redis源码学习_整数集合
redis里面的整数集合保存的都是整数,有int_16、int_32和int_64这3种类型,和C++中的set容器差不多。
同时具备如下特点:
1、set里面的数不重复,均为唯一。
2、set里面的数是从小到大有序的,这在后面的intsetAdd函数中可以看到。
然后由于我们可以同时存储int_16、int_32和int_64这3种类型,一开始只能为一种类型。假设为int_32,那么我们要插入一个int_16类型的数,只需要找到位置直接插入就可以了;但是我们要插入一个int_64类型的数,我们需要先升级,然后再插入。之所以要升级是为了可以有足够的空间存下位数更多的整数,一开始不直接搞成int_64是为了节省内存空间,按需升级非常灵活,既可以节省空间,又可以同时存在不同类型(int_16、int_32和int_64)的整数,一举两得!
主要总结一下intset.c和intset.h里面的关键结构体和函数。
先来看一下intset的结构体吧
typedef struct intset {
/*
虽然 intset 结构将 contents 属性声明为 int8_t 类型的数组, 但实际上 contents 数组的真正类型取决于 encoding 属性的值:
如果 encoding 属性的值为 INTSET_ENC_INT16 , 那么 contents 就是一个 int16_t 类型的数组, 数组里的每个项都是一个 int16_t类型的整数值 (最小值为 -32,768 ,最大值为 32,767 )。
如果 encoding 属性的值为 INTSET_ENC_INT32 , 那么 contents 就是一个 int32_t 类型的数组, 数组里的每个项都是一个 int32_t类型的整数值 (最小值为 -2,147,483,648 ,最大值为 2,147,483,647 )。
如果 encoding 属性的值为 INTSET_ENC_INT64 , 那么 contents 就是一个 int64_t 类型的数组, 数组里的每个项都是一个 int64_t类型的整数值 (最小值为 -9,223,372,036,854,775,808 ,最大值为9,223,372,036,854,775,807 )。
*/
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;
函数intsetAdd是里面精华部分,在看它之前我们先看一下它用到的一些函数
_intsetValueEncoding:得到实际的类型,即对应的是int_16、int_32和int_64中的哪一个
/* Return the required encoding for the provided value.
*
* 返回适用于传入值 v 的编码方式
*
* T = O(1)
*/
static uint8_t _intsetValueEncoding(int64_t v) {
if (v < INT32_MIN || v > INT32_MAX)
return INTSET_ENC_INT64;
else if (v < INT16_MIN || v > INT16_MAX)
return INTSET_ENC_INT32;
else
return INTSET_ENC_INT16;
}
_intsetSet:在指定位置上面插数
/* Set the value at pos, using the configured encoding.
*
* 根据集合的编码方式,将底层数组在 pos 位置上的值设为 value 。
*
* T = O(1)
*/
static void _intsetSet(intset *is, int pos, int64_t value) { // 取出集合的编码方式
uint32_t encoding = intrev32ifbe(is->encoding); // 根据编码 ((Enc_t*)is->contents) 将数组转换回正确的类型
// 然后 ((Enc_t*)is->contents)[pos] 定位到数组索引上
// 接着 ((Enc_t*)is->contents)[pos] = value 将值赋给数组
