ResNet-RS:谷歌领衔调优ResNet,性能全面超越EfficientNet系列 | 2021 arxiv
论文重新审视了ResNet的结构、训练方法以及缩放策略,提出了性能全面超越EfficientNet的ResNet-RS系列。从实验效果来看性能提升挺高的,值得参考
来源:晓飞的算法工程笔记 公众号
论文: Revisiting ResNets: Improved Training and Scaling Strategies

- 论文地址:https://arxiv.org/abs/2103.07579
- 论文代码:https://github.com/tensorflow/tpu/tree/master/models/official/resnet/resnet_rs
Introduction
视觉模型的准确率由结构、训练方式和缩放策略共同决定,新模型的实验通常使用了新的训练方法和超参数,不能直接和过时的训练方法得到的旧模型结果进行对比。为此,论文打算在ResNet上验证不同的训练方法和缩放策略的影响。
论文的主要贡献如下:
- 在不改变模型结构的前提下,通过实验验证正则化方法及其组合的作用,得到能提升性能的正则化策略。
- 提出简单、高效的缩放策略:1)如果实验配置可能出现过拟合(比如训练周期长),优先缩放深度,否则缩放宽度。2)更慢地缩放输入分辨率。
- 将上面的正则化策略和缩放策略实验结果应用到ResNet提出ResNet-RS,性能全面超越EfficientNet。
- 使用额外的130M伪标签图片对ResNet-RS进行半监督预训练,ImageNet上的性能达到86.2%,TPU上的训练速度快4.7倍。
- 将通过自监督获得的ResNet-RS模型,在不同的视觉任务上进行fine-tuned,性能持平或超越SimCLR和SimCLRv2。
