Oracle是如何工作的?实例是如何响应用户请求?一条SQL的执行过程~
Oracle 是如何工作的?
- Select id,name from t order by id ;
– SQL 解析(查看语法是否错误,如果没有错误,分析语意,执行此语句的权限)
– 执行计划(ORACLE如何访问数据,按照执行计划取数据)
– 执行SQL
• 从磁盘中读取数据(如果数据在内存中没有,就去磁盘读取)
• 数据处理(数据读到内存后,就进行处理。排序,组合等处理)
• 返回结果(把结果返回给用户)
- Insert into t values(1,‘tigerfish’);
– SQL 解析
– 执行计划
– 执行SQL
• 从磁盘中读取数据块(如果内存中没有)
• 修改回滚段数据块(同时产生redo log)----Oracle特性(将数据修改前的数据放到回滚数据块)
• 修改原始数据块(同时产生redo log)
- Create table t values(id int,name varchar2(10);
– SQL 解析
– 执行计划
– 执行SQL
• 给对象分配初始化的存储空间(段),产生一些undo和redo日志。
• 在Oracle字典表中创建新的对象相关信息(表,字段,各种属性….),产生一些Undo和redo日志。
- Drop table t purge(truncate table t);
– SQL 解析
– 执行计划
– 执行SQL
• 收回对象占用的空间,产生一些undo和redo日志。
• 在Oracle字典表中删除的对象的相关信息(表,字段,各种属性….),产生一些Undo和redo日志。
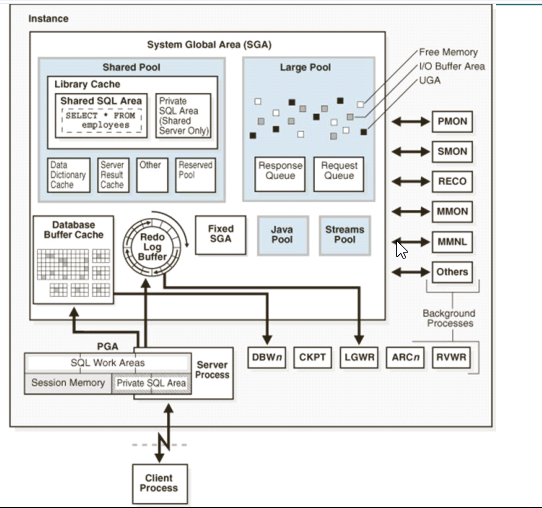
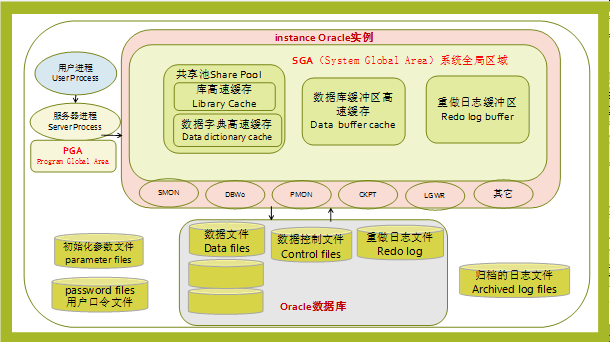
实例是如何响应用户请求?
- Client Process(用户端进程)向数据库发了一条SQL语句.
- 数据库端会启用一个Server Process(服务器进程).
- Client Process和Server Process组成了一个Session(会话).
- Server Process就会处理用户的请求.
- Server Process会开一块内存(PGA),用户的请求(SQL语句)首先会放在PGA里.
- Server Process开辟了内存后就要开始执行SQL语句了.这时候就需要去访问SGA.
