Hadoop2学习路程-HDFS
什么是Hadoop HDFS?
Hadoop 分布式文件系统是世界上最可靠的文件系统。HDFS可以再大量硬件组成的集群中存储大文件。
它的设计原则是趋向于存储少量的大文件,而不是存储大量的小文件。
即使在硬件发生故障的时候,HDFS也能体现出它对数据存储的可靠性。它支持高吞吐量的平行访问方式。
HDFS的介绍
源自于Google的GFS论文 发表于2003年10月 HDFS是GFS克隆版 ,HDFS的全称是Hadoop Distributed File System易于扩展的分布式文件系统,运行在大量普通廉价机器上,提供容错机制,为大量用户提供性能不错的文件存取服务 。
HDFS设计目标
1. 自动快速检测应对硬件错误
2. 流式访问数据
3. 移动计算比移动数据本身更划算
4. 简单一致性模型
5. 异构平台可移植
{
对于设计目标的详细解释:
I. 硬件故障(自动快速检测应对硬件错误)
硬件故障已经不再是异常了,它变成了一个常规现象。HDFS实例由成千上万的服务机器组成,这些机器中的任何一个都存储着文件系统的部分数据。这里元件的数量是庞大的,而且极可能导致硬件故障。这就意味着总是有一些组件不工作。所以,核心结构的目标是快速的自动的进行错误检测和恢复。
II. 流数据访问(流式访问数据)
HDFS 应用需要依赖流去访问它的数据集。Hadoop HDFS的设计方向主要面向于批处理而不是用户交互。着力点在于重视数据访问的高吞吐率而不是数据访问的低延迟性。它注重于如何在分析日志的同时尽肯能快速的获得数据。
III. 巨大的数据集
HDFS通常需要工作在大数据集上。标准的实践中是,HDFS系统中存在的文件大小范围是GB到TB。HDFS架构的设计就是如果最好的存储和获得大量的数据。HDFS也提供高聚合数据的带宽。它同样应该具备在单一集群中可以扩展上百个节点的能力。与此同时,它也应该具备在一个单元实例中处理处理数千万个文件的能力。
IV. 简单的一致性模型(简单一致性模型)
它工作在一次性写入多次的读取的理论上。一旦数据被创建、写入和关闭,该文件是不能被修改的。这种方式解决数据一致性的问题同时也实现了高吞吐量访问数据的需求。基于MapReduce的应用和或者网络爬虫的应用在这种模型中拥有很高的适应性。和每一apache笔记一样,未来计划增加追加写入文件这一功能。
V. 转移计算量比转移数据更合理(移动计算比移动数据本身更划算)
如果一个应用在它操作的数据附近进行计算,总会比在离它远的地方做计算更高效。这个现象在处理大的数据集时,往往提现的更明显。这样做主要的优势体现在增加系统的总吞吐量上。它同时也最小化了网路阻塞。其理念是,将计算移动到离数据更近的位置,来代替将数据转移到离计算更近的位置。
