Spark集群的安装及高可用配置
Spark集群的安装及高可用配置
前期需求:Hadoop和Scala必须已经安装完成
步骤:
①进入spark下载网站中https://spark.apache.org/downloads.html
(红框的部分是选择tar包的版本,选择完毕之后点击绿框的部分下载)
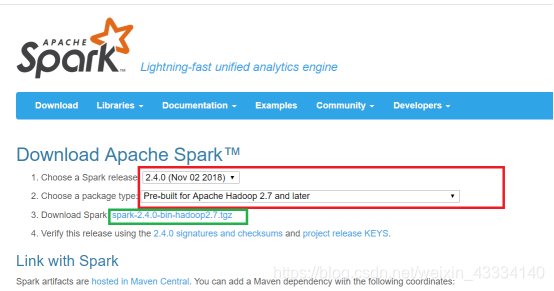
②下载完成之后用xftp将安装包传服务器的opt文件夹下。然后用tar命令解压。解压完成之后删除安装包。再然后进入/etc/profile配置环境变量。加入下面的两条语句,然后保存并退出用source命令使其生效。
export SPARK_HOME=/opt/spark-2.4.0-bin-hadoop2.7
在export PATH的末尾加上 :
S
P
A
R
K
H
O
M
E
/
b
i
n
:
SPARK_HOME/bin:
SPARKHOME/bin:SPARK_HOME/sbin
③进入/opt/spark-2.4.0-bin-hadoop2.7/conf文件夹下,执行下面两条语句
cp spark-env.sh.template spark-env.sh
cp slaves.template slaves
④用vi命令分别修改spark-env.sh和slaves
spark-env.sh的末尾添加如下语句

前三个都指的是对应的安装目录,这个不多赘述,后面五个的意思如下
HADOOP_CONF_DIR:hadoop集群的配置文件的目录
SPARK_MASTER_IP:spark集群的Master节点的ip地址
SPARK_WORKER_MEMORY:每个worker节点能够最大分配给exectors的内存大小
SPARK_WORKER_CORES:每个worker节点所占有的CPU核数目
SPARK_WORKER_INSTANCES:每台机器上开启的worker节点的数目
slaves的末尾修改为(工作者节点,我这里选择2号和3号机,1号作为Master)

修改$SPARK_HOME/conf/spark_defaults.conf
在其尾部添加
spark.executor.extraClassPath=/opt/flume_tar_dir/libs/*
spark.driver.extraClassPath=/opt/flume_tar_dir/libs/*
主要是为了spark-submit 提交时不用指定jars,但是需要自己在idea打jar包时指定类打包,将打包好的jar传入该入境下,提交时不用写–class
例:spark-submit --master spark://hadoop1:7077,hadoop2:7077 OfflineProject.jar
配置Spark高可用
vi /usr/etc/spark-2.3.0-bin-hadoop2.7/conf/spark-evn.sh
修改内容如下:
#export SPARK_MASTER_IP=Master #注释掉该行,Spark自己管理集群的状态
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=Master:2181,Worker1:2181,Worker2:2181 -Dspark.deploy.zookeeper.dir=/spark" #通过Zookeeper管理集群状态
/spark 自己定义一个保存数据的路径
实现高可用得先在前两个节点上启动 spark-master.sh
然后停掉一个节点 访问8080 查看状态
⑤将/etc/profile以及Spark文件夹用scp命令分发到其他两台机子上。发送过去之后到其他两台机子的窗口里,用source命令使环境变量生效
⑥回到一号机,开启Zookeeper,然后执行start-dfs.sh命令(开不开zookeeper其实没什么影响,也没要求说必须开,但是作为平常的习惯还是开启了Zk)。执行之后进入/opt/spark-2.4.0-bin-hadoop2.7文件夹下,执行 ./sbin/start-all.sh(进入这里执行的目的是为了防止和hadoop里的同名文件冲突)

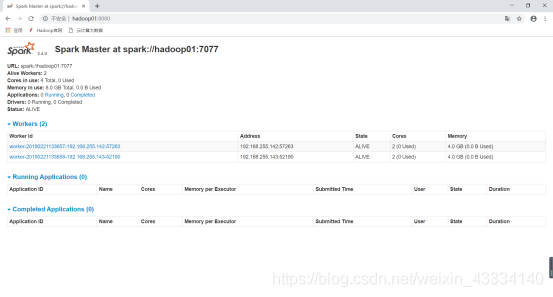
然后查看三台机子的节点(多了一个Master和两个Worker)