// 最后, ((Enc_t*)is->contents)+pos 定位到刚刚设置的新值上
// 如果有需要的话, memrevEncifbe 将对值进行大小端转换
if (encoding == INTSET_ENC_INT64) {
((int64_t*)is->contents)[pos] = value;
memrev64ifbe(((int64_t*)is->contents)+pos);
} else if (encoding == INTSET_ENC_INT32) {
((int32_t*)is->contents)[pos] = value;
memrev32ifbe(((int32_t*)is->contents)+pos);
} else {
((int16_t*)is->contents)[pos] = value;
memrev16ifbe(((int16_t*)is->contents)+pos);
}
}
关于里面的memrevXXXifbe函数就是个宏
#if (BYTE_ORDER == LITTLE_ENDIAN)
#define memrev16ifbe(p)
#define memrev32ifbe(p)
#define memrev64ifbe(p)
#else
#define memrev16ifbe(p) memrev16(p) //高低位对换
#define memrev32ifbe(p) memrev32(p) //高低位对换
#define memrev64ifbe(p) memrev64(p) //高低位对换
#endif
补充一下大小端的知识:
大端模式:是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址中;
小端模式:是指数据的低位保存在内存的低地址中,而数据的高位保存在内存的高地址中。
在裘宗燕翻译的《程序设计实践》里,这对术语并没有翻译为“大端”和小端,而是“高尾端”和“低尾端”,这就好理解了:如果把一个数看成一个字符串,比如11223344看成"11223344",末尾是个'\0','11'到'44'个占用一个存储单元,那么它的尾端很显然是44,前面的高还是低就表示尾端放在高地址还是低地址,它在内存中的放法非常直观,如下图:
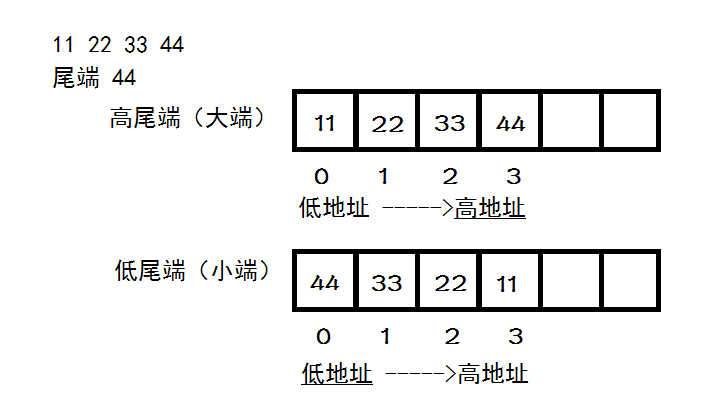
“高/低尾端”比“大/小端”更不容易让人迷惑。在这两对形容词中,恰好“高”和“大”对应,“低”和“小”对应;既然高尾端对应的是大端,低尾端对应的是小端,那么当你再见到大端和小端这一对术语,就可以在脑中把它们转化成高尾端和低尾端,这时凭着之前的理解,甚至不用回忆,想着高低的字面含义就能回想起它们的含义。
理解之后,总结一下,记忆的方法是:
(数据看成字符串)大端——高尾端,小端——低尾端
稍一思索什么是“高”、什么是"低","尾端"又是什么,问题迎刃而解,再不用担心被“大端”和“小端”迷惑。用这种方式,是时候放弃原先的死记硬背和容易把自己绕进去而发生迷惑的理解了。
16bit宽的数0x1234在Little-endian模式CPU内存中的存放方式(假设从地址0x4000开始存放)为:
|
内存地址 |
0x4000 |
0x4001 |
|
存放内容 |
0x34 |
0x12 |
而在Big-endian模式CPU内存中的存放方式则为:
|
内存地址 |
0x4000 |
0x4001 |
|
存放内容 |
0x12 |
0x34 |
32bit宽的数0x12345678在Little-endian模式CPU内存中的存放方式(假设从地址0x4000开始存放)为:
|
内存地址 |
0x4000 |
0x4001 |
0x4002 |
0x4003 |
|
存放内容 |
0x78 |
0x56 |
0x34 |
0x12 |
而在Big-endian模式CPU内存中的存放方式则为:
|
内存地址 |
0x4000 |
0x4001 |
0x4002 |
0x4003 |
|
存放内容 |
0x12 |
0x34 |
0x56 |
0x78 |
如何判断系统是大端还是小端呢?