VI. 便捷的访问有不同软件和硬件组成的平台(异构平台可移植)
HDFS 被设计成便捷的在平台之间切换。这让HDFS系统能够因为其适应性而广泛传播。这是在处理大数据集数据的最好的平台。
}
HDFS的特点
优点:
1. 高可靠性:Hadoop按位存储和处理数据的能力值得人们信赖;
2. 高扩展性:Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
3. 高效性: Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
4. 高容错性:Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
缺点:
1. 不适合低延迟数据访问。
2. 无法高效存储大量小文件。
3. 不支持多用户写入及任意修改文件。
hdfs核心设计思想及作用
- 分而治之:将大文件、大批量文件,分布式存放在大量服务器上,以便于采取分而治之的方式对海量数据进行运算分析;
- 为各类分布式运算框架(如:mapreduce,spark,tez,……)提供数据存储服务
- hdfs描述
首先,它是一个文件系统,用于存储文件,通过统一的命名空间——目录树来定位文件
其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色;
重要特性如下:
- HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,老版本中是64M。
- HDFS文件系统会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data。
- 目录结构及文件分块信息(元数据)的管理由namenode节点承担——namenode是HDFS集群主节点,负责维护整个hdfs文件系统的目录树,以及每一个路径(文件)所对应的block块信息(block的id,及所在的datanode服务器)。
- 文件的各个block的存储管理由datanode节点承担--- datanode是HDFS集群从节点,每一个block都可以在多个datanode上存储多个副本(副本数量也可以通过参数设置dfs.replication)。
- HDFS是设计成适应一次写入,多次读出的场景,且不支持文件的修改
NameNode.SecondaryNameNode.StandByNameNode,Blocks
NO.1 NameNode的功能
