Flink Standalone集群部署
Flink Standalone模式部署集群是最简单的一种部署方式,不依赖于其他的组件,另外还支持YARN/Mesos/Docker等模式下的部署,这里使用的flink版本为最新的稳定版1.9.1版本,对应的Scala版本是2.11,二进制包为:flink-1.9.1-bin-scala_2.11.tgz,即将安装的环境为内网4个节点,其中1个jobmanager,3个taskmanager,角色分配如下:
bigdata1 - jobmanager
bigdata2, bigdata3, bigdata4 - taskmanager
老规矩,配置flink前必须做下面的基础准备:
1). JDK环境,1.8.x或者更高,Oracle JDK或者OpenJDK都可以,二进制包解压的方式安装要配置好JAVA_HOME
2). 主机名和hosts配置文件集群内完全对应,准确配置.
3). 集群之间保证通信正常,关闭防火墙或者提前设置好规则.
4). 集群所有节点配置ssh免密,否则后续启动集群的时候还需要输入密码.
5). 集群配置时间同步服务,ntp或者chrony服务,这个应该是大数据组件集群的标配
然后准备安装flink,flink的安装目录为了便于维护所有的安装位置都要一致,这里是/opt/flink-1.9.1,首先在其中1个节点bigdata1上开始配置:
解压安装包并进入安装目录: tar -xvzf flink-1.9.1-bin-scala_2.11.tgz -C /opt && cd /opt/flink-1.9.1
编辑配置文件:conf/flink-conf.yaml,对于独立集群有下面的配置项需要修改:
jobmanager.rpc.address: bigdata1
jobmanager.rpc.port: 6123
jobmanager.heap.size: 2048m
taskmanager.heap.size: 4096m
taskmanager.numberOfTaskSlots: 4
parallelism.default: 1
简单来看一下jobmanager.rpc.address表示jobmanager rpc通信绑定的地址,这里就是jobmanager的主机名
jobmanager.rpc.port是jobmanager的rpc端口,默认是6123
jobmanager.heap.size 这个是 jobmanager jvm进程的堆内存大小,默认是1024M,这里设置成2048m,也就是2G
taskmanager.heap.size 这个是taskmanager jvm进程的堆内存大小,也就是实际运行任务的jvm最大所能占用的堆内存,默认也是1024m,这里设置成4g
taskmanager.numberOfTaskSlots 这个表示每个taskmanager所能提供的slots数量,也就是flink节点的计算能力,这个和算子的并行度配合使用,每个slot运行1个pipeline[source,transformation,slink],多个slot使得flink的subtasks是并行的,这个一般设置成和机器cpu核数一致,比如我们这里是3个taskmanager,每个taskmanager是4个slots,那么这个集群的slots个数为12.
parallelism.default 这个是默认任务的并行度,也就是说当代码中或者提交时没指定并行度,则按照这里的并行度执行任务,并行度是按照整个集群来算的,比如上面slots个数为12,那么支持subtasks最大的并行度就是12,因为在代码中通常会针对单个任务设置并行度,所以这里的默认并行度可以不设置.
上面这几项是flink独立集群最基本的配置,另外还有关于rest和web ui的配置,如果需要可以配置一下,我这里按照默认的配置:
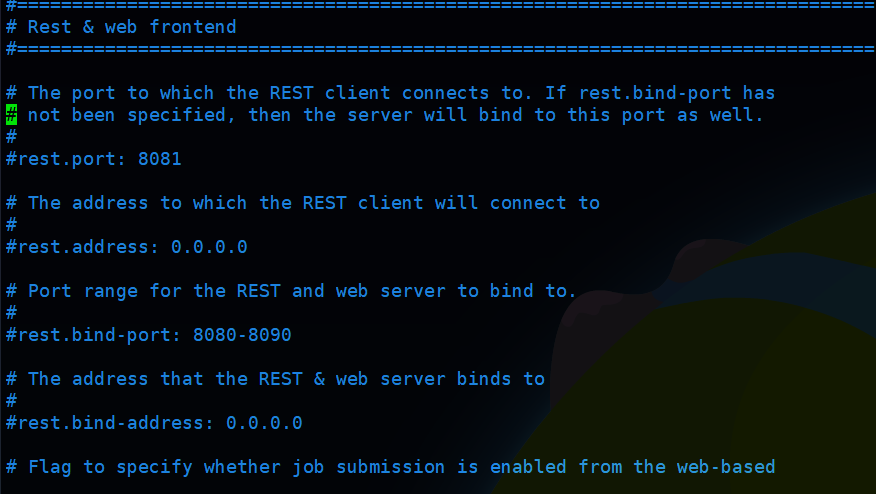

web ui和jobmanager同时运行,端口默认为8081,可以根据需要修改,另外还有个参数:web.submit.enable,也就是是否可以从界面提交任务,默认是开启的,取消注释就可以关闭.