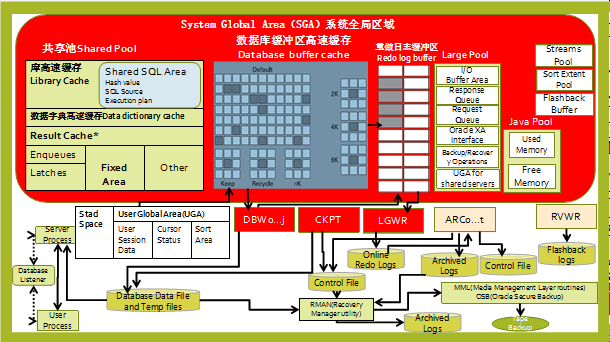
- 访问SGA,首先去Share Pool解析SQL语句,得到执行计划,然后按照执行计划去Database Buffer Cache查找数据.
- 如果Database Buffer Cache没有,Server Process就直接去磁盘里面读数据到Database Buffer Cache.
- 如果Database Buffer Cache里读到了数据,用户需要修改数据块,那么就会在Database Buffer Cache里修改数据块.
- 修改数据块后会产生redo log,redo log Buffer会产生响应的重做项。
- 如果用户发出commit的提交,redo log Buffer会通过LGWR进程将数据写到磁盘上.
- 如果用户发出了checkpoint检查点,数据会被DBWn进程会将修改了的脏数据(当buffer cache被修改了就会标记为脏数据)写入磁盘上.
一条SQL的执行过程:
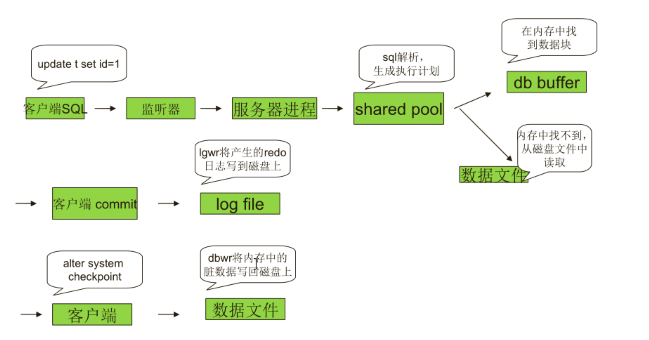
- 客户端发出请求(update set id=1),连接监听器,监听器将服务转到实例上,ORACLE启动服务器进程,和客户端进程建立连接,就完成了一个会话.
- ORACLE服务器进程将SQL语句在Share pool里面进行解析(语法分析、语义分析(权限啊,表是否存在),生成执行计划)
- ORACLE服务器进程按照执行计划访问数据,先到db buffer里面找数据块.如果有就对数据库做update!
- 如果db buffer里面没有,就会从磁盘相应的数据文件中找.再把数据读到db buffer里面去.就可以修改数据块了.
- 修改数据时会产生一个undo数据(重做数据).(如之前的id=99,那么id=99的数据块就会被放到undo表空间去,方便回滚),然后修改当前的数据块为1.
- 客户端提交commit命令.
- LGWR将undo产生的日志和当前数据块修改产生的日志放在一起,写在磁盘上.
- 客户端发出alter system checkpoint,DBWR将内存中的脏数据写到磁盘上.