#include <stdlib.h>
#include <stdio.h>
int main(int argc, char **argv)
{
union {
short s;
char c[sizeof(short)];
} un;
un.s = 0x0102;
if(sizeof(short)==) {
if(un.c[]== && un.c[] == )
printf("big-endian\n");
else if (un.c[] == && un.c[] == )
printf("little-endian\n");
else
printf("unknown\n");
} else
printf("sizeof(short)= %d\n",sizeof(short));
exit();
}
扯远了,我们再回来接着看啊~~~
intsetUpgradeAndAdd:升级函数,这算是set里面比较难的函数了。
/* Upgrades the intset to a larger encoding and inserts the given integer.
*
* 根据值 value 所使用的编码方式,对整数集合的编码进行升级,
* 并将值 value 添加到升级后的整数集合中。
*
* 返回值:添加新元素之后的整数集合
*
* T = O(N)
*/
static intset *intsetUpgradeAndAdd(intset *is, int64_t value) { // 当前的编码方式
uint8_t curenc = intrev32ifbe(is->encoding); // 新值所需的编码方式
uint8_t newenc = _intsetValueEncoding(value); // 当前集合的元素数量
int length = intrev32ifbe(is->length); // 根据 value 的值,决定是将它添加到底层数组的最前端还是最后端
// 注意,因为 value 的编码比集合原有的其他元素的编码都要大
// 所以 value 要么大于集合中的所有元素,要么小于集合中的所有元素
// 因此,value 只能添加到底层数组的最前端或最后端
int prepend = value < ? : ; /* First set new encoding and resize */
is->encoding = intrev32ifbe(newenc); is = intsetResize(is,intrev32ifbe(is->length)+); /* Upgrade back-to-front so we don't overwrite values.
* Note that the "prepend" variable is used to make sure we have an empty
* space at either the beginning or the end of the intset. */
while(length--)
_intsetSet(is,length+prepend,_intsetGetEncoded(is,length,curenc)); /* Set the value at the beginning or the end. */
// 设置新值,根据 prepend 的值来决定是添加到数组头还是数组尾
if (prepend)
_intsetSet(is,,value);
else
_intsetSet(is,intrev32ifbe(is->length),value); // 更新整数集合的元素数量
is->length = intrev32ifbe(intrev32ifbe(is->length)+); return is;
}
intsetSearch:找数函数,找插入数的位置,有就不插,没有才插,用了二分查找,呵呵!
static uint8_t intsetSearch(intset *is, int64_t value, uint32_t *pos) {
int min = , max = intrev32ifbe(is->length)-, mid = -;
int64_t cur = -;
/* The value can never be found when the set is empty */
if (intrev32ifbe(is->length) == ) {
if (pos) *pos = ;
return ;
} else {
/* Check for the case where we know we cannot find the value,
* but do know the insert position. */
// 因为底层数组是有序的,如果 value 比数组中最后一个值都要大
// 那么 value 肯定不存在于集合中,
// 并且应该将 value 添加到底层数组的最末端
if (value > _intsetGet(is,intrev32ifbe(is->length)-)) {
if (pos) *pos = intrev32ifbe(is->length);
return ;
// 因为底层数组是有序的,如果 value 比数组中最前一个值都要小
// 那么 value 肯定不存在于集合中,
// 并且应该将它添加到底层数组的最前端
} else if (value < _intsetGet(is,)) {
if (pos) *pos = ;
return ;
}
}
// 在有序数组中进行二分查找
while(max >= min) {
mid = (min+max)/;
cur = _intsetGet(is,mid);
if (value > cur) {
min = mid+;
} else if (value < cur) {
max = mid-;
} else {
break;
}
}
// 检查是否已经找到了 value
if (value == cur) {
if (pos) *pos = mid;
return ;
} else {
if (pos) *pos = min;
return ;
}
}
intsetMoveTail:移动函数
static void intsetMoveTail(intset *is, uint32_t from, uint32_t to) {
void *src, *dst;