⑦进入Master所在机器的8080端口,可以查看Worker的信息
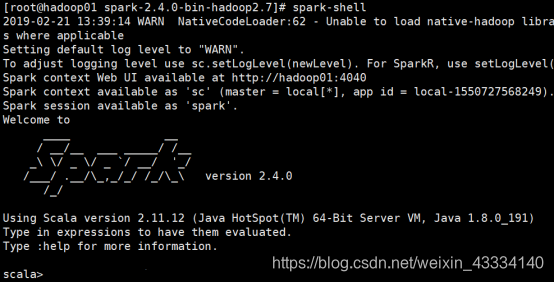
⑧在Master机器上执行 spark-shell命令。会出现如下语句
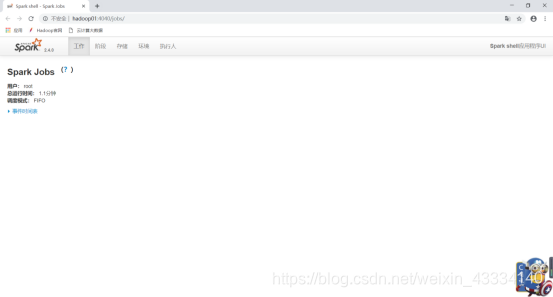
同样,在开启之后,也可以访问4040端口查看当前任务
至此,Spark集群安装就算圆满完成了。
Spark集群的安装及高可用配置的更多相关文章
- Apache shiro集群实现 (六)分布式集群系统下的高可用session解决方案---Session共享
Apache shiro集群实现 (一) shiro入门介绍 Apache shiro集群实现 (二) shiro 的INI配置 Apache shiro集群实现 (三)shiro身份认证(Shiro ...
- Apache shiro集群实现 (五)分布式集群系统下的高可用session解决方案
Apache shiro集群实现 (一) shiro入门介绍 Apache shiro集群实现 (二) shiro 的INI配置 Apache shiro集群实现 (三)shiro身份认证(Shiro ...
- Spark集群 + Akka + Kafka + Scala 开发(1) : 配置开发环境
目标 配置一个spark standalone集群 + akka + kafka + scala的开发环境. 创建一个基于spark的scala工程,并在spark standalone的集群环境中运 ...
- Spark系列—01 Spark集群的安装
一.概述 关于Spark是什么.为什么学习Spark等等,在这就不说了,直接看这个:http://spark.apache.org, 我就直接说一下Spark的一些优势: 1.快 与Hadoop的Ma ...
- openstack高可用集群21-生产环境高可用openstack集群部署记录
第一篇 集群概述 keepalived + haproxy +Rabbitmq集群+MariaDB Galera高可用集群 部署openstack时使用单个控制节点是非常危险的,这样就意味着单个节 ...
- k8s集群中部署Rook-Ceph高可用集群
先决条件 为确保您有一个准备就绪的 Kubernetes 集群Rook,您可以按照这些说明进行操作. 为了配置 Ceph 存储集群,至少需要以下本地存储选项之一: 原始设备(无分区或格式化文件系统) ...
- Docker namespace,cgroup,镜像构建,数据持久化及Harbor安装、高可用配置
1.Docker namespace 1.1 namespace介绍 namespace是Linux提供的用于分离进程树.网络接口.挂载点以及进程间通信等资源的方法.可以使运行在同一台机器上的不同服务 ...
- kubeadm安装集群系列-2.Master高可用
Master高可用安装 VIP负载均衡可以使用haproxy+keepalive实现,云上用户可以使用对应的ULB实现 准备kubeadm-init.yaml文件 apiVersion: kubead ...
- HAProxy+keepalived+MySQL 实现MHA中slave集群负载均衡的高可用
HAProxy+keepalived+MySQL实现MHA中slave集群的负载均衡的高可用 Ip地址划分: 240 mysql_b2 242 mysql_b1 247 haprox ...
- Cluster基础(四):创建RHCS集群环境、创建高可用Apache服务
一.创建RHCS集群环境 目标: 准备四台KVM虚拟机,其三台作为集群节点,一台安装luci并配置iSCSI存储服务,实现如下功能: 使用RHCS创建一个名为tarena的集群 集群中所有节点均需要挂 ...
随机推荐
- __int128的输入输出(快读快输)
引言:__int128不能用\(cin\)\(cout\)或\(scanf\)\(printf\). 快读 思想:把每一个字符读入,组成数字. int read(){ int x = 0,y = 1; ...
- 带你学习通过GitHub Actions如何快速构建和部署你自己的项目,打造一条属于自己的流水线
本文主要讲解通过github的actions来对我们项目进行ci/cd 一.actions简介 GitHub Actions 是一种持续集成和持续交付 (CI/CD) 平台,可用于自动执行生成.测试和 ...
- RDD | 算子 | 持久化
分布式集合对象上的API称之为算子 算子分为两类: transformation算子:指返回值仍然是rdd,类似于stream里的中间流 这类算子与中间流相同,是懒加载的 action算子:返回值不是 ...
- 新版宝塔面板快速搭建WordPress新手教程
一.宝塔面板介绍 1. 介绍 宝塔面板是一款服务器管理软件,支持Windows和Linux系统,可以通过Web端轻松管理服务器,提升运维效率,该软件内置了创建管理网站.FTP.数据库.可视化文件管理器 ...
- JAVA并发编程理论基础
注:本文章是对极客时间<java并发编程实战>学习归纳总结,更多知识点可到原文 java并发编程实战 进行学习.如果侵权,联系删除: 一.并发编程的BUG的源头 1.1 缓存导致的可见性问 ...
- jmeter测试udp广播(jmeter发送udp)
jmeter测试udp广播(jmeter发送udp) jmeter测试udp广播(jmeter接收udp) 先下载安装第三方插件 下载链接:https://jmeter-plugins.org/ins ...
- P1973 [NOI2011] NOI 嘉年华
思路: 先将时间进行离散化,设总时间为 \(cnt\),然后考虑求出 \(W(l,r)\),即在时间段 \([l,r]\) 内的所有节目,可以 \(n^2\) 前缀和,也可以 \(n^3\) 暴力. ...
- 【Java】JDBC Part6 Apache-DBUtil & Spring-JdbcTemplate
Apache-DBUtils 开源的JDBC工具类,对JDBC的简单封装 SQL操作交给了QueryRunner的实例 Maven依赖 <!-- https://mvnrepository.co ...
- 【Redis】02 Redis 搭建与操作
Redis的安装及启动停止 官网地址: https://redis.io/download 使用wget命令下载redis wget 下载地址 下载: [root@VM-0-7-centos ~]# ...
- 使用 addRouteMiddleware 动态添加中间
title: 使用 addRouteMiddleware 动态添加中间 date: 2024/8/4 updated: 2024/8/4 author: cmdragon excerpt: 摘要:文章 ...