执行一个SQL语句
执行查询语句的过程:
- 用户进程执行一个查询语句如select * from emp where empno=7839
- 用户进程和服务器进程建立连接,把改用户进程的信息存储到PGA的UGA中
- 语句经过PGA处理后传递给实例instance
- 实例instance中的共享池处理这条语句
- 库缓冲区去判断语句如何分析--软分析(快)或硬分析(慢)
- 根据cbo得到执行计划,准备去执行语句.(CBO和RBO是ORACLE提供的两种优化器)
- 查询语句中的对象(emp表和行)存放在那个表空间,指定的行放在那个块block里?需要到数据字典缓冲区得到这些信息。
- 开始执行
- 如何执行?在内存中执行
- 判断在database buffer cache数据缓存区中是否缓存了需要的block。
- 如果是,在内存读取数据得到需要的行的结果返回给用户,用户看到执行的结果。
- 如果不是,则服务器进程把块从磁盘读入到data bufer cache缓存下来,然后undo缓存块会对该块做镜像,然后读镜像中的数据得到行的结果返回给用户,用户看到执行的结果。
执行UPDATE语句的过程:
- 用户进程执行一个update语句:UPDATE emp set sal=10 WHERE id=1234
- 用户进程和服务器进程建立连接,把该用户进程的信息存储到PGA的UGA中
- 语句经过PGA处理后传递给实例instance
- 实例instance中的共享池处理这条语句
- 库缓冲区去判断语句如何分析--软分析(快)或硬分析(慢)
- 根据cbo得到执行计划,准备去执行语句.(CBO和RBO是ORACLE提供的两种优化器)
- 查询语句中的对象(emp表和行)存放在那个表空间,需要修改的行放在那个块block里?需要到数据字典缓冲区得到这些信息。
- 开始执行
- 如何执行?在内存中执行
- 判断在database buffer cache数据缓存区中是否缓存了需要修改的block。
- 如果是,直接在内存中操作。
- 如果不是,则服务器进程把块从磁盘读入到data buffer cache缓存下来,然后undo缓存块会对该块做镜像,然后对内存中的block做修改操作。
- 由于block发生了修改/变化,redo log buffer会记录块block修改的操作信息,同时,会将修改之前的数据放在undo块镜像,修改之后的数据放在undo块镜像。
- 提交的数据要写入磁盘,没有提交的不写入磁盘。如果执行了commit,data buffer chache的undo的块数据就会标记已经提交。
注:服务器进程把块从磁盘读入到data buffer cache缓存下来后,执行的操作:
1、通过undo把你需要的block做镜像,(这个时候判断操作类型)
(1)、如果是查询语句,执行语句会通过undo中的镜像数据进行游标操作,打开行,取记录,用户可以看到结果.
(2)、如果是更新、删除、插入,执行语句会修改database buffer cache的块,修改之后把修改之后的状态保留在undo中,作为一个新的镜像. 修改之前的镜像是之前就有的,这个镜像是之前数据文件中真实的记录,而后我们将数据进行修改,这个记录成为我们修改之后的状态,而修改之后的状态有2种,第一种是进行了事务提交(修改操作在undo中被标记为已提交),第二种是没有进行事务提交(修改操作在undo中被标记为未提交).
undo中所保留的镜像数据一直要到什么时候把没有提交的更改呢,要到事务结束,或事务撤销,事务崩溃,才能在undo中把这个没有提交的状态给清空或取消,undo中保存的临时数据有2种状态,对DML语句来说一种是修改之前的(原镜像),一个是修改之后的(新镜像). 如果是需要的数据,会根据事务提交commit,把语句通过CKPT来触发,由于块发生了变化,redo log buffer会记录变化的数据块更改的过程,然后根据需要database buffer cache 数据写入数据文件中.
Oracle是如何工作的?实例是如何响应用户请求?一条SQL的执行过程~的更多相关文章
- 转:Oracle中SQL语句执行过程中
Oracle中SQL语句执行过程中,Oracle内部解析原理如下: 1.当一用户第一次提交一个SQL表达式时,Oracle会将这SQL进行Hard parse,这过程有点像程序编译,检查语法.表名.字 ...
- Oracle SQL语句执行过程
前言 QQ群讨论的时候有人遇到这样的问题:where子句中无法访问Oracle自定义的字段别名.这篇 博客就是就这一问题做一个探讨,并发散下思维,谈谈SQL语句的执行顺序问题. 问题呈现 直接给出SQ ...
- oracle里要查看一条sql的执行情况,有没有走到索引,怎么看?索引不能提高效率?
index scan 索引扫描 full table scan是全表扫描 直接explain plan for 还有个set autotrace什么 索引一定能提高执行效率吗? 索引不能提高效率的情况 ...
- 一条SQL在内存结构与后台进程工作机制
oracle服务器由数据库以及实例组成,数据库由数据文件,控制文件等物理文件组成,实例是由内存结构+后台进程组成,实例又可以看做连接数据库的方式,在我看来就好比一家公司,实例就是一个决策的办公室,大大 ...