NameNode在HDFS架构中也被成为主节点。HDFS NameNode存储元数据,比如,数据块的数量,副本的数量和其它的一些细节。这些元数据被存放在主节点的内存中,为了达到最快速度的获取数据。NameNode 负责维护和管理从节点并且给从节点分配任务。它是整个HDFS的中心环节,所以应该将其部署在可靠性高的机器上。
NameNode的任务:
· 管理文件系统命名空间
· 规定客户端访问文件规则
· 对文件执行命名,关闭,打开文件或打开路径等 操作
· 所有的数据节点发送心跳给NameNode, NameNode需要确保DataNode是否在线。一个数据块报告包含所有这个数据点上的所有block的情况。
· NameNode也负责管理复制因子的数量。
文件呈现在NameNode的元数据表示和管理:
FsImage :元数据镜像文件 (保存文件系统的目录树) -
- 内存中保存一份最新的
- 内存中镜像= FsImage + Edits
- FsImage在NameNode中是一个“镜像文件”。它将全部的文件系统的命名空间保存为一个文件存储在NameNode的本地文件系统中,这个文件中还包含所有的文件序列化路径和在文件系统中的文件inodes,每个inode都是文件或者目录元数据的内部表示。
Edits :元数据操作日志 (针对目录树的修改操作) -
- 日志文件包含所有在镜像文件上对系统的最新修改。当NameNode从客户端收到一个创建/更新/删除请求时,这条请求会先被记录到日志文件中。
- 定期合并fsimage与edits(- Edits文件过大将导致NameNode重启速度慢, Secondary Namenode负责定期合并他们)
NO.2 NameNode 启动过程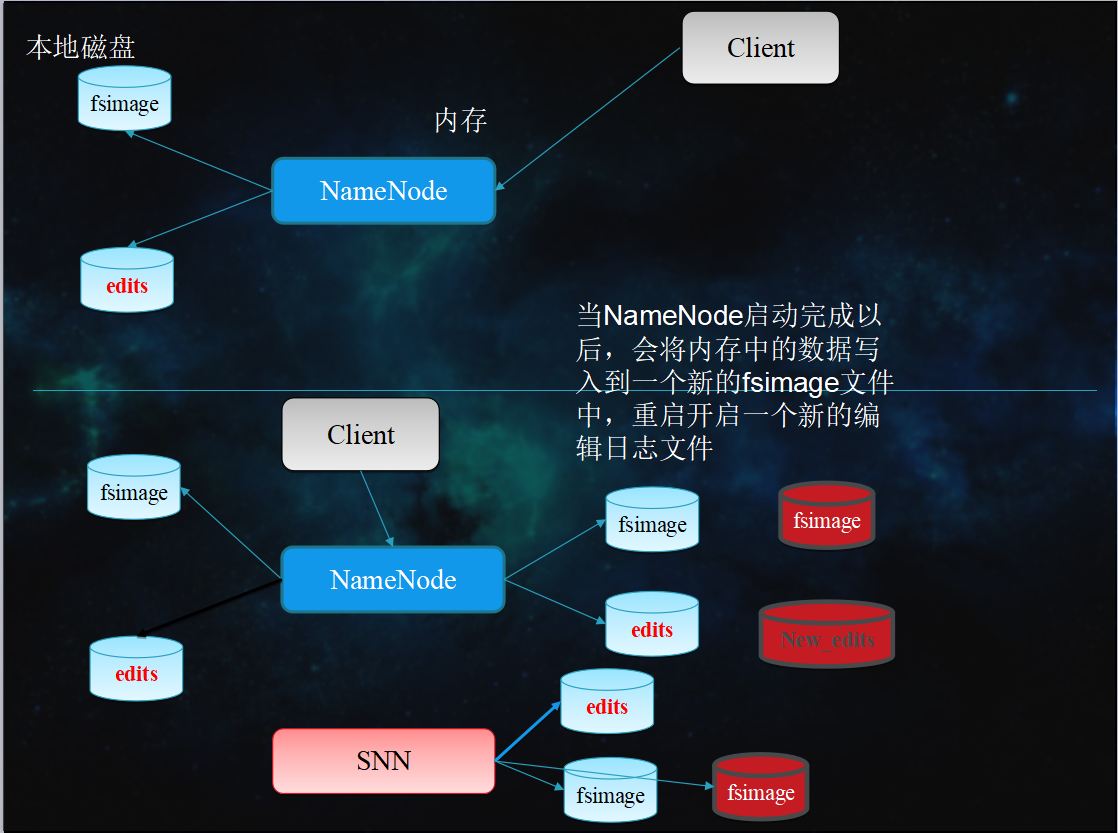
- NameNode启动的时候首先将fsimage(镜像)载入内存,并执行(replay)编辑日志edits的的各项操作
- 一旦在内存中建立文件系统元数据映射,则创建一个新的fsimage文件(这个过程不需SecondaryNameNode) 和一个空的edits
- 在安全模式下,各个datanode会向namenode发送块列表的最新情况
- 此刻namenode运行在安全模式。即NameNode的文件系统对于客户端来说是只读的。(显示目录,显示文件内容等。写、删除、重命名都会失败)
- NameNode开始监听RPC和HTTP请求
解释RPC:RPC(Remote Procedure Call Protocol)——远程过程通过协议,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议
