20 ...
- Spark 实践——基于 Spark Streaming 的实时日志分析系统
本文基于<Spark 最佳实践>第6章 Spark 流式计算. 我们知道网站用户访问流量是不间断的,基于网站的访问日志,即 Web log 分析是典型的流式实时计算应用场景.比如百度统计, ...
- Java,面试题,简历,Linux,大数据,常用开发工具类,API文档,电子书,各种思维导图资源,百度网盘资源,BBS论坛系统 ERP管理系统 OA办公自动化管理系统 车辆管理系统 各种后台管理系统
Java,面试题,简历,Linux,大数据,常用开发工具类,API文档,电子书,各种思维导图资源,百度网盘资源BBS论坛系统 ERP管理系统 OA办公自动化管理系统 车辆管理系统 家庭理财系统 各种后 ...
- GIS+=地理信息+行业+大数据——基于云环境流处理平台下的实时交通创新型app
应用程序已经是近代的一个最重要的IT创新.应用程序是连接用户和数据之间的桥梁,提供即时訪问信息是最方便且呈现的方式也是easy理解的和令人惬意的. 然而,app开发人员.尤其是后端平台能力,一直在努力 ...
- Spark SQL慕课网日志分析(1)--系列软件(单机)安装配置使用
来源: 慕课网 Spark SQL慕课网日志分析_大数据实战 目标: spark系列软件的伪分布式的安装.配置.编译 spark的使用 系统: mac 10.13.3 /ubuntu 16.06,两个 ...
- 大数据项目实践:基于hadoop+spark+mongodb+mysql+c#开发医院临床知识库系统
一.前言 从20世纪90年代数字化医院概念提出到至今的20多年时间,数字化医院(Digital Hospital)在国内各大医院飞速的普及推广发展,并取得骄人成绩.不但有数字化医院管理信息系统(HIS ...
- 大数据核心知识点:Hbase、Spark、Hive、MapReduce概念理解,特点及机制
今天,上海尚学堂大数据培训班毕业的一位学生去参加易普软件公司面试,应聘的职位是大数据开发.面试官问了他10个问题,主要集中在Hbase.Spark.Hive和MapReduce上,基础概念.特点.应用 ...
- 大数据的前世今生【Hadoop、Spark】
一.大数据简介 大数据是一个很热门的话题,但它是什么时候开始兴起的呢? 大数据[big data]这个词最早在UNIX用户协会的会议上被使用,来自SGI公司的科学家在其文章“大数据与下一代基础架构 ...
- 了解大数据的技术生态系统 Hadoop,hive,spark(转载)
首先给出原文链接: 原文链接 大数据本身是一个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的.你能够把它比作一个厨房所以须要的各种工具. 锅碗瓢盆,各 ...
- 一文教你看懂大数据的技术生态圈:Hadoop,hive,spark
转自:https://www.cnblogs.com/reed/p/7730360.html 大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞 ...
随机推荐
- 免费注册 Redhat 开发者并且进行订阅和激活
注册 一.进入 https://www.redhat.com/wapps/ugc/register.html 进行注册 二.然后通过这个网址进入开发者平台 https://developers.red ...
- Nginx主要功能
Nginx主要功能: 1.反向代理2.负载均衡3.HTTP服务器(包含动静分离)4.正向代理 一.反向代理 反向代理应该是 Nginx 做的最多的一件事了,什么是反向代理呢,以下是百度百科的说法:反向 ...
- StampedLock:JDK1.8中新增,比ReadWriteLock还快的锁
摘要:StampedLock是一种在读取共享变量的过程中,允许后面的一个线程获取写锁对共享变量进行写操作,使用乐观读避免数据不一致的问题,并且在读多写少的高并发环境下,比ReadWriteLock更快 ...
- 多态 polymorphic
多态是同一个行为具有多个不同表现形式,多态实现需要以下条件 继承父类并重写方法 父类引用指向子类对象:Animal a = new Cat(); 多态实例: //测试类 public class Te ...
- Nvidia GPU池化-远程GPU
1 背景 Nvidia GPU得益于在深度学习领域强大的计算能力,使其在数据中心常年处于绝对的统治地位.尽管借助GPU虚拟化实现多任务混布,提高了GPU的利用率,缓解了长尾效应,但是GPU利用率的绝对 ...
- 【Spring5】框架新功能
Spring5框架新功能 整个Spring5框架的代码基于Java8,运行时兼容JDK9,许多不建议使用的类和方法在代码库中删除. Spring5自带了通用的日志封装:log4j2 已经移除了log4 ...
- CommunityToolkit.Mvvm8.1 IOC依赖注入控制反转(5)
本系列文章导航 https://www.cnblogs.com/aierong/p/17300066.html https://github.com/aierong/WpfDemo (自我Demo地址 ...
- Linx 阶段一
Linux Linux常用命令 具体演示 1). ls 2). pwd 3). touch 4). mkdir 5). rm 使用技巧 1. 连按 Tab健自动补齐文件名 2. ll 查看当前目录文件 ...
- 2023GDKOI游记
2023GDKOI游记 DAY-5: 3.5 周五回家提前一天返校,连续打了两场比赛,第二场清华ACM就只打出了最后一题世界杯(签到题),然后就只会做第二题了,调了一下午没想到正解. DAY-4: 3 ...
- P1008 [NOIP1998 普及组] 三连击,置顶题解的问题
题目链接: https://www.luogu.com.cn/problem/P1008 置顶题解 暴力,加简化的判断,数学原理,2个集合内所有数相加相乘结果一样,2个集合的内容一样(没错我自己编得, ...