uint32_t bytes = intrev32ifbe(is->length)-from;
uint32_t encoding = intrev32ifbe(is->encoding);
//这里的移动可就是批量移动的了,见后面的memmove
if (encoding == INTSET_ENC_INT64) {
src = (int64_t*)is->contents+from;
dst = (int64_t*)is->contents+to;
bytes *= sizeof(int64_t);
} else if (encoding == INTSET_ENC_INT32) {
src = (int32_t*)is->contents+from;
dst = (int32_t*)is->contents+to;
bytes *= sizeof(int32_t);
} else {
src = (int16_t*)is->contents+from;
dst = (int16_t*)is->contents+to;
bytes *= sizeof(int16_t);
}
memmove(dst,src,bytes);
}
看了前面那么多,我们在看函数intsetAdd,那就太简单了
intset *intsetAdd(intset *is, int64_t value, uint8_t *success) {
// 计算编码 value 所需的长度
uint8_t valenc = _intsetValueEncoding(value);
uint32_t pos;
// 默认设置插入为成功
if (success) *success = ;
/* Upgrade encoding if necessary. If we need to upgrade, we know that
* this value should be either appended (if > 0) or prepended (if < 0),
* because it lies outside the range of existing values. */
if (valenc > intrev32ifbe(is->encoding)) {
/* This always succeeds, so we don't need to curry *success. */
return intsetUpgradeAndAdd(is,value);
} else {
/* Abort if the value is already present in the set.
* This call will populate "pos" with the right position to insert
* the value when it cannot be found. */
if (intsetSearch(is,value,&pos)) {
if (success) *success = ;
return is;
}
//将 value 添加到整数集合中并为 value 在集合中分配空间
is = intsetResize(is,intrev32ifbe(is->length)+);
if (pos < intrev32ifbe(is->length)) intsetMoveTail(is,pos,pos+);
}
// 将新值设置到底层数组的指定位置中
_intsetSet(is,pos,value);
// 增一集合元素数量的计数器
is->length = intrev32ifbe(intrev32ifbe(is->length)+);
// 返回添加新元素后的整数集合
return is;
}
再看一个删除函数intsetRemove,也是上面各种操作的结合体,也比较简单了
intset *intsetRemove(intset *is, int64_t value, int *success) {
uint8_t valenc = _intsetValueEncoding(value);
uint32_t pos;
if (success) *success = ;
if (valenc <= intrev32ifbe(is->encoding) && intsetSearch(is,value,&pos)) {
uint32_t len = intrev32ifbe(is->length);
/* We know we can delete */
if (success) *success = ;
/* Overwrite value with tail and update length */
if (pos < (len-)) intsetMoveTail(is,pos+,pos);
is = intsetResize(is,len-);
is->length = intrev32ifbe(len-);
}
return is;
}
最后我们再求个长度就结束了吧 zzzZZZ……
size_t intsetBlobLen(intset *is) {
return sizeof(intset)+intrev32ifbe(is->length)*intrev32ifbe(is->encoding);
}
关于大小端的参考材料:
http://blog.csdn.net/zhaoshuzhaoshu/article/details/37600857/
http://www.cnblogs.com/wi100sh/p/4899460.html
redis源码学习_整数集合的更多相关文章
- redis源码学习_字典
redis中字典有以下要点: (1)它就是一个键值对,对于hash冲突的处理采用了头插法的链式存储来解决. (2)对rehash,扩展就是取第一个大于等于used * 2的2 ^ n的数作为新的has ...
- redis源码学习_链表
redis的链表是双向链表,该链表不带头结点,具体如下: 主要总结一下adlist.c和adlist.h里面的关键结构体和函数. 链表节点结构如下: /* * 双端链表节点 */ typedef st ...
- redis源码学习_简单动态字符串
SDS相比传统C语言的字符串有以下好处: (1)空间预分配和惰性释放,这就可以减少内存重新分配的次数 (2)O(1)的时间复杂度获取字符串的长度 (3)二进制安全 主要总结一下sds.c和sds.h中 ...
