【转载】 深入理解TensorFlow中的tf.metrics算子
原文地址:
https://mp.weixin.qq.com/s/8I5Nvw4t2jT1NR9vIYT5XA

=================================================================================
1. 概述
本文将深入介绍Tensorflow内置的评估指标算子,以避免出现令人头疼的问题。
tf.metrics.accuracy()tf.metrics.precision()tf.metrics.recall()tf.metrics.mean_iou()
简单起见,本文在示例中使用tf.metrics.accuracy(),但它的模式以及它背后的原理将适用于所有评估指标。如果您只想看到有关如何使用tf.metrics的示例代码,请跳转到5.1和5.2节,如果您想要了解为何使用这种方式,请继续阅读。
这篇文章将通过一个非常简单的代码示例来理解 tf.metrics 的原理,这里使用Numpy创建自己的评估指标。
这将有助于对Tensorflow中的评估指标如何工作有一个很好的直觉认识。然后,我们将给出如何采用 tf.metrics 快速实现同样的功能。但首先,我先讲述一下写下这篇博客的由来。
2. 背景
这篇文章的由来是来自于我尝试使用tf.metrics.mean_iou评估指标进行图像分割,但却获得完全奇怪和不正确的结果。我花了一天半的时间来弄清楚我哪里出错了。你会发现,自己可能会非常容易错误地使用tf的评估指标。截至2017年9月11日,tensorflow文档并没有非常清楚地介绍如何正确使用Tensorflow的评估指标。
因此,这篇文章旨在帮助其他人避免同样的错误,并且深入理解其背后的原理,以便了解如何正确地使用它们。
3. 生成数据
在我们开始使用任何评估指标之前,让我们先从简单的数据开始。我们将使用以下Numpy数组作为我们预测的标签和真实标签。数组的每一行视为一个batch,因此这个例子中共有4个batch。
import numpy as np
labels = np.array([[1,1,1,0],
[1,1,1,0],
[1,1,1,0],
[1,1,1,0]], dtype=np.uint8)
predictions = np.array([[1,0,0,0],
[1,1,0,0],
[1,1,1,0],
[0,1,1,1]], dtype=np.uint8)
n_batches = len(labels)
4. 建立评价指标
为了简单起见,这里采用的评估指标是准确度(accuracy):
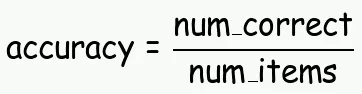
如果我们想计算整个数据集上的 accuracy , 可以这样计算:
n_items = labels.size
accuracy = (labels == predictions).sum() / n_items
print("Accuracy :", accuracy)
[OUTPUT]
Accuracy : 0.6875
这种方法的问题在于它不能扩展到大型数据集,这些数据集太大而无法一次性加载到内存。为了使其可扩展,我们希望使评估指标能够逐步更新,每次更新一个batch中预测值和标签。为此,我们需要跟踪两个值:
正确预测的例子总和
目前所有例子的总数
在Python中,我们创建两个全局变量:
# Initialize running variables
N_CORRECT = 0
N_ITEMS_SEEN = 0
每次新来一个batch,我们将这个batch中的预测情况更新到这两个变量中:
# Update running variables
N_CORRECT += (batch_labels == batch_predictions).sum()
N_ITEMS_SEEN += batch_labels.size
而且,我们可以实时地计算每个点处的accuracy:
# Calculate accuracy on updated values
acc = float(N_CORRECT) / N_ITEMS_SEEN
合并前面的功能,我们创建如下的代码:
# Create running variables
N_CORRECT = 0
N_ITEMS_SEEN = 0
def reset_running_variables():
""" Resets the previous values of running variables to zero """
global N_CORRECT, N_ITEMS_SEEN
N_CORRECT = 0
N_ITEMS_SEEN = 0
def update_running_variables(labs, preds):
global N_CORRECT, N_ITEMS_SEEN
N_CORRECT += (labs == preds).sum()
N_ITEMS_SEEN += labs.size
def calculate_accuracy():
global N_CORRECT, N_ITEMS_SEEN
return float(N_CORRECT) / N_ITEMS_SEEN
4.1 整体accuracy
使用上面的函数,当我们便利完所有的batch之后,可以计算出整体accuracy:
reset_running_variables()
for i in range(n_batches):
update_running_variables(labs=labels[i], preds=predictions[i])
accuracy = calculate_accuracy()
print("[NP] SCORE: ", accuracy)
[OUTPUT]
[NP] SCORE: 0.6875
4.2 每个batch的accuracy