- 将3D ResNet-RS应用到视频分类,性能比baseline高4.8%。
Characterizing Improvements on ImageNet
模型的提升可以粗略地分为四个方向:结构改进、训练/正则方法、缩放策略和使用额外的训练数据。
Architecture
新结构的研究最受关注,神经网络搜索的出现使得结构研究更进了一步。另外还有一些脱离经典卷积网络的结构,比如加入self-attention或其它替代方案,如lambda层。
Training and Regularization Methods
当模型需要训练更长时间时,正则方法(如dropout、label smoothing、stochastic depth、dropblock)和数据增强能有效地提升模型泛化能力,而更优的学习率调整方法也能提升模型最终的准确率。为了与之前的工作进行公平对比,一些研究仅简单地使用无正则的训练设置,这样显然不能体现研究的极致性能。
Scaling Strategies
提升模型的维度(宽度、深度和分辨率)也是提升准确率的有效方法。特别是在自然语言模型中,模型的规模对准确率有直接的影响,而在视觉模型中也同样有效。随着计算资源的增加,可以适当增加模型的维度。为了将此适配系统化,EfficentNet提出了混合缩放因子方法,用于缩放时平衡网络深度、宽度和分辨率之间的关系,但论文发现这个方法并不是最优的。
Additional Training Data
另一个有效提升性能的方法是使用额外的数据集进行预训练。在大规模数据集下预训练的模型,能够在ImageNet上达到很好的性能。需要注意的是,这里并非必须要标注好的数据集,使用伪标签的半监督训练,同样也能达到很好的性能。
Methodology
Architecture
