Flink Standalone集群部署
Flink Standalone模式部署集群是最简单的一种部署方式,不依赖于其他的组件,另外还支持YARN/Mesos/Docker等模式下的部署,这里使用的flink版本为最新的稳定版1.9.1版本,对应的Scala版本是2.11,二进制包为:flink-1.9.1-bin-scala_2.11.tgz,即将安装的环境为内网4个节点,其中1个jobmanager,3个taskmanager,角色分配如下:
bigdata1 - jobmanager
bigdata2, bigdata3, bigdata4 - taskmanager
老规矩,配置flink前必须做下面的基础准备:
1). JDK环境,1.8.x或者更高,Oracle JDK或者OpenJDK都可以,二进制包解压的方式安装要配置好JAVA_HOME
2). 主机名和hosts配置文件集群内完全对应,准确配置.
3). 集群之间保证通信正常,关闭防火墙或者提前设置好规则.
4). 集群所有节点配置ssh免密,否则后续启动集群的时候还需要输入密码.
5). 集群配置时间同步服务,ntp或者chrony服务,这个应该是大数据组件集群的标配
然后准备安装flink,flink的安装目录为了便于维护所有的安装位置都要一致,这里是/opt/flink-1.9.1,首先在其中1个节点bigdata1上开始配置:
解压安装包并进入安装目录: tar -xvzf flink-1.9.1-bin-scala_2.11.tgz -C /opt && cd /opt/flink-1.9.1
编辑配置文件:conf/flink-conf.yaml,对于独立集群有下面的配置项需要修改:
jobmanager.rpc.address: bigdata1
jobmanager.rpc.port: 6123
jobmanager.heap.size: 2048m
taskmanager.heap.size: 4096m
taskmanager.numberOfTaskSlots: 4
parallelism.default: 1
简单来看一下jobmanager.rpc.address表示jobmanager rpc通信绑定的地址,这里就是jobmanager的主机名
jobmanager.rpc.port是jobmanager的rpc端口,默认是6123
jobmanager.heap.size 这个是 jobmanager jvm进程的堆内存大小,默认是1024M,这里设置成2048m,也就是2G
taskmanager.heap.size 这个是taskmanager jvm进程的堆内存大小,也就是实际运行任务的jvm最大所能占用的堆内存,默认也是1024m,这里设置成4g
taskmanager.numberOfTaskSlots 这个表示每个taskmanager所能提供的slots数量,也就是flink节点的计算能力,这个和算子的并行度配合使用,每个slot运行1个pipeline[source,transformation,slink],多个slot使得flink的subtasks是并行的,这个一般设置成和机器cpu核数一致,比如我们这里是3个taskmanager,每个taskmanager是4个slots,那么这个集群的slots个数为12.
parallelism.default 这个是默认任务的并行度,也就是说当代码中或者提交时没指定并行度,则按照这里的并行度执行任务,并行度是按照整个集群来算的,比如上面slots个数为12,那么支持subtasks最大的并行度就是12,因为在代码中通常会针对单个任务设置并行度,所以这里的默认并行度可以不设置.
上面这几项是flink独立集群最基本的配置,另外还有关于rest和web ui的配置,如果需要可以配置一下,我这里按照默认的配置:
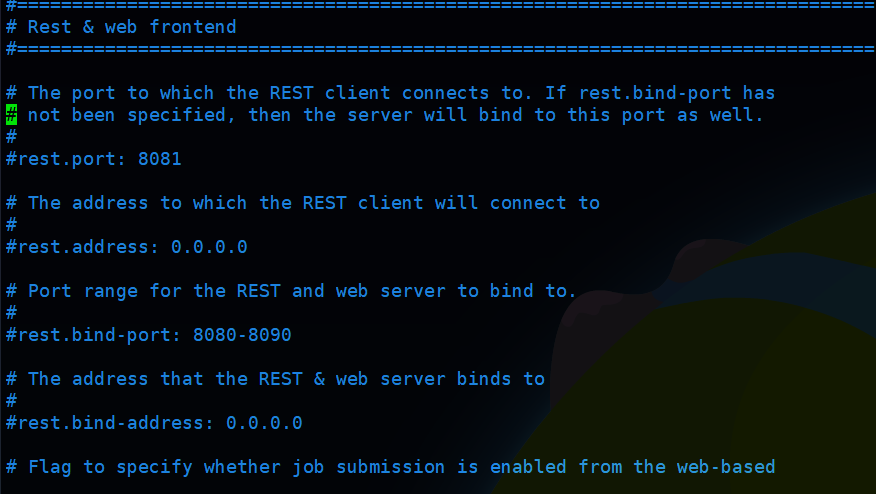

web ui和jobmanager同时运行,端口默认为8081,可以根据需要修改,另外还有个参数:web.submit.enable,也就是是否可以从界面提交任务,默认是开启的,取消注释就可以关闭.