但是,如果我们想要计算每个batch的accuracy,那就要重新组织我们的代码了。每次更新全局变量之前,你需要先重置它们(归为0):
for i in range(n_batches):
reset_running_variables()
update_running_variables(labs=labels[i], preds=predictions[i])
acc = calculate_accuracy()
print("- [NP] batch {} score: {}".format(i, acc))
[OUTPUT]
- [NP] batch 0 score: 0.5
- [NP] batch 1 score: 0.75
- [NP] batch 2 score: 1.0
- [NP] batch 3 score: 0.5
5. Tensorflow中的metrics
在第4节中我们将计算评估指标的操作拆分为不同函数,这其实与Tensorflow中tf.metrics背后原理是一样的。当我们调用tf.metrics.accuracy函数时,类似的事情会发生:
会同样地创建两个变量(变量会加入tf.GraphKeys.LOCAL_VARIABLES集合中),并将其放入幕后的计算图中:
total(相当于N_CORRECT)
count(相当于N_ITEMS_SEEN)
返回两个tensorflow操作。
accuracy(相当于calculate_accuracy())
update_op(相当于update_running_variables())
为了初始化和重置变量,比如第4节中的reset_running_variables函数,我们首先需要获得这些变量(total和count)。你可以在第一次调用时为tf.metrics.accuracy函数显式指定一个名称,比如:
tf.metrics.accuracy(label, prediction, name="my_metric")然后就可以根据作用范围找到隐式创建的2个变量:
# Isolate the variables stored behind the scenes by the metric operation
running_vars = tf.get_collection(tf.GraphKeys.LOCAL_VARIABLES, scope="my_metric")
<tf.Variable 'my_metric/total:0' shape=() dtype=float32_ref>,
<tf.Variable 'my_metric/count:0' shape=() dtype=float32_ref>
接下了我们可以创建一个初始化操作,以可以初始化或者重置两个变量:
running_vars_initializer = tf.variables_initializer(var_list=running_vars)
当你需要初始化或者重置变量时,只需要在session中运行一下即可:
session.run(running_vars_initializer)注意:除了手动分离变量,然后创建初始化op,在TF中更常用的是下面的操作:
session.run(tf.local_variables_initializer())
所以,有时候你看到上面的操作不要大惊小怪,其实只是初始化了在tf.GraphKeys.LOCAL_VARIABLES集合中的变量,但是这样做把所以变量都初始化了,使用时要特别注意。
知道上面的东西,我们很容易计算整体accuracy和batch中的accuracy。
5.1 计算整体accuracy
在TF中要计算整体accuracy,只需要如此:
import tensorflow as tf
graph = tf.Graph()
with graph.as_default():
# Placeholders to take in batches onf data
tf_label = tf.placeholder(dtype=tf.int32, shape=[None])
tf_prediction = tf.placeholder(dtype=tf.int32, shape=[None])
# Define the metric and update operations
tf_metric, tf_metric_update = tf.metrics.accuracy(tf_label,
tf_prediction,
name="my_metric")
# Isolate the variables stored behind the scenes by the metric operation
running_vars = tf.get_collection(tf.GraphKeys.LOCAL_VARIABLES, scope="my_metric")
# Define initializer to initialize/reset running variables
running_vars_initializer = tf.variables_initializer(var_list=running_vars)
with tf.Session(graph=graph) as session:
session.run(tf.global_variables_initializer())
# initialize/reset the running variables
session.run(running_vars_initializer)
for i in range(n_batches):
# Update the running variables on new batch of samples
feed_dict={tf_label: labels[i], tf_prediction: predictions[i]}
session.run(tf_metric_update, feed_dict=feed_dict)