在结构上,ResNet-RS仅采用了ResNet-D加SENet的改进,这些改进在当前的模型中经常被采用。
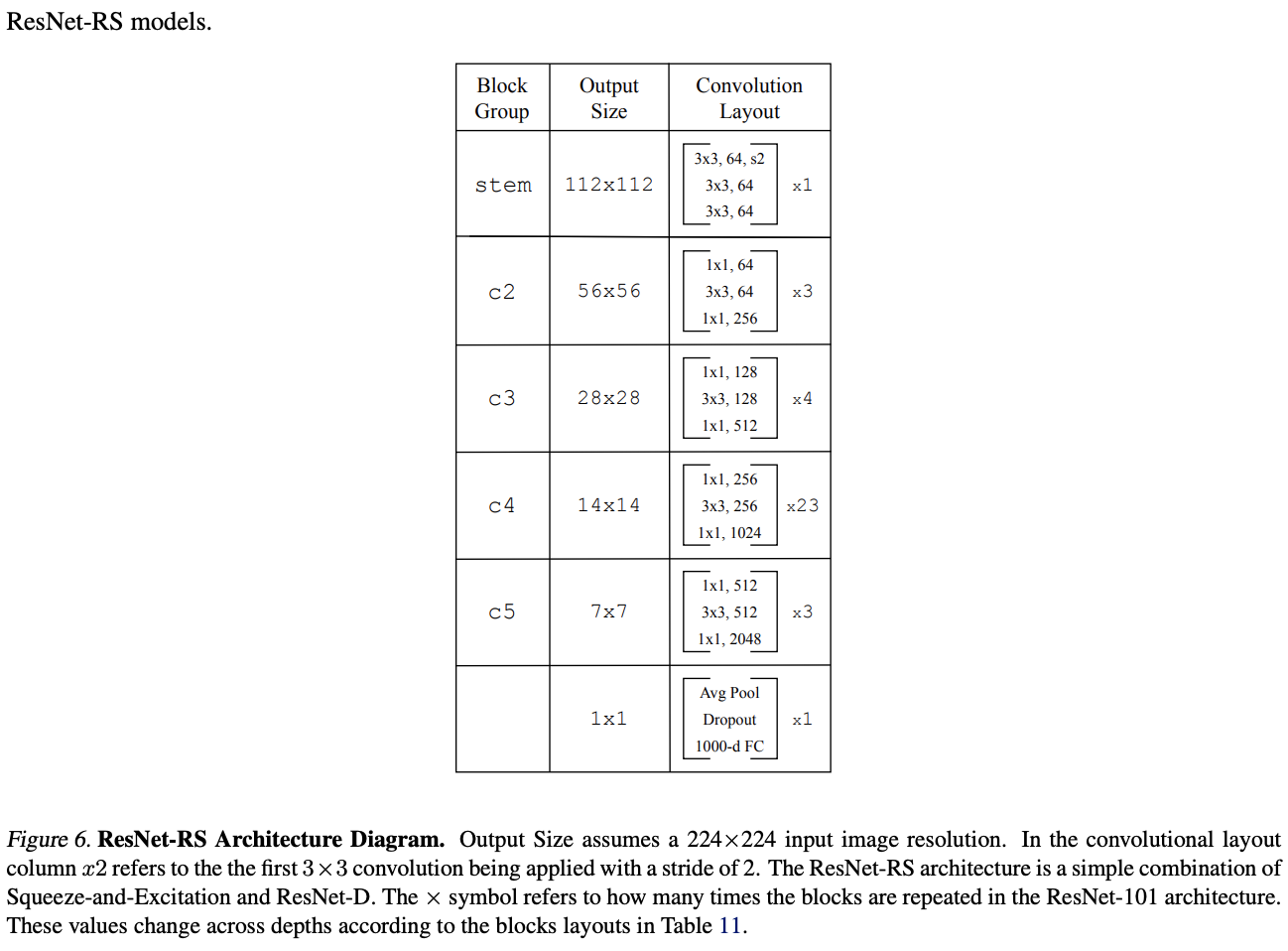
ResNet-D
对原生的ResNet进行了四处改进:1)将stem的\(7\times 7\)卷积替换为3个\(3\times 3\)卷积。2)交换下采样模块的residual路径的头两个卷积的stride配置。3)将下采样模块的skip路径中的stride-2 \(1\times 1\)卷积替换为stride-2 \(2\times 2\)平均池化和non-strided \(1\times 1\)卷积。4)去掉stem中的stride-2 \(3\times 3\)最大池化层,在下个bottleneck的首个\(3\times 3\)卷积中进行下采样。
Squeeze-and-Excitation
SE模块通过跨通道计算获得的各通道的权值,然后对通道进行加权。设置ratio=0.25,在每个bottleneck中都加入。
Training Method
研究当前SOTA分类模型中使用的正则化和数据增强方法,以及半监督/自监督学习。
Matching the EfficientNet Setup
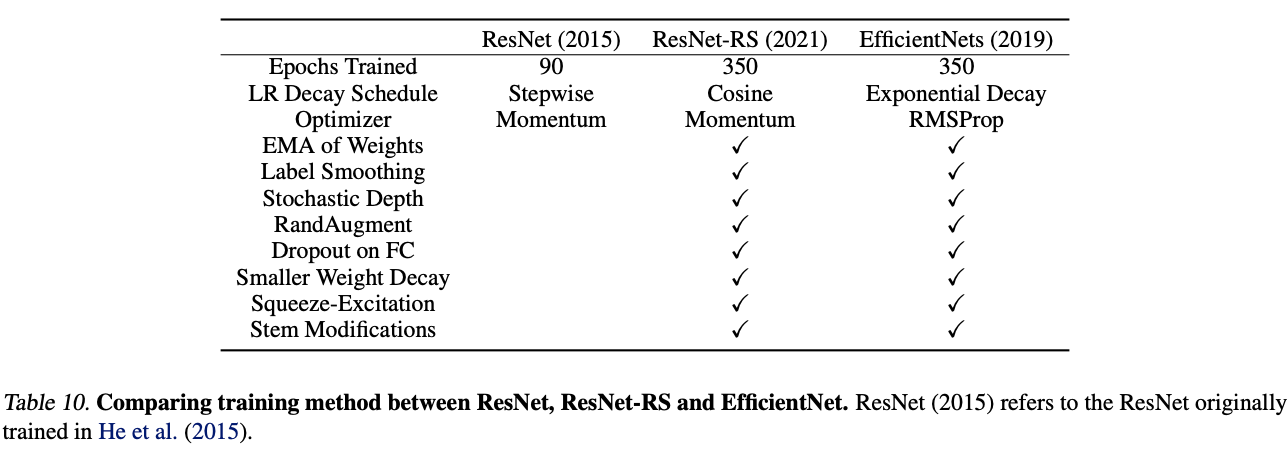
训练方法与EfficientNet类似,共训练350轮,有以下细微的差异:1)使用cosine学习率调整方法。2)使用RandAugment增强数据。EfficientNet最初使用AutoAugment增强数据,使用RandAugment结果变化不大。3)为了简便,使用Momentum优化器而不是RMSProp优化器。
Regularization
使用weight decay,label smoothing,dropout和stochastic depth进行正则化。