- Oracle sql语句执行顺序
sql语法的分析是从右到左 一.sql语句的执行步骤: 1)词法分析,词法分析阶段是编译过程的第一个阶段.这个阶段的任务是从左到右一个字符一个字符地读入源程序,即对构成源程序的字符流进行扫描然后根据构 ...
- Oracle SQL语句执行步骤
转自:http://www.cnblogs.com/quanweiru/archive/2012/11/09/2762345.html Oracle中SQL语句执行过程中,Oracle内部解析原理如下 ...
- Hadoop MapReduce执行过程实例分析
1.MapReduce是如何执行任务的?2.Mapper任务是怎样的一个过程?3.Reduce是如何执行任务的?4.键值对是如何编号的?5.实例,如何计算没见最高气温? 分析MapReduce执行过程 ...
- Oracle一条SQL语句时快时慢
今天碰到一个非常奇怪的问题问题,一条SQL语句在PL/SQL developer中很慢,需要9s,问题SQL: SELECT * FROM GG_function_location f WHERE f ...
- 在Oracle中利用SQL_TRACE跟踪SQL的执行
当你在执行一条SQL语句非常慢的时候,你是不是想问Oracle怎么执行这条语句的呢? Oracle提供的SQL_TRACE工具可以让你知道你执行的SQL究竟做了什么.执行的过程会被 输出到trace文 ...
随机推荐
- nginx-1.2.7 + tcp_proxy_module手动编译安装
Nginx开源软件默认没有提供TCP协议的负载均衡,下面记录一下我的安装过程: 1. 下载nginx最新稳定版的源码.可访问:http://www.nginx.org 或 linux命令下载到本地: ...
- .Net并行编程高级教程(二)-- 任务并行
前面一篇提到例子都是数据并行,但这并不是并行化的唯一形式,在.Net4之前,必须要创建多个线程或者线程池来利用多核技术.现在只需要使用新的Task实例就可以通过更简单的代码解决命令式任务并行问题. 1 ...
- Sql學習資源
http://blog.csdn.net/wltica/article/category/1324738/1 SQL Server 整体方案系列: 1. SQL Server 数据归档方案 2. SQ ...
- PHP中获取当前页面的完整URL & php $_SERVER中的SERVER_NAME 和HTTP_HOST的区别
#测试网址: http://localhost/blog/testurl.php?id=5 //获取域名或主机地址 echo $_SERVER['HTTP_HOST']."<b ...
- EularProject 32: 数字1-9排列构成乘法等式
Pandigital products Problem 32 We shall say that an n-digit number is pandigital if it makes use of ...
- bashrc,bash_profile和/etc/profile
bashrc,bash_profile和/etc/profile 最近老出现在shell里面能跑的程序用鼠标双击app去不能跑.究其原因是因为环境变量的问题. 在类unix系统中一般有三个bash配置 ...
- Atitit.判断元素是否显示隐藏在父元素 overflow
Atitit.判断元素是否显示隐藏在父元素 overflow 1.1. scrollTop 指的是元素的滚动条顶端距离原生基线的高度...1 1.2. 判断元素是否显示隐藏在父元素 $(next) ...
- python对象序列化之pickle
本片文章主要是对pickle官网的阅读记录. The pickle module implements binary protocols for serializing and de-serializ ...
- InnoDB:文件
Mysql中有多种类型的文件,每种类型的文件都有其特定的作用,下面就来说说: 参数文件:告诉Mysql实例数据库文件的位置,定义参数. 日志文件:Mysql实例对某种条件作出的响应写入文件,这个文件就 ...
- CentOS上扩充lv-root空间步骤详解
查看服务器发现vg_host01-lv_root下的空间占用的比较多,需要扩容. 有以下两种方案: )利用空余的磁盘,扩展lv_root的大小(推荐) )将lv_home的空间挪出一部分给lv_roo ...