- 系统中数据块的位置并不是由namenode维护的,而是以块列表形式存储在datanode中
- 在系统的正常操作期间,namenode会在内存中保留所有块信息的映射信息
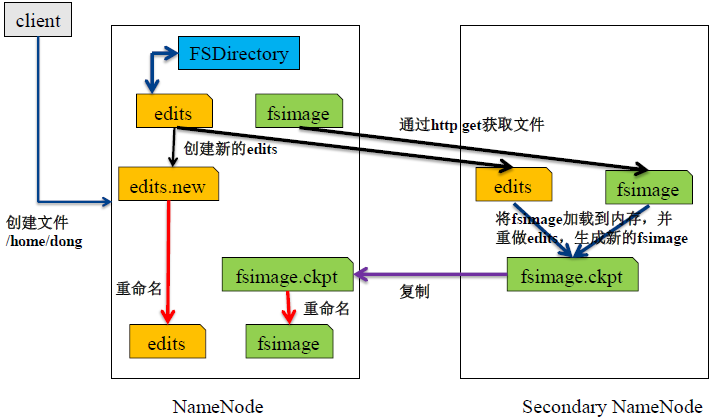
NO.3 SecondaryNameNode 合并fsimage和edits 生成fsimage的过程
-每过1小时或edits达到64mb执行合并(dfs.namenode.checkpoint.period 指定时间, dfs.namenode.checkpoint.txns 指定文件限制大小)
- Secondary NN通知NameNode切换edits。
- Secondary NN从NameNode 获得fsimage和editlog(通过http方式)。
- Secondary NN将fsimage载入内存,然后开始合并edits。
- Secondary NN 将新的fsimage发回给NameNode NameNode 用新的fsimage替换旧的fsimage。
NOTE: SecondaryNameNode 在HDFS中起到一个常规检查点的作用。
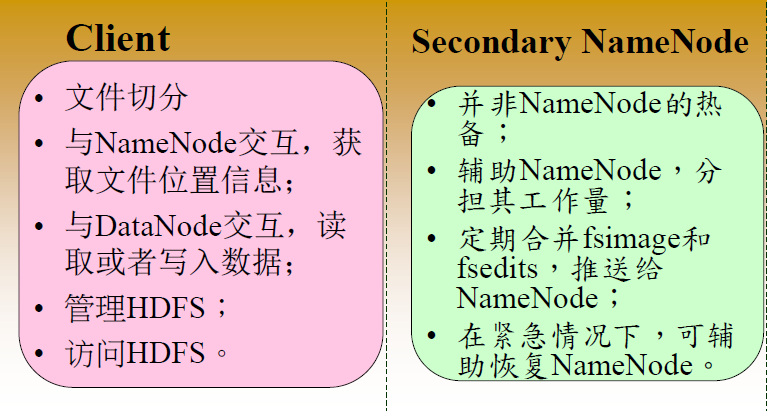
检查节点是一个定期在命名空间创建检查点的节点。在Hadoop中的检查点先从活动的Namenode中下载FsImage文件和日志文件,它在本地将两个文件进行融合,然后上传新的镜像给活动NameNode。它存储最后的检查点的结构,所以它的路径结构应该跟NameNode的路径结构一样。读取检查点镜像的权限,如果有必要应该一直为NameNode开放。
NO.4 StandByNameNode
- 备份节点也提供和检查节点一样的检查功能。
- 在Hadoop中,Backup节点保留内存中最新文件系统命名空间的副本。
- 它和NameNode的状态总是同步的。
- 在HDFS架构中的备份节点不需要从活动的NameNode中下载FsImage和它日志文件去创建检查点。
- 它在内存中已经拥有了最新的命名空间状态。
- 备份节点的检查点流程比起检查节点的检查流程效率更高,因为它只需要保存命名空间到本地镜像文件和重置日志文件就够了。
- NameNode一次只支持一个备份节点。
NO.5 Blocks
- HDFS将巨大的文件分割成小的文件块,这种文件块就叫Blocks. 这些Blocks是文件系统中最小的数据单元。
- 客户端或者管理员,不需要控制这些blocks的存储位置,由NameNode决定类似的事情。