# Calculate the score
score = session.run(tf_metric)
print("[TF] SCORE: ", score)
[OUTPUT]
[TF] SCORE: 0.6875
5.2 计算每个batch的accuracy
为了分别计算各个batch的准确度,在每批新数据之前将变量重置为零:
with tf.Session(graph=graph) as session:
session.run(tf.global_variables_initializer())
for i in range(n_batches):
# Reset the running variables
session.run(running_vars_initializer)
# Update the running variables on new batch of samples
feed_dict={tf_label: labels[i], tf_prediction: predictions[i]}
session.run(tf_metric_update, feed_dict=feed_dict)
# Calculate the score on this batch
score = session.run(tf_metric)
print("[TF] batch {} score: {}".format(i, score)) [OUTPUT]
[TF] batch 0 score: 0.5
[TF] batch 1 score: 0.75
[TF] batch 2 score: 1.0
[TF] batch 3 score: 0.5
注意:如果每个batch计算之前不重置变量的话,其实计算的就是累积accuracy,也就是目前所有已经运行数据的accuracy。
5.3 要避免的问题
不要在相同的session.run()中同时运行tf_metrics和tf_metric_update,比如这样:
_ , score = session.run([tf_metric_update, tf_metric], feed_dict=feed_dict)
score, _ = session.run([tf_metric, tf_metric_update], feed_dict=feed_dict)
在Tensorflow 1.3 (或许其它版本)中,这可能得到不一致的结果。这返回的两个op,只有update_op才是真正负责更新变量,而第一个op只是简单根据当前变量计算评价指标,所以你应该先执行update_op,然后再用第一个op计算指标。需要注意的,update_op执行后一个作用是更新变量,另外会同时返回一个结果,对于tf.metric.accuracy,就是更新变量后实时计算的accuracy。
6. 其它metrics
tf.metrics中的其他评估指标将以相同的方式工作。它们之间的唯一区别可能是调用tf.metrics函数时需要额外参数。例如,tf.metrics.mean_iou需要额外的参数num_classes来表示预测的类别数。另一个区别是背后所创建的变量,如tf.metrics.mean_iou创建的是一个混淆矩阵,但仍然可以按照我在本文第5部分中描述的方式收集和初始化它们。
7. 结语
对于TF中所有metric,其都是返回两个op,一个是计算评价指标的op,另外一个是更新op,这个op才是真正其更新作用的。我想之所以TF会采用这种方式,是因为metric所服务的其实是评估模型的时候,此时你需要收集整个数据集上的预测结果,然后计算整体指标,而TF的metric这种设计恰好满足这种需求。但是在训练模型时使用它们,就是理解它的原理,才可以得到正确的结果。
注:原文略有删改
【转载】 深入理解TensorFlow中的tf.metrics算子的更多相关文章
- Tensorflow中的tf.argmax()函数
转载请注明出处:http://www.cnblogs.com/willnote/p/6758953.html 官方API定义 tf.argmax(input, axis=None, name=None ...
- tensorflow中使用tf.variable_scope和tf.get_variable的ValueError
ValueError: Variable conv1/weights1 already exists, disallowed. Did you mean to set reuse=True in Va ...
- 转载 深入理解JavaScript中的this关键字
转载原地址: http://www.cnblogs.com/rainman/archive/2009/05/03/1448392.html 深入理解JavaScript中的this关键字 1. 一 ...
- TensorFlow 中的 tf.train.exponential_decay() 指数衰减法
exponential_decay(learning_rate, global_step, decay_steps, decay_rate, staircase=False, name=None) 使 ...
- TensorFlow中使用tf.keras.callbacks.EarlyStopping防止训练过拟合
TensorFlow tf.keras.callbacks.EarlyStopping 当模型训练次数epoch设置到100甚至更大时,如果模型的效果没有进一步提升,那么训练可以提前停止,继续训练很可 ...
- [转载]tensorflow中使用tf.ConfigProto()配置Session运行参数&&GPU设备指定
tf.ConfigProto()函数用在创建session的时候,用来对session进行参数配置: config = tf.ConfigProto(allow_soft_placement=True ...
