Spark集群的安装及高可用配置
Spark集群的安装及高可用配置
前期需求:Hadoop和Scala必须已经安装完成
步骤:
①进入spark下载网站中https://spark.apache.org/downloads.html
(红框的部分是选择tar包的版本,选择完毕之后点击绿框的部分下载)
②下载完成之后用xftp将安装包传服务器的opt文件夹下。然后用tar命令解压。解压完成之后删除安装包。再然后进入/etc/profile配置环境变量。加入下面的两条语句,然后保存并退出用source命令使其生效。
export SPARK_HOME=/opt/spark-2.4.0-bin-hadoop2.7
在export PATH的末尾加上 :
S
P
A
R
K
H
O
M
E
/
b
i
n
:
SPARK_HOME/bin:
SPARKHOME/bin:SPARK_HOME/sbin
③进入/opt/spark-2.4.0-bin-hadoop2.7/conf文件夹下,执行下面两条语句
cp spark-env.sh.template spark-env.sh
cp slaves.template slaves
④用vi命令分别修改spark-env.sh和slaves
spark-env.sh的末尾添加如下语句

前三个都指的是对应的安装目录,这个不多赘述,后面五个的意思如下
HADOOP_CONF_DIR:hadoop集群的配置文件的目录
SPARK_MASTER_IP:spark集群的Master节点的ip地址
SPARK_WORKER_MEMORY:每个worker节点能够最大分配给exectors的内存大小
SPARK_WORKER_CORES:每个worker节点所占有的CPU核数目
SPARK_WORKER_INSTANCES:每台机器上开启的worker节点的数目
slaves的末尾修改为(工作者节点,我这里选择2号和3号机,1号作为Master)

修改$SPARK_HOME/conf/spark_defaults.conf
在其尾部添加
spark.executor.extraClassPath=/opt/flume_tar_dir/libs/*
spark.driver.extraClassPath=/opt/flume_tar_dir/libs/*
主要是为了spark-submit 提交时不用指定jars,但是需要自己在idea打jar包时指定类打包,将打包好的jar传入该入境下,提交时不用写–class
例:spark-submit --master spark://hadoop1:7077,hadoop2:7077 OfflineProject.jar
配置Spark高可用
vi /usr/etc/spark-2.3.0-bin-hadoop2.7/conf/spark-evn.sh
修改内容如下:
#export SPARK_MASTER_IP=Master #注释掉该行,Spark自己管理集群的状态
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=Master:2181,Worker1:2181,Worker2:2181 -Dspark.deploy.zookeeper.dir=/spark" #通过Zookeeper管理集群状态
/spark 自己定义一个保存数据的路径
实现高可用得先在前两个节点上启动 spark-master.sh
然后停掉一个节点 访问8080 查看状态
⑤将/etc/profile以及Spark文件夹用scp命令分发到其他两台机子上。发送过去之后到其他两台机子的窗口里,用source命令使环境变量生效
⑥回到一号机,开启Zookeeper,然后执行start-dfs.sh命令(开不开zookeeper其实没什么影响,也没要求说必须开,但是作为平常的习惯还是开启了Zk)。执行之后进入/opt/spark-2.4.0-bin-hadoop2.7文件夹下,执行 ./sbin/start-all.sh(进入这里执行的目的是为了防止和hadoop里的同名文件冲突)

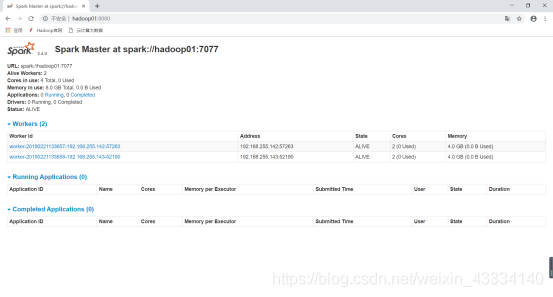
然后查看三台机子的节点(多了一个Master和两个Worker)