- 默认的HDFS block大小为128MB,当然这值可以根据不同需求而改变。一个文件除了最后一个block其他block的大小都是相同的,最后一个文件的大小可以是128MB,也可以更小。
- 如果数据的大小比block默认值小的话,block大小就会等于数据的大小。
例如一个数据的大小为129MB,则系统会为这个数据创建两个Block一个大小为128MB,另一个大小只为1MB. 存储成这样的好处是,既可以节省空间,有可以节省查询时间。
NO.6 复制管理
- Block复制支持容错机制。如果一个副本不能被访问或者损坏,我们可以从其他的副本中读取数据。
- 在HDFS架构中一个文件的副本数量叫做复制因子。默认的复制因子为3,可以通过修改配置文件修改复制因子。当复制因子为3的时候每个block会被存放在3个不同的DataNode中。
- 如果一个文件是128MB,根据默认配置它将占用384MB的系统空间存储。
- NameNode通过从DataNode定期接收数据块上报去维护复制因子,当一个数据块过多复制或者复制不足,则NameNode负责根据需要增加或删除副本。
NO.7 机架感知
- 在大型的Hadoop集群中,为了提高读、写HDFS文件的效率,NameNode都是按就近原则选择数据节点的,一般的都是选择相同机架的DataNode或者是邻近机架的DataNode去读、写数据。NameNode通过为维护每个数据节点的机架ID来获取机架信息。机架感知在hadoop中是一个有机架信息来获取数据节点的概念。
- 在HDFS架构中, NameNode必须确保所有的副本不存放在相同机架或者单一机架中,并遵循机架感知算法来减少延迟和提高容错。详情查看后边: 数据存储位置与复制详解...
- 机架感知对于提升一下方面有着重要作用:
· 数据高可用性和可靠性
· 集群的表现
· 提升网络带宽
HDFS工作机制详解
NO.1 HDFS概述
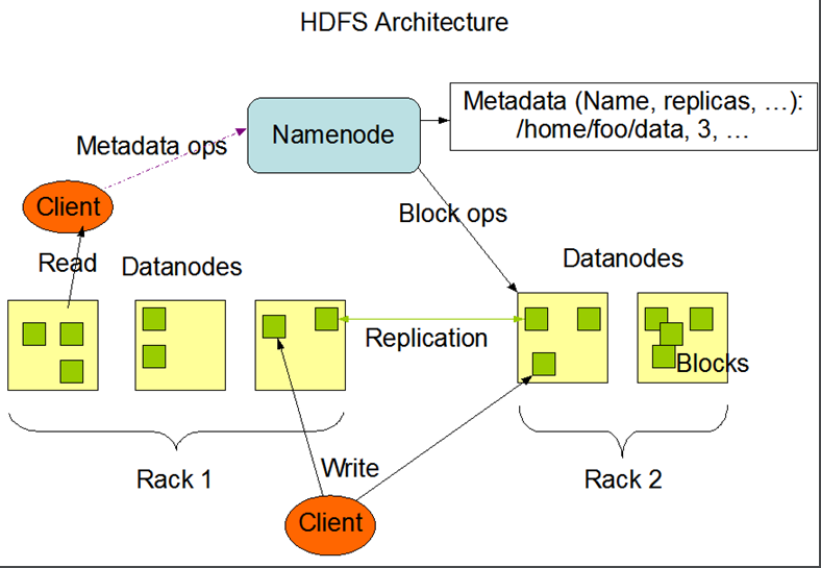
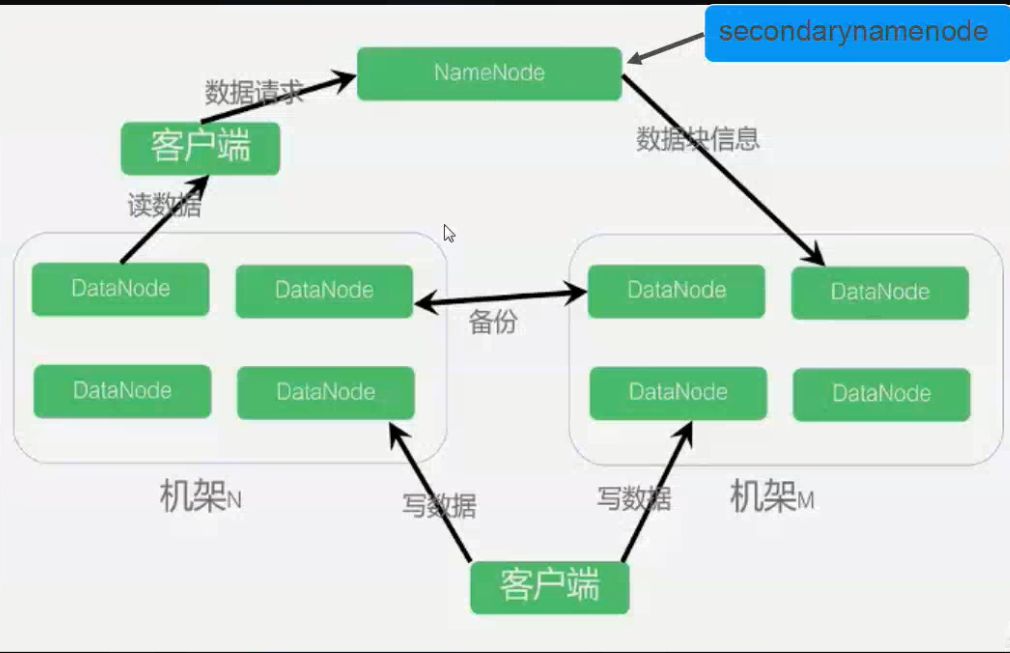
- HDFS集群分为两大角色:NameNode、DataNode
- NameNode负责管理整个文件系统的元数据
- DataNode 负责管理用户的文件数据块block
- 文件会按照固定的大小(blocksize)切成若干块后分布式存储在若干台datanode上
- 每一个文件块可以有多个副本,并存放在不同的datanode上
- Datanode会定期向Namenode汇报自身所保存的文件block信息,而namenode则会负责保持文件的副本数量