确认上面配置无误之后,保存配置
然后配置masters和slaves的节点文件,
conf/masters,配置jobmanager的机器列表,这里独立集群非HA模式下配置为:bigdata1:8081
conf/slaves,配置taskmanager的机器列表,这里配置如下:
确认上面配置正常全部保存,接下来就可以从bigdata1将配置好的flink分发到其他3个节点:
scp -r /opt/flink-1.9.1 bigdata2:/opt
scp -r /opt/flink-1.9.1 bigdata3:/opt
scp -r /opt/flink-1.9.1 bigdata4:/opt
然后从任意1个节点可以启动集群,启动命令为: bin/start-cluster.sh 执行之后jobmanager和taskmanager就全部启动了,通过jps可以查看到相应的进程,jobmanager的进程为StandaloneSessionClusterEntrypoint,其余3个taskmanager的进程为TaskManagerRunner,然后可以访问浏览器界面查看web ui,这里是:http://bigdata1:8081
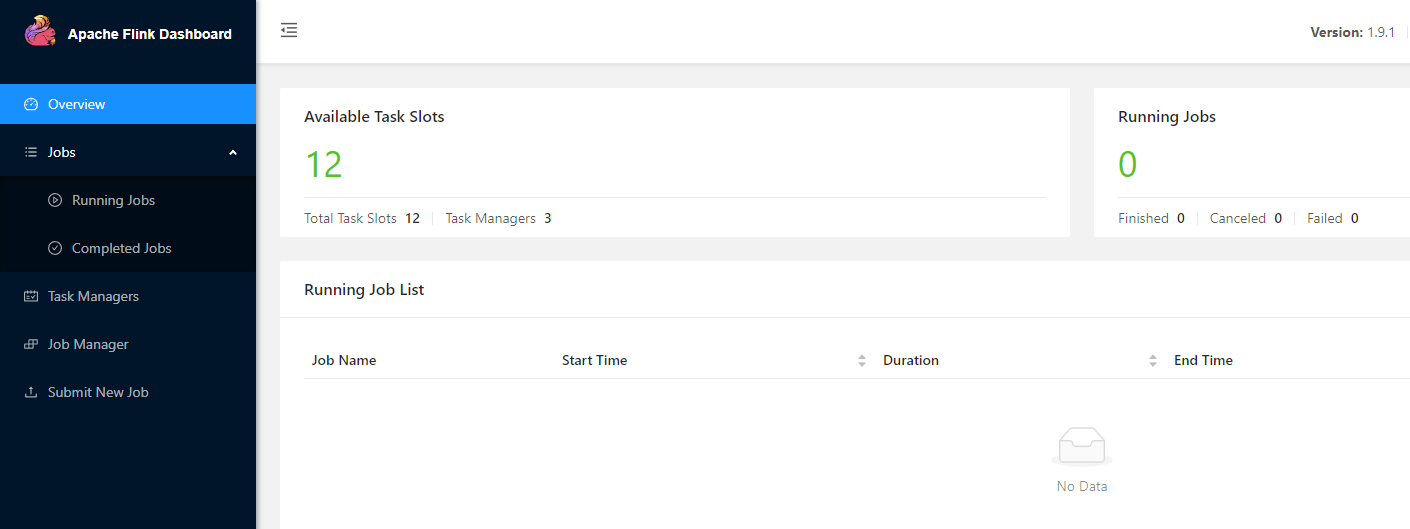
这样,flink standalone模式的集群就配置完成了
停止集群命令: bin/stop-cluster.sh 执行之后所有节点的进程都会停止
单个jobmanager的启动或停止: bin/jobmanager.sh start|start-foreground|stop|stop-all
单个taskmanager的启动或停止: bin/taskmanager.sh start|start-foreground|stop|stop-all
其中start-foreground是在前台启动,单独启动的命令一方面可以用在cluster启动或者停止失败的时候执行,另一方面可以用于flink集群运行时向其中加入节点,主要是运行时添加配置好的taskmanager节点,这样可以为集群动态扩容,添加之后稍微等一下,web界面就可以看到可用的slots和task managers数量发生变化了.
参考文档:https://ci.apache.org/projects/flink/flink-docs-release-1.9/zh/ops/deployment/cluster_setup.html
Flink Standalone集群部署的更多相关文章
- flink初识及安装flink standalone集群
flink architecture 1.可以看出,flink可以运行在本地,也可以类似spark一样on yarn或者standalone模式(与spark standalone也很相似),此外fl ...