Data Augmentation
使用RandAugment数据增强作为额外的正则化器,对每张图片使用一系列随机增强方法。
Hyperparameter Tuning
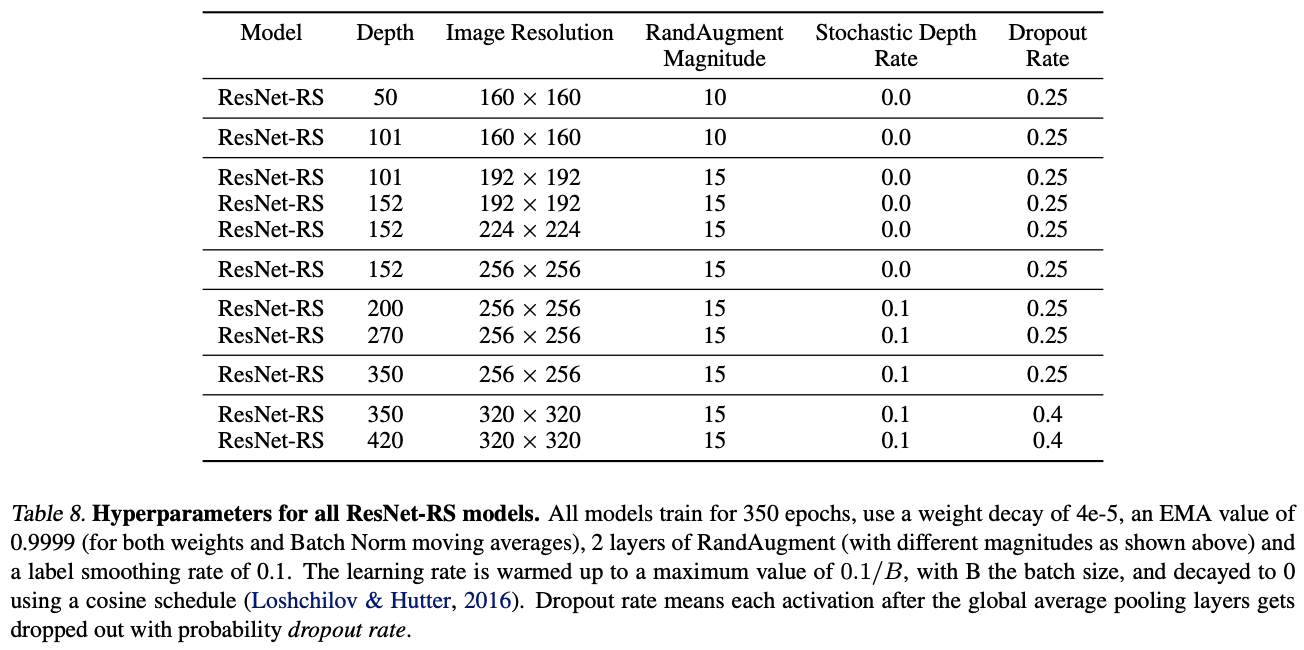
为了快速选择适合不同正则方法和训练方法的超参数,使用包含ImageNet的2%(1024分片取20分片)数据构成minival-set,而原本的ImageNet验证集作为validation-set。
Improved Training Methods
Additive Study of Improvements
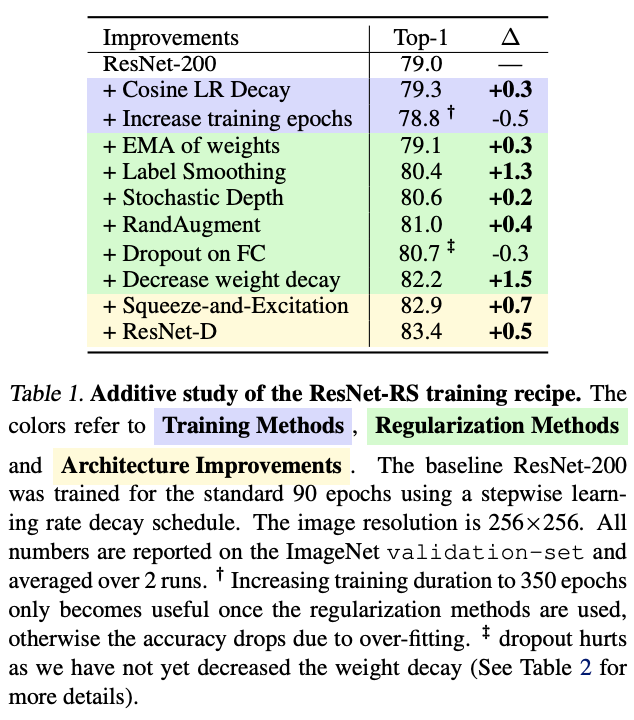
论文对各训练方法、正则化方法、结构优化进行了叠加实验,结果如表2所示,训练方法和正则化方法带来的提升大约占3/4的总精度提升。
Importance of decreasing weight decay when combining regularization methods
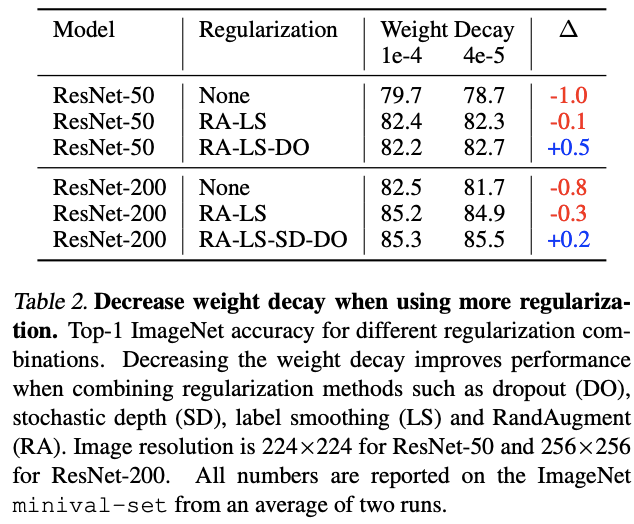
论文在使用RandAugment和label smoothing时,没有改变默认的weight decay设置,性能有提升。但在加入dropout或stochastic depth后,性能出现了下降,最后通过降低weight decay来恢复。weight decay用于正则化参数,在搭配其它正则化处理时,需要降低其值避免过度正则化。
Improved Scaling Strategies