⑦进入Master所在机器的8080端口,可以查看Worker的信息
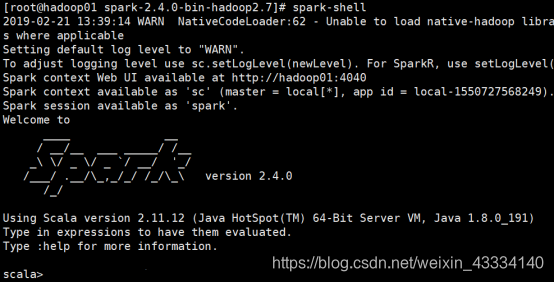
⑧在Master机器上执行 spark-shell命令。会出现如下语句
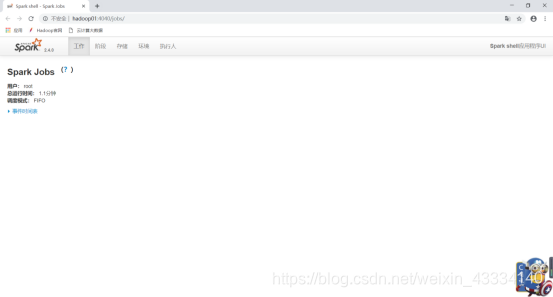
同样,在开启之后,也可以访问4040端口查看当前任务
至此,Spark集群安装就算圆满完成了。
Spark集群的安装及高可用配置的更多相关文章
- Apache shiro集群实现 (六)分布式集群系统下的高可用session解决方案---Session共享
Apache shiro集群实现 (一) shiro入门介绍 Apache shiro集群实现 (二) shiro 的INI配置 Apache shiro集群实现 (三)shiro身份认证(Shiro ...
- Apache shiro集群实现 (五)分布式集群系统下的高可用session解决方案
Apache shiro集群实现 (一) shiro入门介绍 Apache shiro集群实现 (二) shiro 的INI配置 Apache shiro集群实现 (三)shiro身份认证(Shiro ...
- Spark集群 + Akka + Kafka + Scala 开发(1) : 配置开发环境
目标 配置一个spark standalone集群 + akka + kafka + scala的开发环境. 创建一个基于spark的scala工程,并在spark standalone的集群环境中运 ...
- Spark系列—01 Spark集群的安装
一.概述 关于Spark是什么.为什么学习Spark等等,在这就不说了,直接看这个:http://spark.apache.org, 我就直接说一下Spark的一些优势: 1.快 与Hadoop的Ma ...
- openstack高可用集群21-生产环境高可用openstack集群部署记录
第一篇 集群概述 keepalived + haproxy +Rabbitmq集群+MariaDB Galera高可用集群 部署openstack时使用单个控制节点是非常危险的,这样就意味着单个节 ...
- k8s集群中部署Rook-Ceph高可用集群
先决条件 为确保您有一个准备就绪的 Kubernetes 集群Rook,您可以按照这些说明进行操作. 为了配置 Ceph 存储集群,至少需要以下本地存储选项之一: 原始设备(无分区或格式化文件系统) ...
- Docker namespace,cgroup,镜像构建,数据持久化及Harbor安装、高可用配置
1.Docker namespace 1.1 namespace介绍 namespace是Linux提供的用于分离进程树.网络接口.挂载点以及进程间通信等资源的方法.可以使运行在同一台机器上的不同服务 ...
- kubeadm安装集群系列-2.Master高可用
Master高可用安装 VIP负载均衡可以使用haproxy+keepalive实现,云上用户可以使用对应的ULB实现 准备kubeadm-init.yaml文件 apiVersion: kubead ...
- HAProxy+keepalived+MySQL 实现MHA中slave集群负载均衡的高可用
HAProxy+keepalived+MySQL实现MHA中slave集群的负载均衡的高可用 Ip地址划分: 240 mysql_b2 242 mysql_b1 247 haprox ...
- Cluster基础(四):创建RHCS集群环境、创建高可用Apache服务
一.创建RHCS集群环境 目标: 准备四台KVM虚拟机,其三台作为集群节点,一台安装luci并配置iSCSI存储服务,实现如下功能: 使用RHCS创建一个名为tarena的集群 集群中所有节点均需要挂 ...
随机推荐
- Django 自定义装饰器解决MySQL server has gone away错误
Django 自定义装饰器解决MySQL server has gone away错误 by:授客 QQ:1033553122 测试环境 Win 10 Python 3.5.4 Django- ...
- Jmeter汉化成中文版
1.jmeter安装成功后,默认启动是英文版 2.汉化方法 到jmeter安装目录下找到\bin\jmeter.properties,右键记事本打开定位"#language=en" ...
- Linux 备份命令 fsarchiver 基础使用教程
1 安装配置 fsarchiver 使用yum安装[二者选一个即可,我使用的是下面那个]: yum install https://dl.fedoraproject.org/pub/epel/epel ...
- 【Java】MultiThread 多线程 Re01
学习参考: https://www.bilibili.com/video/BV1ut411T7Yg 一.线程创建的四种方式: 1.集成线程类 /** * 使用匿名内部类实现子线程类,重写Run方法 * ...
- 【Uni-App】UniApp转微信小程序发布应用
参考地址: https://www.jianshu.com/p/a77b73f329e4 第一步,把原始Uni-App项目,转成微信小程序项目 点[发行]-- [小程序-微信(仅适用uni-app)] ...
- 《A Palestinian Woman Embraces the Body of Her Niece》—— 4月19日报道 2024年世界新闻摄影大赛结果在荷兰出炉,一张巴勒斯坦妇女在加沙地带抱着被杀害的五岁侄女尸体的照片被评为年度最佳作品
The genocide is not just a matter between the parties involved; it's a concern for all humanity. Gen ...
- 【转载】 Ring Allreduce (深度神经网络的分布式计算范式 -------------- 环形全局规约)
作者:初七123链接:https://www.jianshu.com/p/8c0e7edbefb9来源:简书著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. ----------- ...
- 基于浅层神经网络(全连接网络)的强化学习算法(Reinforce) 在训练过程中出现梯度衰退(degenerate)的现象
首先给出一个代码地址: https://gitee.com/devilmaycry812839668/CartPole-PolicyNetwork 强化学习中的策略网络算法.<TensorFlo ...
- 【转载】 Visual Studio Code几款FTP插件使用总结
===================================================== 平时要维护类似wordpress这样的网站,然后虚拟主机又不支持远程仓的版本管理.总而言之, ...
- 【转载】 xavier,kaiming初始化中的fan_in,fan_out在卷积神经网络是什么意思
原文地址: https://www.cnblogs.com/liuzhan709/p/10092679.html =========================================== ...