- flink部署操作-flink standalone集群安装部署
flink集群安装部署 standalone集群模式 必须依赖 必须的软件 JAVA_HOME配置 flink安装 配置flink 启动flink 添加Jobmanager/taskmanager 实 ...
- Flink 集群搭建,Standalone,集群部署,HA高可用部署
基础环境 准备3台虚拟机 配置无密码登录 配置方法:https://ipooli.com/2020/04/linux_host/ 并且做好主机映射. 下载Flink https://www.apach ...
- spark standalone集群部署 实践记录
本文记录了一次搭建spark-standalone模式集群的过程,我准备了3个虚拟机服务器,三个centos系统的虚拟机. 环境准备: -每台上安装java1.8 -以及scala2.11.x (x代 ...
- Standalone 集群部署
Spark中调度其实是分为两个层级的,即集群层级的资源分配和任务调度,以及任务层级的任务管理.其中集群层级调度是可配置的,Spark目前提供了Local,Standalone,YARN,Mesos.任 ...
- Flink集群部署
部署方式 一般来讲有三种方式: Local Standalone Flink On Yarn/Mesos/K8s… 单机模式 参考上一篇Flink从入门到放弃(入门篇2)-本地环境搭建&构建第 ...
- Spark standalone安装(最小化集群部署)
Spark standalone安装-最小化集群部署(Spark官方建议使用Standalone模式) 集群规划: 主机 IP ...
- Scala进阶之路-Spark独立模式(Standalone)集群部署
Scala进阶之路-Spark独立模式(Standalone)集群部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我们知道Hadoop解决了大数据的存储和计算,存储使用HDFS ...
- zookeeper的单实例和伪集群部署
原文链接: http://gudaoyufu.com/?p=1395 zookeeper工作方式 ZooKeeper 是一个开源的分布式协调服务,由雅虎创建,是 Google Chubby 的开源实现 ...
- flink的集群的HA高可用
对于一个企业级的应用,稳定性是首要要考虑的问题,然后才是性能,因此 HA 机制是必不可少的: 和 Hadoop 一代一样,从架构中我们可以很明显的发现 JobManager 有明显的单点问题(SPOF ...
随机推荐
- Centos安装常见软件
一.vscode sudo rpm --import https://packages.microsoft.com/keys/microsoft.asc sudo sh -c 'echo -e &qu ...
- ble的notification和indication的区别和联系
Ble服务端传输消息有两个常用手段,notification和indication.那么这两者之间有什么区别呢? Notification 不需要应答,所以服务端发送的消息,它自己并不知道消息是否发送 ...
- C++多态底层原理:虚函数表
虚函数表 C++ 对象模型 在有虚函数的情况下,C++对象的模型可以概括为:虚函数表指针+数据struct.在对象所在的内存里:前8个字节(64位系统)是虚函数表所在地址,后边是对象中的member ...
- Android混淆后的bug日志通过mapping文件找对应行号
背景 由于项目中提测以及线上的apk都是经过混淆处理的,因此拿到日志后也无法正常查看崩溃日志的行号 这个原因是因为混淆了文件,输出的日志是对应不上源文件的,为了正确找到行号需要用到mapping.tx ...
- Redis集群模式和常用数据结构
一.Redis 支持三种主要的集群模式 主从复制模式(Master-Slave Replication): 在这种模式下,主节点(Master)负责处理写入操作,而从节点(Slave)则是主节点的副本 ...
- 记录--Echarts绘制气泡图
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 Echarts绘制气泡图 气泡图是一种用于可视化三维数据的图表类型,其中两个变量用于确定数据点在平面上的位置,另一个变量用于确定气泡的大小 ...
- OpenCvSharp inputs[0].size[1] % blobs[0].size[1] == 0
报错代码如图 详细错误 未处理 OpenCvSharp.OpenCVException HResult=-2146233088 Message=inputs[0].size[1] % blobs[0] ...
- 降低FTP服务器速度的解决方案(Filezilla等)
我最近发现,尽管有70Mbps(8.75MB / s)的互联网连接和1Gbps(125MB / s)的专用服务器可以从中下载,但我似乎只能从FTP服务器上以大约16.8Mbps(2.1MB / s)的 ...
- read IEEE standard for verilog(3)
read IEEE std for verilog 1.阅读准备 在阅读的第二部分读到了lexical conventions,这次计划读一节.也就是把lexical conventions读完. 2 ...
- KingbaseES V8R6 Deallocate 语句使用说明
用途 DEALLOCATE被用来释放一个之前PREPARE好的SQL语句.如果不显式地释放一个PREPARE语句,那么会话结束时会释放它. prepare语句类似oracle的绑定变量 绑定过程: 1 ...