- HDFS的内部工作机制对客户端保持透明,客户端请求访问HDFS都是通过向namenode申请来进行
- 集群中主机分别放置在不同的机架(rack)中
NO.2 写入过程分析
客户端要向HDFS写数据,首先要跟namenode通信以确认“可以写文件”并获得接收文件block的datanode,
然后,客户端按顺序将文件逐个block传递给相应datanode,并由接收到block的datanode负责向其他datanode复制block的副本 。
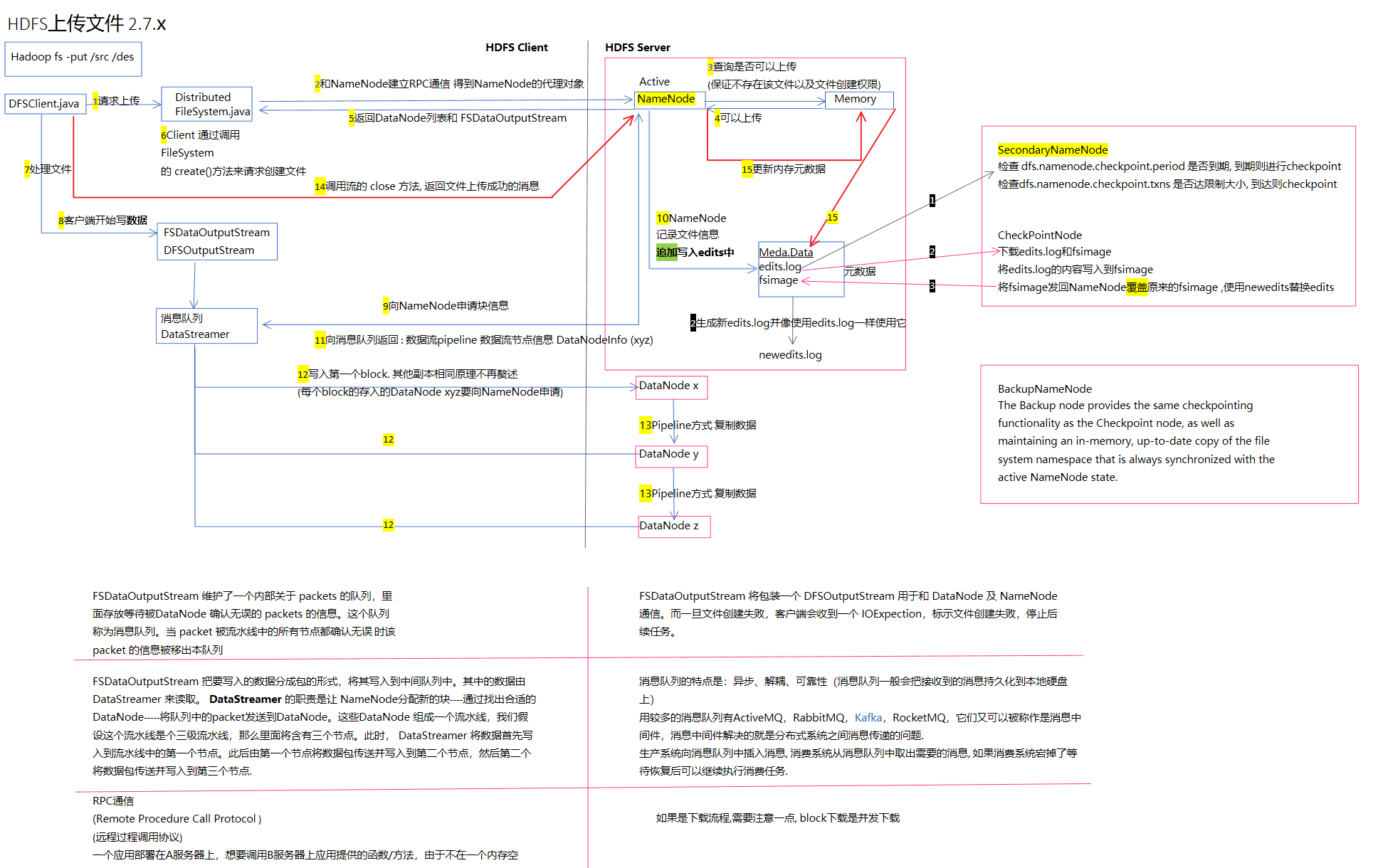
NO.3 数据存储位置与复制详解
- 同一节点上的存储数据
- 同一机架上不同节点上的存储数据
- 同一数据中心不同机架上的存储数据
- 不同数据中心的节点
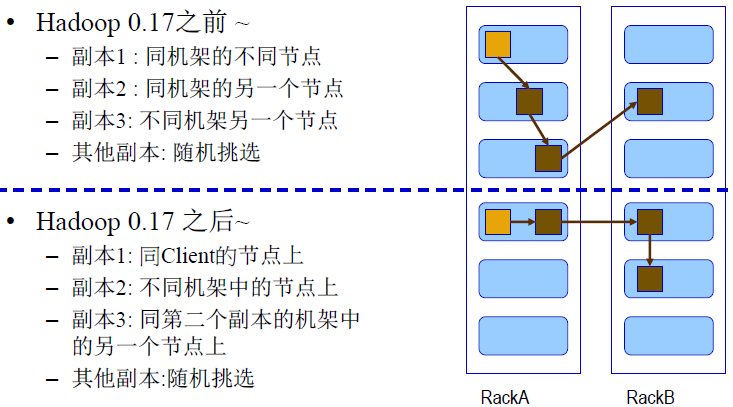
HDFS 数据存放策略就是采用同节点与同机架并行的存储方式。在运行客户端的当前节点上存放第一个副本,第二个副本存放在于第一个副本不同的机架上的节点,第三个副本放置的位置与第二个副本在同一个机架上而非同一个节点。
NO.4 宏观的代码实现
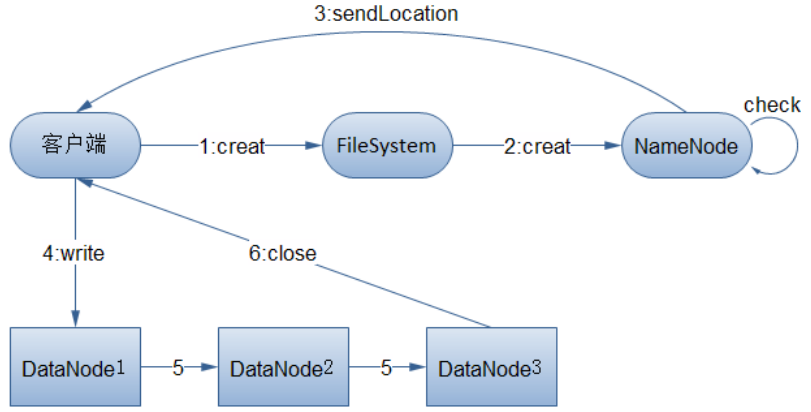
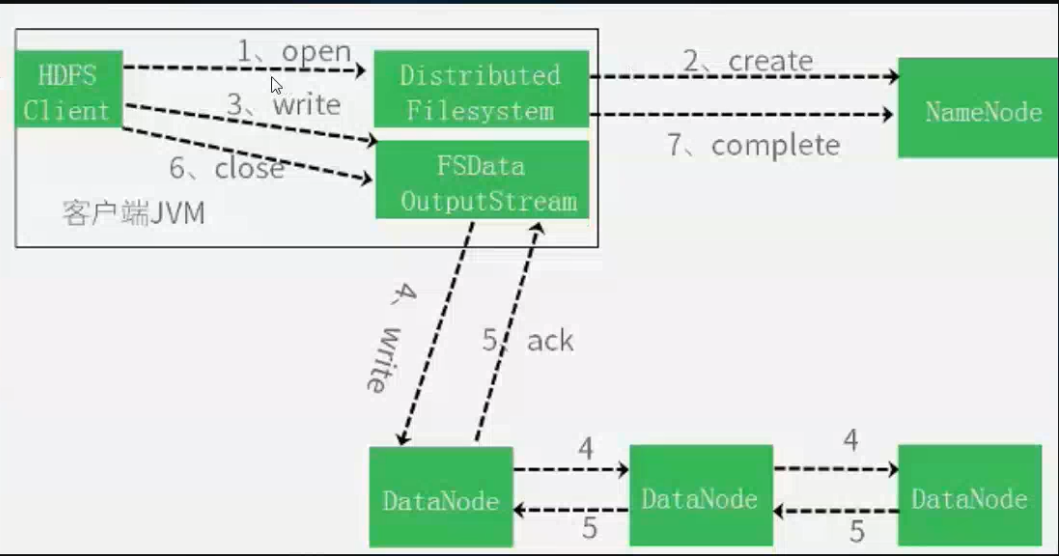
1. Client 通过调用 FileSystem 的 create()方法来请求创建文件
2. FileSystem 通过对 NameNode 发出远程请求,在 NameNode 里面创建一个新的文件,但此时并不关联任何的块。 NameNode 进行很多检查来保证不存在要创建的文件已经存在于文件系统中,同时检查是否有相应的权限来创建文件。如果这些检查都完成了,那么NameNode 将记录下来这个新文件的信息。 FileSystem 返回一个 FSDataOutputStream 给客户端用来写入数据。和读的情形一样, FSDataOutputStream 将包装一个 DFSOutputStream 用于和 DataNode 及 NameNode 通信。而一旦文件创建失败,客户端会收到一个 IOExpection,标示文件创建失败,停止后续任务。
3. 客户端开始写数据。 FSDataOutputStream 把要写入的数据分成包的形式,将其写入到中间队列中。其中的数据由 DataStreamer 来读取。 DataStreamer 的职责是让 NameNode分配新的块——通过找出合适的 DataNode——来存储作为备份而复制的数据。这些DataNode 组成一个流水线,我们假设这个流水线是个三级流水线,那么里面将含有三个节点。此时, DataStreamer 将数据首先写入到流水线中的第一个节点。此后由第一个节点将数据包传送并写入到第二个节点,然后第二个将数据包传送并写入到第三个节点。