- Redis源码学习:字符串
Redis源码学习:字符串 1.初识SDS 1.1 SDS定义 Redis定义了一个叫做sdshdr(SDS or simple dynamic string)的数据结构.SDS不仅用于 保存字符串, ...
- Redis源码学习:Lua脚本
Redis源码学习:Lua脚本 1.Sublime Text配置 我是在Win7下,用Sublime Text + Cygwin开发的,配置方法请参考<Sublime Text 3下C/C++开 ...
- 『TensorFlow』SSD源码学习_其一:论文及开源项目文档介绍
一.论文介绍 读论文系列:Object Detection ECCV2016 SSD 一句话概括:SSD就是关于类别的多尺度RPN网络 基本思路: 基础网络后接多层feature map 多层feat ...
- redis源码学习之slowlog
目录 背景 环境说明 redis执行命令流程 记录slowlog源码分析 制造一条slowlog slowlog分析 1.slowlog如何开启 2.slowlog数量限制 3.slowlog中的耗时 ...
- 柔性数组(Redis源码学习)
柔性数组(Redis源码学习) 1. 问题背景 在阅读Redis源码中的字符串有如下结构,在sizeof(struct sdshdr)得到结果为8,在后续内存申请和计算中也用到.其实在工作中有遇到过这 ...
- __sync_fetch_and_add函数(Redis源码学习)
__sync_fetch_and_add函数(Redis源码学习) 在学习redis-3.0源码中的sds文件时,看到里面有如下的C代码,之前从未接触过,所以为了全面学习redis源码,追根溯源,学习 ...
随机推荐
- Cronz表达式
- ylbtech-LanguageSamples-Indexers_2(索引器)
ylbtech-Microsoft-CSharpSamples:ylbtech-LanguageSamples-Indexers_2(索引器) 1.A,示例(Sample) 返回顶部 Indexers ...
- mac设置多个屏幕显示的问题
点击 设置 -> 显示器 -> 排列,然后拉着菜单在两个显示器之间切换.
- go语言基础之安装go开发环境和beego
1.install gogo1.11.4.windows-amd64.msi #默认安装就可以 2.golandgoland-2018.2.2.exe 安装完成,不要运行软件. 软件下载:https ...
- 一步一步学RenderMonkey(3)——改良Phong光照模型 【转】
转载请注明出处: http://blog.csdn.net/tianhai110 改良后的Phong光照模型: 上一节实现的phong镜面光照模型,如果固定光源,移动视点(及matView 关联为ma ...
- tomcat 部署 RESTful 服务实例
1.建立简单restfule服务 参考:java 利用JAX-RS快速开发RESTful 服务实例 简单代码: package com.example; import javax.ws.rs.GET; ...
- URLRewrite地址重定向的实现
URLRewrite就是我们通常说的地址重写,用户得到的全部都是经过处理后的URL地址.其优点有: (1)提高安全性,可以有效的避免一些参数名.ID等完全暴露在用户面前,如果用户随便乱输的话,不符合规 ...
- megalo -- 网易考拉小程序解决方案
megalo 是基于 Vue 的小程序框架(没错,又是基于 Vue 的小程序框架),但是它不仅仅支持微信小程序,还支持支付宝小程序,同时还支持在开发时使用更多 Vue 的特性. 背景 对于用户而言,小 ...
- 安装Tomcat指定JDK ——转
转自:http://www.cnblogs.com/lioillioil/archive/2011/10/08/2202169.html 一.应用实例 一般情况下一台服务器只跑一个业务,那么就直接配置 ...
- 建站笔记1:centos6.5下安装mysql
近期买了个域名,想要玩玩自己建站点:接下来遇到的问题都会一次记录下来.以备自己以后复习查看: 首先建站方案选择: wordPress +centos6.5 +mysql; server买的:搬瓦工最低 ...