确认上面配置无误之后,保存配置
然后配置masters和slaves的节点文件,
conf/masters,配置jobmanager的机器列表,这里独立集群非HA模式下配置为:bigdata1:8081
conf/slaves,配置taskmanager的机器列表,这里配置如下:
确认上面配置正常全部保存,接下来就可以从bigdata1将配置好的flink分发到其他3个节点:
scp -r /opt/flink-1.9.1 bigdata2:/opt
scp -r /opt/flink-1.9.1 bigdata3:/opt
scp -r /opt/flink-1.9.1 bigdata4:/opt
然后从任意1个节点可以启动集群,启动命令为: bin/start-cluster.sh 执行之后jobmanager和taskmanager就全部启动了,通过jps可以查看到相应的进程,jobmanager的进程为StandaloneSessionClusterEntrypoint,其余3个taskmanager的进程为TaskManagerRunner,然后可以访问浏览器界面查看web ui,这里是:http://bigdata1:8081
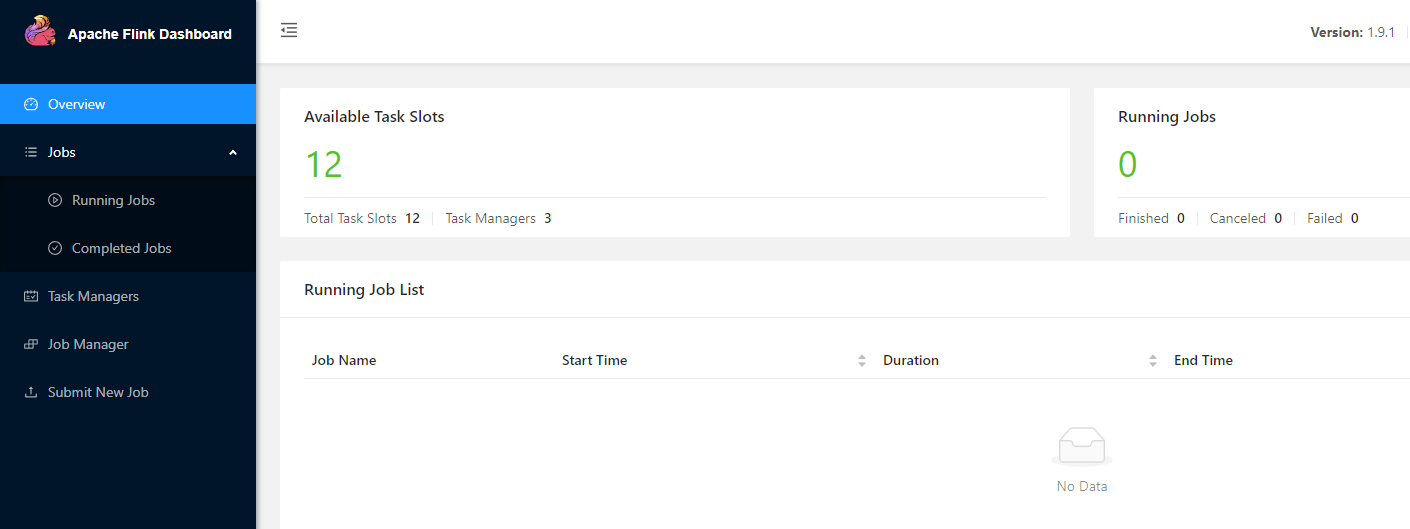
这样,flink standalone模式的集群就配置完成了
停止集群命令: bin/stop-cluster.sh 执行之后所有节点的进程都会停止
单个jobmanager的启动或停止: bin/jobmanager.sh start|start-foreground|stop|stop-all
单个taskmanager的启动或停止: bin/taskmanager.sh start|start-foreground|stop|stop-all
其中start-foreground是在前台启动,单独启动的命令一方面可以用在cluster启动或者停止失败的时候执行,另一方面可以用于flink集群运行时向其中加入节点,主要是运行时添加配置好的taskmanager节点,这样可以为集群动态扩容,添加之后稍微等一下,web界面就可以看到可用的slots和task managers数量发生变化了.
参考文档:https://ci.apache.org/projects/flink/flink-docs-release-1.9/zh/ops/deployment/cluster_setup.html
Flink Standalone集群部署的更多相关文章
- flink初识及安装flink standalone集群
flink architecture 1.可以看出,flink可以运行在本地,也可以类似spark一样on yarn或者standalone模式(与spark standalone也很相似),此外fl ...
- flink部署操作-flink standalone集群安装部署
flink集群安装部署 standalone集群模式 必须依赖 必须的软件 JAVA_HOME配置 flink安装 配置flink 启动flink 添加Jobmanager/taskmanager 实 ...