4. FSDataOutputStream 维护了一个内部关于 packets 的队列,里面存放等待被DataNode 确认无误的 packets 的信息。这个队列称为等待队列。一个 packet 的信息被移出本队列当且仅当 packet 被流水线中的所有节点都确认无误
5. 当完成数据写入之后客户端调用流的 close 方法,在通知 NameNode 完成写入之前,这个方法将 flush 残留的 packets,并等待确认信息( acknowledgement)。 NameNode 已经知道文件由哪些块组成(通过 DataStream 询问数据块的分配),所以它在返回成功前只需要等待数据块进行最小值复制。
NO.5 安全模式
安全模式下,集群属于只读状态。但是严格来说,只是保证HDFS元数据信息的访问,而不保证文件的访问,因为文件的组成Block信息此时NameNode还不一定已经知道了。所以只有NameNode已了解了Block信息的文件才能读到。而安全模式下任何对HDFS有更新的操作都会失败。
- 对于全新创建的HDFS集群,NameNode启动后不会进入安全模式,因为没有Block信息。
安全模式相关命令
- 查询当前是否安全模式 hadoop dfsadmin -safemode get Safe mode is ON
- 等待safemode关闭,以便后续操作 hadoop dfsadmin -safemode wait
- 退出安全模式 hadoop dfsadmin -safemode leave
- 设置启用safemode hadoop dfsadmin -safemode enter
(注: 文档有参考 ----> https://www.jianshu.com/p/86a70ac1f5f9 )
Hadoop2学习路程-HDFS的更多相关文章
- 学习web前端学习路程
学习路程: 1.HTML和CSS基础 2.JavaScript语言 3.jQuery 4.综合网站实践 5.优化及调试
- Hadoop学习笔记-HDFS命令
进入 $HADOOP/bin 一.文件操作 文件操作 类似于正常的linux操作前面加上“hdfs dfs -” 前缀也可以写成hadoop而不用hdfs,但终端中显示 Use of this scr ...