为了探索模型缩放的逻辑,预设宽度比例[0.25, 0.5, 1.0, 1.5, 2.0]、深度比例[26, 50, 101, 200, 300, 350, 400]以及分辨率[128, 160, 224, 320, 448],组合不同的比例进行模型性能的实验。每个组合训练350周期,训练配置与SOTA模型一致,在模型大小增加时,相应地加强正则化的力度。
主要有以下发现:
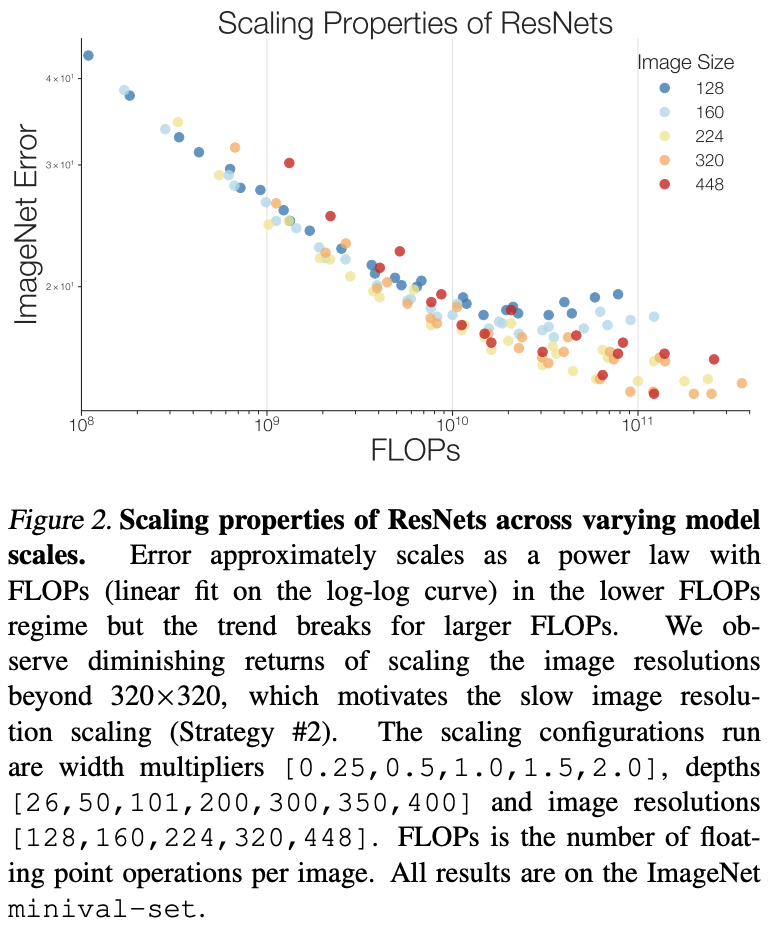
- FLOPs do not accurately predict performance in the bounded data regime。在模型较小时,模型性能跟模型大小成正相关关系,但当模型变得越大后,这种关系就变得越不明显了,转而跟缩放策略有关。使用不同缩放策略将模型缩放到相同大小,模型越大,性能差异越大。
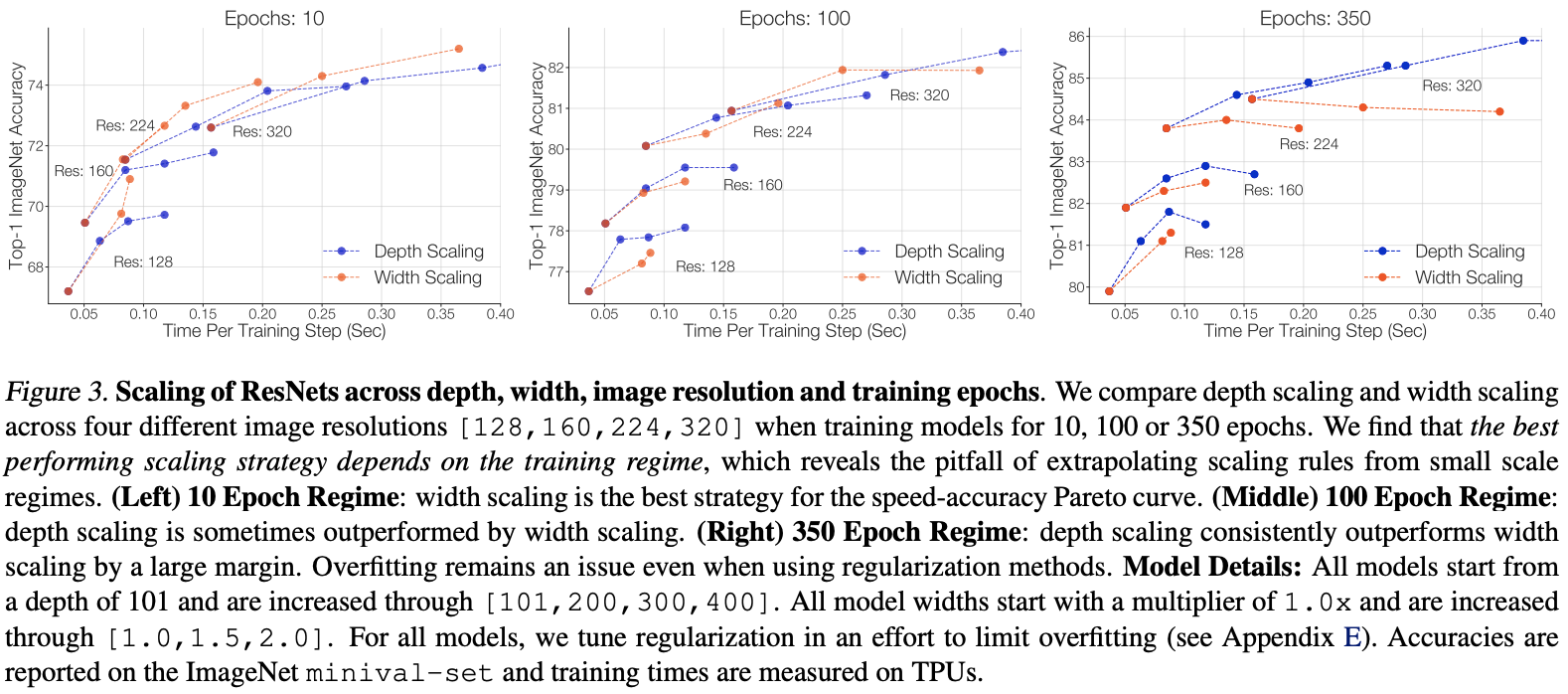
- The best performing scaling strategy depends on the training regime。不同训练周期下,不同缩放版本的性能曲线差异较大,因此缩放策略的最好性能跟实验的设置有很大关系。
Strategy #1 - Depth Scaling in Regimes Where Overfitting Can Occur
Depth scaling outperforms width scaling for longer epoch regimes。从图3右可以看出,在350周期的训练配置下,深度缩放在任意输入分辨率下都要比宽度缩放更有效。宽度缩放对过拟合是次优的,甚至有时会导致性能损失,这可能由于宽度缩放引入了过多参数,而深度缩放仅引入少量参数。
Width scaling outperforms depth scaling for shorter epoch regimes,从图3左可以看出,在10周期的训练配置下,宽度缩放更优。而从图3中可以看出,在100周期的训练配置下,搭配不同的输入分辨率,深度缩放和宽度缩放的性能各有差异。