- tf.Session()函数的参数应用(tensorflow中使用tf.ConfigProto()配置Session运行参数&&GPU设备指定)
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/dcrmg/article/details ...
- tensorflow中共享变量 tf.get_variable 和命名空间 tf.variable_scope
tensorflow中有很多需要变量共享的场合,比如在多个GPU上训练网络时网络参数和训练数据就需要共享. tf通过 tf.get_variable() 可以建立或者获取一个共享的变量. tf.get ...
- tensorflow中使用tf.ConfigProto()配置Session运行参数&&GPU设备指定
tf.ConfigProto()函数用在创建session的时候,用来对session进行参数配置: config = tf.ConfigProto(allow_soft_placement=True ...
- tensorflow中的tf.app.run()的使用
指明函数的入口,即从哪里执行函数. 如果你的代码中的入口函数不叫main(),而是一个其他名字的函数,如test(),则你应该这样写入口tf.app.run(test()) 如果你的代码中的入口函数叫 ...
随机推荐
- kettle从入门到精通 第二十九课 job 循环 检验字段的值
1.平常我们在用kettle设计job的时候,会用到循环来处理一些业务逻辑,比如循环检测某个表中的数据条数等.这个时候就会用到一个特别重要的步骤:检验字段的值. 下图是一个的通过初始化DNOE变量为f ...
- 一文搞懂 ARM 64 系列: 一文搞懂 ARM 64 系列: 函数调用传参与返回值
函数调用涉及到传参与返回值,下面就来看下ARM 64中,参数与返回值的传递机制. 1 整数型参数传递 这里的整数型并不单指int类型,或者NSInteger类型,而是指任何能够使用整数表示的数据类型, ...
- vm ware 虚拟WIN10 时,chrome ,cent browser 显示异常,花屏
类似: 解决方法: 在VM WARE 显卡设置中关闭"加速3D图形". -
- work13
任务要求: 1.建立一个企鹅类,企鹅有名字(可以自由添加属性)2.把多个企鹅的信息添加到集合中3.查看企鹅的数量4.遍历输出所有企鹅的信息5.删除集合中索引值是2的企鹅的元素 任务描述: 定义一个老鼠 ...
- Centos7部署FytSoa项目至Docker——第二步:安装Mysql、Redis
FytSoa项目地址:https://gitee.com/feiyit/FytSoaCms 部署完成地址:http://82.156.127.60:8001/ 先到腾讯云申请一年的云服务器,我买的是一 ...
- CSS3随机背景图片切换特效
Tips:当你看到这个提示的时候,说明当前的文章是由原emlog博客系统搬迁至此的,文章发布时间已过于久远,编排和内容不一定完整,还请谅解` CSS3随机背景图片切换特效 日期:2018-5-16 阿 ...
- 简单的解释下什么是CNAME
今天在用阿里云的安全防护给接口域名做web应用防火墙,需要配置cname,原来有用到过但是一直没去了解过,只知道怎么用今天搜了一下看看下面是原文,白话文好理解分享一下. 什么是CNAME?先简单的说下 ...
- 记录一次MySQL多表查询,order by不走索引的情况.
首先是表结构,部分字段脱敏已删除 CREATE TABLE `log_device_heart` ( `id` int unsigned NOT NULL AUTO_INCREMENT, `devic ...
- 认真学习CSS3-问题收集-101号-莫名其妙的row行高
其他人都有事情,有些事情只好自己上阵,自己做,最踏实! 做了两个基本一样的页面,都是采用bootsrap+jquey+js的技术,业务内容就是简单的查询,加上一些简单的效果,没有啥特别的内容. 由于历 ...
- Linux中的环境变量PS1,打造你的专属终端
文章目录 介绍 PS1的格式 设置字体样式 举例 小建议 进阶 介绍 好看的终端是怎么做的呢?通过PS1这个环境变量! PS1的格式 PS1='[\u@\h \w]\$ ' 样式: 解释: [是普通字 ...