- Flink 集群搭建,Standalone,集群部署,HA高可用部署
基础环境 准备3台虚拟机 配置无密码登录 配置方法:https://ipooli.com/2020/04/linux_host/ 并且做好主机映射. 下载Flink https://www.apach ...
- spark standalone集群部署 实践记录
本文记录了一次搭建spark-standalone模式集群的过程,我准备了3个虚拟机服务器,三个centos系统的虚拟机. 环境准备: -每台上安装java1.8 -以及scala2.11.x (x代 ...
- Standalone 集群部署
Spark中调度其实是分为两个层级的,即集群层级的资源分配和任务调度,以及任务层级的任务管理.其中集群层级调度是可配置的,Spark目前提供了Local,Standalone,YARN,Mesos.任 ...
- Flink集群部署
部署方式 一般来讲有三种方式: Local Standalone Flink On Yarn/Mesos/K8s… 单机模式 参考上一篇Flink从入门到放弃(入门篇2)-本地环境搭建&构建第 ...
- Spark standalone安装(最小化集群部署)
Spark standalone安装-最小化集群部署(Spark官方建议使用Standalone模式) 集群规划: 主机 IP ...
- Scala进阶之路-Spark独立模式(Standalone)集群部署
Scala进阶之路-Spark独立模式(Standalone)集群部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我们知道Hadoop解决了大数据的存储和计算,存储使用HDFS ...
- zookeeper的单实例和伪集群部署
原文链接: http://gudaoyufu.com/?p=1395 zookeeper工作方式 ZooKeeper 是一个开源的分布式协调服务,由雅虎创建,是 Google Chubby 的开源实现 ...
- flink的集群的HA高可用
对于一个企业级的应用,稳定性是首要要考虑的问题,然后才是性能,因此 HA 机制是必不可少的: 和 Hadoop 一代一样,从架构中我们可以很明显的发现 JobManager 有明显的单点问题(SPOF ...
随机推荐
- RIPEMD算法:多功能哈希算法的瑰宝
一.RIPEMD算法的起源与历程 RIPEMD(RACE Integrity Primitives Evaluation Message Digest)算法是由欧洲研究项目RACE发起,由Hans D ...
- SyntaxError: invalid property id(就是不支持ES6) (浏览器不支持对象...展开)
SyntaxError: invalid property id(就是不支持ES6) (浏览器不支持对象...展开) 火狐55以后支持
- 如何在数据库中存储小数:FLOAT、DECIMAL还是BIGINT?
前言 这里还是用前面的例子: 在线机票订票系统的数据表设计.此时已经完成了大部分字段的设计,可能如下: CREATE TABLE flights ( flight_id INT AUTO_INCREM ...
- WEBRTC回声消除-AECM算法源码解析之参数解析
一 概述 webrtc 针对回声问题一共开源了3种回声消除算法,分别为aec,aecm,以及aec3,其中aec是最早期的版本,在后续的更新中aec3的出现代替了aec在webrtc 中的地位,而 ...
- linux shell 字体颜色设置
使用 echo -e "\033[0;32;40m" 可以将字体设置成绿色. 这里必须使用echo 的选项 "-e",因为后面需要用到转义序列. 转义序列就是一 ...
- Ubuntu 14.04 升级到Gnome3.12z的折腾之旅(警示后来者)+推荐Extensions.-------(二)
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文发布于 2014-12-22 15:33:35 ...
- dbvisivuser连oracle数据库报错没有权限
原因:数据库从11g升级为19c了 解决:ojdbc.jar也要换成最新的,导致报错的旧jar包2M大小,换成新jar包3M大小.替换jar包要将 dbvisivuser的tool driverMan ...
- 哈希表(HashTable)
哈希表 哈希表:也叫做散列表.是根据关键字和值(Key-Value)直接进行访问的数据结构.也就是说,它通过关键字 key 和一个映射函数 Hash(key) 计算出对应的值 value,然后把键值对 ...
- #欧拉序,线段树#洛谷 6845 [CEOI2019] Dynamic Diameter
题目 动态修改边权,强制在线询问树的直径. 分析 设 \(dis[x]\) 表示 \(x\) 到1号点的距离. 那么树的直径就可以表示成 \(dis[x]+dis[y]-2*dis[lca]\) 只需 ...
- 快捷转换/互转 Markdown 文档和 TypeScript/TypeDoc 注释
背景 作为文档工具人,经常需要把代码里面的注释转换成语义化的 Markdown 文档,有时也需要进行反向操作.以前是写正则表达式全局匹配,时间长了这种方式也变得繁琐乏味.所以写了脚本来互转,增加一些便 ...