Strategy #2 - Slow Image Resolution Scaling
从图2可以看出,输入分辨率越大,可带来的收益增加越少,也就是性价比越低。因此,在输入分辨率缩放上,论文采取最低优先级,从而更好地折中速度和准确率。
Two Common Pitfalls in Designing Scaling Strategies
在分析缩放策略时,论文发现了两个常见的错误做法:
- Extrapolating scaling strategies from small-scale regimes,从小尺寸的实验设置进行研究。以往的搜索策略通常使用小模型或较短的训练周期进行研究,这种场景最优的缩放策略不一定能迁移到大模型和较长周期下的训练。因此,论文不推荐在这种场景下花费大力气进行缩放策略实验。
- Extrapolating scaling strategies from a single and potentially sub-optimal initial architecture,从次优的初始结构进行缩放会影响缩放的结果。比如EfficientNet的混合缩放固定了计算量和分辨率进行搜索,然而分辨率也是影响准确率的一个影响因素。因此,论文综合宽度、深度和分辨率进行缩放策略研究。
Summary of Improved Scaling Strategies
对于新任务,论文建议先使用小点的训练子集,对不同尺寸的配置进行完整周期训练测试,找到对准确率影响较大的缩放维度。对于图片分类,缩放策略主要有以下两点:
- 如果实验配置可能出现过拟合(比如训练周期长),优先缩放深度,否则缩放宽度。
- 缓慢地缩放输入分辨率。