- hadoop学习(五)----HDFS的java操作
前面我们基本学习了HDFS的原理,hadoop环境的搭建,下面开始正式的实践,语言以java为主.这一节来看一下HDFS的java操作. 1 环境准备 上一篇说了windows下搭建hadoop环境, ...
- web前端学习路程
学习路程: 1.HTML和CSS基础 2.JavaScript语言 3.jQuery and ajax 4.综合网站实践 5.优化及调试
- 大数据学习之hdfs集群安装部署04
1-> 集群的准备工作 1)关闭防火墙(进行远程连接) systemctl stop firewalld systemctl -disable firewalld 2)永久修改设置主机名 vi ...
- Hadoop2学习记录(1) |HA完全分布式集群搭建
准备 系统:CentOS 6或者RedHat 6(这里用的是64位操作) 软件:JDK 1.7.hadoop-2.3.0.native64位包(可以再csdn上下载,这里不提供了) 部署规划 192. ...
- 大数据学习之HDFS基本API操作(下)06
hdfs文件流操作方法一: package it.dawn.HDFSPra; import java.io.BufferedReader; import java.io.FileInputStream ...
- 大数据学习之HDFS基本API操作(上)06
package it.dawn.HDFSPra; import java.io.FileNotFoundException; import java.io.IOException; import ja ...
- 【转载 Hadoop&Spark 动手实践 2】Hadoop2.7.3 HDFS理论与动手实践
简介 HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.是根据google发表的论文翻版的.论文为GFS(Google File System)Go ...
随机推荐
- Math类中常用方法
public static int abs(int a) , public static long abs(long a), public static float abs(float a), pu ...
- CSS media query应用中的层叠特性使用最佳实践
media query是css3规范中引入的,它提供了一种responsive design的基础机制:浏览器在不同size的设备中将以不同样式展现网页,这就给一个网页能够适应不同device一种可能 ...
- Ubuntu安装使用pyltp和StanfordCoreNLP
环境:Ubuntu 16.04+anaconda3 一.pyltp 1. 安装 直接用pip安装: pip install pyltp 然后下载语言模型库,网址:https://pan.baidu.c ...
- java操作svn【svnkit】实操
SVNKit中怎样使用不同的仓库访问协议? 当你下载了最新版的SVNKit二进制文件并且准备使用它时,一个问题出现了,要创建一个库需要做哪些初始化的步骤?直接与Subversion仓库交互已经在低级层 ...
- 【Leetcode】【Easy】Merge Two Sorted Lists .
Merge two sorted linked lists and return it as a new list. The new list should be made by splicing t ...
- fork: retry: Resource temporarily unavailable
用户A打开文件描述符太多,超过了该用户的限制 修改用户可以打开的文件描述符数量 1.首先,用另一个用户B登录,修改/etc/security/limit.conf * soft nofile 6553 ...
- Visual Studio中头文件stdafx.h的作用
在较新版的Visual Studio中,新生成的C++项目文件的的头文件夹下会默认有头文件stdafx.h,而源文件夹下则默认有源文件stdafx.cpp,手动将这些文件删除后,编译时系统还会报错.下 ...
- 更新UI的几种方式
在学习Handler的过程中牵涉到UI的更新,在这里就总结一下更新UI的四种方式吧,用法都比较简单,直接看代码就可以了. 一.使用Handler的post方法 新建项目,修改MainActivity代 ...
- 4.spriing:Bean的生命周期/工厂方法配置Bean/FactoryBean
1.Bean的生命周期 scope:singleton/prototype 1)spring容器管理singleton作用的生命周期,spring能够精确知道Bean合适创建,何时初始化完成,以及何时 ...
- ICompare 可比较接口
执行