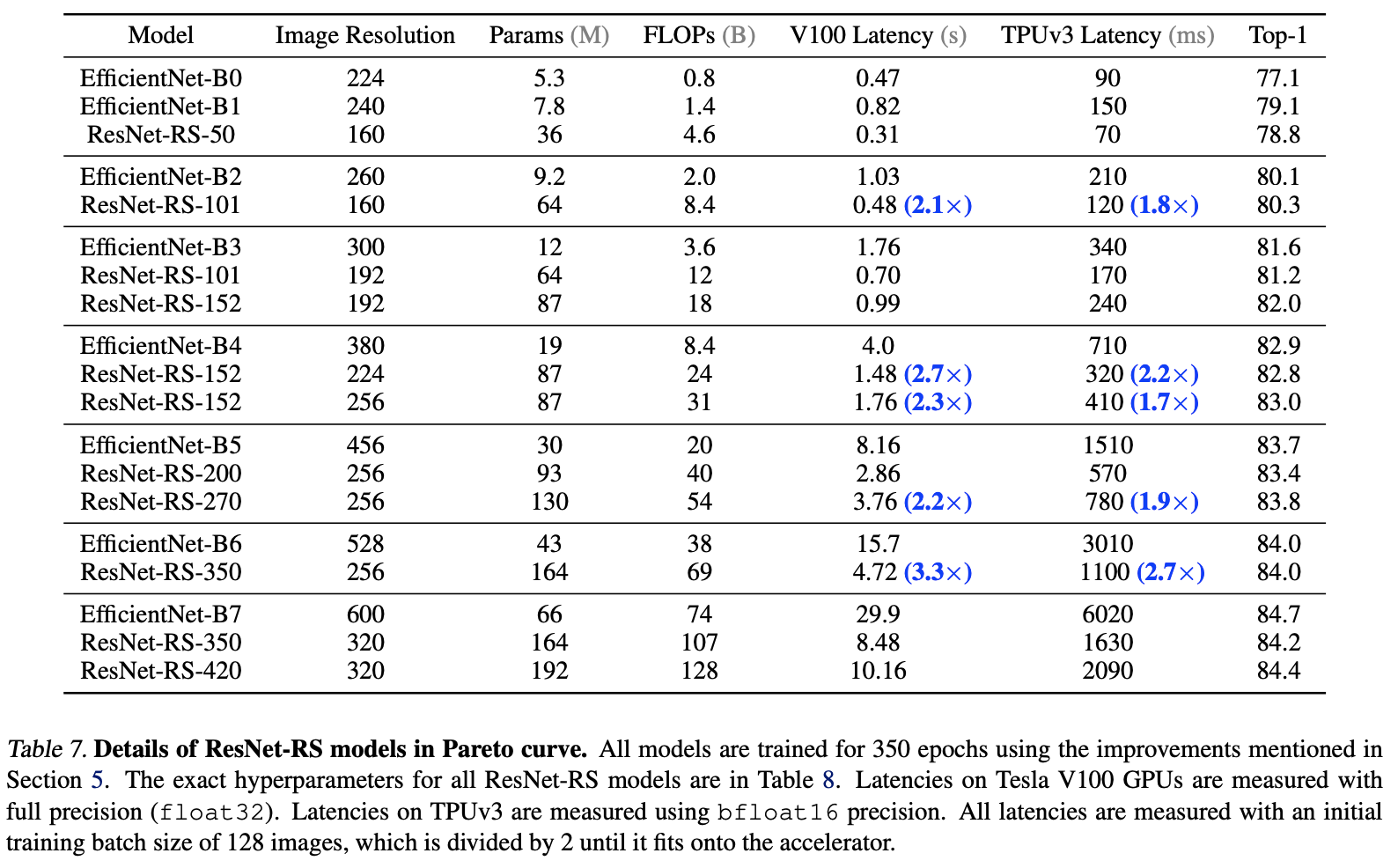
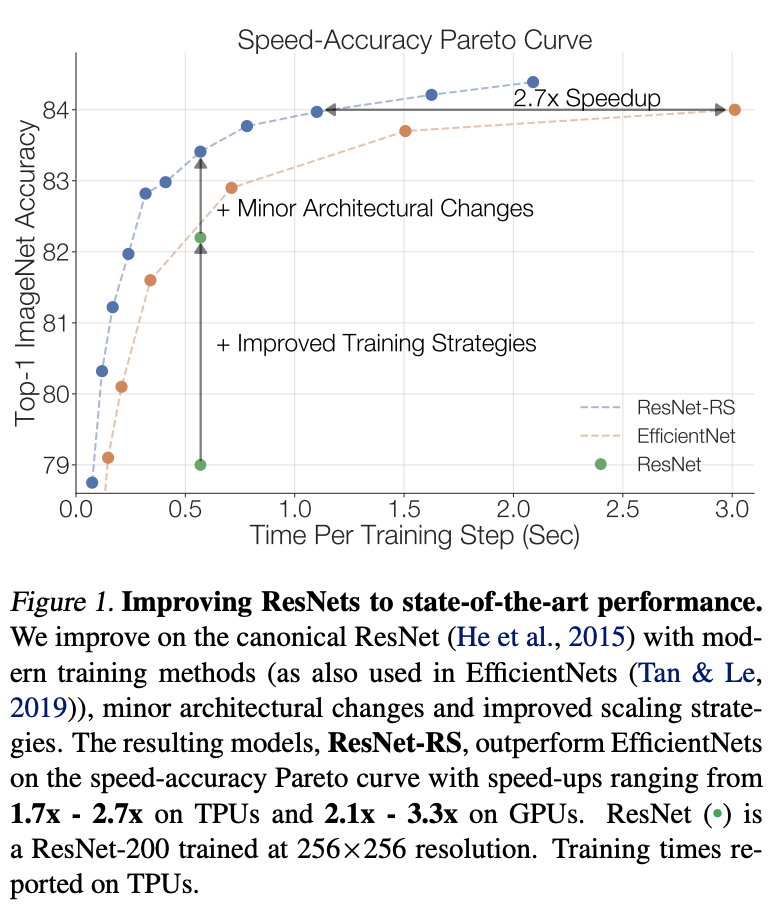
论文最终搜索得到的ResNet-RS系列的配置如表7所示,在准确率匹配EfficientNet的前提下,TPU上的计算速度快1.7~2.7倍。需要说明的是,虽然ResNet-RS的计算量和参数量普遍比EfficientNet高,但ResNet-RS的实际计算速度和内存使用都更优秀,说明计算量和参数量并不能直接代表速度大小和内存占用。
Experiment
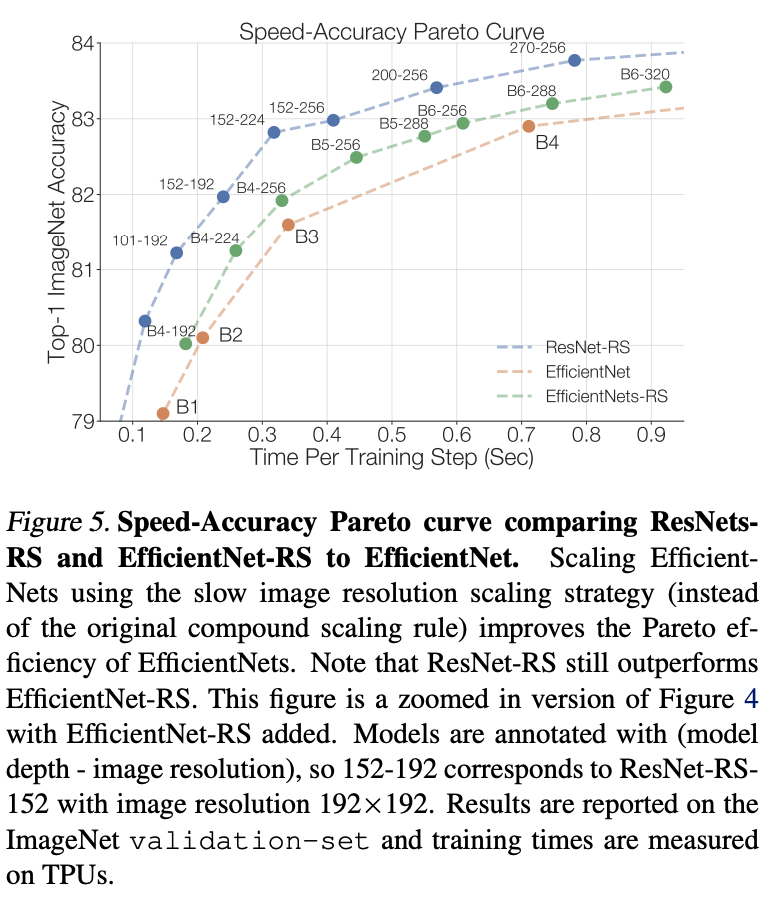
对EfficentNet进行优化后对比。
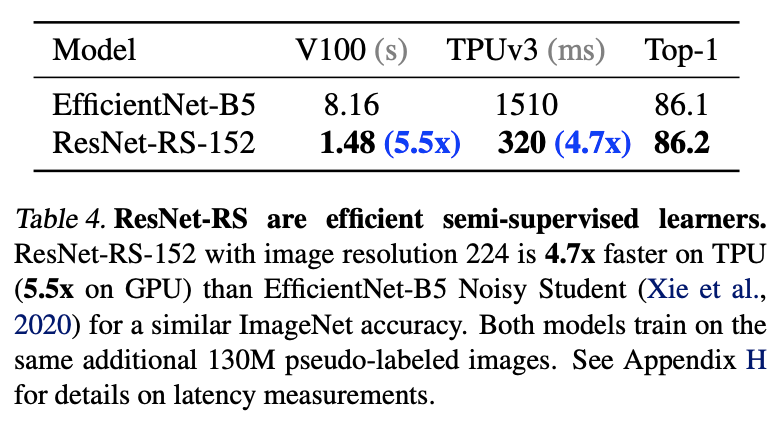
半监督效果对比。
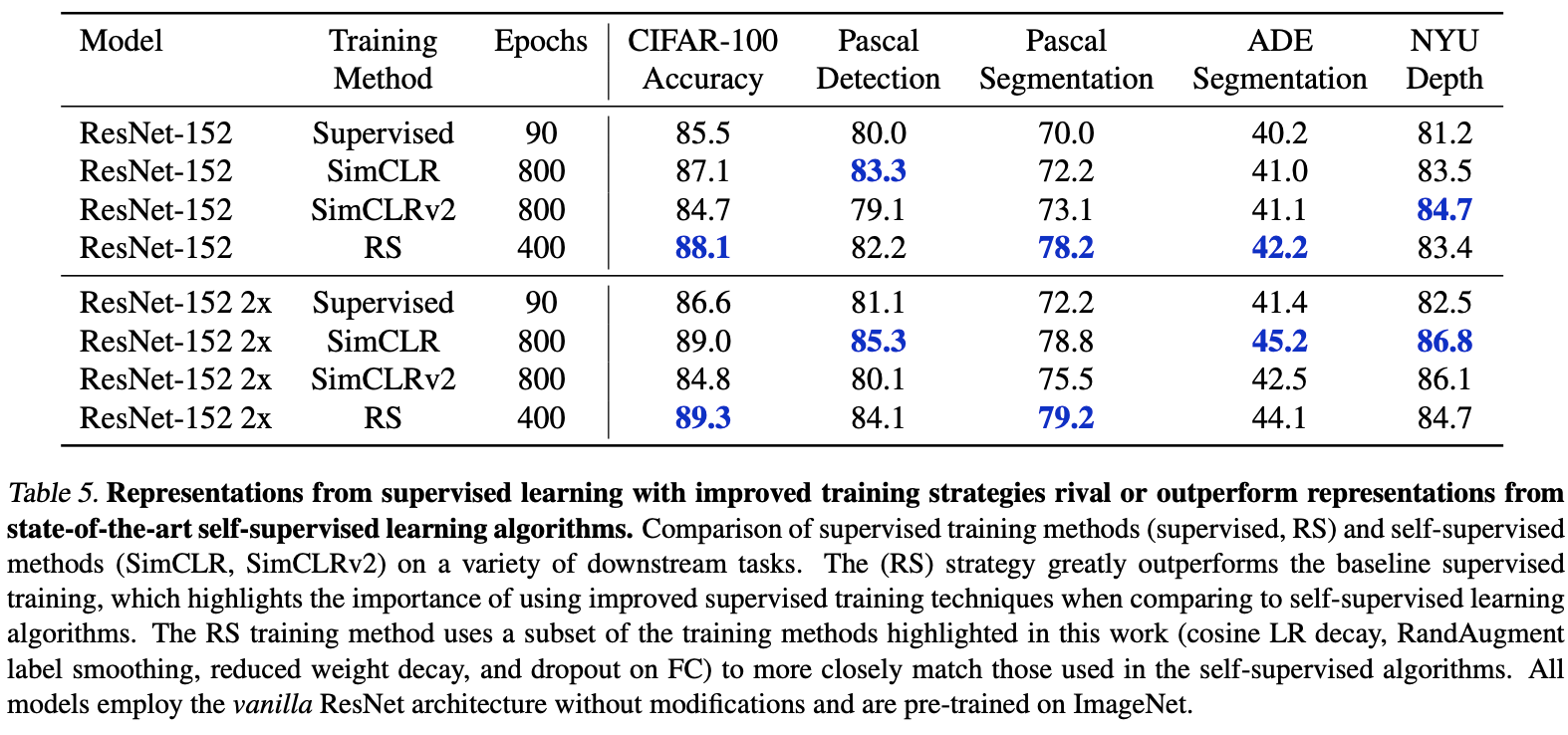
自监督在不同任务上的效果对比。
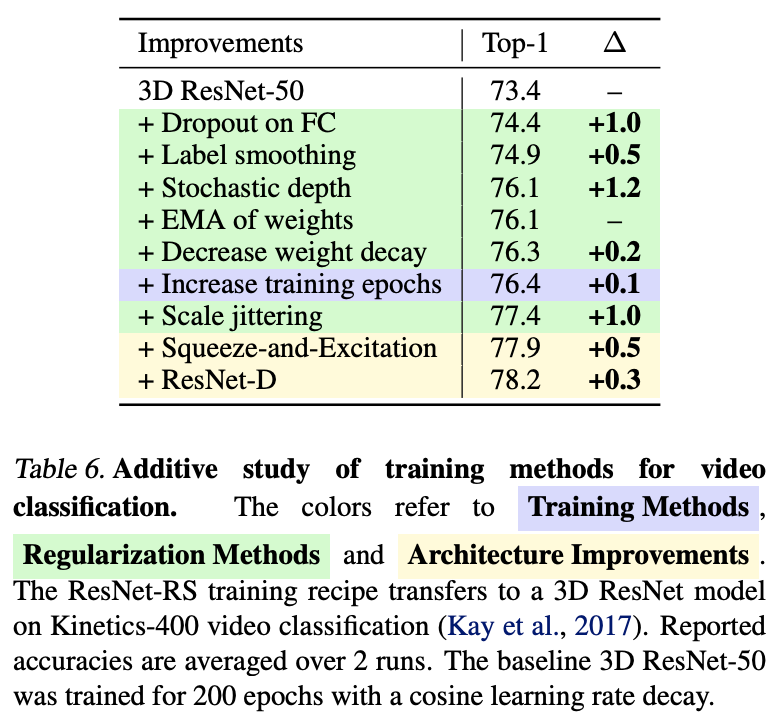
视频分类的对比实验。
Conclusion
论文重新审视了ResNet的结构、训练方法以及缩放策略,提出了性能全面超越EfficientNet的ResNet-RS系列。从实验效果来看性能提升挺高的,值得参考。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

ResNet-RS:谷歌领衔调优ResNet,性能全面超越EfficientNet系列 | 2021 arxiv的更多相关文章
- 二十种实战调优MySQL性能优化的经验
二十种实战调优MySQL性能优化的经验 发布时间:2012 年 2 月 15 日 发布者: OurMySQL 来源:web大本营 才被阅读:3,354 次 消灭0评论 本文将为大家介 ...
- Spark调优_性能调优(一)
总结一下spark的调优方案--性能调优: 一.调节并行度 1.性能上的调优主要注重一下几点: Excutor的数量 每个Excutor所分配的CPU的数量 每个Excutor所能分配的内存量 Dri ...
- Mysql数据库调优和性能优化的21条最佳实践
Mysql数据库调优和性能优化的21条最佳实践 1. 简介 在Web应用程序体系架构中,数据持久层(通常是一个关系数据库)是关键的核心部分,它对系统的性能有非常重要的影响.MySQL是目前使用最多的开 ...
- Java生鲜电商平台-API请求性能调优与性能监控
Java生鲜电商平台-API请求性能调优与性能监控 背景 在做性能分析时,API的执行时间是一个显著的指标,这里使用SpringBoot AOP的方式,通过对接口添加简单注解的方式来打印API的执行时 ...
- Spark调优,性能优化
Spark调优,性能优化 1.使用reduceByKey/aggregateByKey替代groupByKey 2.使用mapPartitions替代普通map 3.使用foreachPartitio ...
- Mysql数据库调优和性能优化
1. 简介 在Web应用程序体系架构中,数据持久层(通常是一个关系数据库)是关键的核心部分,它对系统的性能有非常重要的影响.MySQL是目前使用最多的开源数据库,但是mysql数据库的默认设置性能非常 ...
- EMQ X 系统调优和性能压测
前言 如果使用 EMQ 来承载百万级别的用户连接可以吗?毕竟在 MQTT 官方介绍上说 EMQ X 可以处理千万并发客户端,而 EMQ X 自己官方称 4.x 版本 MQTT 连接压力测试一台 8 核 ...
- jvm系列(五):tomcat性能调优和性能监控(visualvm)
tomcat服务器优化 1.JDK内存优化 根据服务器物理内容情况配置相关参数优化tomcat性能.当应用程序需要的内存超出堆的最大值时虚拟机就会提示内存溢出,并且导致应用服务崩溃.因此一般建议堆的最 ...
- Linux系统性能调优之性能分析
1.Linux性能分析的目的1)找出系统性能瓶颈(包括硬件瓶颈和软件瓶颈):2)提供性能优化的方案(升级硬件?改进系统系统结构?):3)达到合理的硬件和软件配置:4)使系统资源使用达到最大的平衡.(一 ...
- 二十种实战调优MySQL性能优化的经验
http://www.searchdatabase.com.cn/showcontent_58391.htm [为查询缓存优化你的查询] 像 NOW() 和 RAND() 或是其它的诸如此类的S ...
随机推荐
- [Android 逆向]绕过小米需插卡安装apk限制
1. 确保自己手机是root的了 2. 给手机安装busybox,使可以用vi编辑文件 安装方法: 0. adb shell getprop ro.product.cpu.abi 获得 cpu架构信息 ...
- Windows如何快速修改hosts文件
作为开发人员,修改hosts文件可能是一个经常会执行的操作(使用自定义域名映射),但是如果每次都需要在Windows资源管理中进入到目录:C:\Windows\System32\drivers\etc ...
- extra用法
做子查询时,有些orm语句满足不了的时候使用 select参数 ## select age,(age > 18) as is_adult from myapp_person; Person.ob ...
- 【Azure 应用服务】本地Git部署Java项目到App Server,访问无效的原因
问题描述 在App Server的部署中心配置好本地Git 仓库 并推送 git push azure master 分支代码到服务器时,并未发生错误 ,但是服务异常,无法访问到正确的项目文件,始终打 ...
- 【Azure Developer】PHP网站使用AAD授权登录的参考示例
问题描述 如果有个PHP网站,需要使用AAD授权登录,有没有PHP代码实例 可供参考呢? 参考代码 参考一篇博文(Single sign-on with Azure AD in PHP),学习使用SS ...
- 使用debezium实现cdc实时数据同步功能记录
Debezium 是一个用于变更数据捕获的开源分布式平台.能够保证应用程序就可以开始响应其他应用程序提交到您数据库的所有插入.更新和删除操作.Debezium 持久.快速,因此即使出现问题,您的应用程 ...
- 使用OpenTelemetry进行监控
工具介绍 注意:该部分介绍摘抄自:https://www.aiwanyun.cn/archives/174 Prometheus.Grafana.Node Exporter 和Alertmanager ...
- Java 多态 案列
1 package com.bytezreo.duotai; 2 3 //多态性的使用 举例一 4 public class AnimalTest 5 { 6 public static void m ...
- java中StringBuffer与 StringBuilder 类
目录 创建 StringBuffer 类 追加字符串 替换字符 反转字符串 删除字符串 StringBuffer 方法 在 Java 中,除了通过 String 类创建和处理字符串之外,还可以使用 S ...
- java.util.Arrays 快速学习教程
在 Java 中,java.util.Arrays类提供的多种数组操作功能,可以有效地执行各种数组相关的操作,使得数组处理变得简单和高效. 打印数组 String[] arr = new String ...